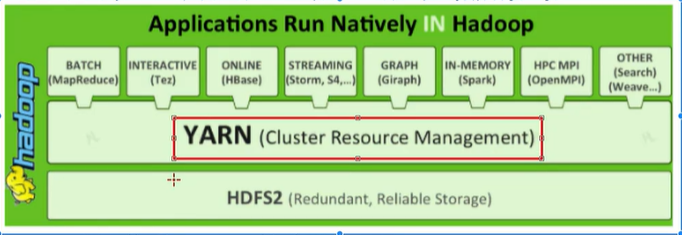
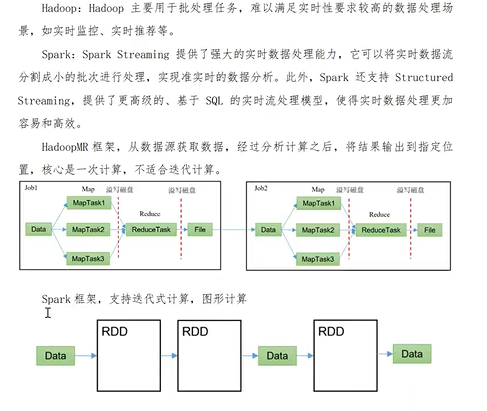
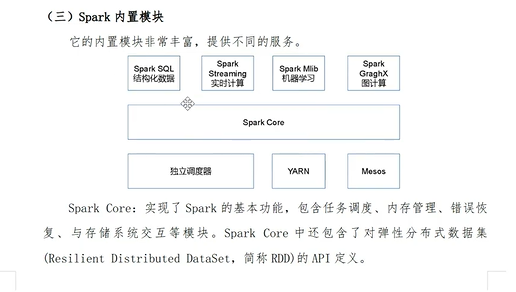
技术栈
spark与hadoop的区别
461K.
2025-04-22 20:07
一.概述
二.处理速度
三.编程模型
四:实时性处理
五.spark内置模块
六.spark的运行模式
大数据
运维
hadoop
分布式
spark
intellij-idea
上一篇:
STM32CubeMX-H7-15-SPI通信协议读写W25Q64
下一篇:
Linux——系统安全及应用
相关推荐
Championship.23.24
4 小时前
Linux 3.0 锁机制与故障排查详解
linux
·
运维
·
服务器
ffqws_
4 小时前
Redis 分布式锁:基于 Redisson 的实现与面试高频问答
redis
·
分布式
·
面试
jkyy2014
5 小时前
深耕AI健康医疗数据智库,赋能企业构建主动健康管理新生态
大数据
·
人工智能
·
健康医疗
风123456789~
6 小时前
【Linux专栏】ls 排除某个文件
linux
·
运维
·
服务器
其实防守也摸鱼
6 小时前
运维--学习阶段问题解答(1)(自测)
linux
·
运维
·
服务器
·
数据库
·
学习
·
自动化
·
命令模式
2601_96194608
7 小时前
AI API 网关实战:从单 Key 管理到企业级多租户架构
大数据
·
人工智能
·
金融
·
架构
·
api
·
个人开发
Darkwanderor
8 小时前
对Linux的进程控制的研究
linux
·
运维
·
c++
大大大大晴天
9 小时前
Flink CDC 深度解析:从原理到实践的全链路指南
大数据
·
flink
六bring个六
10 小时前
open Harmony中分布式软总线的学习任务清单
分布式
·
学习
·
c/c++
·
open harmony
IT新视界
10 小时前
Elasticsearch信创国产化替代
大数据
·
elasticsearch
·
搜索引擎
热门推荐
01
GitHub 镜像站点
02
幻兽帕鲁 - 服务器管理员权限与 GM 命令完全指南
03
AI科技热点日报 | 2026年07月01日
04
2026年7月AI圈大地震:GPT-5.6被政府限制、Claude入驻Slack、Anthropic自研芯片
05
GPT-5.5 对比 GPT-5.6 Sol、Terra、Luna:官方性能数据与选型分析
06
2026 国产 AI 大模型横评:DeepSeek、通义千问、Kimi、文心一言、星火、豆包谁更能打?
07
AI 编程 IDE 全景解析 2026:Agent 全面接管开发链路
08
全面体验 Grok API 中转站(2025 · Grok 4 系列最新版)
09
2026 年 AI 编程工具终极横评:Cursor vs Claude Code vs Copilot vs Windsurf
10
几个好用的ip纯净度检测网站