SparkStreaming主要用于流式计算,处理实时数据。

DStream是SparkStreaming中的数据抽象模型,表示随着时间推移收到的数据序列。
SparkStreaming支持多种数据输入源(如Kafka、Flume、Twitter、TCP套接字等)和数据输出位置(如HDFS、数据库等)。
SparkStreaming特点
易用性:支持Java、Python、Scala等编程语言,编写实时计算程序如同编写批处理程序。
容错性:无需额外代码和配置即可恢复丢失的数据,允许随时返回上一步重新计算。
整合性:可以在Spark上运行,重复使用相关代码进行批处理,实现交互式查询操作。
SparkStreaming架构
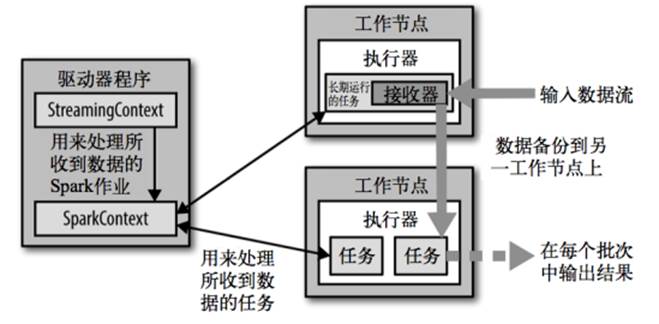
驱动程序:StreamingContext处理所收到的数据的Spark作业,并传给SparkContext。
工作节点:处理所收到的数据的任务,接收器接收并长期运行任务。
背压机制:协调数据接收能力和资源处理能力,避免数据堆积溢出或资源浪费。
自定义数据源
1.创建自定义数据源
需要导入新的函数并继承现有函数。
创建时选择class类型而非object类型。
2.定义数据源
在class中定义onstart和onstop方法。
onstart方法中创建新线程并调用接收数据的方法。
onstop方法为空。
3.接收数据
连接到指定主机和端口号。
创建输入流并转换为字符流。
使用缓冲字符输入流读取数据并写入input中。
判断是否停止,若未停止且数据非空则继续写入sparkstream。
调用自定义数据源
1.配置对象和流对象
填写配置对象和stream对象。
2.调用自定义函数
提供主机名和端口号。
获取数据后进行资金统计。
数据处理
1.扁平化数据
将所有数据根据空格切分并进行扁平化处理。
转换成键值对形式,相同单词进行分组累加,实现词频统计。
2.输出结果
手动终止或程序异常时输出结果并终止程序。