在Mysql数据存储或性能瓶颈时,采用冷热数据分离的方式通常是一种选择。ClickHouse和Elasticsearch(ES)是两个常用的组件,但具体使用哪种组件取决于冷数据的存储目的、查询模式和业务需求等方面。
1、核心对比
(1)、ClickHouse
- 适用场景:
- OLAP分析:适合需要快速处理大规模数据的聚合查询(如统计、分析历史数据)。
- 结构化数据:适合高度结构化的数据(如日志、订单、交易记录等)。
- 列式存储:列式存储设计使其在聚合查询(如SUM, COUNT, GROUP BY)中性能极佳。
- 批量写入:适合批量导入冷数据(如定时任务迁移的批量数据)。
- 优点:
- 查询性能:在复杂分析场景中显著优于MySQL和ES。
- 扩展性:支持水平扩展,适合处理PB级数据。
- 成本:开源免费,硬件成本可控(但需优化配置)。
- 高效的压缩率,减少存储成本。
- 缺点:
- 写入模式:不擅长高频率的小批量写入(适合批量导入冷数据)。
- 事务支持:不支持传统事务,适合分析型场景。
- 学习成本:SQL语法和生态相对复杂。
- 数据更新操作(如删除、修改)效率较低。
(2)、Elasticsearch (ES)
- 适用场景:
- 全文搜索:适合需要快速全文检索的场景(如日志、文本内容搜索)。
- 实时分析:适合半结构化数据(如日志、JSON文档)的实时查询和统计。
- 高并发写入:支持高吞吐量的写入(如实时日志收集)。
- 优点:
- 全文检索:强大的全文搜索和模糊匹配能力。
- 实时性:数据写入后可立即查询,适合近实时分析。
- 灵活性:支持动态Schema,适合非结构化或半结构化数据。
- 扩展性:分布式架构,易于水平扩展。
- 缺点:
- 聚合性能:复杂聚合查询(如多维度统计)可能不如ClickHouse高效。
- 存储成本:存储成本较高(需较多资源存储倒排索引)。
- 数据模型限制:不适合强事务和复杂关联查询。
2、冷数据存储的典型场景选择
(1)、选择ClickHouse的场景
- 冷数据用途:
需要频繁的聚合分析(如统计过去一年的用户行为、订单趋势、日志分析等)。 - 数据类型:
结构化数据(如订单表、日志表、交易记录等)。 - 示例:
- 将MySQL中超过6个月的订单数据迁移到ClickHouse,用于生成历史销售报告。
- 将系统日志数据存入ClickHouse,用于分析用户行为趋势。
(2)、选择ES的场景
- 冷数据用途:
需要全文搜索或实时日志分析(如日志检索、文本内容分析)。- 例如:搜索过去一年中包含特定关键词的日志条目。
- 数据类型:
非结构化或半结构化数据(如日志、JSON文档、文本内容等)。 - 示例:
- 将MySQL中历史聊天记录迁移到ES,支持用户搜索历史对话中的关键词。
- 将系统日志存入ES,用于快速定位错误日志。
(3)、混合使用场景
- 冷数据同时需要分析和搜索:
可将结构化数据(如订单金额、用户ID)存入ClickHouse,非结构化数据(如订单备注、日志内容)存入ES。 - 分层存储:
- 热数据:MySQL(实时事务处理)。
- 冷数据:
- ClickHouse(结构化数据(如:具体的数值,金额,年龄等)的分析)。
- ES(非结构化数据(文档,文本,JSON)的搜索)。
3、冷数据迁移方案设计
(1)、定义冷数据规则:
- 时间维度:如超过6个月未更新的数据。
- 访问频率:如过去3个月未被查询的数据。
(2)、数据迁移工具:
- ClickHouse:使用clickhouse-copier或自定义ETL工具批量导入。
- ES:使用Logstash或Bulk API批量导入。
(3)、查询逻辑改造:
- 业务查询时,优先查询MySQL(热数据),若未命中则查询冷数据源(ClickHouse/ES)。
4、具体场景示例
场景:电商平台订单数据
- 热数据:
MySQL存储最近3个月的订单数据,用于实时下单、支付等操作。 - 冷数据:
- ClickHouse:存储超过3个月的订单数据,用于生成销售报告(如按地区统计GMV)。
- ES:存储订单备注中的文本内容,支持用户搜索历史订单中的关键词(如"红色T恤")。
技术选型依据:
- ClickHouse:
订单金额、用户ID、时间戳等结构化数据的聚合分析(如SUM(order_amount))。 - ES:
订单备注、用户评价等文本内容的全文检索。
5、ClickHouse和ES建议对比
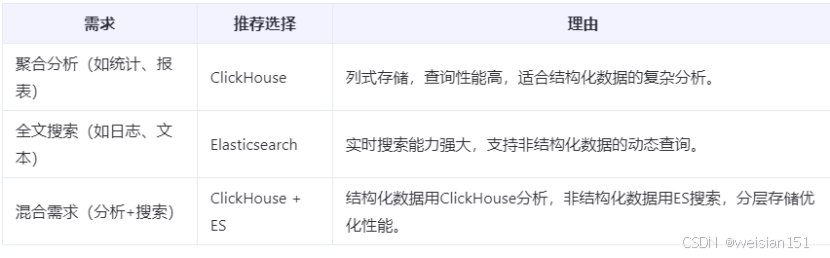
6、其他替代组件的推荐
(1)、对象存储(如AWS S3、阿里云OSS)
适用场景:
- 归档类冷数据:长期存储(如1年以上)且极少访问的数据。
- 低成本存储:通过Parquet、ORC 等列式格式存储,配合Spark/Flink进行批量分析。
优势:
- 存储成本低,适合冷数据的长期归档。
- 适合离线分析(如生成月报、年报)。
(2)、HBase或HDFS
适用场景:
- 半结构化/非结构化数据:如日志、事件日志、需要高扩展性的冷数据。
- 时序数据:通过时间戳分区存储,支持范围查询。
优势:
- HBase支持高并发读写,适合部分冷数据仍需少量更新的场景。
- HDFS适合离线批处理(如 Hadoop 分析)。
(3)、分布式数据库(如TiDB、CockroachDB)
适用场景:
- 混合冷热数据:需要同时支持 OLTP(热数据)和 OLAP(冷数据)的场景。
- 强一致性要求:冷数据仍需少量更新或跨库事务。
优势:
- 自动水平扩展,支持 HTAP(混合事务与分析处理)。
(4)、时序数据库(如 InfluxDB、TimescaleDB)
适用场景:
- 时间序列数据:如 IoT 设备数据、监控指标、传感器数据。
- 按时间范围查询:支持自动过期(TTL)和压缩。
优势:
- 针对时序数据优化,查询效率高,存储成本低。
7、其他组件对比
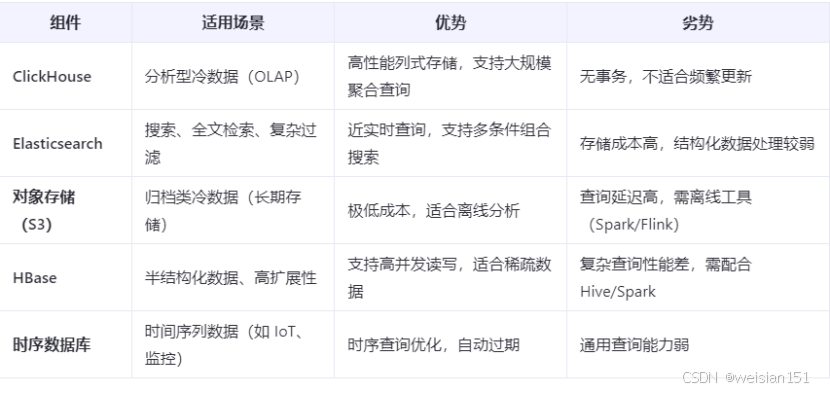
8、最佳实践建议
(1)、根据冷数据的用途选择组件
- 仅需分析(如报表、趋势) → ClickHouse
- 需要搜索或全文检索(如日志、评论) → ES
- 长期归档且极少访问 → 对象存储(S3)
- 时间序列数据(按时间查询) → InfluxDB
(2)、混合架构方案
- 热数据:保留在 MySQL(或分库分表优化)。
- 冷数据:
- 分析需求 → ClickHouse(主) + 对象存储S3(归档)。
- 搜索需求 → ES(主) + 对象存储S3(归档)。
(3)、数据迁移策略
- 触发条件:
- 时间维度(如3个月前)或状态维度(如订单已完结)。
- 可通过定时任务或触发器迁移。
- 迁移工具:
- MySQL → ClickHouse:用INSERT SELECT或工具(如 Maxwell、Debezium)。
- MySQL → ES:用Logstash、Flink 或自定义ETL。
(4)、成本优化
- 存储分层:
- 热数据 → SSD 存储(高性能 MySQL 实例)。
- 冷数据 → HDD 存储(低成本 ClickHouse 集群或对象存储)。
逆风成长,Dare To Be!!!