模块梳理
一、整体架构关系图
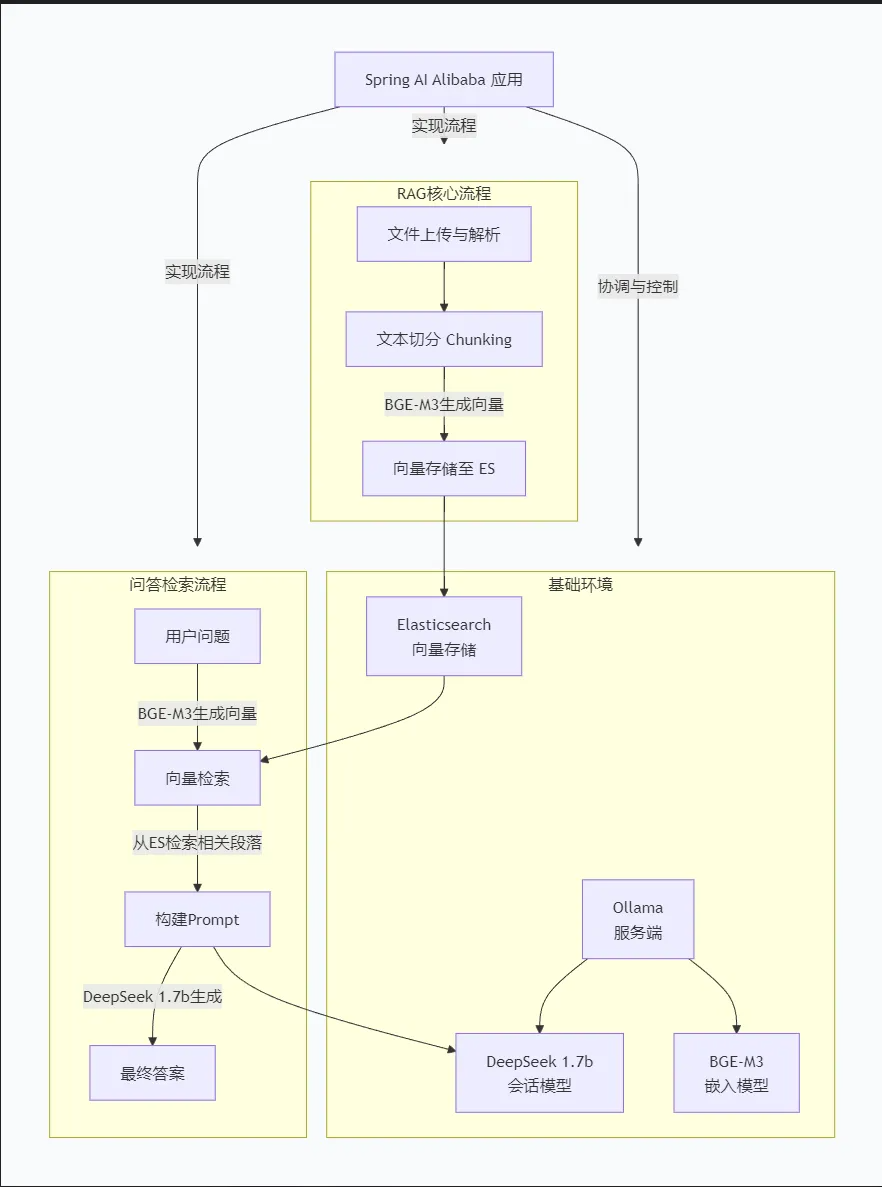
二、核心流程图
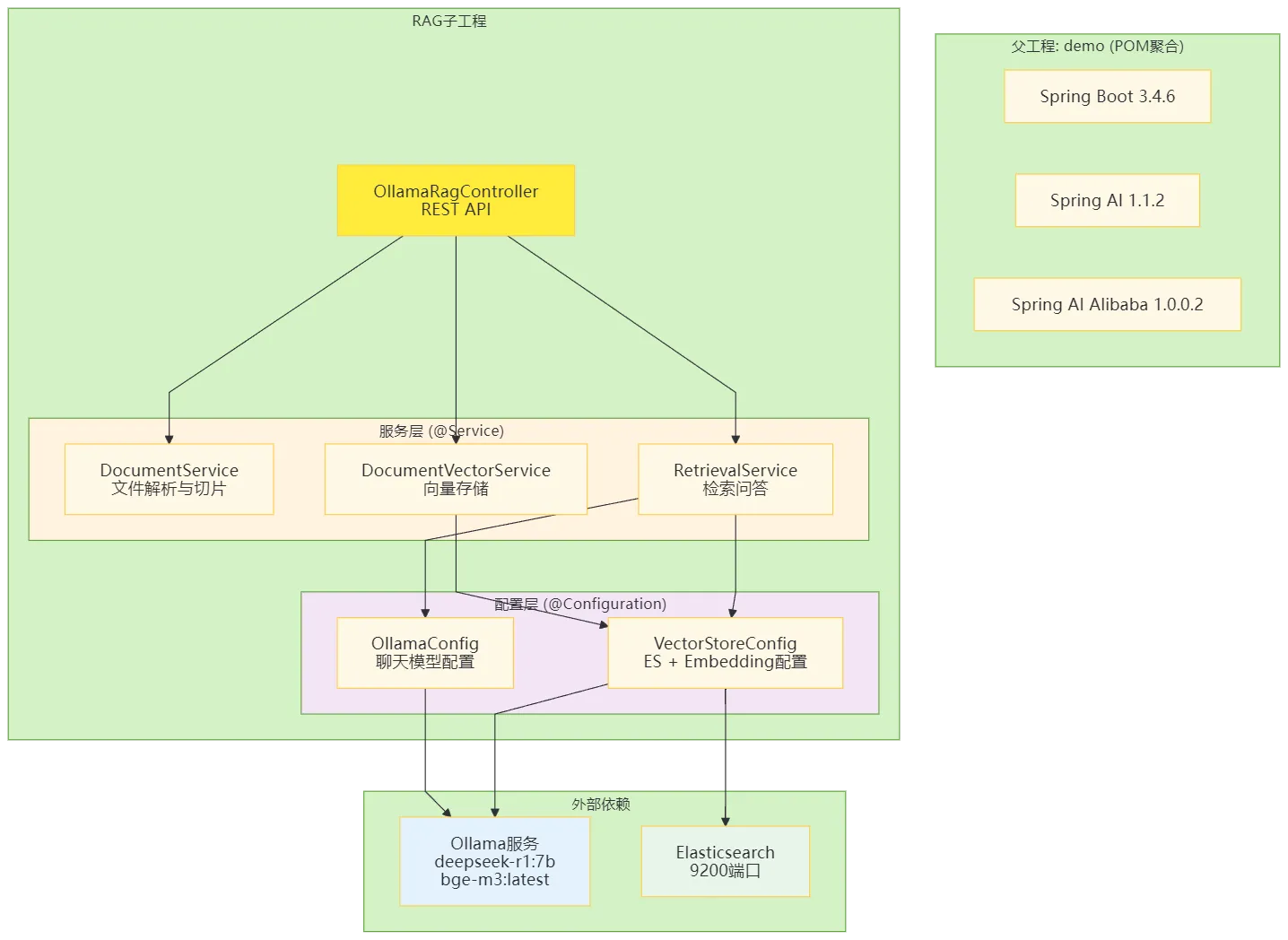
2. 问答检索流程
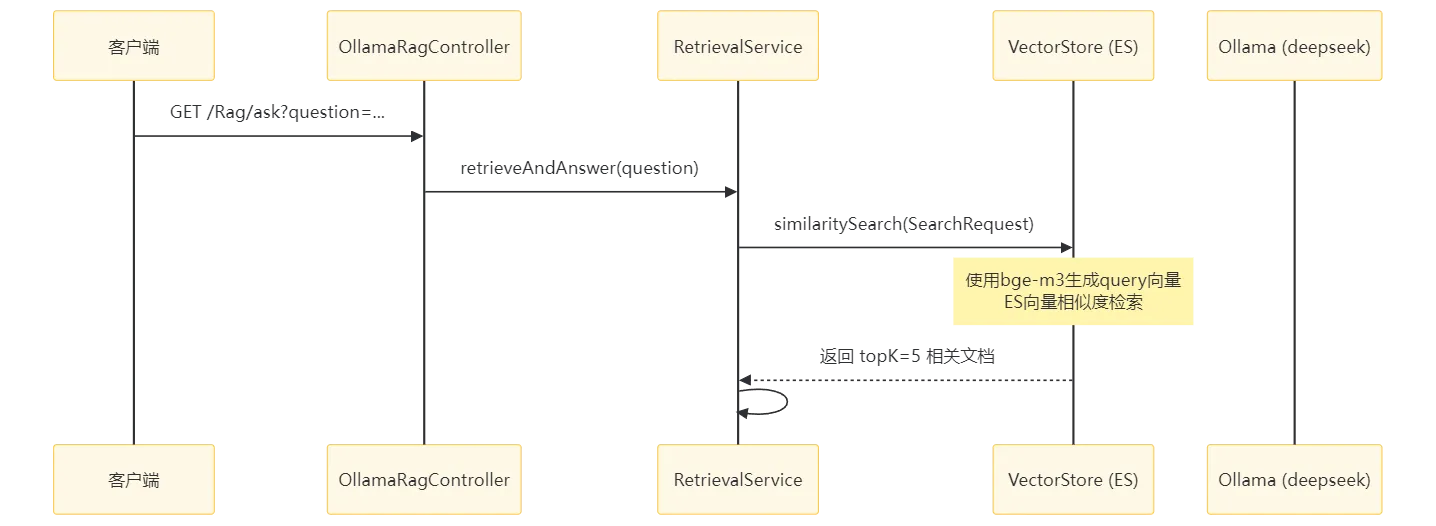
三、模块与依赖配置表
| 模块 | 主要配置类 | 核心依赖 | 端口 |
|---|---|---|---|
| 父工程 (demo) | pom.xml | Spring AI 1.1.2, Spring Boot 3.4.6 | - |
| RAG子工程 | application.yml | spring-ai-pdf-document-reader, elasticsearch-java | 8081 |
| Ollama配置 | OllamaConfig.java | spring-ai-ollama | 11434 |
| 向量存储配置 | VectorStoreConfig.java | spring-ai-elasticsearch-store | 9200 |
核心要点:
- 文档处理: MultipartFile → InputStreamResource → PagePdfDocumentReader → TokenTextSplitter
- 向量存储: Document → EmbeddingModel(bge-m3) → ElasticsearchVectorStore
- 问答流程: 用户问题 → 向量检索 → 上下文构建 → deepseek-r1:7b → 答案
- 配置管理:所有配置通过 @Configuration 和 @Value 从 application.yml 注入
1.创建项目,创建一个maven项目,父工程
主要用于管理springAi相关的版本,目录结构如下

主工程的pom文件如下 大家可查阅阿里巴巴ai的官网: https://java2ai.com/docs/overview
XML
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.5.8</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>org.fl</groupId>
<artifactId>demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>pom</packaging>
<name>demo</name>
<description>demo</description>
<url/>
<licenses>
<license/>
</licenses>
<developers>
<developer/>
</developers>
<modules>
<module>ailibaba</module>
<module>RAG</module>
</modules>
<scm>
<connection/>
<developerConnection/>
<tag/>
<url/>
</scm>
<properties>
<java.version>17</java.version>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<spring-boot.version>3.4.6</spring-boot.version>
<spring-ai.version>1.1.2</spring-ai.version>
<spring-ailibaba.version>1.0.0.2</spring-ailibaba.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-bom</artifactId>
<version>${spring-ailibaba.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- 3. PGVector 向量数据库 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store-spring-boot-starter</artifactId>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring-boot.version}</version>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<!-- 阿里云代码库 -->
<repository>
<id>maven-ali</id>
<url>https://maven.aliyun.com/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
<updatePolicy>always</updatePolicy>
<checksumPolicy>fail</checksumPolicy>
</snapshots>
</repository>
</repositories>
</project>HTML, XML
2.创建子工程RAG
子工程的目录结构如下,主要是pom依赖,导入需要springalibaba-ai-es和es-java,还有pdf处理相关的依赖
RAG子工程pom文件
XML
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.fl</groupId>
<artifactId>demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<artifactId>RAG</artifactId>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<scope>provided</scope>
</dependency>
<!-- ChatClient 向量存储拦截器(RAG 必需) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
<!-- Elasticsearch 向量存储 -->
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-elasticsearch-store</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-elasticsearch</artifactId>
</dependency>
<!-- PDF 解析 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.20</version>
</dependency>
</dependencies>
</project>3.开发步骤
开发前提:需要用ollama拉取对应的模型,我这里使用的是deepseek-r1:7b 与 嵌入式模型 bge-m3:latest, 大家可以根据自己的电脑配置自行升级,拉取es windows版。
1.创建yml文件
我的配置都是默认配置,es在本地配置文件中关闭了ssl与账号密码校验,有疑问的可以自行网上检索,相关处理方法很多
java
server:
port: 8081
servlet:
encoding:
enabled: true
charset: UTF-8
force: true
spring:
application:
name: alibaba
ai:
ollama:
base-url: http://localhost:11434
chat:
options:
model: deepseek-r1:7b
embedding:
options:
enabled: true
model: bge-m3:latest
vectorstore:
elasticsearch:
initialize-schema: true
dimensions: 1024
elasticsearch:
uris: http://localhost:9200
file:
upload:
max-size: 50MB
temp-dir: D:/temp/upload
# model: qwen3:0.6b
# dashscope:
# api-key:2.创建config对应的类
主要是ollama会话模型,嵌入式模型,es搜索相关的初始化配置 ollama会话模型配置类
java
package org.fl.config;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor;
import org.springframework.ai.chat.memory.MessageWindowChatMemory;
import org.springframework.ai.ollama.OllamaChatModel;
import org.springframework.ai.ollama.api.OllamaApi;
import org.springframework.ai.ollama.api.OllamaChatOptions;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
/**
* Ollama配置类,用于创建和配置Ollama聊天模型及相关组件
*/
@Configuration
public class OllamaConfig {
@Value("${spring.ai.ollama.base-url}")
private String baseUrl;
@Value("${spring.ai.ollama.chat.options.model}")
private String model;
/**
* 创建并配置Ollama聊天模型Bean
*
* @return 配置好的OllamaChatModel实例
*/
@Bean("myOllamaChatModel")
@Primary
public OllamaChatModel ollamaChatModel() {
// 构建Ollama API客户端,设置基础URL
OllamaApi ollamaApi = OllamaApi.builder()
.baseUrl(baseUrl)
.build();
// 配置聊天选项,设置使用的模型
OllamaChatOptions options = new OllamaChatOptions();
options.setModel(model);
// 构建并返回Ollama聊天模型实例
return OllamaChatModel.builder()
.ollamaApi(ollamaApi)
.defaultOptions(options)
.build();
}
/**
* 创建并配置聊天客户端Bean
*
* @param ollamaChatModel Ollama聊天模型实例
* @return 配置好的ChatClient实例
*/
@Bean
public ChatClient chatClient(OllamaChatModel ollamaChatModel) {
// 构建聊天客户端,添加日志记录器和消息内存管理器,并设置默认选项
return ChatClient.builder(ollamaChatModel).defaultAdvisors(new SimpleLoggerAdvisor())
.defaultAdvisors(MessageChatMemoryAdvisor
.builder(MessageWindowChatMemory.builder()
.maxMessages(20).build())
.build())
.defaultOptions(OllamaChatOptions.builder().model("deepseek-r1:7b").build()).build();
}
}es与向量模型与数据库配置类
这些配置可以直接从yaml获取,我懒得改,大家根据需求自己更改代码即可
java
package org.fl.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.embedding.TokenCountBatchingStrategy;
import org.springframework.ai.ollama.OllamaEmbeddingModel;
import org.springframework.ai.ollama.api.OllamaApi;
import org.springframework.ai.ollama.api.OllamaEmbeddingOptions;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.vectorstore.elasticsearch.ElasticsearchVectorStore;
import org.springframework.ai.vectorstore.elasticsearch.ElasticsearchVectorStoreOptions;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
/**
* 配置向量存储相关组件的配置类。
* 包括Elasticsearch客户端、嵌入模型以及向量存储实例的创建与初始化。
*/
@Configuration
public class VectorStoreConfig {
/**
* 创建并返回一个用于连接Elasticsearch的RestClient实例。
* 默认连接地址为 http://localhost:9200。
*
* @return 初始化后的RestClient对象
*/
@Bean
public RestClient restClient() {
return RestClient.builder(new HttpHost("localhost", 9200, "http"))
.build();
}
/**
* 构建并返回一个Elasticsearch向量存储(VectorStore)实例。
* 使用自定义索引名称和维度设置,并启用自动初始化schema功能。
*
* @param restClient 用于与Elasticsearch通信的客户端
* @param embeddingModel 嵌入模型,用于将文本转换为向量表示
* @return 配置完成的ElasticsearchVectorStore实例
*/
@Bean("myVectorStore")
@Primary
public VectorStore vectorStore(RestClient restClient, EmbeddingModel embeddingModel) {
// 设置Elasticsearch向量存储选项
ElasticsearchVectorStoreOptions options = new ElasticsearchVectorStoreOptions();
options.setIndexName("custom-index"); // 可选:指定索引名,默认为"spring-ai-document-index"
options.setDimensions(1024); // 可选:设定向量维度,默认使用模型维度或1536,我拉取的模型只支持1024维度
return ElasticsearchVectorStore.builder(restClient, embeddingModel)
.options(options) // 可选:应用自定义选项
.initializeSchema(true) // 可选:是否在启动时初始化索引结构,默认false
.batchingStrategy(new TokenCountBatchingStrategy()) // 可选:批处理策略,默认TokenCountBatchingStrategy
.build();
}
/**
* 创建并返回一个基于Ollama服务的嵌入模型(EmbeddingModel)实例。
* 模型默认使用 bge-m3:latest,并通过本地Ollama API提供服务。
*
* @return 配置好的OllamaEmbeddingModel实例
*/
@Bean
@Primary
public EmbeddingModel embeddingModel() {
return OllamaEmbeddingModel.builder()
.ollamaApi(OllamaApi.builder().baseUrl("http://localhost:11434").build()) // Ollama API基础URL
.defaultOptions(OllamaEmbeddingOptions.builder().model("bge-m3:latest").build()) // 默认使用的模型
.build();
}
}3.文件上传切片处理服务
pdf文档处理类
该类主要是将pdf文件使用ai提供的pdf方法切片,然后返回,后续存储至es嵌入式数据库中
java
package org.fl.service;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.reader.pdf.PagePdfDocumentReader;
import org.springframework.ai.transformer.splitter.TextSplitter;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.core.io.FileSystemResource;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import java.io.File;
import java.nio.file.Files;
import java.util.List;
/**
* 文档处理服务类,用于接收上传的文件并将其解析为结构化文档列表。
* 支持 PDF 和文本文件格式,并对文档进行切分处理以适配后续 AI 模型使用。
*/
@Service
public class DocumentService {
/**
* 处理上传的文件,根据文件类型选择不同的读取方式,最终返回经过切分的文档列表。
*
* @param file 用户上传的多部分文件对象,支持 PDF 或纯文本文件
* @return 经过解析与切分后的文档列表,适用于向量嵌入等下游任务
* @throws Exception 当文件为空、无法读取、处理失败或临时文件操作出错时抛出异常
*/
public List<Document> processFile(MultipartFile file) throws Exception {
// 前置校验:文件为空直接抛异常
if (file.isEmpty()) {
throw new IllegalArgumentException("上传的文件不能为空");
}
List<Document> documents;
if (file.getOriginalFilename() != null && file.getOriginalFilename().toLowerCase().endsWith(".pdf")) {
File tempFile = null;
try {
// 1. 创建临时文件(指定临时目录,避免跨系统路径问题)
tempFile = Files.createTempFile("upload-", ".pdf").toFile();
// 2. 传输文件到临时文件(关键:校验传输是否成功)
file.transferTo(tempFile);
// 校验临时文件是否存在且可读
if (!tempFile.exists() || !tempFile.canRead()) {
throw new Exception("临时文件生成失败或不可读:" + tempFile.getAbsolutePath());
}
// 3. 改用 FileSystemResource 加载文件系统中的文件(核心修复点)
FileSystemResource resource = new FileSystemResource(tempFile);
PagePdfDocumentReader pdfReader = new PagePdfDocumentReader(resource);
documents = pdfReader.read();
} catch (Exception e) {
throw new Exception("处理PDF文件失败:" + e.getMessage(), e); // 保留异常栈,便于排查
} finally {
// 4. 安全删除临时文件(确保文件已处理完成)
if (tempFile != null && tempFile.exists()) {
boolean deleted = tempFile.delete();
if (!deleted) {
tempFile.deleteOnExit();
// 可选:打印日志提醒
System.err.println("临时文件立即删除失败,将在JVM退出时删除:" + tempFile.getAbsolutePath());
}
}
}
} else {
// 处理文本文件:读取输入流为字符串
String content = new String(file.getInputStream().readAllBytes());
documents = new TextReader(content).read();
}
// 文本切分:将长文档分成小块 内置有参数,可自行调参
TextSplitter textSplitter = new TokenTextSplitter();
return textSplitter.apply(documents);
}
}文档向量处理类
java
package org.fl.service;
import jakarta.annotation.Resource;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.stereotype.Service;
import java.util.List;
/**
* 文档向量服务类
* 提供文档向量存储和语义搜索功能
*/
@Service
public class DocumentVectorService {
@Resource(name = "myVectorStore")
private VectorStore vectorStore;
/**
* 将文档(或文本块)添加到向量数据库
*
* @param documents 要添加的文档列表
*/
public void addDocuments(List<Document> documents) {
vectorStore.add(documents);
}
/**
* 进行语义搜索
*
* @param query 搜索查询字符串
* @return 返回与查询最相似的文档列表
*/
public List<Document> search(String query) {
// 构建搜索请求,返回最相似的5条记录
SearchRequest searchRequest = SearchRequest.builder().topK(5).query(query).build();
return vectorStore.similaritySearch(searchRequest);
}
}向量检索与大模型会话类
java
package org.fl.service;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.messages.Message;
import org.springframework.ai.chat.prompt.SystemPromptTemplate;
import org.springframework.ai.document.Document;
import org.springframework.ai.ollama.OllamaChatModel;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
/**
* 提供基于向量检索与大语言模型的回答服务。
* <p>
* 该服务首先通过用户问题在向量库中检索最相关的文档片段,
* 然后将这些文档作为上下文构建系统提示词,
* 最终调用大语言模型生成专业、准确的回答。
*/
@Service
public class RetrievalService {
@Resource(name = "myVectorStore")
private VectorStore vectorStore;
@Resource(name = "myOllamaChatModel")
private OllamaChatModel chatModel; // 自动配置为 deepseek-r1:1.5b
@Resource
private ChatClient chatClient;
/**
* 根据用户的提问,从向量存储中检索相关信息,并结合大模型生成回答。
*
* @param userQuestion 用户提出的问题文本
* @return 大模型根据检索到的上下文所生成的回答内容
*/
public String retrieveAndAnswer(String userQuestion) {
// 1. 检索:从向量库查找相关文档块
List<Document> similarDocuments = vectorStore.similaritySearch(
SearchRequest.builder().topK(5).query(userQuestion).build()// 返回最相似的5条
);
// 2. 构建增强提示词 (Prompt)
String context = similarDocuments.stream()
.map(Document::getText)
.collect(Collectors.joining("\n\n"));
String systemPrompt = """
你是一个专业的文档助手,请严格根据以下上下文信息回答问题。
如果上下文没有提供答案,请直接说"根据现有资料无法回答"。
上下文信息:
{context}
""";
SystemPromptTemplate promptTemplate = new SystemPromptTemplate(systemPrompt);
Message message = promptTemplate.createMessage(Map.of("context", context));
// 3. 生成:调用大模型获取最终答案
String content = chatClient.prompt()
.system(message.getText())
.user(userQuestion)
.call().content();
return content;
}
}4.控制层
主要是测试请求,与返回数据等
java
package org.fl.controller;
import jakarta.annotation.Resource;
import org.fl.service.DocumentService;
import org.fl.service.DocumentVectorService;
import org.fl.service.RetrievalService;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor;
import org.springframework.ai.chat.memory.MessageWindowChatMemory;
import org.springframework.ai.document.Document;
import org.springframework.ai.ollama.OllamaChatModel;
import org.springframework.ai.ollama.api.OllamaChatOptions;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import java.util.List;
/**
* OllamaRagController 类提供基于 RAG(Retrieval-Augmented Generation)的文档上传与问答功能。
* 支持通过 REST 接口上传文档并进行向量化存储,以及根据问题检索相关内容并生成回答。
*/
@RestController
@RequestMapping("/Rag")
public class OllamaRagController {
private static final Logger log = LoggerFactory.getLogger(OllamaRagController.class);
@Resource(name = "myOllamaChatModel")
private OllamaChatModel ollamaChatModel;
private final ChatClient ollamaiChatClient;
@Autowired
private DocumentService documentService;
@Autowired
private DocumentVectorService vectorStoreService;
@Autowired
private RetrievalService retrievalService;
/**
* 构造函数,用于创建 OllamaRagController 实例,并初始化聊天客户端配置。
*
* @param builder ChatClient.Builder 对象,用于构建聊天客户端
*/
private OllamaRagController(ChatClient.Builder builder) {
// 配置聊天客户端,设置内存聊天记录、日志记录和默认模型选项
this.ollamaiChatClient = builder
.defaultAdvisors(new SimpleLoggerAdvisor())
.defaultAdvisors(MessageChatMemoryAdvisor
.builder(MessageWindowChatMemory.builder()
.maxMessages(20).build())
.build())
.defaultOptions(OllamaChatOptions.builder().model("deepseek-r1:7b").build()).build();
}
/**
* 处理文件上传请求。将上传的文件进行处理、切分并转化为向量后存入向量数据库中。
*
* @param file 用户上传的多部分文件对象
* @return 成功信息字符串,表示文档已成功上传并完成向量化存储
* @throws Exception 文件处理或向量化过程中可能抛出异常
*/
@PostMapping("/upload")
public String uploadDocument(@RequestParam("file") MultipartFile file) throws Exception {
List<Document> chunks = documentService.processFile(file);
vectorStoreService.addDocuments(chunks);
return "文档 '" + file.getOriginalFilename() + "' 上传、切分并向量化存储成功!";
}
/**
* 根据用户提出的问题从已有文档中检索相关信息,并结合大模型生成答案。
*
* @param question 用户提出的查询问题
* @return 返回由检索内容支持的大模型生成的回答文本
*/
@GetMapping("/ask")
public String askQuestion(@RequestParam String question) {
return retrievalService.retrieveAndAnswer(question);
}
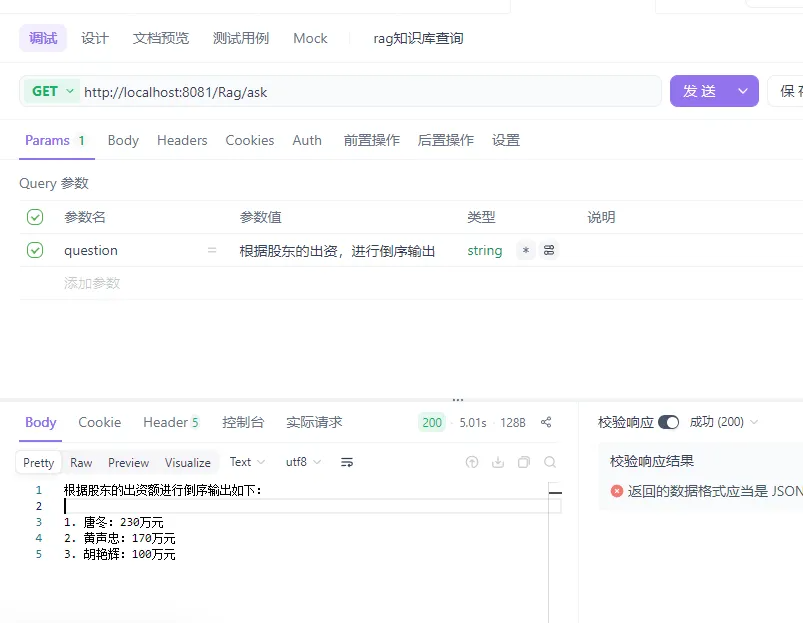
}测试效果如下
文件上传,随便找个http工具即可
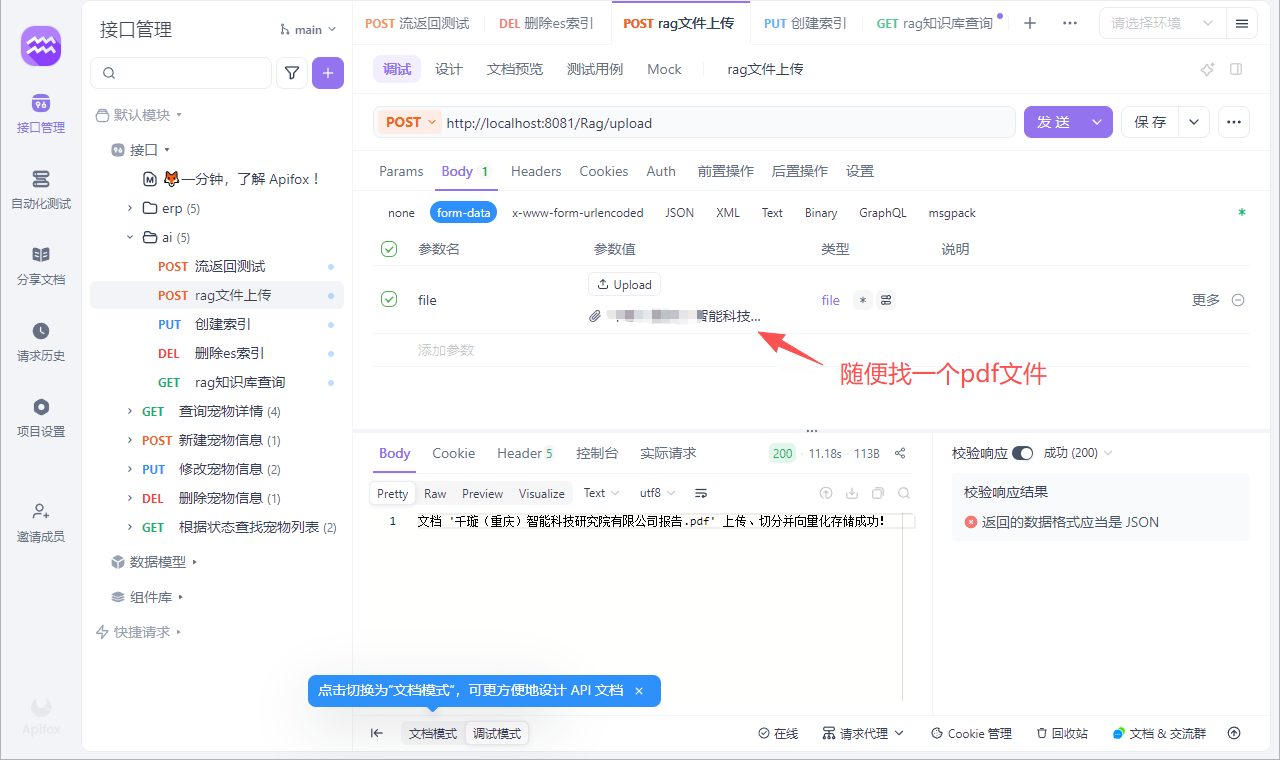
知识库查询
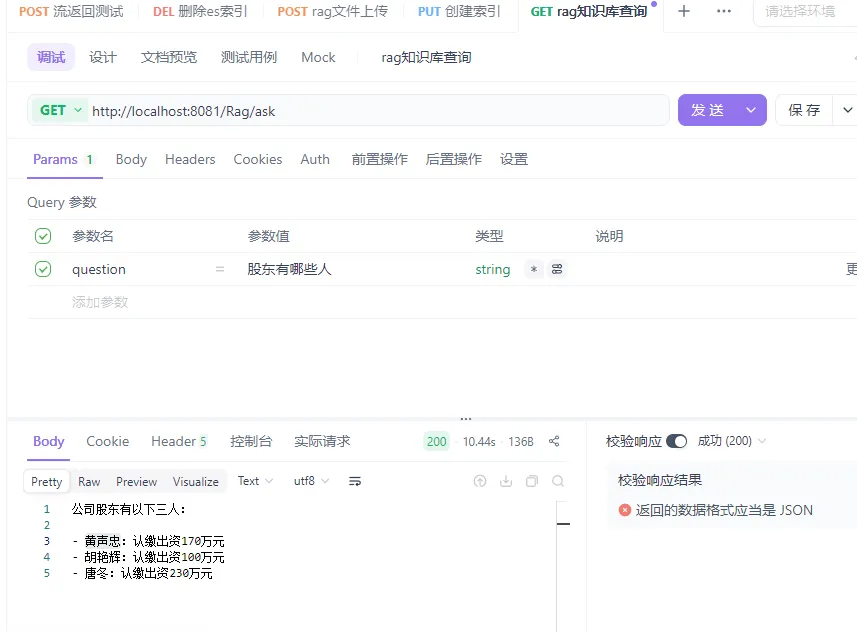
也可以加入自己的部分条件,例如排序