Spark 诞生主要是为了解决 Hadoop MapReduce 在迭代计算以及交互式数据处理时面临的性能瓶颈问题。
一,spark的框架
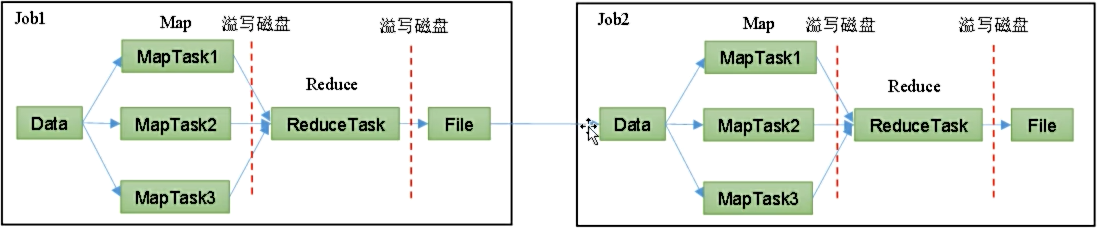
Hadoop MR 框架
从数据源获取数据,经过分析计算后,将结果输出到指定位置,核心是一次计算,不适合迭代计算。
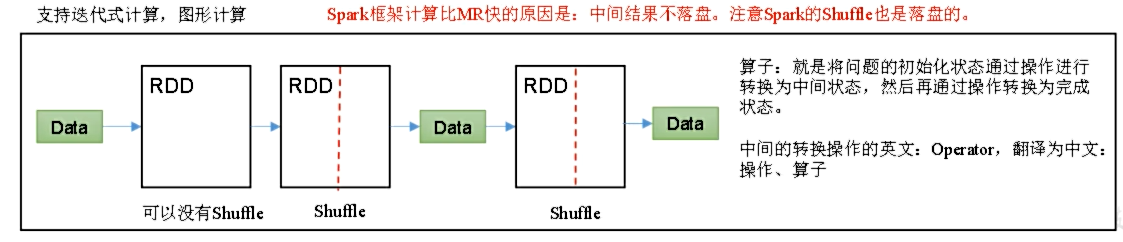
spark 框架
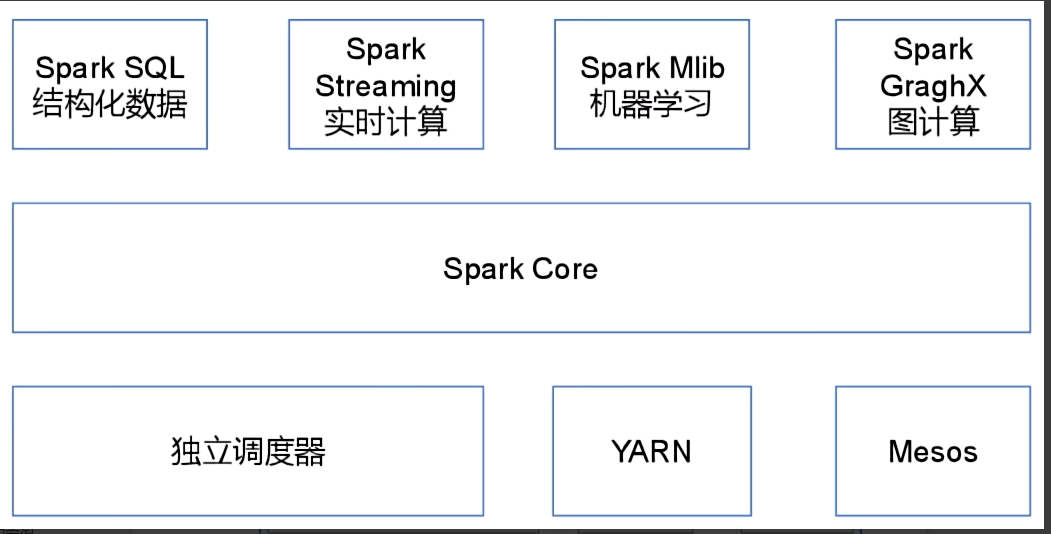
二,Spark内置模块
spark Core:实现了Spark的基本功能,包含任务调度,内存管理,错误恢复,存储系统交互等模块。
spark SQL: 是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用SQL或者Apache Hive 版本的HQL来查询数据。
实时计算:spark是基于MR的,而MR是离线的。(实时的延迟是以ms为单位的)。
机器学习和图计算:需要有比较强的数学功底。
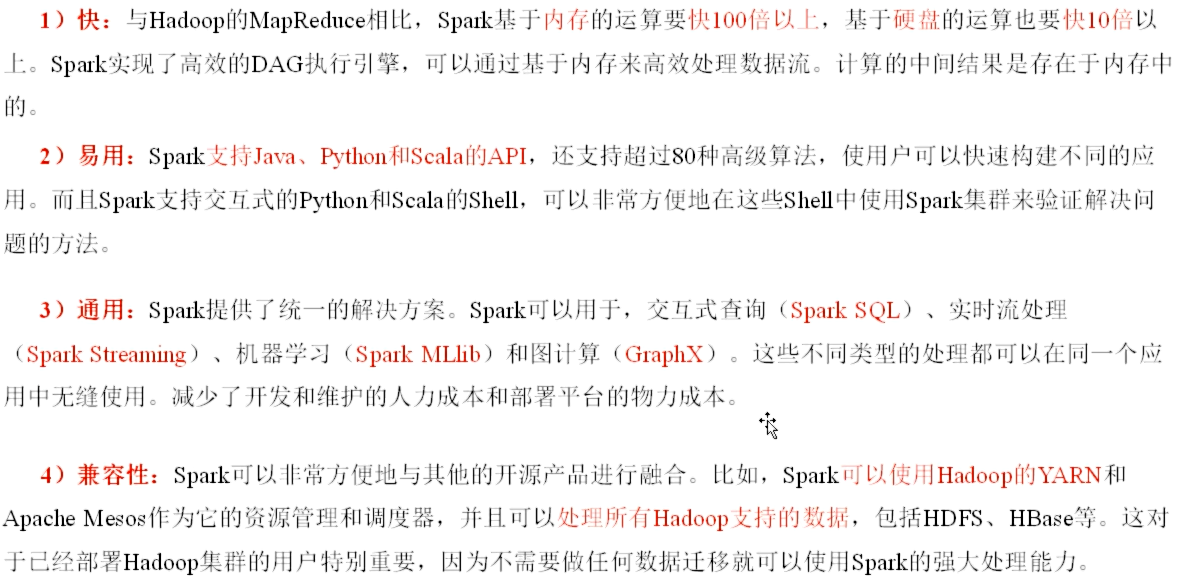
三,spark的特点
四,spark和Hadoop的对比
(1)计算模型
Hadoop MapReduce 基于 "分而治之" 的思想,将任务分为 Map 和 Reduce 两个阶段,数据在不同阶段之间通过磁盘进行存储和传输,适合处理大规模的批处理任务。
Spark 基于内存计算,提供了丰富的操作算子,如 map、reduce、filter 等,可以将数据加载到内存中进行多次迭代计算,适用于实时计算、交互式查询和机器学习等场景。
(2)处理速度
Hadoop 由于频繁的磁盘 I/O 操作,在处理迭代式算法或交互式查询时,速度相对较慢。
Spark 将数据缓存到内存中,避免了大量的磁盘读写,因此在处理相同的数据和任务时,通常比 Hadoop 快数倍甚至数十倍。
(3)编程模型
Hadoop 的编程模型相对复杂,需要开发人员熟悉 MapReduce 的原理和流程,编写大量的代码来实现数据处理逻辑。
Spark 提供了简洁的编程接口,支持 Scala、Java、Python 等多种编程语言,开发人员可以使用更高级的函数式编程风格来处理数据,代码更加简洁易懂。
(4)适用场景
Hadoop 适用于对大规模数据进行批处理,如数据仓库、ETL(Extract,Transform,Load)等场景,能够处理海量的结构化和半结构化数据。
Spark 除了支持批处理外,还在实时流计算、机器学习、图计算等领域有着广泛的应用,能够快速处理实时数据和复杂的计算任务。
五,spark和Hadoop的联系
都是大数据处理框架:它们都致力于解决大数据环境下的数据存储、处理和分析问题,为企业和组织提供了处理海量数据的能力。
Hadoop 为 Spark 提供基础:Hadoop 的 HDFS(Hadoop Distributed File System)可以为 Spark 提供可靠的分布式数据存储,Spark 可以直接读取 HDFS 中的数据进行处理。此外,Hadoop 的 YARN(Yet Another Resource Negotiator)可以作为 Spark 的资源管理器,为 Spark 作业分配计算资源。
功能互补:在实际应用中,Spark 和 Hadoop 常常结合使用。例如,可以先使用 Hadoop MapReduce 进行大规模的数据预处理,然后将处理后的数据存储在 HDFS 中,再使用 Spark 进行进一步的分析和处理,充分发挥两者的优势。