引言
在深度学习的快速发展历程中,Transformer 架构如同璀璨的新星,照亮了自然语言处理(NLP)以及计算机视觉(CV)等众多领域的前行道路。自 2017 年在论文《Attention Is All You Need》中被提出以来,Transformer 凭借其独特的设计和卓越的性能,迅速成为了研究和应用的焦点。本文将深入剖析 Transformer 架构的原理、特点、应用场景以及未来发展趋势。
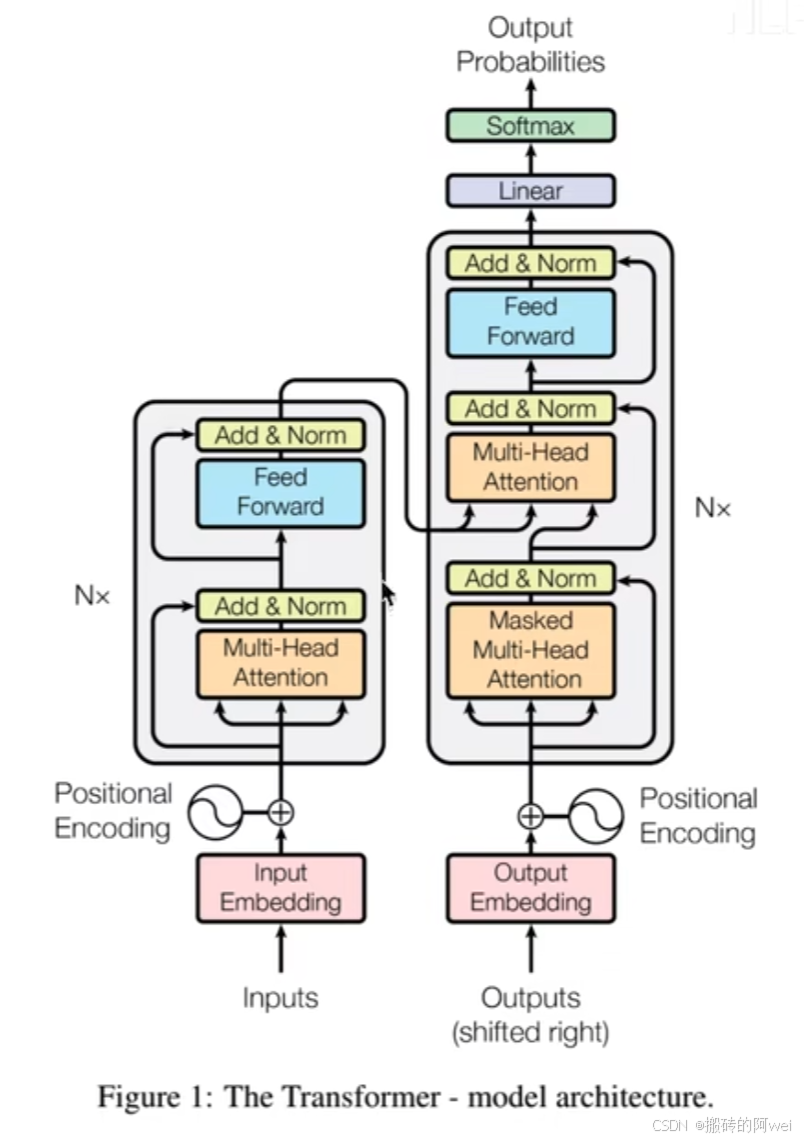
Transformer 采用编码器 - 解码器(Encoder - Decoder)架构。左侧是编码器(Encoder),右侧是解码器(Decoder)。编码器负责对输入序列进行编码,提取特征;解码器根据编码器输出和已生成的部分,生成目标序列。
编码器部分
- 输入嵌入(Input Embedding):输入的词或符号先通过嵌入层,将其转换为低维稠密向量,捕捉输入元素语义信息。
- 位置编码(Positional Encoding):由于 Transformer 本身无捕捉位置信息能力,位置编码给嵌入向量添加位置信息,一般用正弦余弦函数生成。
- N 个编码层堆叠 :编码层重复堆叠,每个编码层包含:
- 多头注意力机制(Multi - Head Attention):并行多个自注意力头,从不同子空间捕捉序列依赖关系,增强模型表达力。自注意力机制让序列各位置能关注其他位置信息,计算相关性权重加权求和。
- 层归一化与残差连接(Add & Norm):先将多头注意力输出与输入做残差连接(相加),再进行层归一化,稳定训练、加速收敛、缓解梯度消失。
- 前馈神经网络(Feed Forward):对多头注意力输出做非线性变换,进一步提取特征,由两个线性变换和激活函数组成。
解码器部分
- 输出嵌入(Output Embedding)和位置编码(Positional Encoding):与编码器类似,将输出元素转换为向量并添加位置信息,输出是右移一位的目标序列,符合自回归生成方式。
- N 个解码层堆叠 :解码层包含:
- 掩码多头注意力机制(Masked Multi - Head Attention):掩码操作防止当前位置关注后续位置信息,确保生成时只能依据已生成部分,符合序列生成从左到右顺序。
- 多头注意力机制(Multi - Head Attention):关注编码器输出,让解码器能利用编码器提取的输入序列特征。
- 层归一化与残差连接(Add & Norm):同编码层,稳定训练。
- 前馈神经网络(Feed Forward):进一步处理特征。
- 线性层(Linear)和 Softmax 层:解码器最后输出经线性层变换,再通过 Softmax 函数计算各输出类别概率,确定最终输出。
Transformer 架构的核心原理
位置编码(Positional Encoding)
由于 Transformer 架构本身不包含任何位置信息,为了让模型能够感知序列中元素的位置,需要对输入序列进行位置编码。
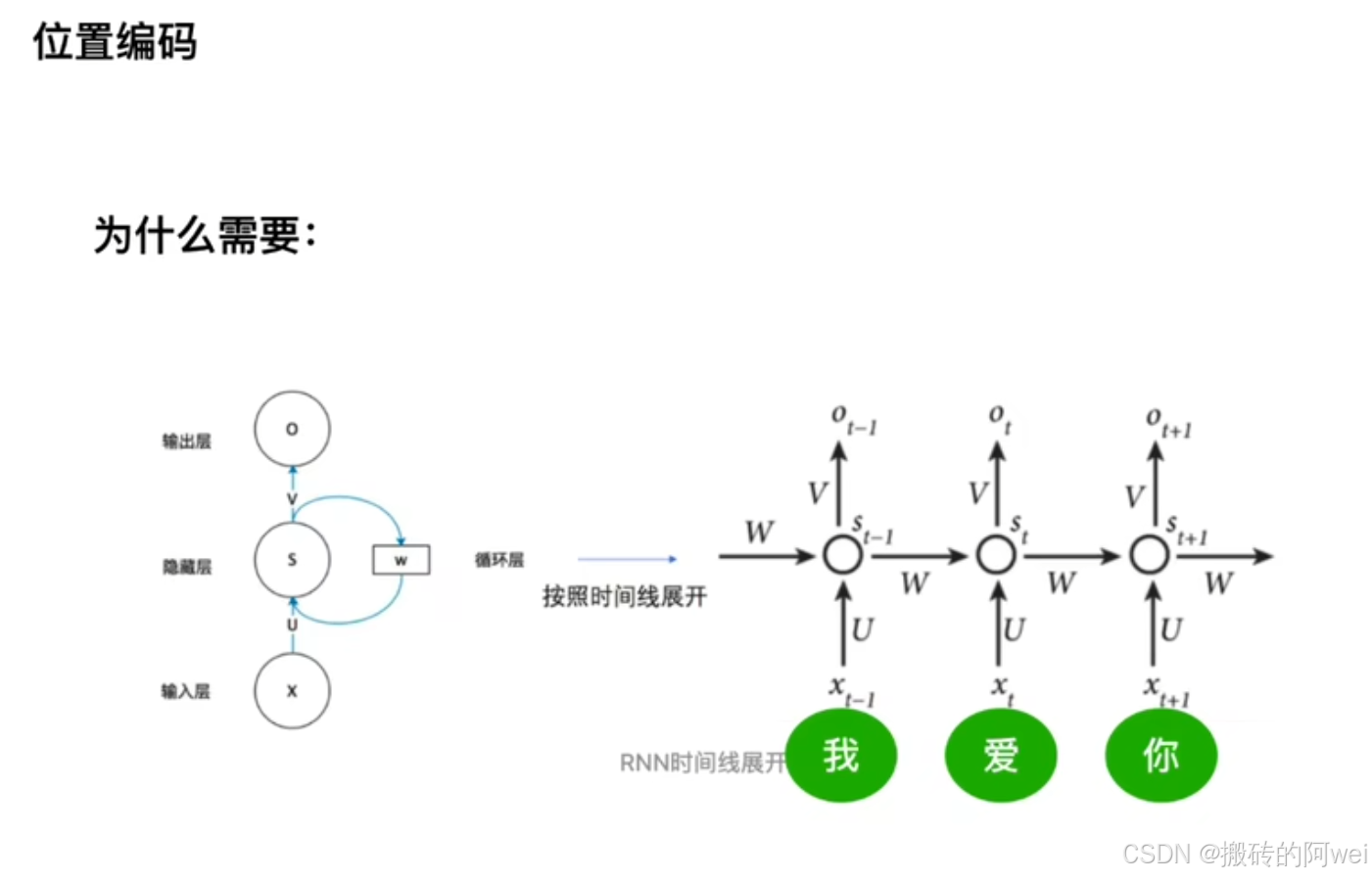
与RNN按顺序依次处理每个元素不同的是 Transformer通过并行计算能够同时处理多个元素,加快了计算效率。但是其忽略了元素之间的序列关系,所以需要位置编码。位置编码是将位置信息添加到输入序列的嵌入向量中,使得模型能够区分不同位置的元素。常见的位置编码方法是使用正弦和余弦函数,根据元素的位置生成不同频率的正弦和余弦值,将这些值与元素的嵌入向量相加。
自注意力机制(Self - Attention)
自注意力机制是 Transformer 的核心创新之一。它允许模型在处理序列时,为序列中的每个位置计算一个加权和,该加权和是序列中所有位置的表示的组合。具体而言,对于输入序列中的每个元素,自注意力机制会计算它与序列中其他元素的相关性得分,这些得分通过 softmax 函数转换为权重,然后根据这些权重对其他元素的表示进行加权求和,得到该元素的新表示。想详细了解自注意力机制可参考博主以往博客:Transformer 里 Self-Attention:解锁序列理解的新视角
多头注意力机制(Multi - Head Attention)
多头注意力机制是自注意力机制的扩展。它通过并行地执行多个自注意力头,每个头关注序列的不同方面,然后将这些头的输出拼接起来并进行线性变换,得到最终的输出。多头注意力机制可以让模型从不同的表示子空间中捕捉信息,从而提高模型的表达能力。
编码器 - 解码器架构(Encoder - Decoder Architecture)
Transformer 采用了编码器 - 解码器架构,这是一种在序列到序列(Seq2Seq)任务中常用的架构。编码器负责对输入序列进行编码,将其转换为一系列的上下文表示;解码器则根据编码器的输出和之前生成的输出,逐步生成目标序列。
编码器由多个相同的编码层堆叠而成,每个编码层包含多头注意力机制和前馈神经网络(Feed - Forward Network)。解码器同样由多个相同的解码层堆叠而成,每个解码层除了包含多头注意力机制和前馈神经网络外,还包含一个编码器 - 解码器注意力机制,用于关注编码器的输出。
Transformer 架构的特点
并行计算能力
与传统的 RNN 和 LSTM 不同,Transformer 在处理序列时可以并行计算,而不需要像 RNN 那样按顺序依次处理每个元素。这使得 Transformer 在训练和推理过程中能够充分利用 GPU 等硬件的并行计算能力,大大提高了计算效率。
长距离依赖处理能力
自注意力机制使得 Transformer 能够有效地捕捉序列中的长距离依赖关系。在处理长序列时,模型可以直接关注到序列中任意位置的元素,而不受距离的限制。这对于处理自然语言中的长句子、长文档等任务非常有优势。
灵活性和可扩展性
Transformer 架构具有很高的灵活性和可扩展性。它可以通过调整层数、头数、隐藏层维度等超参数来适应不同的任务和数据集。此外,Transformer 的编码器和解码器可以单独使用,也可以组合使用,适用于多种不同类型的任务。
Transformer 架构的应用场景
自然语言处理(NLP)
- 机器翻译:Transformer 在机器翻译任务中取得了巨大的成功。像 Google 的 mBART、Facebook 的 Fairseq 等翻译模型都基于 Transformer 架构,它们在多个语言对的翻译任务中达到了最先进的水平。
- 文本生成:在文本生成任务中,如故事生成、诗歌创作等,Transformer 可以生成高质量、连贯的文本。GPT 系列模型就是基于 Transformer 的解码器架构,能够生成自然流畅的文本。
- 问答系统:Transformer 可以用于构建问答系统,通过对问题和文档进行编码,然后根据编码结果生成答案。BERT 模型在问答任务中表现出色,它通过预训练和微调的方式,能够准确地回答各种类型的问题。
计算机视觉(CV)
- 图像分类:Transformer 架构也逐渐应用于计算机视觉领域,如图像分类任务。Vision Transformer(ViT)将图像分割成多个小块,将每个小块视为一个序列元素,然后使用 Transformer 进行处理,在图像分类任务中取得了很好的效果。
- 目标检测:在目标检测任务中,Transformer 可以用于建模图像中的全局信息,提高目标检测的精度。DETR(Detection Transformer)是一种基于 Transformer 的目标检测模型,它通过端到端的方式进行目标检测,简化了传统目标检测方法的流程。
Transformer 架构的未来发展趋势
模型的轻量化和高效化
随着 Transformer 模型的不断发展,模型的规模越来越大,计算资源的需求也越来越高。未来的研究方向之一是如何对 Transformer 模型进行轻量化和高效化,例如通过模型压缩、剪枝、量化等技术,减少模型的参数量和计算量,同时保持模型的性能。
跨领域融合
Transformer 架构在 NLP 和 CV 领域已经取得了显著的成果,未来有望在更多领域进行跨领域融合,如语音处理、多模态学习等。通过将不同领域的数据进行融合,Transformer 可以学习到更丰富的信息,提高模型的泛化能力和应用范围。
自监督学习和预训练技术的发展
自监督学习和预训练技术是 Transformer 取得成功的重要因素之一。未来,研究人员将继续探索更有效的自监督学习方法和预训练策略,以提高模型的学习能力和性能。例如,通过设计更复杂的预训练任务,让模型学习到更丰富的语义信息。
结语
Transformer 架构作为深度学习领域的一项重要创新,已经在多个领域取得了巨大的成功。它的出现改变了人们对序列处理任务的认识,为解决各种复杂的问题提供了新的思路和方法。随着技术的不断发展,Transformer 架构有望在更多领域发挥重要作用,推动深度学习技术不断向前发展。无论是研究者还是开发者,都应该密切关注 Transformer 的发展趋势,不断探索其在不同领域的应用潜力。