我自己的原文哦~https://blog.51cto.com/whaosoft/13860194
#SRPO
业内首次! 全面复现DeepSeek-R1-Zero数学代码能力,训练步数仅需其1/10
OpenAI 的 o1 系列和 DeepSeek-R1 的成功充分证明,大规模强化学习已成为一种极为有效的方法,能够激发大型语言模型(LLM) 的复杂推理行为并显著提升其能力。
然而,这些推理模型的核心训练方法在其技术报告中仍然鲜有披露。近期社区的主要工作也仅局限于数学推理领域,使得跨领域泛化这一挑战依然未得到充分探索。此外,GRPO 训练过程中存在多项常见问题,如性能瓶颈、样本利用效率低下,以及在处理混合领域数据集时难以培养专业推理技能等,这些挑战使得强化学习方法的有效扩展变得更加复杂。
针对这些挑战,来自快手Kwaipilot团队的研究者提出了一种创新的强化学习框架------两阶段历史重采样策略优化(two-Staged history-Resampling Policy Optimization,SRPO),旨在从多个维度系统性地解决上述训练难题。他们对外发布了SRPO的技术报告,详细披露了该训练方法的技术细节,同时也开源了SRPO-Qwen-32B 模型。
论文标题:SRPO: A Cross-Domain Implementation of Large-Scale Reinforcement Learning on LLM
论文链接:https://arxiv.org/abs/2504.14286
模型开源地址:https://huggingface.co/Kwaipilot/SRPO-Qwen-32B
这是业界首个同时在数学和代码两个领域复现 DeepSeek-R1-Zero 性能的方法。通过使用与 DeepSeek 相同的基础模型 (Qwen2.5-32B) 和纯粹的强化学习训练,SRPO 成功在 AIME24 和 LiveCodeBench 基准测试中取得了优异成绩(AIME24 = 50、LiveCodeBench = 41.6),超越了 DeepSeek-R1-Zero-32B 的表现。
更值得注意的是,SRPO 仅需 R1-Zero 十分之一的训练步数就达到了这一水平。
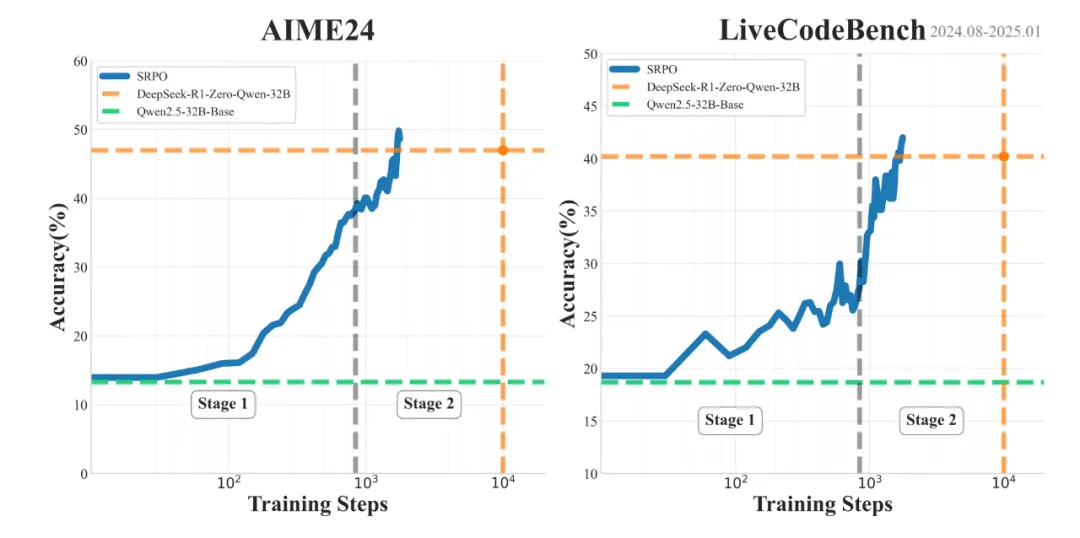
SRPO AIME24 和 LiveCodeBench 表现,每项为 pass@1 的 32 次平均得分
方法概览
原始 GRPO 实现的挑战
在最开始的探索中,快手 Kwaipilot 团队使用过标准的 GRPO 算法(公式 1)直接进行训练:
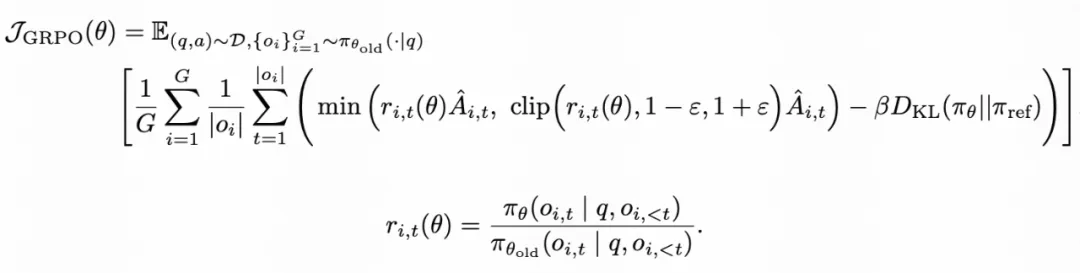
公式 1:GRPO 优化目标
然而,在训练过程中,他们很快遇到了瓶颈,模型始终无法达到预期的 R1-Zero 性能水平。这些问题包括:
- 数学与代码跨领域的优化冲突:数学问题很容易通过训练诱发较长且细致的推理轨迹(长 CoT),而代码数据这种倾向则弱很多。直接混合这两种类型的数据也会产生冲突,导致模型在两个领域中都表现欠佳。
- 相同的组奖励导致训练效率下降:GRPO 算法依赖于采样组内非零的奖励方差来计算优势。当一个组的 rollout 产生几乎相同的奖励值时,计算得到的优势会接近于零。当一个训练 batch 的大部分数据都表现出这种现象时,有效的梯度贡献会变得极小,大幅降低训练效率。
- 过早的性能饱和:GRPO 训练在 benchmark 评测中较早遇到了性能瓶颈,奖励也遇到饱和平台期。这个问题一定程度上源于数据集的质量不足。当训练数据缺乏足够的复杂性或多样性,特别是简单的问题太多,模型会倾向于保守地维持其在较容易任务中的性能,难以得到解决挑战性问题所需的复杂、深入的推理能力。
阶段训练
为了解决数学和代码之间内在的响应长度冲突问题,快手 Kwaipilot 团队最终实现了一种两阶段训练范式:
- Stage 1 (Eliciting Reasoning Abilities):初始训练阶段仅专注于具有挑战性的数学数据。此阶段的目标是充分激励模型的 test-time scaling,发展出反思性停顿、回溯行为和逐步分解等多种能力。
- Stage 2 (Skill Integration):在此阶段,将代码数据引入到训练过程中。利用在阶段 1 中建立的推理基础,进一步提升代码能力,同时逐步强化程序性思维、递归和工具调用能力。
训练策略的比较分析
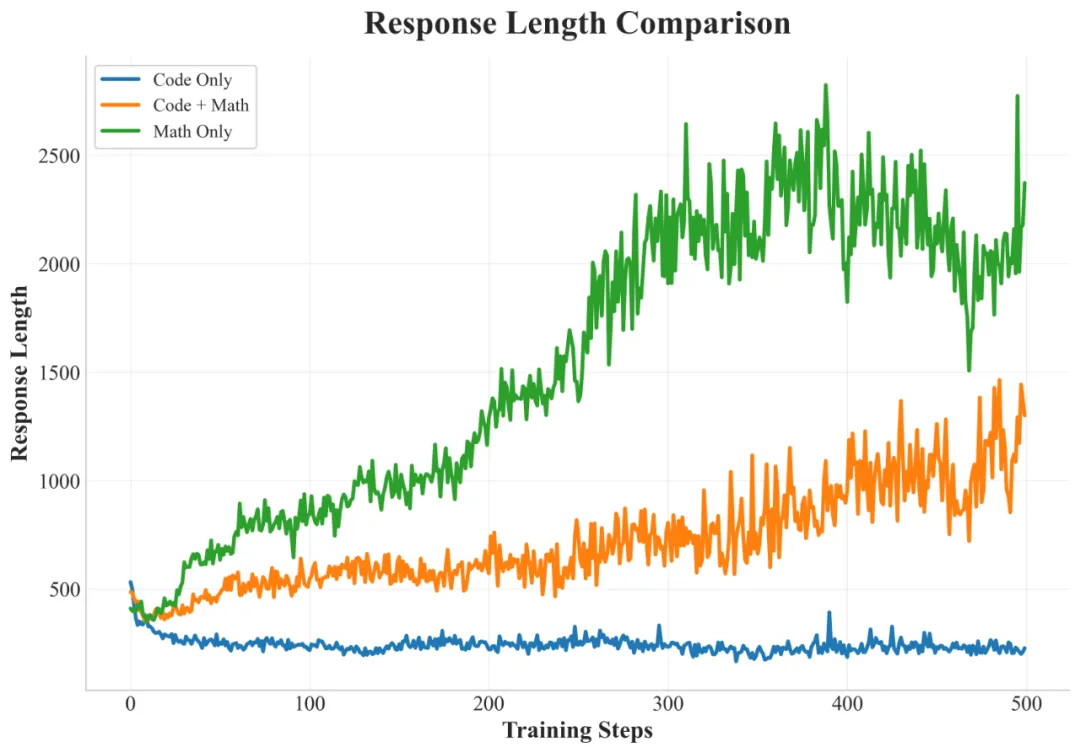
不同训练数据策略对响应长度的影响
Mixed Training:在数学和代码混合数据上训练的混合训练模型,在响应长度的增长方面表现出局限性,且基准测试性能较差。虽然数学问题会引发一些推理模式,但代码问题经常产生简短、直接的响应,主要集中于即时代码输出,而很少进行初步分析或规划。

Math-Only Training:仅使用数学数据进行训练能够稳定地增加回复长度,并在数学基准测试中表现出色。重要的是,这培养了强大的、能够很好地泛化的推理能力;当面对编程任务时,模型会尝试详细的、逐步的推理。观察到的行为包括在数学问题解决过程中细致的步骤检查和重新审视。这反映了数学数据激发推理能力的特征。

Code-Only Training:尽管在代码基准测试中的表现有所提高,但显式推理行为的发展甚微,并且实现响应长度的显著增加被证明是困难的。与纯数学训练相比,对代码和数学问题的响应都明显较短,代码任务的解决方案通常是直接生成的,缺乏实质性的逐步推理或初步分析。

Staged Training:快手 Kwaipilot 团队提出的两阶段训练在数学和编程领域均表现出优异的结果。该模型在解决数学问题时始终如一地生成详细的逐步推理模式,并在处理编程任务时生成结构化的推理模式。特别地,涌现出一些复杂的行为,例如模型自发地利用写代码来辅助数学推理。对这些响应模式的更详细分析将在后文中介绍。
History Resampling
快手 Kwaipilot 团队发现在训练的中后期阶段,batch 中近 50% 的采样组产生相同的奖励。这种情况通常发生在模型在较容易的问题上持续成功时,导致奖励的方差极小,梯度更新效果不佳。
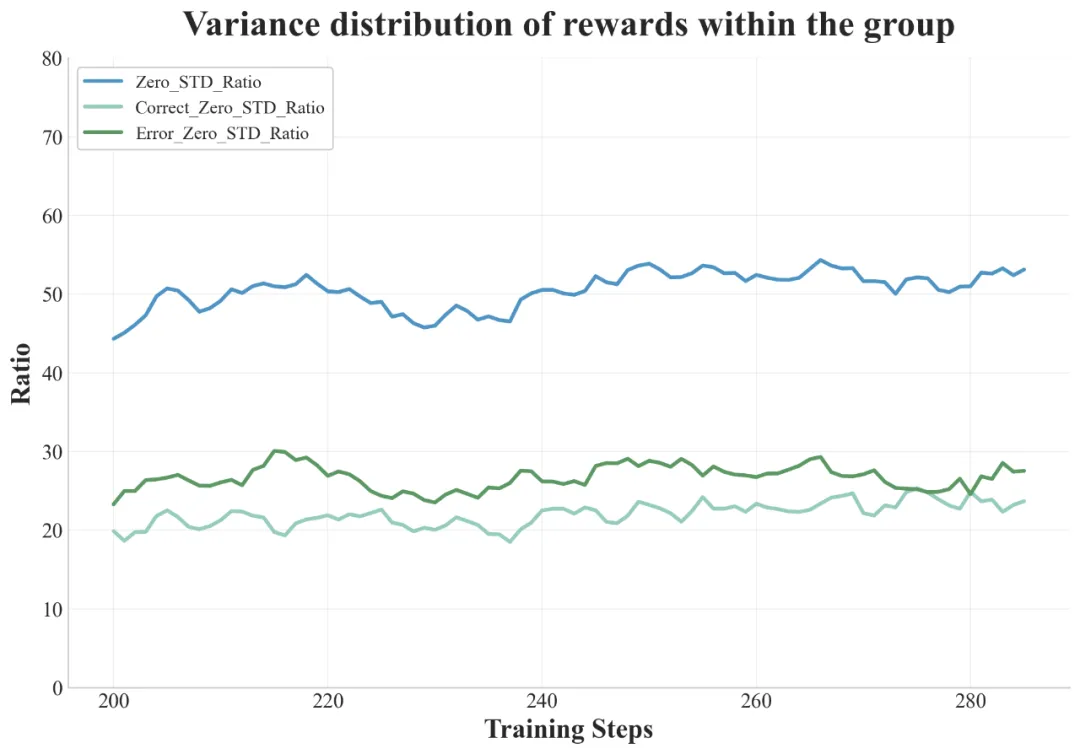
在训练期间 batch 内近 50% 的优势函数值为零(蓝色线)
为了解决这种低效性并提高梯度信号的质量,他们引入了历史重采样(History Resampling)。在训练过程中,他们记录每个 epoch 内所有 rollout 奖励的结果。在一个 epoch 结束时,他们按如下方式重建下一个 epoch 的数据集:
- 过滤过于简单的样本:排除所有 rollout 都得到正确答案的样本,它们实际上没有为策略改进提供任何信息信号。
- 保留信息样本:保留结果多样(既有正确又有不正确)或结果全部不正确的样本。这些样本生成正向奖励方差,确保优势非零及梯度信号有效。此外,对于当前 epoch 中所有展开都不正确的困难样本,快手 Kwaipilot 团队也将其保留在数据集中。理由是,这些最初具有挑战性的一些问题,对于更新后的策略而言可能会变得相对容易,从而在后续的训练中产生有效梯度。这种策略的根本思想与课程学习相一致,即逐步将模型暴露于平均而言更具挑战性的样本,以提高训练效率。
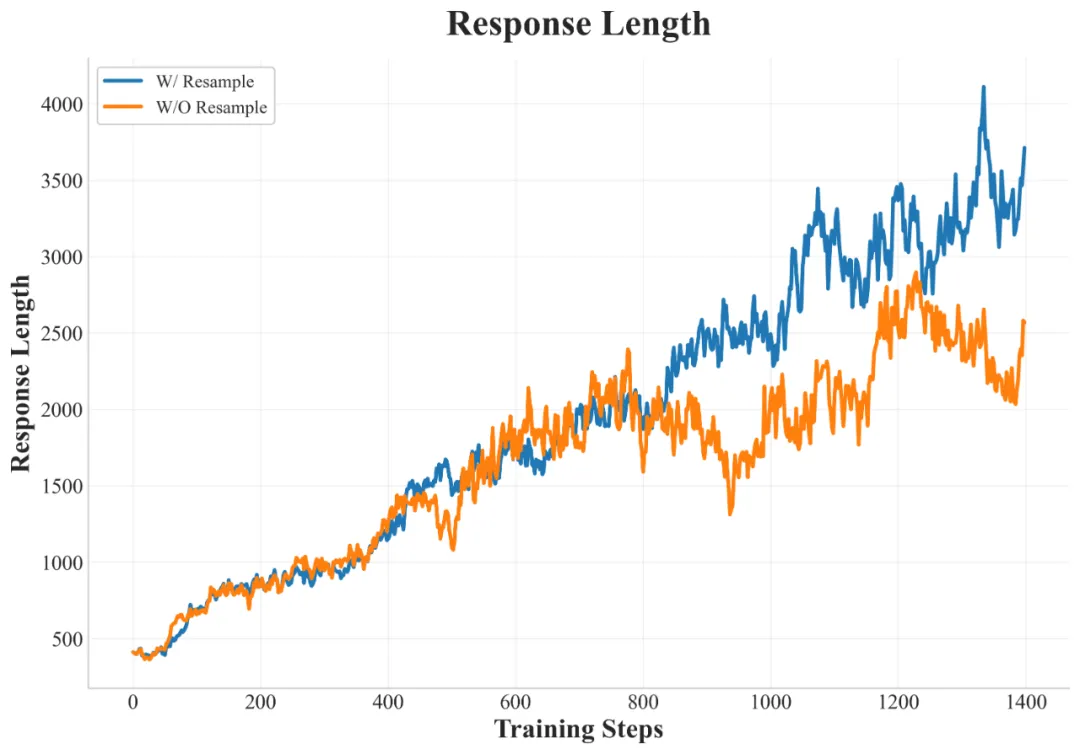
Training statistics of History Resampling
与 DAPO 中提出的 Dynamic Sampling 方法相比,History Resampling 显著提高了计算效率,响应长度增长也更加稳定。
数据
快手 Kwaipilot 团队对社区开源的 Code&Math 数据进行了数据清洗和筛选,通过启发式规则对原始数据进行过滤,清理题目文本中无关的 URL、格式噪声等,确保核心字段(问题和答案真值)完整。参考 PRIME 对数学数据的清洗方法,剔除一题多问、纯证明题、需要图像或表格理解的题目。针对代码数据,剔除依赖特定环境、需要文件 IO 或网络交互的题目,专注于算法逻辑。
在数据入库前,对数学和代码题目进行正确性校验,确保答案的正确性和可解性,剔除答案错误或存在歧义的题目;然后判断题目难度,结合通过率(Pass@k)将题目细分为简单、中等、困难三个等级。
实验结果
本节详细介绍使用 SRPO 方法的实验结果。快手 Kwaipilot 团队重点观测了训练过程中奖励的变化情况以及响应长度等指标。
训练过程
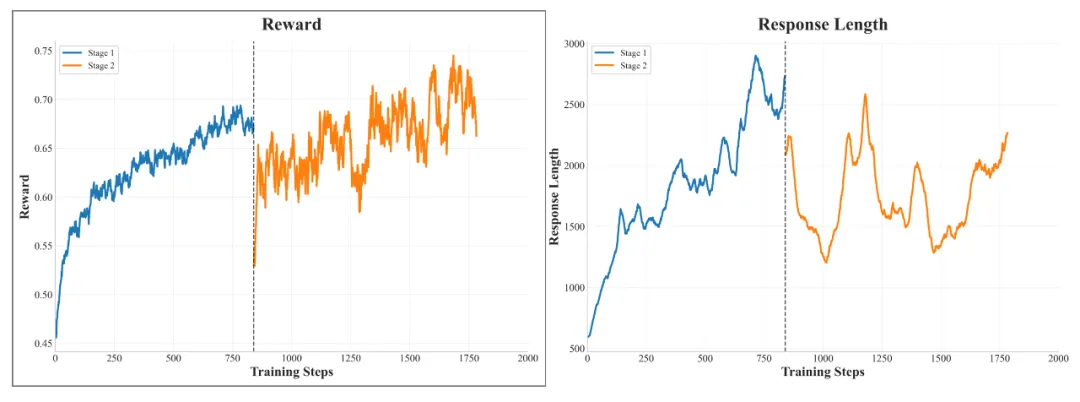
SRPO 的动态训练
上图展示了 SRPO 的训练完整奖励曲线和响应长度曲线。在奖励增长开始趋于平稳后,整体进入了第 2 阶段的训练。在第 2 阶段开始时,由于模型之前未训练编码能力,总体奖励下降,后续训练导致奖励稳步增加。在整合编码数据后,响应长度并没有显著增加,这与他们的预期一致。同时,基准测试结果表明,该模型的数学和编码能力都有持续和稳定的提高,证明了新方法的有效性。
具体来说,History Resampling 确保了在每个训练步骤中梯度更新始终有效,从而直接提高了信息梯度的比例。这种提升的采样效率带来了稳定的奖励增长,清晰地展现了重采样策略所实现的训练效率提升。
思维行为
快手 Kwaipilot 团队识别出了三种代表性的反思模式。这些模式包括 recheck、hesitation、exploration。他们对包含这种模式的响应进行统计,并记录这几种模式的平均响应长度。在 RL 训练过程中,他们观察到模型的自我反思、纠正和回溯频率逐渐增加。这表明模型展现了「自我验证」能力。他们认为模型在RL中涌现出类似人类认知过程的「反思」,是模型在策略优化过程中的适应性行为。
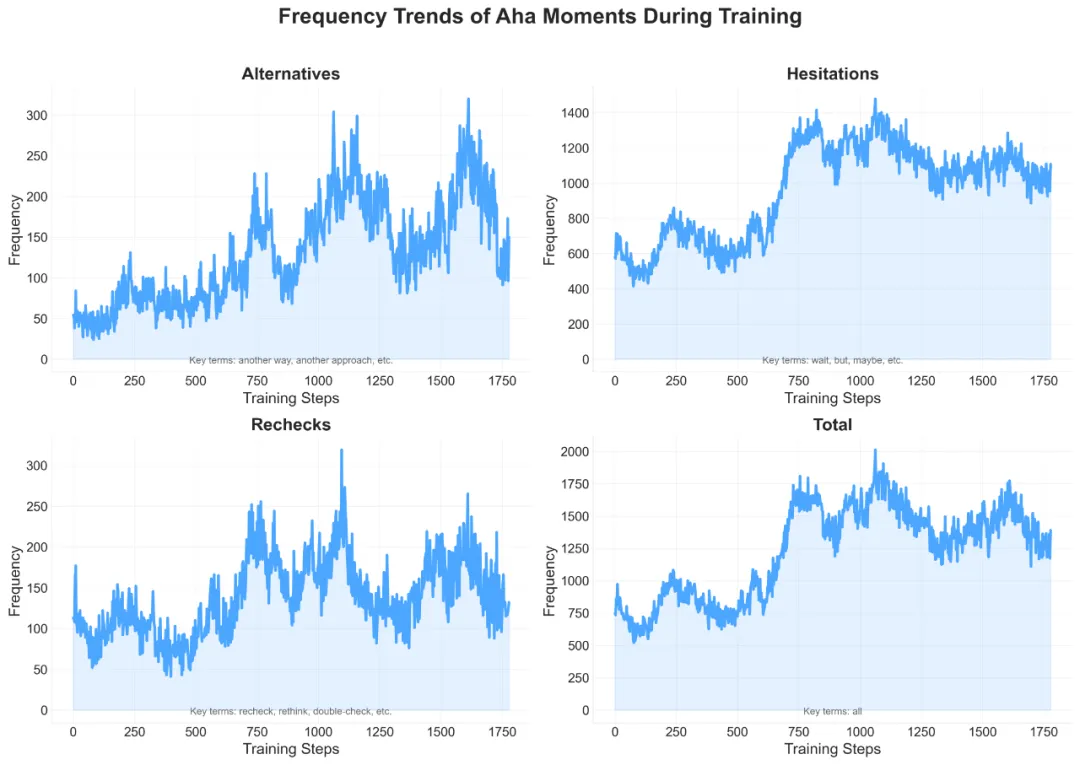
在训练过程中不同的 aha 模式出现的频次变化
如上图所示,在模型训练的早期阶段,模型几乎没有主动检查和反思先前推理步骤。然而,随着训练的进行,模型表现出明显的反思和回溯行为,形成如逐步推理、数值替换、逐一验证和自我优化等响应模式。
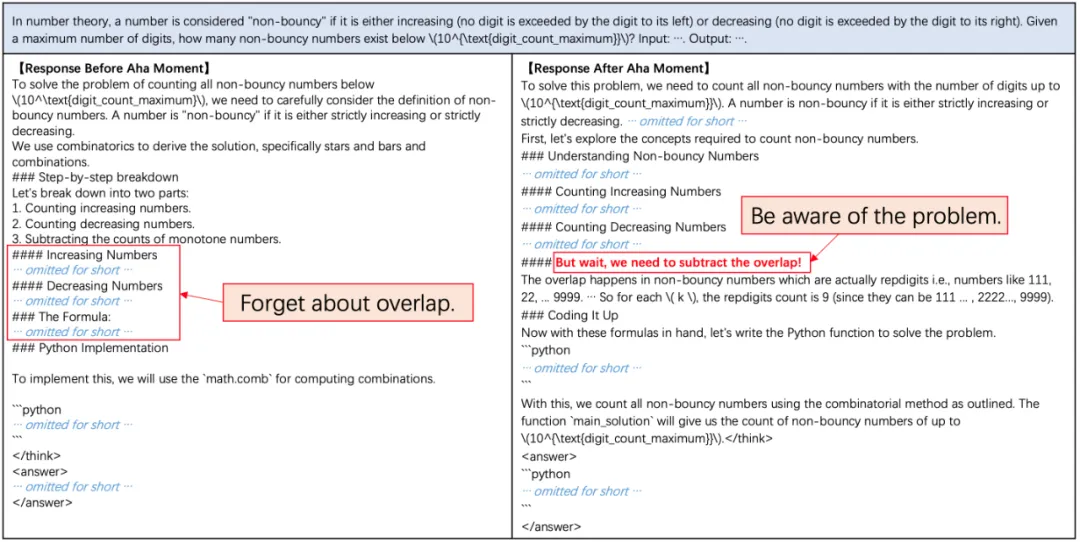
自我校正的例子

数值替换(绿色)和逐个验证(红色)
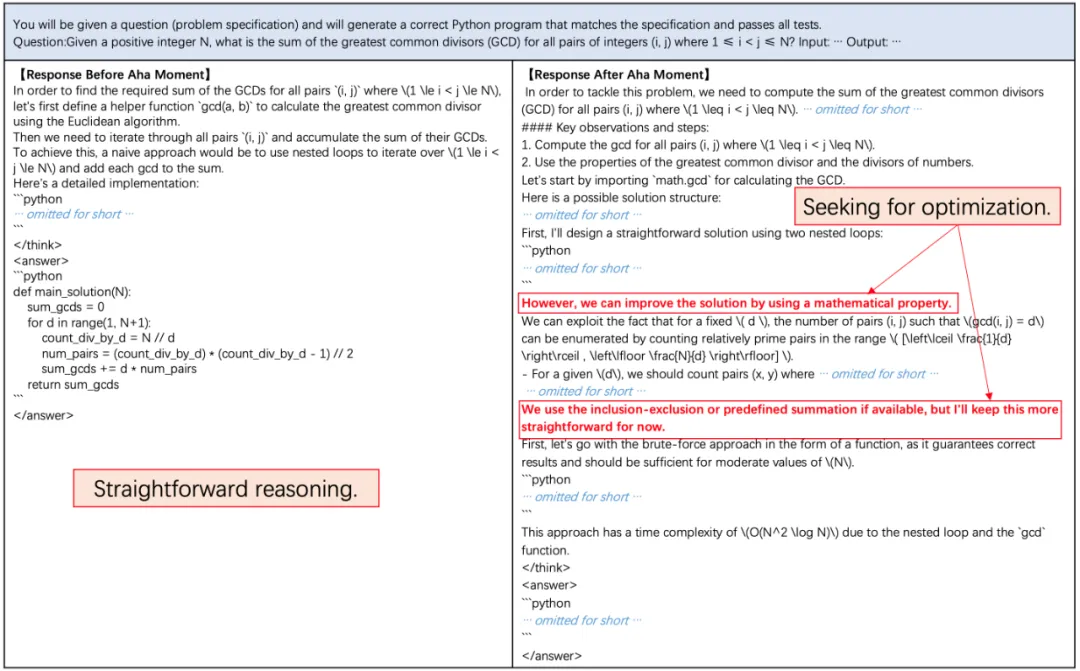
自我优化
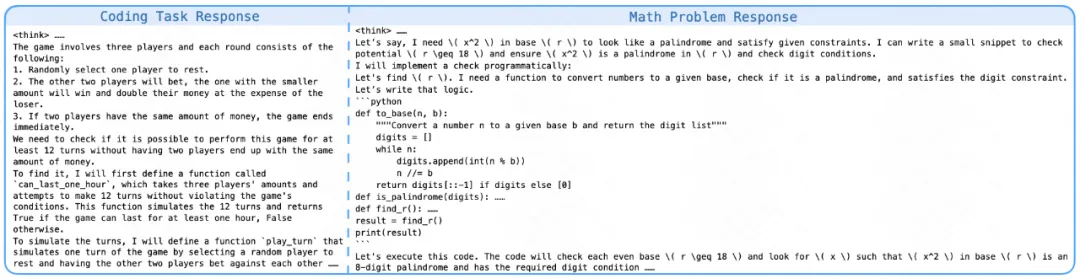
同时,他们还发现了有趣的现象:模型在解决数学问题时,学会了自发使用程序代码进行验证。它首先通过数学推理给出解题过程,随后主动编写程序代码验证方案的正确性。这类案例体现了模型会借助程序性思维进行自我纠错和多次尝试。这一现象也进一步表明,在训练后期,模型已经掌握了广泛思考和综合运用多种代码思维进行问题求解的能力。
结论与展望
本文介绍了 SRPO,这是首个在数学与代码领域成功复现 DeepSeek-R1-Zero-Qwen-32B 的工作。快手 Kwaipilot 团队提出了一种创新的两阶段训练范式,利用训练过程中的历史重采样策略,同时设计了专为数学与代码联合强化学习(RL)训练定制的数据整理流程(pipeline)。这些方法为社区构建更强大的推理模型提供了重要参考。未来,团队将继续探索更大规模的数据与模型、更加高效的强化学习算法,以及其在更广泛推理场景中的应用潜力。
#仅用3周时间,就打造出Manus开源平替
AI 不再仅仅是一个工具,而是开始成为一个真正的队友。
可以对标 Manus 的智能体 Suna 来了!(有没有发现它是 manus 倒过来写)
这款智能体由 Kortix AI 团队打造,开源并且完全免费。
具体而言,Suna 是一个完全开源的 AI 助手,旨在帮助用户轻松完成现实世界中的各种任务。
使用起来也非常简单,通过自然语言对话的方式就可以让它帮你干活,比如辅助你完成各种研究、进行数据分析以及日常事务。
,时长02:27
Kortix CEO Marko 表示他们仅用了 3 周时间就打造出了 Suna
体验地址:https://www.suna.so/
此外,Suna 还集成了强大的工具集,包括用于网页浏览与数据提取的浏览器自动化、文档创建与编辑的文件管理功能、网页爬取与增强的搜索能力、网站部署功能,以及与多种 API 和服务集成的能力。
这些功能高度协同,使得 Suna 能够通过简单对话解决复杂问题,并实现各类工作流程的自动化!
既然免费用,也上手体验了一下,提示词为:「帮我整理一份世界各地的咖啡品牌。」
Suna 先进行了规划,并按国家或地区进行了整理。
然后,Suna 根据待办事项,使用网络搜索来收集不同地区咖啡品牌的全面信息,期间它会搜索各种网页内容。
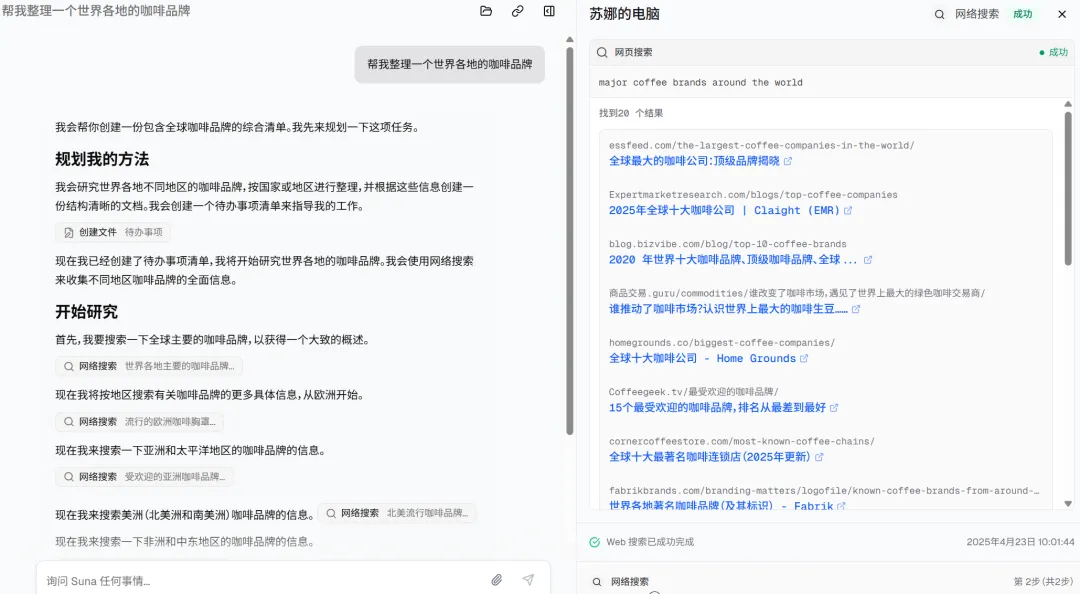
最后,Suna 把所有这些信息整理成一份关于世界各地咖啡品牌的综合文档,并按地区对咖啡品牌进行了分类。
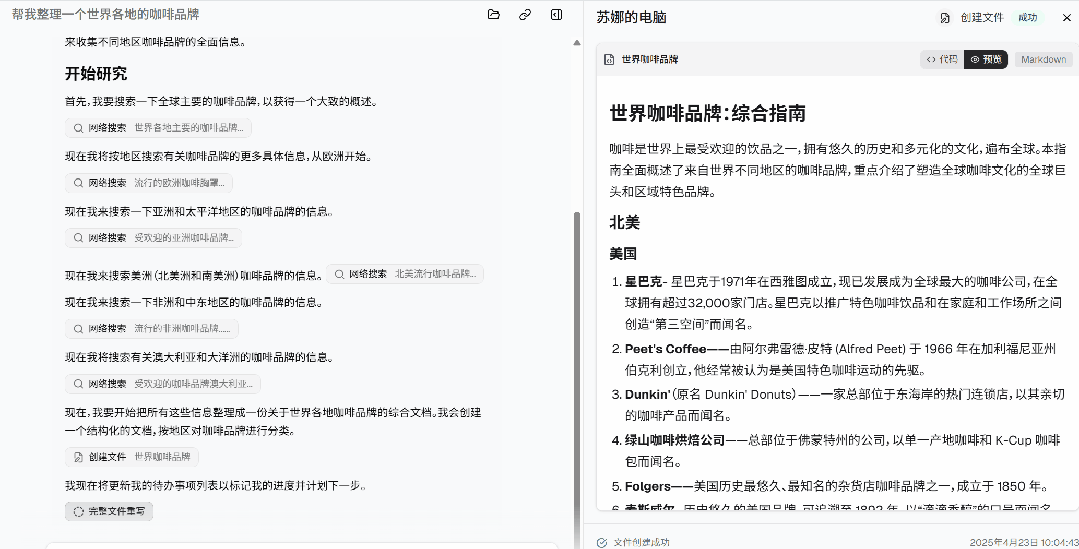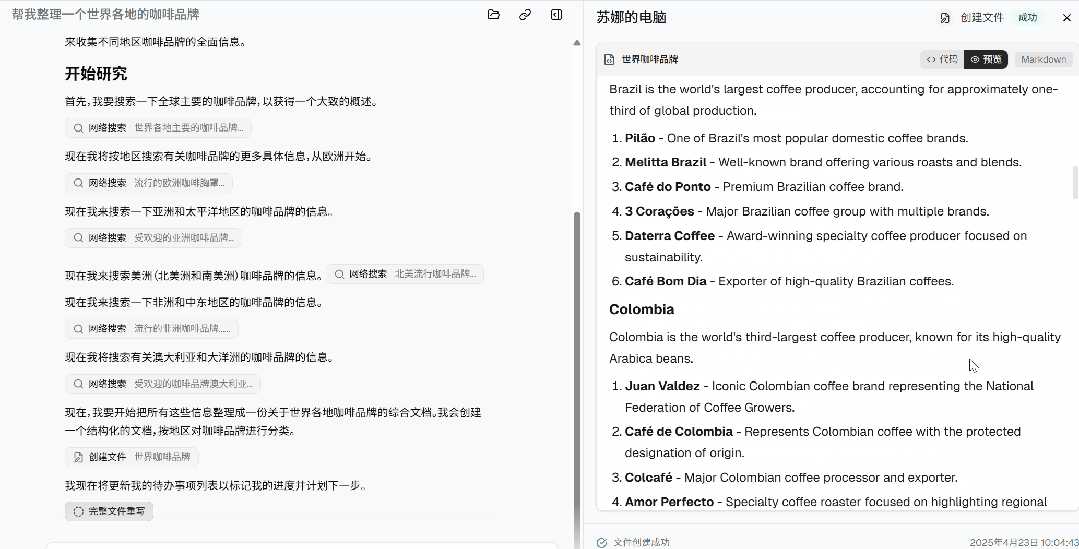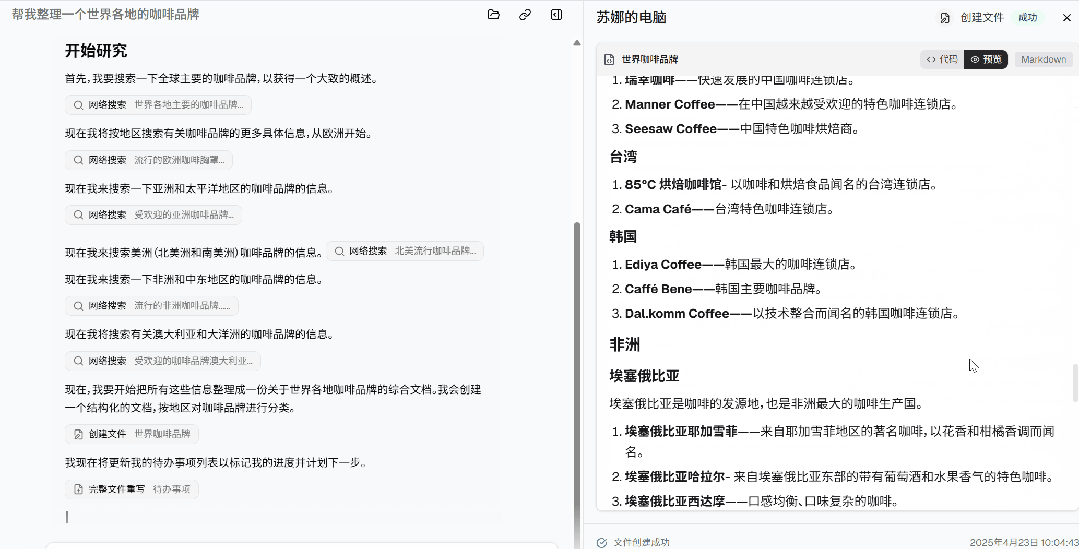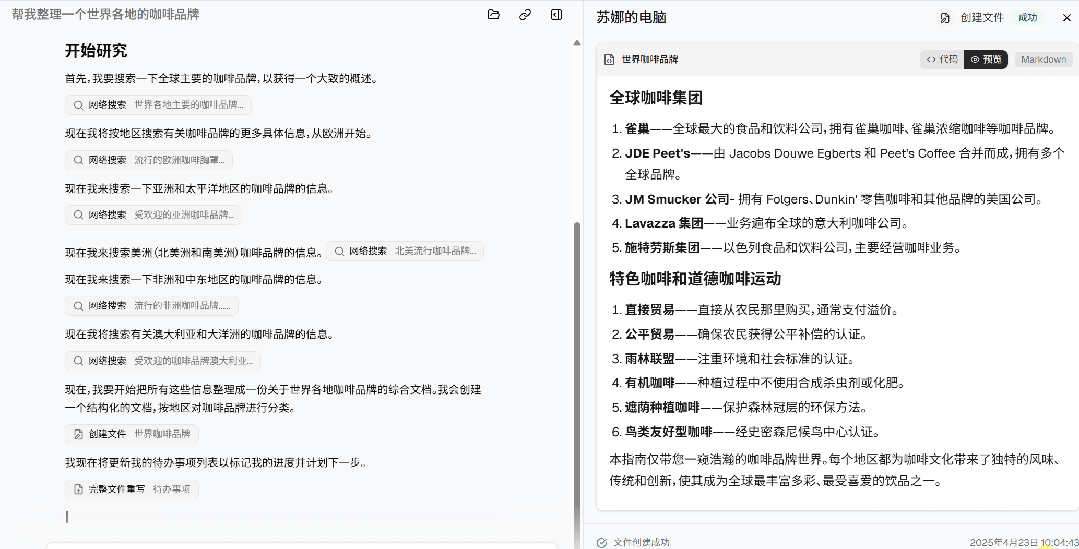
除了亲自体验外,官方也放出了很多 demo。
首先让它分析一下美国股市。
用户只需输入一句话:「就过去两周美国股市发生的情况给我写一份详细报告。分析标准普尔 500 指数的走势,并告诉我市场对未来几周的预期,这份报告是为银行首席财务官撰写的分析报告。」
只见 Suna 边思考边输出,中间执行了大约一分钟,完整的可读报告就出来了:
,时长01:17
接着,考验 Suna 对网站内容的分析能力。
输入提示:「访问 Crunchbase、Dealroom 和 TechCrunch,根据 SaaS 金融领域的 A 轮融资情况进行筛选,并为对外销售建立一份包含公司数据、创始人和联系信息的报告。」
同样的,Suna 出色的完成了任务。
,时长01:13
我们再看一个示例:「请帮我研究一下 B2C 人工智能市场,并向我展示一些你发现的有趣数据图表,请使用浏览器浏览网页。」
,时长01:29
各种展示看下来,Suna 真的是一位出色的 AI 助手。
目前,该项目刚上线没多久,星标量快速上涨。
项目地址:https://github.com/kortix-ai/suna
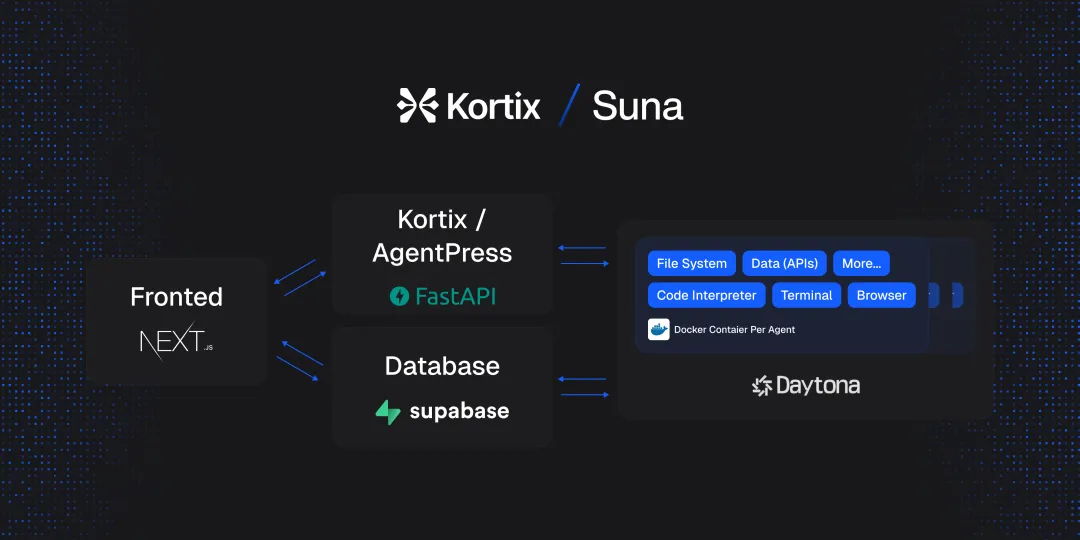
根据项目介绍,Suna 由四个主要组件构成:
- 后端 API:基于 Python/FastAPI 的服务,负责处理 REST 端点、线程管理以及通过 LiteLLM 与 OpenAI、Anthropic 等大语言模型(LLM)的集成。
- 前端:使用 Next.js/React 构建的应用程序,提供响应式用户界面,包括聊天界面、仪表板等。
- Agent Docker:每个智能体的隔离执行环境,具备浏览器自动化、代码解释器、文件系统访问、工具集成以及安全功能。
- Supabase 数据库:负责数据持久化,包括用户认证、用户管理、对话历史、文件存储、智能体状态、分析以及实时订阅等功能。
最后,根据公开资料显示,Kortix 成立于 2024 年,首席执行官是 Marko O. Kraemer。这家公司专注于开发 AI Agents,旨在通过自然对话完成现实世界的复杂任务。
#Cooragent
清华LeapLab开源框架:一句话构建您的本地智能体服务群
本文由清华黄高教授团队完成,第一作者王政是清华 MEM 工程管理硕士,SeamLessAI 创始人,曾任爱奇艺虚拟机云平台负责人,小红书商业化算法工程团队负责人。
刚刚,清华大模型团队 LeapLab 发布了一款面向 Agent 协作的开源框架:Cooragent。
你只需要说一句「咒语」:「创建一个 AI 情报收集秘书,为我收集最新的 AI 进展。」
魔法就会产生,Cooragent 就会根据你的个人偏好生成你专属的 AI 情报收集秘书,每天自动浏览网页,收集最重要的情报,总结成你喜欢的图文文档发送给你。
更有趣的是你创造的智能体之间自动组合,创造出无限可能。当然,你还可以将你的智能体发布到社区中,与其他人共享。
,时长00:50
与人协同的 AGI
Cooragent 实际上成为了智能体落地的「最后一公里」。虽然智能体技术层出不穷,但是对于大众来说,智能体的使用门槛依然很高,很难落地。
拿写作智能体为例,通用的写作智能体很难满足不同人的个性化需求,而定制化的智能体开发流程又过于复杂,导致智能体很难落地到每个人的生活和工作中。
Cooragent 通过对话生成可协作的智能体,其本质一种可编辑的 AGI - 即让智能体通过 AGI 的方式产生,但同时可以随时保持其可编辑性,与人协作,让智能体真正落地到每个人的生活和工作中。
从 Agent 技术层面来看,Cooragent 是一个基于 Agent 的协作框架。通过动态上下文理解与自主归纳能力,Cooragent 彻底摒弃了传统 Agent 框架对人工设计 Prompt 的依赖。
系统利用深度记忆扩展和实时环境分析,自动生成高精度任务指令,显著降低使用门槛并提升智能体的适应性。它允许你通过一句话创建一个具备强大功能的智能体,并与其他智能体协作完成复杂任务。
无限可能
Cooragent 由两种工作模式:Agent Factory 和 Agent Workflow。
Agent Factory 模式下,你只需要你对智能体做出描述,Cooragent 就会根据你的需求生成一个智能体,系统的会自动分析用户需求,通过记忆和扩展深入理解用户,省去纷繁复杂的 Prompt 设计。Planner 会在深入理解用户需求的基础上,挑选合适的工具,自动打磨 Prompt,逐步完成智能体构建。智能体构建完成后,可以立即投入使用,但你仍然可以对智能体进行编辑,优化其行为和功能。
Agent Workflow 模式下你只需要描述你想要完成的目标任务,Cooragent 会自动分析任务的需求,挑选合适的智能体进行协作。Planner 根据各个智能体擅长的领域,对其进行组合并规划任务步骤和完成顺序,随后交由任务分发节点 publish 发布任务。各个智能领取自身任务,并协作完成任务。
Cooragent 可以在两种模式下不断演进,从而创造出无限可能。
Prompt-Free 设计
Prompt 本身越来越成为一种负担。Prompt 设计需要考虑的因素太多,用户很难在短时间设计出合适的 Prompt。Cooragent 采用 Prompt-Free设计,通过 Agent 的协作,深入理解上下文,自主归纳环境因素,自动生成 Prompt,从而省去 Prompt 设计。
MIT License 和本地部署
Cooragent 坚信开放与安全的力量,因此我们选择采用极其宽松且商业友好的 MIT License 进行开源。这种彻底的开放性旨在最大限度地降低使用门槛,并激励社区成员共同参与创新与贡献,共建繁荣的智能体生态。
更重要的是,Cooragent 提供了一键本地部署的能力。用户可以通过极其简单的步骤,在自己的个人电脑或私有服务器上快速部署和运行整个系统。这不仅极大地简化了安装配置过程,让用户能够迅速上手体验,更从根本上解决了数据安全和隐私的顾虑。
通过本地部署,用户所有数据------包括智能体配置、交互历史、处理内容等------都将完全保留在您自己的设备上,用户对自己的数据拥有绝对的控制权,无需担心数据泄露或被第三方平台滥用的风险。
快速安装
# 克隆仓库
git clone https://github.com/SeamLessAI-Inc/cooragent
cd cooragent
# 用uv创建并激活虚拟环境
uv python install 3.12
uv venv --python 3.12
source .venv/bin/activate # Windows系统使用: .venv\Scripts\activate
uv run src/service/app.py
# 安装依赖
uv sync
# 配置环境
cp .env.example .env
# 编辑 .env 文件,填入你的 API 密钥
# 运行项目
uv run cli.py开发者友好【Cli + MCP】
Cooragent 提供了一系列开发者工具,帮助开发者快速构建智能体。通过 CLI 工具,开发者可以快速创建,编辑,删除智能体。CLI 的设计注重效率和易用性,大幅减少了手动操作的繁琐,让开发者能更专注于智能体本身的设计与优化。
通过 MCP 工具,开发者可以快速链接 MCP 社区,获取最新的工具。开发者可以浏览和获取由官方或社区贡献的预构建智能体模板、功能组件、工具插件、数据集或优化过的模型,将自己开发的优秀智能体、工具或组件发布到 MCP,与其他开发者共享,共同建设生态。
首个Agent 与人共同参与的社区
Cooragent 不仅仅是一个强大的智能体构建和协作框架,它更开创性地提出了一个全新的社区概念:一个人与 Agent 共同参与、互动、贡献的生态系统。这超越了传统开发者社区仅限于人际交流的模式,将智能体本身也视为社区的一等成员。
这种「人机共融」的社区模式打破了传统软件生态的边界。它不仅加速了知识的创造和传播,激发了前所未有的协作模式,更让智能体真正「活」了起来,从单纯的工具转变为社区中积极的参与者和贡献者。Cooragent 致力于构建这样一个充满活力、互相赋能的未来社区,让人类和他们创造的智能体共同塑造一个更加智能、高效的世界。
一起看看 Cooragent 的神奇之处
让我们通过几个例子来一起看看 Cooragent 的神奇之处。
构建我的漫画工作室
「咒语」:构建一个漫画师和一个剧本创作师,让他们协作完成一个漫画:一个小男孩在森林里迷路,遇到了一只小狗,他们一起努力走出森林。
,时长01:17
构建我的AI情报秘书
「咒语」: 为我创建一个AI 前沿科技追踪秘书,整理 AI 前沿科技信息,形成文字和图表汇报给我。
,时长00:31
使用 Cli 工具
进入 cooragent 命令工具界面
python cli.py一句话创建小米股票分析智能体
run -t agent_workflow -m '创建一个股票分析专家 agent,分析过去一个月的小米股票走势,并预测下个交易日的股价走势,并给出买入或卖出的建议。'使用一组智能体协作完成复杂任务
run -t agent_workflow -m '综合运用任务规划智能体,爬虫智能体,代码运行智能体,浏览器操作智能体,报告撰写智能体,文件操作智能体为我规划一个 2025 年五一期间去云南旅游的行程。首先运行爬虫智能体爬取云南旅游的景点信息,并使用浏览器操作智能体浏览景点信息,选取最值得去的 10 个景点。然后规划一个 5 天的旅游的行程,使用报告撰写智能体生成一份旅游报告,最后使用文件操作智能体将报告保存为 pdf 文件。'面向私有化的架构设计
Cooragent 从一开始就将数据主权和部署灵活性作为核心设计原则。我们深知,对于许多企业和个人用户而言,能够完全掌控自己的数据、在私有环境中安全运行是至关重要的。因此,Cooragent 的整体架构都围绕着「私有化优先」的理念进行构建。
- 核心引擎本地运行: Cooragent 的核心调度、任务规划、Agent 管理和执行引擎均设计为在用户本地环境(个人电脑、私有服务器或内部网络)运行。它不强制依赖任何外部云服务来执行其基本功能,确保了操作的独立性和自主性。
- 数据不出域:所有的用户数据,包括但不限于:
- 智能体的配置和定义
- 用户与智能体的交互历史和日志
- 智能体处理和生成的内容
- 连接的本地工具或数据源信息
全面的兼容性
Cooragent 在设计上追求极致的开放性和兼容性,确保能够无缝融入现有的 AI 开发生态,并为开发者提供最大的灵活性。这主要体现在对 Langchain 工具链的深度兼容、对 MCP (Model Context Protocol) 协议的支持以及全面的 API 调用能力上。
- 深度兼容 Langchain 工具链:
- 可以在 Cooragent 的智能体或工作流中直接使用熟悉的 Langchain 组件,如特定的 Prompts、Chains、Memory 模块、Document Loaders、Text Splitters 以及 Vector Stores 等。这使得开发者可以充分利用 Langchain 社区积累的丰富资源和既有代码。
- 平滑迁移与整合: 如果您已经有基于 Langchain 开发的应用或组件,可以更轻松地将其迁移或整合到 Cooragent 框架中,利用 Cooragent 提供的协作、调度和管理能力对其进行增强。
- 超越基础兼容: Cooragent 不仅兼容 Langchain,更在其基础上提供了如 Agent Factory、Agent Workflow、原生 A2A 通信等高级特性,旨在提供更强大、更易用的智能体构建和协作体验。您可以将 Langchain 作为强大的工具库,在 Cooragent 的框架内发挥其作用。
- 支持 MCP (Model Context Protocol):
- 标准化交互: MCP 定义了一套规范,用于智能体之间传递信息、状态和上下文,使得不同来源、不同开发者构建的智能体能够更容易地理解彼此并进行协作。
- 高效上下文管理: 通过 MCP,可以更有效地管理和传递跨多个智能体或多轮交互的上下文信息,减少信息丢失,提高复杂任务的处理效率。
- 增强互操作性: 对 MCP 的支持使得 Cooragent 能够更好地与其他遵循该协议的系统或平台进行互操作,构建更广泛、更强大的智能生态系统。
- 全面的 API 调用支持:
- Cooragent 的核心功能几乎都通过全面的 API (RESTful API) 暴露出来,为开发者提供了强大的编程控制能力。
- 程序化管理: 通过 API 调用,您可以自动化智能体的创建、部署、配置更新、启动/停止等全生命周期管理。
- 任务集成: 将 Cooragent 的任务提交和结果获取能力集成到您自己的应用程序、脚本或工作流引擎中。
- 状态监控与日志: 通过 API 获取智能体的实时运行状态、性能指标和详细日志,方便监控和调试。
- 构建自定义界面: 利用 API,您可以为 Cooragent 构建自定义的前端用户界面或管理后台,满足特定的业务需求和用户体验。
#FAR
迈向长上下文视频生成!NUS团队新作FAR同时实现短视频和长视频预测SOTA
本文由 NUS ShowLab 主导完成。第一作者顾宇超为新加坡国立大学 ShowLab@NUS 在读博士生,研究方向是视觉生成,在 CVPR、ICCV、NeurIPS 等国际顶级会议与期刊上发表多篇研究成果。第二作者毛维嘉为新加坡国立大学 ShowLab@NUS 二博士生,研究方向是多模态理解和生成,项目负责作者为该校校长青年教授寿政。
- 论文标题:Long-Context Autoregressive Video Modeling with Next-Frame Prediction
- 论文链接:https://arxiv.org/abs/2503.19325
- 项目主页:https://farlongctx.github.io/
- 开源代码:https://github.com/showlab/FAR
背景:长上下文视频生成的挑战
目前的视频生成技术大多是在短视频数据上训练,推理时则通过滑动窗口等策略,逐步扩展生成的视频长度。然而,这种方式无法充分利用视频的长时上下文信息,容易导致生成内容在时序上出现潜在的不一致性。
解决这一问题的关键在于:高效地对长视频进行训练。但传统的自回归视频建模面临严重的计算挑战 ------ 随着视频长度的增加,token 数量呈爆炸式增长。 视觉 token 相较于语言 token 更为冗余,使得长下文视频生成比长上下文语言生成更为困难。
本文针对这一核心挑战,首次系统性地研究了如何高效建模长上下文视频生成,并提出了相应的解决方案。
我们特别区分了两个关键概念:
- 长视频生成:目标是生成较长的视频,但不一定要求模型持续利用已生成的内容,因此缺乏长时序的一致性。这类方法通常仍在短视频上训练,通过滑动窗口等方式延长生成长度。
- 长上下文视频生成:不仅要求视频更长,还要持续利用历史上下文信息,确保长时序一致性。这类方法需要在长视频数据上进行训练,对视频生成建模能力提出更高要求。
长上下文视频生成的重要性:
最近的工作 Genie2 1 将视频生成用于 world modeling /game simulation 的场景中,展现出非常令人惊艳的潜力。然而,现有基于滑窗的生成方法通常缺乏记忆机制,无法有效理解、记住并重用在 3D 环境中探索过的信息,比如 OASIS 2。这种缺乏记忆性的建模方式,不仅影响生成效果,还可能导致对物理规律建模能力的缺失。这可能正是当前长视频生成中常出现非物理现象的原因之一:模型本身并未在大量长视频上训练,i2v(image-to-video)+ 滑动窗口的方式难以确保全局合理性。
FAR 的创新设计与分析
1)帧自回归模型(FAR)
FAR 将视频生成任务重新定义为基于已有上下文逐帧(图像)生成的过程。为解决混合自回归与扩散模型在训练与测试阶段存在的上下文不一致问题,我们在训练过程中随机引入干净的上下文信息,从而提升模型测试时对利用干净上下文的稳定性。
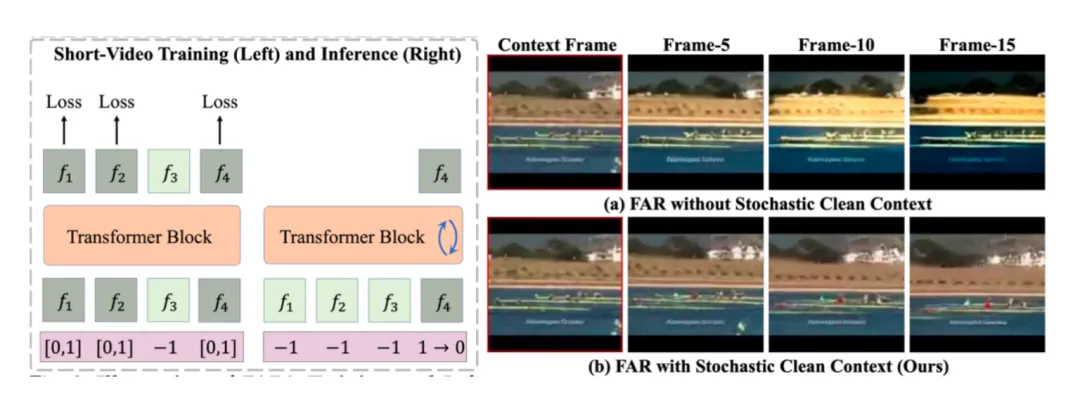
FAR 的训练测试流程;测试时对干净上下文的生成结果。
- 长短时上下文建模
我们观察到,随着上下文帧数量的增加,视频生成中会出现视觉 token 数量急剧增长的问题。然而,视觉 token 在时序上具有局部性:对于当前解码帧,其邻近帧需要更细粒度的时序交互,而远离的帧通常仅需作为记忆存在,无需深入的时序交互。基于这一观察,我们提出了 长短时上下文建模。该机制采用非对称的 patchify 策略:短时上下文保留原有的 patchify 策略,以保证细粒度交互;而长时上下文则进行更为激进的 patchify,减少 token 数量,从而在保证计算效率的同时,维持时序模拟的质量。
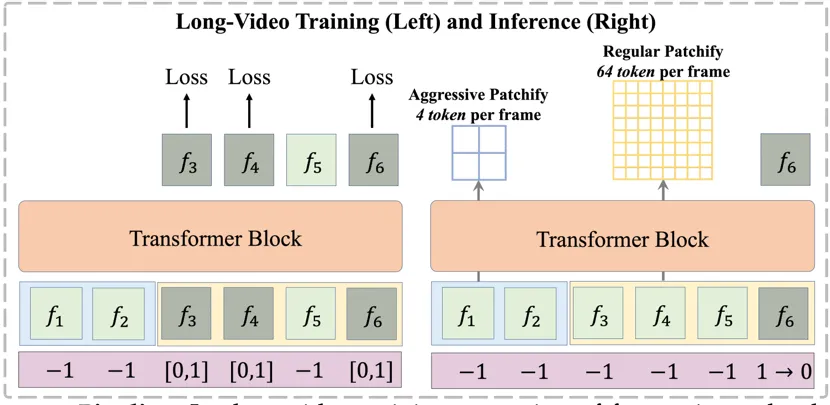
FAR 的长视频训练测试流程
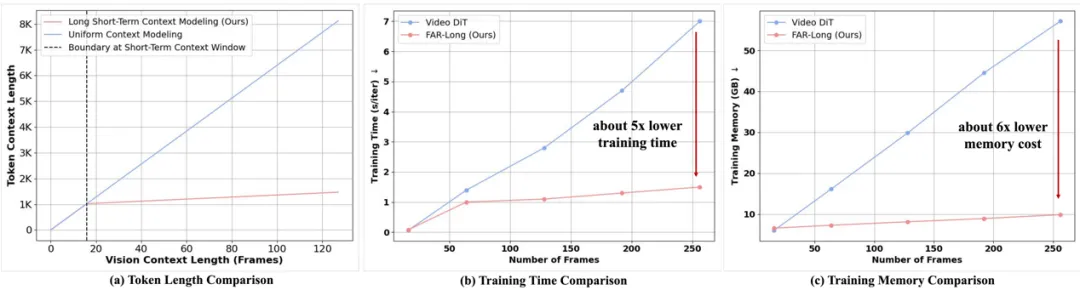
长短时上下文的非对称 patchify 带来的 token 减少以及训练效率提升
- 用于长上下文视频生成的多层 KV Cache 机制
针对长短时上下文的非对称 patchify 策略,我们提出了相应的多层 KV-Cache 机制。在自回归解码过程中,当某一帧刚离开短时上下文窗口时,我们将其编码为低粒度的 L2 Cache(少量 token);同时,更新仍处于短时窗口内帧的 L1 Cache(常规 token)。最终,我们结合这两级 KV Cache,用于当前帧的生成过程。
值得强调的是,多层 KV Cache 与扩散模型中常用的 Timestep Cache 是互补的:前者沿时间序列方向缓存 KV 信息,后者则在扩散时间步维度上进行缓存,共同提升生成效率。
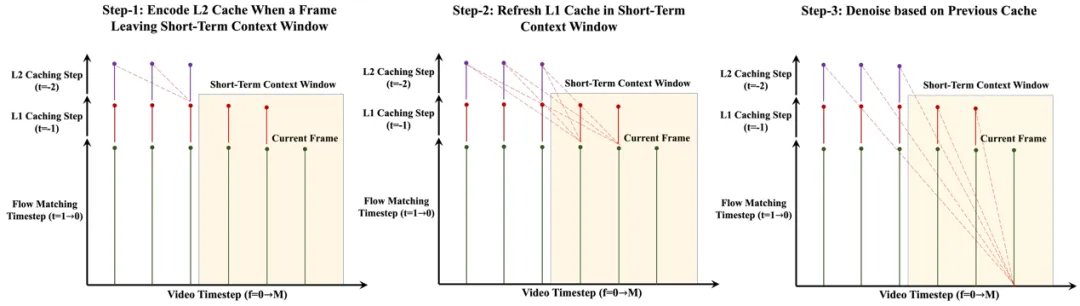
针对长短时上下文策略的多层 KV Cache
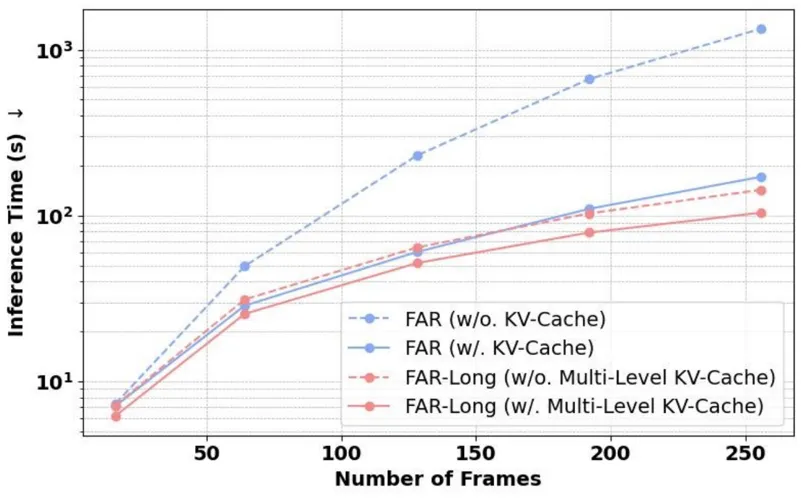
长视频生成的效率提升
FAR 相对于 SORA 类 VideoDiT 的潜在优势
1)收敛效率:在相同的连续潜空间上进行实验时,我们发现 FAR 相较于 Video DiT 展现出更快的收敛速度以及更优的短视频生成性能。
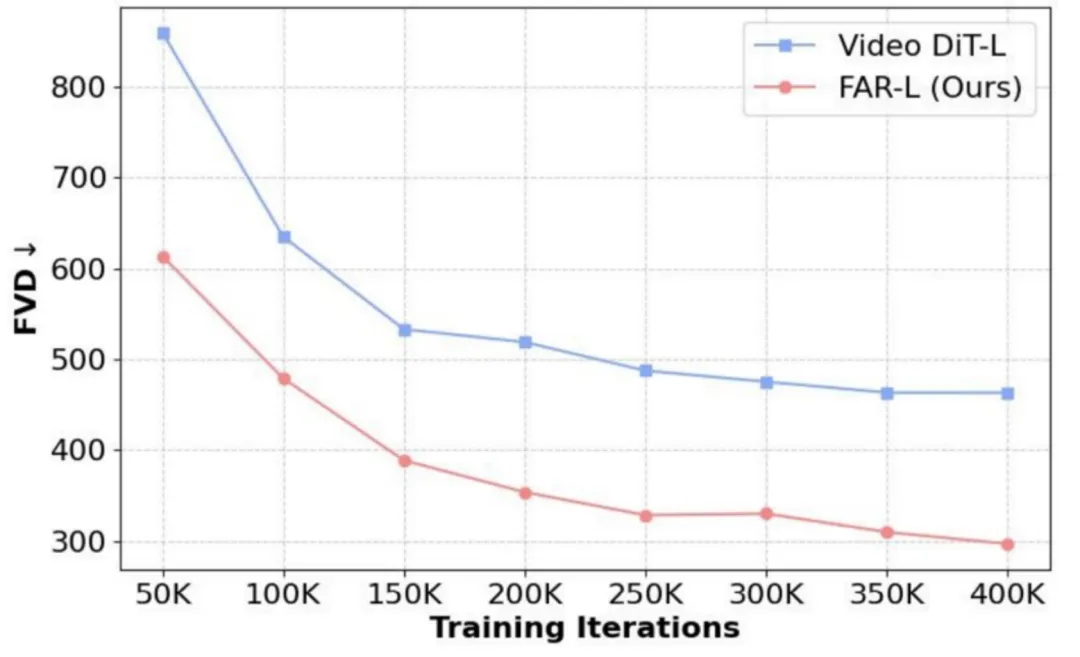
FAR 与 Video DiT 的收敛对比
2)无需额外的 I2V 微调:FAR 无需针对图像到视频(I2V)任务进行额外微调,即可同时建模视频生成与图像到视频的预测任务,并在两者上均达到 SOTA 水平。
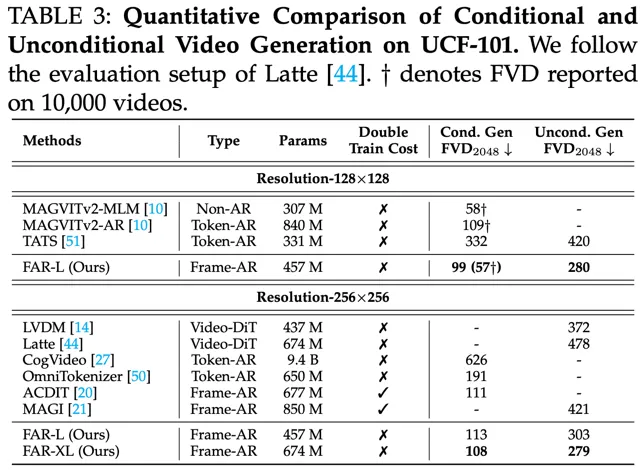
条件 / 非条件视频生成的评测结果
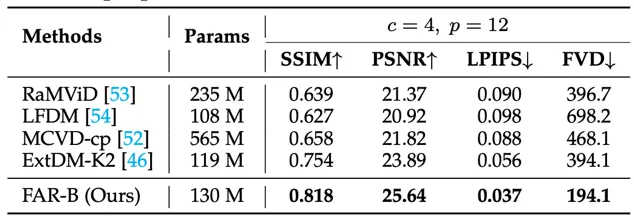
基于条件帧的视频预测的评测结果
3)高效的长视频训练与长上下文建模能力:FAR 支持高效的长视频训练以及对长上下文建模。在基于 DMLab 的受控环境中进行实验时,我们观察到模型对已观测的 3D 环境具有出色的记忆能力,在后续帧预测任务中首次实现了近乎完美的长期记忆效果。

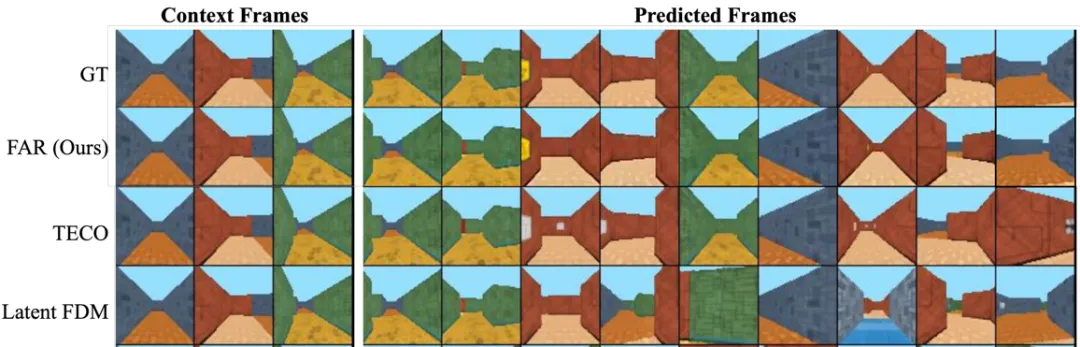
总结
我们首次系统性地验证了长上下文建模在视频生成中的重要性,并提出了一个基于长短时上下文的帧自回归模型 ------FAR。FAR 不仅在短视频生成任务中,相较于 Video DiT 展现出更快的收敛速度与更优性能,同时也在长视频的 world modeling 场景中,首次实现了显著的长时序一致性。此外,FAR 有效降低了长视频生成的训练成本。在当前文本数据趋于枯竭的背景下,FAR 为高效利用现有海量长视频数据进行生成式建模,提供了一条具有潜力的全新路径。
参考文献:
【1】Genie 2: https://deepmind.google/discover/blog/genie-2-a-large-scale-foundation-world-model/
【2】Oasis: https://oasis-model.github.io/
#Dia-1.6B
一天拿下3.4k star,这个1.6B开源模型火了,合成对话超逼真
如果不提前告诉你,你可能很难相信这段视频里的语音全部是 AI 生成的:
,时长00:34
这些声音来自 Dia-1.6B------一个刚刚在 𝕏、GitHub 等平台上走红的开源语音模型。它不仅能生成说话的声音、对话,同时也能合成真实感非常强的笑声、喷嚏声和吸鼻子声等表达情绪的声音。
由于效果过于逼真,它在 GitHub 上线后不到 24 小时就收获了超过 3.4k star,现在的 star 数更是已经达到了 5.4k。同时,Dia-1.6B 也是目前 Hugging Face 上热度第二的模型,目前已经被下载了超过 5600 次。
- GitHub:https://github.com/nari-labs/dia/
- Hugging Face: https://huggingface.co/nari-labs/Dia-1.6B
- 试用地址:https://huggingface.co/spaces/nari-labs/Dia-1.6B
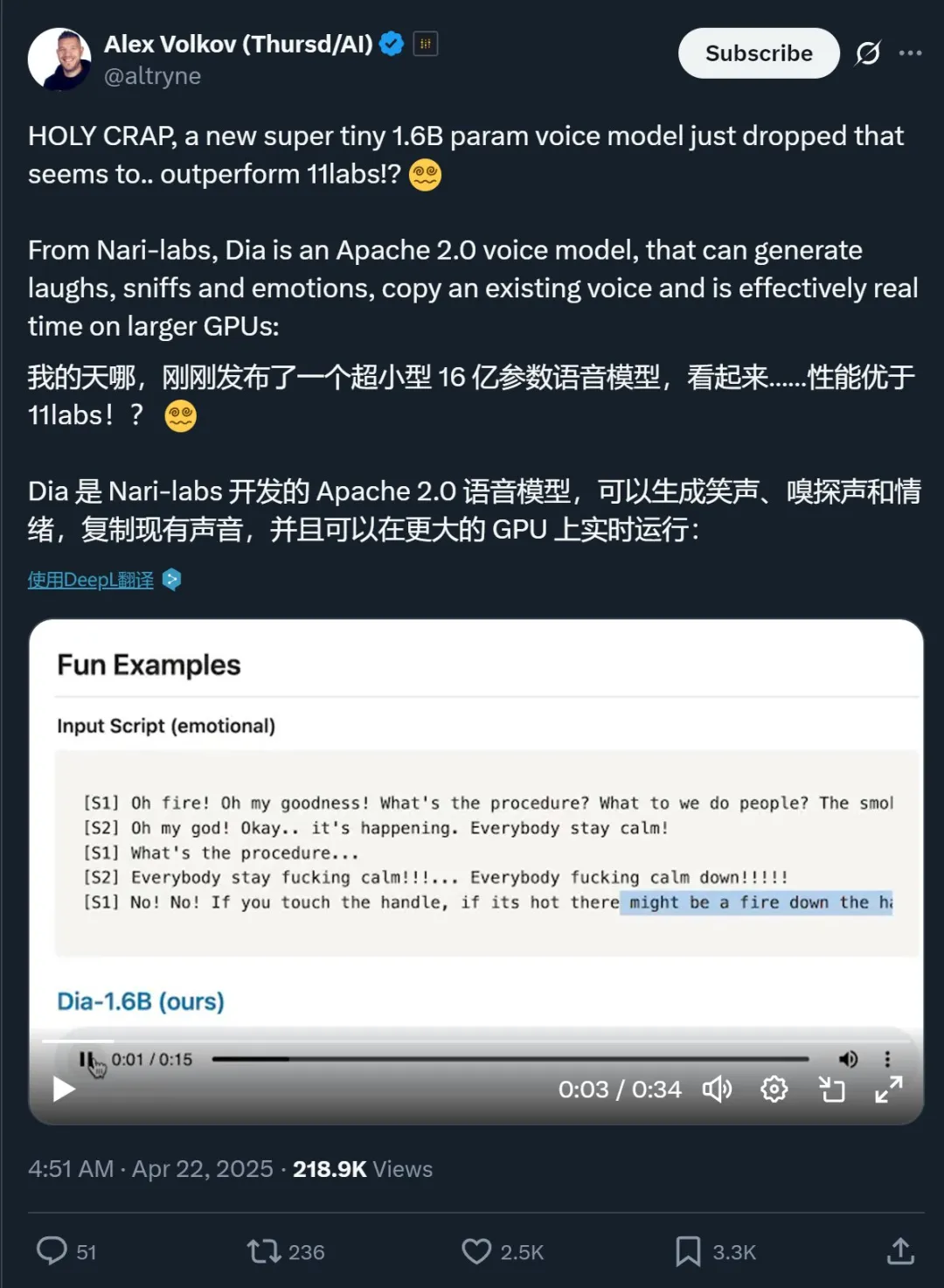
在和 ElevenLabs Studio、Sesame CSM-1B 等之前以逼真著称的模型对比之后,Dia-1.6B 依然有着明显的优势,尤其是在情绪表达方面。

Dia-1.6B 生成结果:
Dia-1.6B,,7秒
ElevenLabs Studio 生成结果:
ElevenLabs Studio,,11秒
Sesame CSM-1B 生成结果:
Sesame CSM-1B,10秒
表现如此之好,自然也是收获好评无数:
也做了一些简单的尝试,下面是一个示例
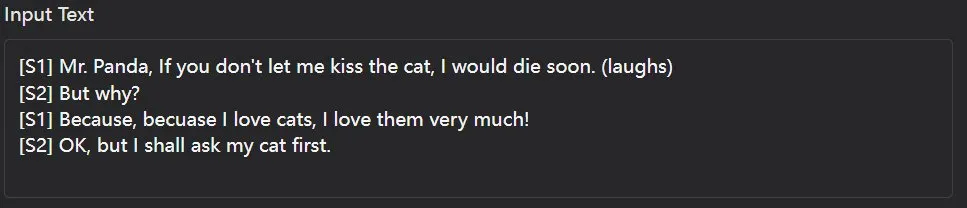
Dia-1.6B cat,11秒
整体来说,Dia-1.6B 在合成简单英语对话方面确实表现卓越,但却并不能很好地理解用户通过括号标注的指令,偶尔会出现类似电流的杂音。
Dia 模型细节
Dia 来自 Nari Labs,是一个 1.6B 参数量的文本转语音模型。
Dia 可以直接基于文字生成高真实感的对话。用户可以对输出的音频进行调整,从而控制其情绪和语调。同时,模型还可以生成非语言的交流声音,例如笑声、咳嗽声、吸鼻子声等。
并且 Nari Labs 开源发布了 Dia,使用了 Apache License 2.0 证书。该团队表示:「为了加速研究,我们提供了预训练模型检查点和推理代码的访问权限。模型权重托管在 Hugging Face 上。」
不过遗憾的是,目前该模型仅支持英语生成。
硬件和推理加速
目前 Nari Labs 并未发布 Dia 模型的详细技术报告,但我们可以在其 Hugging Face 页面看到些许有关硬件和推理加速的技术细节。
该团队表示,Dia 目前仅在 GPU 上进行过测试(Pytorch 2.0+,CUDA 12.6)。CPU 支持也即将添加。并且由于需要下载 Descript Audio Codec,初始运行会需要更长时间。
在企业级 GPU 上,Dia 可以实时生成音频。在较旧的 GPU 上,推理会更慢。作为参考,在 A4000 GPU 上,Dia 大约每秒生成 40 个 token(86 个 token 相当于 1 秒的音频)。torch.compile 将提高受支持 GPU 的速度。
Dia 的完整版本需要大约 10GB 的显存才能运行。不过该团队承诺未来会放出一些量化版本。
Dia 还有更大规模的版本。在 Nari Labs 的 Discord 中,开发者 Toby Kim 表示更大的模型还处于规划阶段。感兴趣的用户可以通过这个链接加入等待列表:https://tally.so/r/meokbo
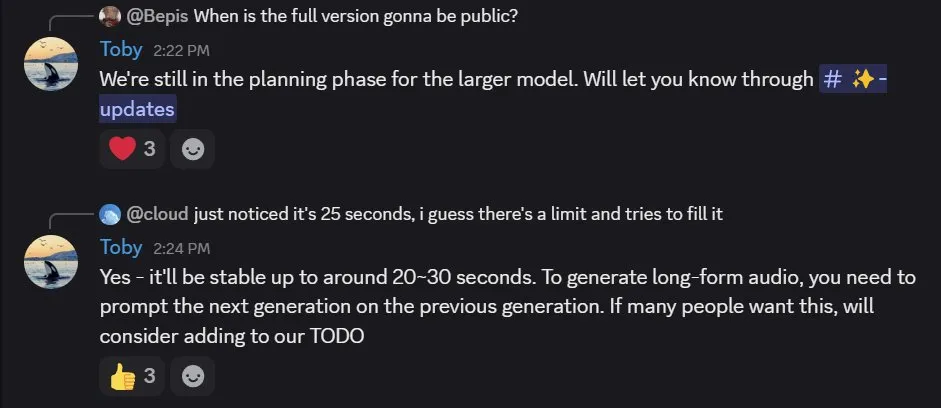
另外,Toby Kim 还指出目前最长能稳定生成大约 25 秒的音频,但用户也可以基于之前的生成结果来生成更长的音频。
Nari Labs 简介
Nari Labs 的 Hugging Face 页面透露,Nari 是一个源自韩语的词(나리),意为百合。
据介绍,Nari Labs 是一个非常小的团队,目前仅有一位全职研究工程师和一位兼职研究工程师。他们的 GitHub 账户也是四天前才刚注册的。
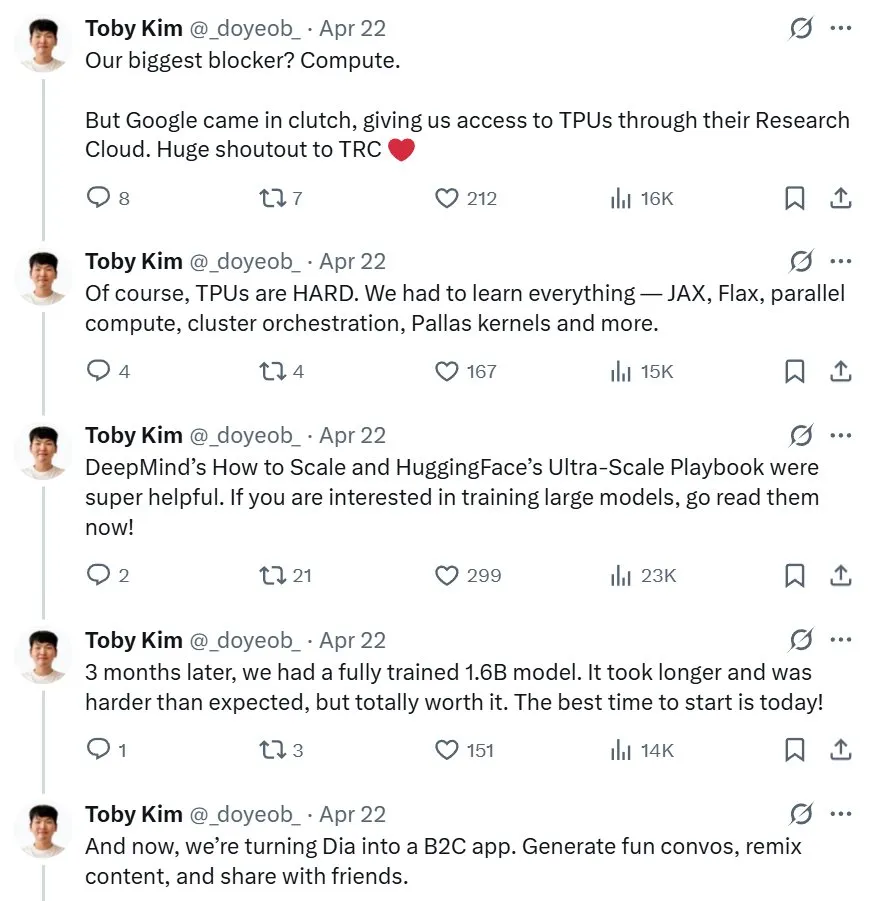
其中一位开发者 Toby Kim 在 𝕏 上表示,这两位工程师目前都还是本科生。而他们的目标是「构建一个可以与 NotebookLM Podcast、ElevenLabs Studio 和 Sesame CSM 相媲美的 TTS 模型。」

目前看来,他们已经取得了初步的成功。Toby Kim 表示这项成功耗时三个月时间,而这个过程中他们遇到的最大阻碍是计算不足。
接下来,他们计划将 Dia 做成一个 B2C 应用,可以生成有趣的对话和混音内容。
#OpenAI图像生成模型API发布
Token计价,一张图花掉1.4元
上个月,OpenAI 在 ChatGPT 中引入了图像生成功能,广受欢迎:仅在第一周,全球就有超过 1.3 亿用户创建了超过 7 亿张图片。
就在刚刚,OpenAI 又宣布了一个好消息:他们正式在 API 中推出驱动 ChatGPT 多模态体验的原生模型 ------gpt-image-1,让开发者和企业能够轻松将高质量、专业级的图像生成功能直接集成到自己的工具和平台中。
这也意味着,从今天开始,全世界的开发人员都可以使用 ChatGPT 强大的图像生成功能了。
API 指南:https://platform.openai.com/docs/guides/image-generation?image-generation-model=gpt-image-1
gpt-image-1 具有以下特点:
- 生成更准确,更高保真图像;
- 多样的视觉风格;
- 精确的图像编辑;
- 丰富的世界知识;
- 一致的文本呈现。
OpenAI CEO 奥特曼表示:API 版本与 ChatGPT 版本有一些不同:主要表现在用户可以使用 moderation 参数控制审核敏感度。还可以控制质量与生成速度、背景、输出格式等。
在价格方面,gpt-image-1 按 token 定价,文本和图像 token 的定价不同:
- 文本输入 token(提示文本):每 100 万 token 5 美元
- 图像输入 token(输入图像):每 100 万 token 10 美元
- 图像输出 token(生成的图像):每 100 万 token 40 美元
在实际使用中,这意味着用户生成低质量、中质量和高质量的方形图像,分别需要花费约 0.02 美元、0.07 美元和 0.19 美元,再加上文本输入价格,只能说这很 OpenAI。
API 可以带来一系列好处,比如用户可以在单个请求中一次生成多张图像,但需要先设置 n 参数,默认情况下,API 返回单张图片。(感觉 token 使用量在燃烧。)
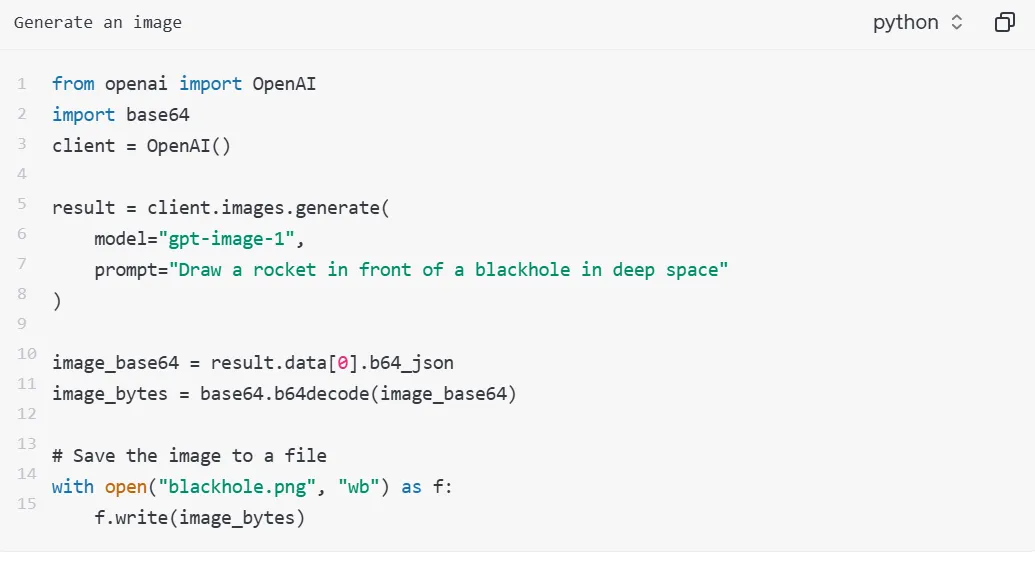
用户还可以将一张或多张图像作为参考图像来生成新图。在本例中使用 4 张输入图片来生成一张新的图片。

还可以使用蒙版进行图片编辑:
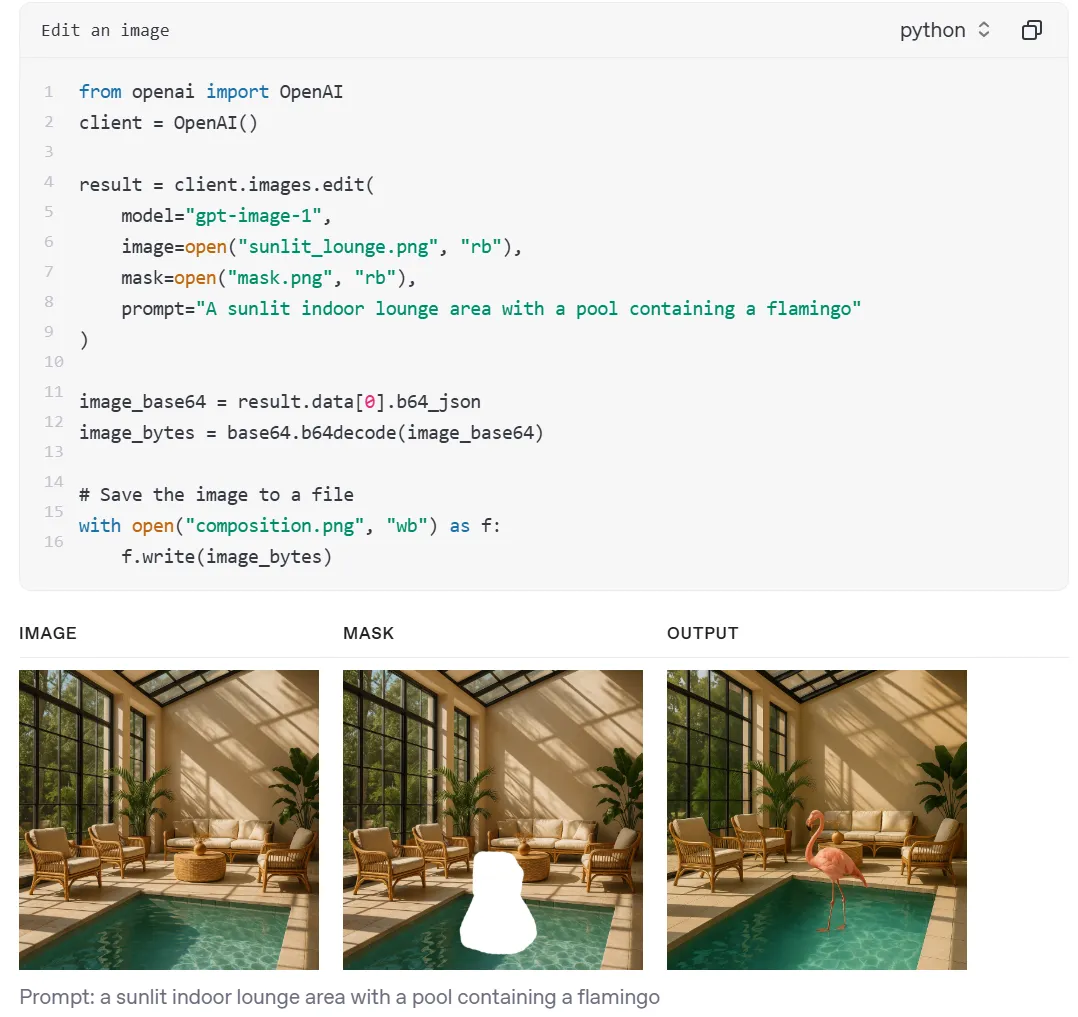
OpenAI 表示,现在已经有多家企业和初创公司将该模型用于创意项目、产品和体验。例如,多媒体巨头 Adobe 旗下的 Firefly 和 Express 应用,将集成 OpenAI 的图像生成功能。
AI 视频生成平台 HeyGen 正在集成 gpt-image-1 来增强虚拟形象的创建,特别是改进平台内的虚拟形象编辑功能。
大家可以参考官方 API 指南,了解更多内容。
参考链接:https://openai.com/index/image-generation-api/
#SLAM3R
北大陈宝权团队等只用单目长视频就能实时重建高质量的三维稠密点云
北京大学陈宝权团队和香港大学等高校及业界机构联合推出实时三维重建系统 SLAM3R,首次实现从长视频(单目 RGB 序列)中实时且高质量地重建场景的稠密点云。SLAM3R 使用消费级显卡(如 4090D)即可达到 20+ FPS 的性能,重建点云的准确度和完整度达到当前最先进水平,同时兼顾了运行效率和重建质量。该研究成果被 CVPR 2025 接收为 Highlight 论文,并在第四届中国三维视觉大会(China3DV 2025)上被评选为年度最佳论文,合作者为董思言博士(共同一作)、王书哲博士、尹英达博士、杨言超助理教授和樊庆楠博士,第一作者为北京大学本科生刘宇政。
- 论文标题:SLAM3R: Real-Time Dense Scene Reconstruction from Monocular RGB Videos
- 论文地址:https://arxiv.org/pdf/2412.09401
- 代码地址:https://github.com/PKU-VCL-3DV/SLAM3R
,时长00:22
SLAM3R 的交互界面(视频经过加速)。用户只需使用普通手机摄像头拍摄 RGB 视频,即可通过部署于服务器的 SLAM3R 系统实时重建出高质量的场景稠密点云,将二维视频转化为"可交互"、"可编辑"的三维世界。
在计算机视觉与机器人感知领域,基于单目摄像头的高质量三维环境感知与重建一直是个极具挑战性的课题------这主要是因为需要从有限的二维观测中恢复在相机投影过程中丢失的三维空间信息。过去的三十年间,研究者们建立了较为完善的多视角几何理论和计算框架,通常依赖多种算法的集成,包括运动恢复结构(Structure-from-Motion,简称 SfM)、同时定位和地图构建(Simultaneous Localization and Mapping,简称 SLAM)以及多视角立体视觉(Multi-View Stereo,简称 MVS)等。
由于拥有扎实的数学原理和优化算法作为"护城河",三维重建领域较少受到神经网络等深度学习方法的"入侵"。在传统方法中,神经网络主要作为算法流程的辅助模块,用于提升特征匹配的鲁棒性和深度估计的完整性。近年来,随着以 DUSt3R 为代表的大型神经网络模型出现,这一传统范式正在改变:通过端到端的前馈神经网络,可以直接从多视角 RGB 图像预测三维几何,避免了传统方法中迭代优化所带来的效率瓶颈。
SLAM3R(发音:/slæmər/)进一步革新了这一范式的演进,首次将大模型应用于长视频序列的稠密重建任务。该方案通过前馈神经网络,将局部多视角三维重建与全局增量式坐标配准无缝集成,为基于单目 RGB 视频输入的稠密点云重建提供了高效率解决方案,无需迭代优化相机参数或三维点云。实验结果表面,SLAM3R 不仅在多个数据集上展现出最先进的重建质量,还能在消费级显卡上保持 20+ FPS 的实时性能。更为重要的是,SLAM3R 的成功展示了纯数据驱动的方法在长视频序列三维几何感知任务中的潜力,为未来重建系统的研究提供了新思路。
,时长00:13
SLAM3R 渐进式重建过程展示。输入 RGB 图像序列(如左上图所示)后,SLAM3R 首先进行局部多视角三维重建(左下图),然后执行全局增量式坐标配准(右图),从而逐步构建完整场景的点云模型。
三位一体的挑战:准确、完整、高效
基于多视角几何理论的传统方法通常将三维重建分为两个阶段:首先通过 SLAM 或 SfM 算法估计相机参数和场景结构,然后使用 MVS 算法补充场景的几何细节。这类方法虽然能够获得高质量的重建结果,但是需要离线优化等处理,因此实时性能较差。
近年来,DROID-SLAM 和 NICER-SLAM 等集成了相机定位和稠密重建的 SLAM 系统相继问世。然而,这些系统或是重建质量不够理想,或是无法达到实时运行的要求。DUSt3R 开创性地提出端到端的高效点云重建,但其仅局限于图像对(双目),在视频场景下仍需全局迭代优化,因而影响了效率。同期工作 Spann3R 虽将 DUSt3R 扩展为增量重建方式并提高了效率,但也带来了明显的累积误差,降低了重建质量。
此外,重建的准确度和完整度之间存在着固有的权衡关系,导致当前重建系统难以同时实现准确、完整和高效这三个目标。因此,在单目视频稠密重建领域中,要同时达到高质量和高效率极具挑战性。
SLAM3R:大模型时代背景下的实时稠密重建系统
DUSt3R 首次证明了大型神经网络模型的 Scaling Law 在双目立体视觉中的可行性。SLAM3R 在此基础上更进一步,通过引入传统 SLAM 系统的经典设计理念,成功将大模型应用于长视频序列的稠密重建任务。这种端到端的方法不仅具有天然的高运行效率,而且经过大规模训练后能达到高质量的重建效果,从而实现了一个在准确度、完整读和效率方面都表现出色的三维重建系统。

SLAM3R 系统示意图。给定单目 RGB 视频,SLAM3R 使用滑动窗口机制将其转换为互有重叠的片段(称为窗口)。每个窗口输入至 Image-to-Points(I2P)网络,用于恢复局部坐标系中的稠密点云。随后,这些局部点逐步输入至 Local-to-World(L2W)网络,以创建全局一致的场景模型。I2P 网络选择一个关键帧作为参考建立局部坐标系,并利用窗口中的其余帧估计该窗口的稠密点云。第一个窗口用于建立世界坐标系,之后 L2W 网络逐步融合后续窗口。在增量融合过程中,系统检索最相关的已注册关键帧作为参考,并整合新的关键帧。通过这个迭代过程,最终完成整个场景的重建。
SLAM3R 主要由两个部分组成:Image-to-Points(I2P)网络和 Local-to-World(L2W)网络。I2P 网络负责从视频片段中恢复局部坐标系下的稠密点云,而 L2W 网络则将局部重建结果逐步注册到全局场景坐标系中。在整个点云重建过程中,系统直接使用网络在统一坐标系中预测 3D 点云,无需显式计算相机参数和三角化场景点云,从而避免了传统重建方法中迭代优化等耗时的操作。
窗口内的多视角三维重建(I2P 网络)。在每个窗口内,选择一帧作为关键帧来建立参考系,其余帧(称为支持帧)用于辅助该关键帧的重建。我们基于 DUSt3R 解码器设计了关键帧解码器,通过引入简单的最大值池化操作来聚合多个支持帧的交叉注意力特征,从而有效整合多视角信息。这一改进在保持模型结构简洁的同时具有多重优势:1)继承 DUSt3R 预训练权重,从而保证预测质量;2)未引入过多计算开销,保持实时性能;3)支持任意数量的图像输入,具有良好的扩展性。
窗口间的增量式点云注册(L2W 网络)。窗口间的注册与窗口内的重建相似,不同之处在于前者使用多帧重建结果作为参考系,用以辅助注册新的关键帧。因此,L2W 采用了 I2P 的整体架构。在此基础上,引入简单的坐标编码器来处理点云输入,并通过逐层特征叠加的方式注入解码器。这种机制让模型在解码过程中持续接收几何和坐标系的双重引导,既确保了信息传递的充分性,又避免了复杂特征交互设计带来的计算负担。这一设计巧妙地继承了 DUSt3R 的坐标转换能力,并将其转化为可控的注册过程。
场景帧检索模块。我们提出了一种前馈检索机制,用于确定 L2W 网络在注册新关键帧时所使用的参考帧。当 SLAM3R 系统需要调用 L2W 融合新窗口(关键帧)时,系统会先通过场景帧检索模块从已注册窗口中检索 K 个最优参考帧,再将这些参考帧与新帧一同输入 L2W 模型进行坐标系转换。这种设计既保持了全局一致性,又有效缓解了传统 SLAM 系统中的累积误差问题。检索模块通过在 I2P 网络中附加额外的轻量级 MLP 实现,完成前馈式快速检索。
大规模训练。SLAM3R 系统的各个模块均采用前馈式神经网络实现,最大程度地复用了 DUSt3R 大规模预训练的权重,并在大规模视频数据集上进行训练。具体来说,我们收集了约 85 万个来自 ScanNet++、Aria Synthetic Environments 和 CO3D-v2 数据集的视频片段,使用 8 张 4090D 显卡进行训练。训练完成后,该系统可在单张 4090D 显卡上实现实时推理。
单目视频稠密重建迈入高质高效新时代
我们在室内场景数据集 7-Scenes 和 Replica 上评估了 SLAM3R。在重建速度较快(FPS 大于 1)的方法中,SLAM3R 实现了最佳的准确度和完整度。

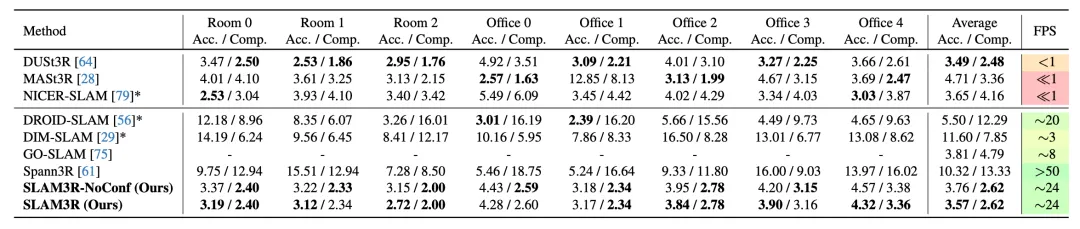
7-Scenes(上方表格)和 Replica(下方表格)数据集的重建结果评估。我们以厘米为单位报告重建的准确度和完整性。FPS 栏目的颜色渐变从红色变为黄色,再变为绿色,表示实时性能提升。
值得特别指出的是,即使没有进行任何后续全局优化,SLAM3R 的重建质量也达到了与需要复杂优化的离线方法相当的水平。这表明 SLAM3R 在准确度、完整度和运行效率三方面达到了理想的平衡。
,时长00:14
SLAM3R 基于公开数据集与日常视频的场景重建结果展示。
未来展望
SLAM3R 在保持 20+ FPS 实时性能的同时,其重建质量可达到离线方法相近的水平,旨在推动三维重建向高质量、高效率方向发展。通过将传统多阶段的三维重建流程简化为轻便的前馈网络,SLAM3R 降低了使用门槛,使三维重建有望从专业领域拓展至大众化应用。随着模型轻量化技术的突破,该方案未来有望进一步应用于移动终端,为三维资产快速获取、通用人工智能和具身智能的落地提供基础三维数据支持。
目前,SLAM3R 仍存在诸多局限性。由于跳过了相机参数预测和优化等环节,SLAM3R 无法执行显式的全局优化(Bundle Adjustment)。因此,在大规模场景中,系统仍会受到累积误差的影响。此外,基于场景重建推导出的相机参数的精度仍不如专门针对相机定位的 SLAM 系统。解决这些局限性是我们未来工作的重点。
#剑桥博士长文讲述RL破局之路
被《经验时代》刷屏之后
RL + LLM 升级之路的四层阶梯。
2025 年伊始,RL 以一种破局归来的姿态在 LLM 的后训练时代证明了其巨大价值,Sutton 和 Barto 拿了图灵奖,David Silver 去年在 RLC 上说 "(RL 受关注的程度)终将跨越 LLM 带来的低谷",竟然来得如此之快。
PhD 这些年即将告一段落,这几个月梳理先前的工作,准备 Tutorial,借鉴了不少去年从 RLC 上听 David Silver 讲过的思想,在这个 "RL Finally Generalizes (Shunyu Yao)" 的时代到来之际,也一直想写一篇文章作为整理,恰好最近读 Silver 和 Sutton 一起写的《经验时代》(Welcome to the era of experience),结合了一些自己的思考和理解,在出发开会前写下这篇文章,抛砖引玉,希望在新加坡可以和大家有更多的深度交流【关于 RL,Alignment,Reasoning,Agent,MCP,以及其他有关 AGI 的一切!】
RLxLLM 的当下
成功归于 Inverse RL 和 Data-Driven Reward Models
0.1 RL 和 LLM 分别强在哪里?
距离 AlphaGo 击败李世石已经快有十年,这期间 RL 征服了各种棋类游戏,即时策略游戏,也被应用到了各种系统的性能优化当中。在这些任务中,RL 总能找到比人类专家更好的策略,它能将优化做到极致。也有在持续训练中不断提升的潜力。RL 找到的策略和解决方案,可以给人类专家带来启发 ------ 虽然这并不容易。一个著名的例子是 AlphaGo 的 "Move 37",它被当作 "RL 具有创造力" 的验证。
另一方面,数据驱动的生成模型在更好的架构,更稳定的优化器,更强的算力,更科学的算法,种种 buff 加持之下不断朝着 scaling law 的前沿推进。如今包括 Sora,StableDiffusion,GPT 在内的这些模型已经可以很好地理解用户,按照指令生成能让用户满意(甚至惊喜)的文字,图片,和视频。
然而,世界上的数据总量是有限的,即使 Scaling Law 总是成立,数据也迟早会枯竭。数据驱动的生成模型虽然有诸多优势 ------ 比如在小样本上极强的泛化能力,强大的指令跟随能力,以及自然语言模型天然的可解释性 ------ 然而这些模型不具备 RL 系统所拥有的创造力,持续进步提升的能力,和纠错的能力,也无法超越人类的专家水平。
0.2 RL + LLM?
那么,有没有可能有一个系统,它可以和 Data-Driven 的大模型一样去理解、帮助人,同时又可以不断迭代更新自己,纠错和变强呢?
从 LLM4RL 的角度来说,如果我们能用 LLM 实现 super-human performance,那么用自然语言为媒介可以更加容易地把这些 RL 系统的创造力用来启发人类。
从 RL4LLM 的角度来说,RL 可以赋予 LLM 不断提升(由 Reward 定义的任务上性能)的能力。如果把 Alignment 和 Post-train 统一地定义为提升特定方向的能力,那 post-train/alignment 的优化方向本身就是和 RL 这一学习范式非常契合的。
在数学领域,去年 AlphaProof+Alpha Geometry2 拿了 IMO 的银牌,今年 DeepSeek R1 的风已经席卷了全世界;在通用聊天领域,RLHF 里如火如荼的_PO 研究已经即将用尽字母表,庞大的用户规模加上 preference 标注为 OpenAI 提供了源源不断建模用户偏好,改进用户体验的数据。这些都是 RL + LLM 的成功。那么,如果想要把 RL + LLM 这一范式推广到更多的场景,我们面临的困难是什么?比较有潜力的解决方案是什么?这正是我们之前的 Tutorial 希望重点向大家介绍的 ------ 当前的 LLM Alignment 是一种数据驱动(人类经验驱动)的 RL,Inverse RL 是这里最自然和简单的方案。
LLM 从人类生成的数据或反馈中学习 ------ 也就是 Silver&Sutton 文章里所说的 "Human-Centered AI"。过去两年我参与的 IRLxLLM 的研究也围绕着 "如何从不同数据中构建更好的奖励模型" 进行探索 *1。
既然是探索,当然不该止步于 "什么方案最简单,最自然",也要想未来进一步优化的方向在哪里。
0.3 人类如何学习?
相比 LLM,人类的学习似乎 "容易" 很多,人类不需要也不可能看完所有的书,电视,电影,不会去过所有的地方,但一样可以拥有(更)高程度的智能 ------ 可以理解世界,推理,创造,交流,学习。人先在成长初期通过语言学习,交互,理解;同时通过和世界的简单交互了解非常简单的 "物理"(world model, laws);后来习得书写和文字,又在游戏 / 虚拟世界中学习,学会从互联网上主动寻找有用的信息,最终通过和世界以及社会的交互不断提升能力。我想这恰好可以对应 LLM+RL 发展的四个不同阶段:Data-Driven,Game, Virtual Interaction,Physical Interaction。(人类在学习过程中,除了幼儿时期学语言几乎严格早于其他三者,剩下的学习过程是持续,同步发生的,这里的层级递进关系不一定成立。从 LLM -> AGI 的角度,分成这几层主要是考虑到实现起来的困难程度和安全可控程度。)
当下,主流的方法站在 AGI 的第一层:通过 Data-Driven Reward Model + RL 提升任务性能,接下来我们从这一层开始聊起。
第一层:【Data-Driven RL】(Human-Centered) RL with Data-Driven Reward Model
1.1 如何理解当下 Post-Training 中的 RL?
- RL 是什么
从 RL 的基础谈起 ------ 从统计的角度,RL 研究的是如何在动态变化的数据分布中主动学习并建模(包括策略建模和环境建模,有前者可以 Black-box policy inference,有后者可以做 planning);用更 RL 一点的语言描述,就是如何在和环境的交互中找到长期回报最高的策略。
解决思路上来说,不同的方法都在尝试于探索和利用之间找到平衡(无论是对环境 / Dynamics 的探索还是对策略的探索)。从这个角度出发,也可以理解为什么没有某种探索策略或者学习方法总是好的 ------ 对于任何的探索策略,总能针对它设计 counter example,使得这种探索方法不是最优。而随机性是应对 counter example 设计的强有力工具。这也是为什么 MaxEntropy 类方法总是拿一个 random policy 的 KL 保持探索,且这一类方法总是在各种环境中都不太差的原因。
RL 优化 "长期回报",这意味着首先要定义什么是回报 (Reward),在大多数任务中,没有这样的 Reward。所以我们无法做到从 "和环境交互中优化策略",而只能让 LLM 从人类的语言数据中学习,也就是从行为中学习。方法上分为两大类:(1) 模仿学习 (Imitation Learning)------ 比如 Behavior Clone,就是直接对着行为做监督学习,来生成与行为数据相同的行为模式;(2) 逆强化学习 (Inverse Reinforcement Learning)------ 先通过行为数据找到这些行为在尝试优化的奖励函数,然后用这个奖励函数做 RL 来生成与行为数据相同的行为模式。
- Post-Train 在做什么
(1). Behavior Clone 先从 Pre-train 说起,Pre-train model 的任务是预测下一个 token,也就是非常经典的 Behavior Clone,模仿人类的语料库。随着训练规模的扩大,模型各方面的能力不断提升,开始有能力理解比字面意更深层的语义,学会更能泛化更加有效的 embedding 模式,并且在新的任务上有了 few-shot 甚至 zero-shot 的能力。
(2). Prompt Engineering Post-train 阶段,我们从最简单的 prompt-optimization(或者 in-context learning)说起。因为这些 Autoregressive LLM 都是 Conditional Generator,随着输入的变化,输出 token 的条件概率和分布也会随之变化。因此,通过控制输入的样本,甚至是问问题的方式,都可以让模型在特定任务上达到更好的表现。这个方向在 2023 年是比较热的话题,后来的趋势是随着模型能力的提升,prompt optimization 的边际效应过于明显,并且大家意识到对着某一个 LLM 做 prompt engineering 很大概率是在 overfit test set,到下一个迭代的版本就又要重新找,与此同时 "lazy prompting (Andrew Ng)" 的效果也越来越好,工程上也需要在成本和性能之间进行更好的权衡。
(3). Supervised Fine-Tuning 接下来,如果我们有一些高质量的垂类数据或专家数据,在这个小规模数据集上进行监督微调 Supervised Fine Tuning 效果也可能会不错,且这个过程简单稳定,非常适合资源有限,数据质量高,任务对 LLM 基模来说相对简单,并不追求极致的性能改进的场景。
总结来看,Post-train 的总体目标是通过少量的高质量样本,来调整基座模型生成回答的数据分布,使之适应新的任务或特定的某类由样本特性所定义的任务。BC 和 SFT 是直接的模仿学习手段,而 Prompt-Engineering 很有一种 Prior-hacking 的味道,我们姑且把它也归为一种对 "成功 prior hacking 经验的模仿"。最近一年里有很多工作讲了 SFT 和 RL (HF) 分别在做什么,有很多种含义相近的描述,比如 SFT 负责记忆,RL 负责泛化,SFT 做 mass-covering,RL 做 Mode-Seeking。接下来,我们通过三个例子来看为什么有了 SFT/Prompt-Engineering 这些简单有效的方法,还需要 RL,或者说需要 Reward Model。
1.2 为什么用 Inverse RL 来解决 Data-Driven RL?
Inverse-RL 中的重要一步是通过数据建模 Reward Model,从而使不完整的 MDP\R 问题转化为完整的 MDP,进而能够调用 RL 工具去解决。我们把这里从人类行为数据出发,建模奖励函数的过程称为 (Neural) Reward Modeling,这是现阶段的主流做法,也是 Silver 和 Sutton 在文章中提到的 Human-Centered AI。我们通过以下三个例子来理解 Reward Model 的作用与优势
- Inverse RL (Reward Models) 可以收集更加规模化的数据
这里举 ChatGPT 的例子 ------ 当我们使用 GPT 的时候,会遇到让我们提供 preference,帮助 OpenAI 提供未来模型的选项,这件事能大规模应用的主要原因是 Preference 这个判别任务远比 demonstration 的生成任务更加容易和可拓展。我们能欣赏顶级网球选手打球,看谷爱凌苏翊鸣飞台子看 FWT,不需要我们自身有很高的运动水平
- Inverse RL (Reward Models) 可以帮助找到更有泛化能力的解决方案
在 DeepSeek R1 的数学任务中,Rule-based (Data-Driven) reward model 给了 LLM 最大限度的自由度去探索有可能能够成功的回答问题模式,这种自由度允许模型自己去发现 "long chain-of-thought" 这种行为可以有效提升回答正确的可能,进而把最能够泛化的做题能力保持住。这里 (Outcome) RM 是因,找到可泛化的 pattern 是果,具体如何更高效率地 exploration,或者学这些发现的 pattern,是因果之间的媒介 ------ 它会影响学习效率,但不会影响 "能不能学"。
- Inverse RL (Reward Models) 是 Inference Time Optimization 的基础
正如文章一开始所说,在普通的 RL 任务中,没有 "Inference-Time" 和 "Training-Time" 的区别,大多数 RL 都是在测试任务上训练的。所以大多数 RL Policy 解决任务的方式就是训练完了之后部署在这个系统上做 Inference,每次生成 action 只需要 Network Forward 一把,也谈不上 Inference Time Optimization(比如 Mujoco/Atari 都是这样的任务)。然而,在围棋任务中,目前还没有每一步直接做一次 Neural Network Inference 就能击败人类顶级选手的 RL Policy,需要这些 Policy Network 配合 Value Network 做 MCTS 才能取得较好的效果。在这个过程中,value network 扮演的决策就是一个 "dense reward function",能够在 inference 过程中把不好的 action 过滤掉。
同理,Reward Model 在困难的 LLM 任务中也可以扮演 Inference-time 过滤器的角色,它总能和已有的 post-train 方法相结合,进一步提升 LLM 生成的质量。
1.3 为什么关注 Inverse (Reward Model) 部分而不是 Forward (Policy Optimization) 部分
首先,准确的 evaluation 是一切算法改进的根基。Online RL 的工具库里有很多工具,但这些工具能用的前提是有一个靠谱的 Reward Model。找到问题出在哪是研究的第一步,如果 Reward Model 没有研究清楚,在第二阶段各种 RL 算法如此难收敛,超参如此之多又如此敏感,LLM 的训练又如此之慢的前提下,对着不靠谱的 Reward Model 做优化,得到的实验观察很难总结出可信的结论(更别提有人不到 10 个数据点取完 log 都 fit 不好也起名叫 scaling law 了)。
此外,RL 领域无数任务中的经验告诉我们,RL 里没有 Silver Bullet,最重要的是理解任务的特点,并根据任务(数据,奖励性质,系统性质,算力约束)去优化相应的算法。DPO 和 GRPO 的成功不是因为它们是 LLM 时代的策略优化万金油,而是因为它们找到了先前系统中存在的问题(冗余),根据任务的需求和硬件进行了优化。
1.4 为什么 Reasoning 是这一层里最重要 (和目前为止最成功) 的任务
首先是观察:Reasoning task 确实可以提升模型 "聪明" 的程度,跟随用户指令,完成任务和解决问题的能力,在数学上训出来的模型,整体能力都提升了。
其次是动机:如果能够真的让 LLM reasoning 起来,行为上具有想的越久,正确率越高的能力,那么这个系统兴许真的可以自举起来。数学家不断推理就有可能发现新的定理,提出新的问题,或是在解决问题的方向上取得进展。不过话说回来,用没有这种能力的模型尝试达到 "左脚踩右脚原地起飞" 的效果,并且用 "左脚踩右脚原地起飞" 宣传工作,或许有点不太合适。。
第二层:【Game】Experience from Games and Rule-based Tasks
在第一层,我们知道通过人类的经验,反馈,或是人工生成的题库来建立奖励模型,可以把 LLM Post-Train 这个缺失了 Reward Function 的 MDP\R 问题转化成完整的 MDP 问题。这种数据驱动的方式廉价,可规模化,在数学任务上优化过后取得了非常好的优化泛化性,显著提升了模型的通用能力。但是但凡是有限样本拟合的奖励函数,都会有过拟合的风险,只是不同的模型,不同规模的数据,不同的任务,这种过拟合的风险不同罢了。Reward Model 的过拟合带来的后果是 Reward Hacking,也就是朝着背离 Reward 设计初衷的方向狂奔,比如 helpful 这个任务里一个经典的 reward hacking 是 "length bias"------ 模型不管说的话有没有用,发现说的越多分数越高,就可劲输出废话。
短期来看,我们可以想办法在有限的范围内缓解 Reward hacking,就像这一路 data-driven 的科研模式中大家通过各种方式减少 overfit,提升模型的泛化性一样。但是长期来看,这种发展不符合数据 x 算力这种更加可预测的扩张模式 ------ 在所有有可能的改进中,算法的改进可能是最难预测的(天不生 Sutton,RL 如长夜)
那么,除了数学,还有什么任务是或许可以突破数据瓶颈,增强模型能力的呢?回想人类幼崽的学习过程,从小时候学会了语言之后,首先接触的是游戏!技术上来讲,游戏往往是定义良好的完整 MDP,十几年前我们用游戏训练了 DeepRL 算法,那如果 DeepRL 算法运行在 LLM 上呢?
我们的终极目标是通过在环境中进行无穷多次的尝试探索,让 LLM 不断提升自己的理解 / 推理 / 规划 / 指令跟随能力。游戏恰好提供了这样的(廉价模拟)环境 ------ 想要在游戏中取胜,需要首先理解其规则,进而在规则限定的范围内对策略进行优化。这里的游戏包括文字为基础的辩论 / 讨论类型的游戏,规则更为明确的棋牌类游戏,以及其他更一般的 3D 类型游戏。其中文字 / 辩论类游戏的胜负判断相对困难,但输入输出空间最适用于语言模型。棋牌类游戏虽然可行,但输入输出空间的表征适配或许是一个较大的挑战。更复杂一些的游戏虽然可行,但现在 LLM 包括 VLM 的能力可能距离玩好这些游戏太远了,找到合适的 curriculum 和任务是重要的问题。从去年下半年开始 ^*3,我们陆续看到了这个方向的尝试,包括简单的 Atari,贪吃蛇类型游戏,3D,Text-based game,未来可期,但也有诸多亟待解决的问题:
- 什么样的任务最适合评估 LLM 的能力?如何避免 text-based game 中的 cheating?
- 怎样找到 LLM 处理输入输出,理解游戏的最佳表示?
- 什么样的游戏可以最全面地发展 LLM 个方面的能力(而不至于让 LLM "玩物丧志" overfit 到游戏)
- 游戏中取得的进展是否可以像数学一样带来全面的能力提升?
- 如果允许调用 Tool(比如 AlphaGo 的 value function 或者 GTO 软件),LLM 还能(需要)在这个过程中学会推理吗,学会造轮子更重要还是使用轮子更重要
- 这里是否会有一个对应的 game supremacy scaling law 之类的东西存在?游戏提升 LLM 推理能力的上限在哪里
解决了这些问题之后,大规模上 Self-Play,突破目前的数据局限,提升 LLM 的推理能力就只剩下算力问题。
第三层:【Virtual Experience】"Experience" in the Virtual World
在过去两年做 Alignment 研究的过程中,一直很想做但又没有合适机会的方向是 Agent------Agent 是一个非常面向产品 / 用户 / 落地的课题,工程上的优化,用户的反馈,活跃开发社群的建设和维护都十分重要。除此之外,即使可以在研究中尽可能地将基座模型的能力和框架以及学习范式二者分离,基座模型的能力提升往往可以直接带来质变。
至于非技术上的问题,例如早期大家担心的适配与权限问题,目前看来在 MCP 到来以后都不再是重点。除非数据的拥有者能做到垄断,不然市场的反向选择一定会让数据的拥有者对 Agent 更加开放。当然,一切的前提都是 Agent 背后有足量用户的支持,Agent 足够强大和有用。从这个角度看,Agent 时代做内容和社交,或许能带来洗牌的机会。Agent 时代很或许会有新的微信。
从 RL 的角度,Agent 时代也有更多的机遇和挑战:
首先,Agent 与虚拟世界(互联网中的内容)进行交互,完成 "任务"。所以其实 Agent 相比 LLM 的变化,重点不在于加了几个 prompt,引入了工作流,而是增加了很多它们和非语言系统交互的可能性。有交互就会有反馈,这些反馈信息是一手的,真实的,on-policy 的,用 Silver 和 Sutton 的话说就是它们自己的 Experience。
在这个交互过程中,用户可以定义无穷多的任务,并且提供任务是否成功的反馈。相比在游戏中进行 self-play,直接和用户打交道的 Agent 所参与的场景和用户的日常需求高度对齐,不太需要担心能力提升的泛化问题。通过用户众包形式的反馈,提升 Agent 的能力就像是在培养具有专业技能的劳动者。
更重要的是,Agent 达成目标这个任务属于 RL 中的 Multi-Goal 问题,Multi-Goal 最大的特点就是很方便从失败的经验中学习 (Hindsight Methods)。举个例子,LLM 做数学题的时候,一道题做错了,生成的错误答案只能通过 "反思,纠错",来帮助 LLM 以后在类似的题上不犯同样的错误 ------ 但是它很有可能会犯别的错误。这里失败的经验只能被拿来做排除法,从失败中学习难就难在失败的可能千千万,成功的路径相比之下要稀缺很多。所以数学就不是一个很好的 "multi-goal" 的例子 ------ 没有人会把 "做错这道题" 当成一个有效的目标。
再来看 Agent 达成目标这个任务,如果我让 Agent 帮我【订一张从北京到上海的火车票】,结果 Agent 一通操作,帮我买了一张从北京到深圳的机票,我们会认为这个任务失败了,但是这个失败的经验只是对于原始的目标失败了,如果有一天我想从北京去深圳,这次 Agent 的失败经验是很有用的,只需要更改这次失败经验的目标,就可以让 Agent 的 Experience 中有【订一张从北京到深圳的机票】这个目标应该如何达成这一条,对着成功的案例学习,效率自然会比用排除法高很多。
在这些机遇背后,很多技术问题的答案也让人充满好奇 ------
- 可以规模化的持续学习的能力如何注入,范式是什么
- RL 会有 plasticity vanishment 的问题,GPT 系列模型做 Supervised Learning 的 scaling law 到了 RL 还是否存在?
- 大规模的 Agent Learning 是工程和算力的双重挑战。人类社会是多元的,Agent 更像是人类社会中承担不同工作的员工们,人类的多元化和不同的天赋让分工更加明确,并且持续积累经验,不断提升专业化的程度和业务能力。用 Prompt 给 Agent 注入的 Diversity 或许帮助有限,用 Fine-tuning 甚至不同的 pretrain model 又难以支撑。
- Agentic Personalization 是必然的趋势,但端侧友好的轻量化实现目前并没有好的方案。对齐和监管要求这个过程必然是中心化进行的,如果要用目前的技术手段做到这个规模的中心化,英伟达的卡是不是需要普及到人手一块。
第四层:【Physical Experience】"Experience" in the Physical World
最近两年机器人和具身智能再度火热,早期做 RL 方向的同学可能大多都对这个方向有着比较深的感情,robot control、mujoco 应该是当年开始 RL 的时候大家最先接触的任务。能够和物理世界做真实交互的机器人一定是未来,但是硬件和伦理是两大绕不开的挑战。硬件的成本会随着技术的进步不断降低,但风险和伦理问题一眼还需要更多思考。
硬件方面,2020 年和朋友一起琢磨过面向发烧友的手工出海,做过一条非常简易的 "四足机器 (狗?)"。元件就是几个电机,树莓派,四条腿是一次性筷子做的,拍脑袋写了个声控往前爬往后爬的运动模式。然而出师未捷,内忧外患一起出现 ------ 贸易战升级,小米也出了一款价格四位数的消费级器狗。对比过后发现硬件这个东西不比服务或者互联网,一分价格一分货,且重资产轻技术,十几二十块的电机就是做不到精准有力的操控,力度不够就是没办法后空翻,这个产品或许只能卖给发烧友搞着玩,价格也不便宜,后来就不了了之了。
更现实一些,距离我们生活最近的场景是智能 (辅助) 驾驶,在这个场景里,车是市场上存在的刚醒需求,客户不会因为智能的 "具身" 支付太多额外的硬件成本。车作为智能的载体,能执行的动作也比较有限,更加可控。即使在这样的 Embodied AI 系统里 ------ 我们多大程度上可以接受自己的车一边开一边学,增强推理和理解场景的能力?多大程度上可以接受它犯错?谁来承担系统的错误。
人的分工和相互信任建立在长时间的社会稳定和协作共赢之上,但人和机器如何做到互信,要花多久?当智能能够通过具身或者物理世界的载体和人交互,就不可避免会带来伦理问题,包括我在内的大多数的技术 / 科研工作者对此可能都一无所知,这里也就不多做讨论。可以确定的是,AGI 时代会有更多的挑战,关于 AI Safety 的探讨也会更加迫切,当 Agent 有有了无限探索的能力和物理世界做交互的时候,碳基文明的存亡也有了实实在在的威胁。
在 AGI 的前夜,人类更加需要伟大哲学家的指引
作者简介
孙浩是剑桥大学 4 年级在读博士生,研究课题为强化学习和大语言模型的对齐(后训练)。他关于强化学习的研究涵盖了稀疏奖励,奖励塑形,可解释性等课题,研究发表于 NeurIPS 会议;在关于大语言模型对齐的工作中,重点关注如何从数据中获得奖励函数,提升大模型在对话和数学上的能力,论文发表于 ICLR 会议,并参与贡献了 AAAI2025 和 ACL2025 的系列课程报告。
原文链接:https://zhuanlan.zhihu.com/p/1896382036689810197
1 过去两年我参与的 IRLxLLM 的研究也围绕着 "如何从不同数据中构建更好的奖励模型" 进行探索
ICLR'24: RM for Math & Prompting;
ICML'24: Dense RM for RLHF;
RLC workshop'24: RM from Demonstration data;
DMRL'24: When is RM (off-policy-evaluation) useful?;
ICLR'25: foundation of RM from preference data;
Preprint (s)'25: Active RM, Infra for Embedding-based Efficient RM Research, PCA for Diverse/Personalized RM)
2 关于未来方向的畅想,理解和思路上距离在 Agent 方向深耕的研究难免会有偏差,烦请大家不吝斧正!
3 更早一些在 2023 年底的 NeurIPS 就有一篇工作是讲外交类游戏博弈的,希望 LLM+Game 这个方向的未来不要步前几年的 RL + 阿瓦隆 / 狼人杀 /xx 游戏的后尘,而是在选择任务上多一些思考,做长期更有价值的探索!
#TTRL
TTS和TTT已过时?TTRL横空出世,推理模型摆脱「标注数据」依赖,性能暴涨
在大语言模型(LLMs)竞争日趋白热化的今天,「推理能力」已成为评判模型优劣的关键指标。OpenAI 的 o 系列、Anthropic 的 Claude 和 DeepSeek-R1 等模型的惊艳表现背后,测试时缩放(TTS)技术功不可没。
测试时缩放(TTS,Test-Time Scaling)是一种提升大语言模型推理能力的新兴策略,通过在测试阶段优化推理过程(如多数投票、蒙特卡洛树搜索等)提升大型语言模型(LLMs)的性能,而无需修改模型参数。
研究表明,TTS 在计算效率上优于预训练阶段扩大模型规模,能以更低资源成本实现更好表现。然而,TTS 依赖预训练知识,在面对未标注新数据或输入分布变化时,泛化能力受限。如 OpenAI o3 在某基准任务上达到 75.7% 的成功率,对更复杂的新任务却仅能解决 4% 的问题。
为克服 TTS 的局限,测试时训练(TTT,Test-Time Training)一度受到广泛关注。TTT 通过在测试阶段利用 RL 等技术动态更新模型参数,使模型适应新数据或任务,弥补了 TTS 在泛化能力上的不足。但 TTT 同样面临自身的挑战:测试阶段缺乏奖励函数或验证信号,而人工标注数据的高成本使得无监督环境下的 RL 应用受限。
在最新的一篇论文中,清华大学和上海人工智能实验室提出了一种新方法 ------ 测试时强化学习(Test-Time Reinforcement Learning,TTRL),该方法能够在无标注数据上对 LLM 进行强化学习训练。
- 论文标题:TTRL: Test-Time Reinforcement Learning
- 论文地址:https://arxiv.org/abs/2504.16084
- GitHub:https://github.com/PRIME-RL/TTRL
- HuggingFace:https://huggingface.co/papers/2504.16084
TTRL 通过利用预训练模型中的先验知识,使 LLM 具备自我演化的能力。实验证明,TTRL 在多种任务和模型上都能持续提升性能:在仅使用未标注测试数据的情况下,TTRL 将 Qwen-2.5-Math-7B 在 AIME 2024 任务中的 pass@1 指标提升了约 159%。
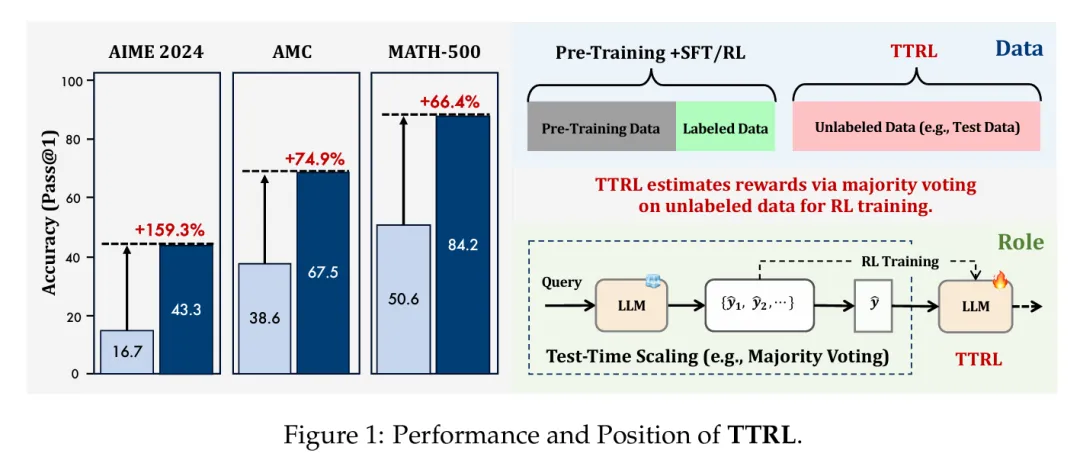
值得注意的是,虽然 TTRL 仅依靠 Maj@N 指标进行监督,但其表现不仅能持续超越初始模型的性能上限,更能接近于那些直接在有标注测试数据上进行监督训练的模型性能。实验结果验证了 TTRL 在多种任务中的广泛有效性,充分展示了该方法在更广阔领域中的应用潜力。
方法
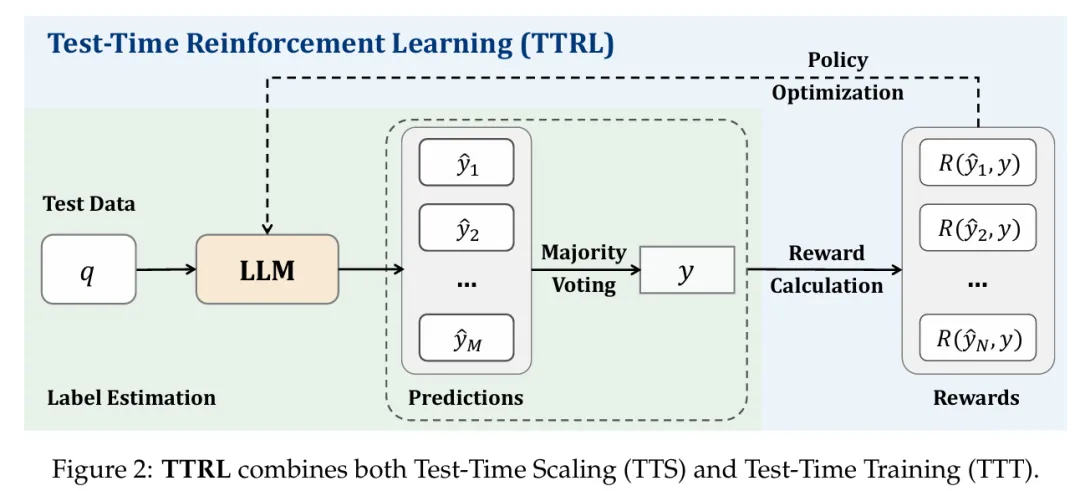
图 2 展示了研究者提出的 TTRL 方法如何应对此类挑战。给定状态表示为输入提示 x(prompt x),模型依据参数化策略 π_θ(y | x) 生成输出 y。为了在无真实标签的条件下构造奖励信号,研究者通过重复采样的方法,从模型中生成多个候选输出 {y₁, y₂, ..., y_N}。接着,使用多数投票(majority voting)或其他聚合方法从这些候选中推导出共识输出 y*,作为近似的最优动作(optimal action)的替代。
环境反馈的奖励 r (y, y*) 则根据当前动作 y 与共识输出 y* 之间的一致性进行设定。模型的 RL 目标是最大化期望奖励:
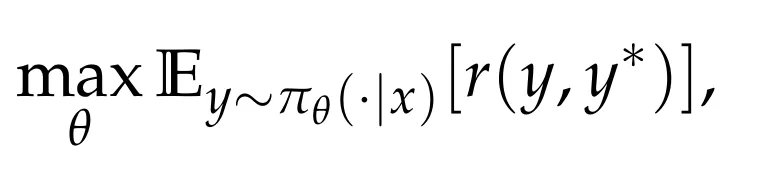
通过梯度上升(gradient ascent)更新参数 θ:
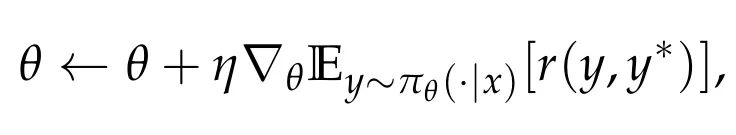
该方法能够在推理阶段实现模型的动态适应,无需标注数据即可提升模型应对分布变化输入时的性能。
多数投票奖励函数(Majority Voting Reward Function)
多数投票奖励机制的核心在于:首先借助多数投票策略估算一个伪标签(pseudo-label),再基于该估计标签计算规则驱动的奖励(rule-based rewards),并作为最终用于 RL 训练的奖励信号。
在具体操作上,给定一个输入问题 x,研究者对其输入到大型语言模型中,并生成一组输出结果。随后,答案抽取器(answer extractor)对这些输出进行处理,提取对应的预测答案,记为 P = {ŷᵢ}ⁿ_{i=1}。接着,研究者在集合 P 上应用第 4 节定义的多数投票策略函数 s (y, x),选出出现频次最高的预测 y,作为估计标签。
随后,该多数投票结果 y 被用作标签估计,用于计算基于规则的奖励信号:
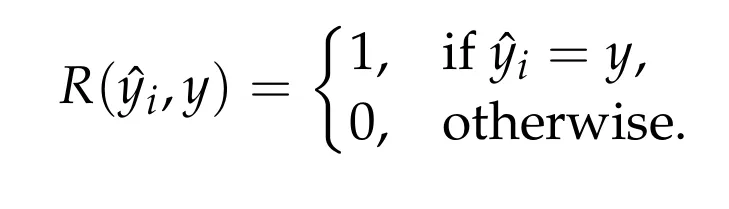

实验
TTRL 在大多数任务和模型上都表现出色。尽管 TTRL 完全依赖于使用无标注测试数据的自我进化,但其性能却可媲美基于大规模标注数据集训练的现有 RL 模型。如表 1 所示,在 AIME 2024 上,TTRL 实现了 159.3% 的大幅提升,超过了所有在大规模数据集上训练的模型。此外,当应用于 Qwen2.5-Math-7B 时,TTRL 在三个基准测试中平均提高了 84.1%。
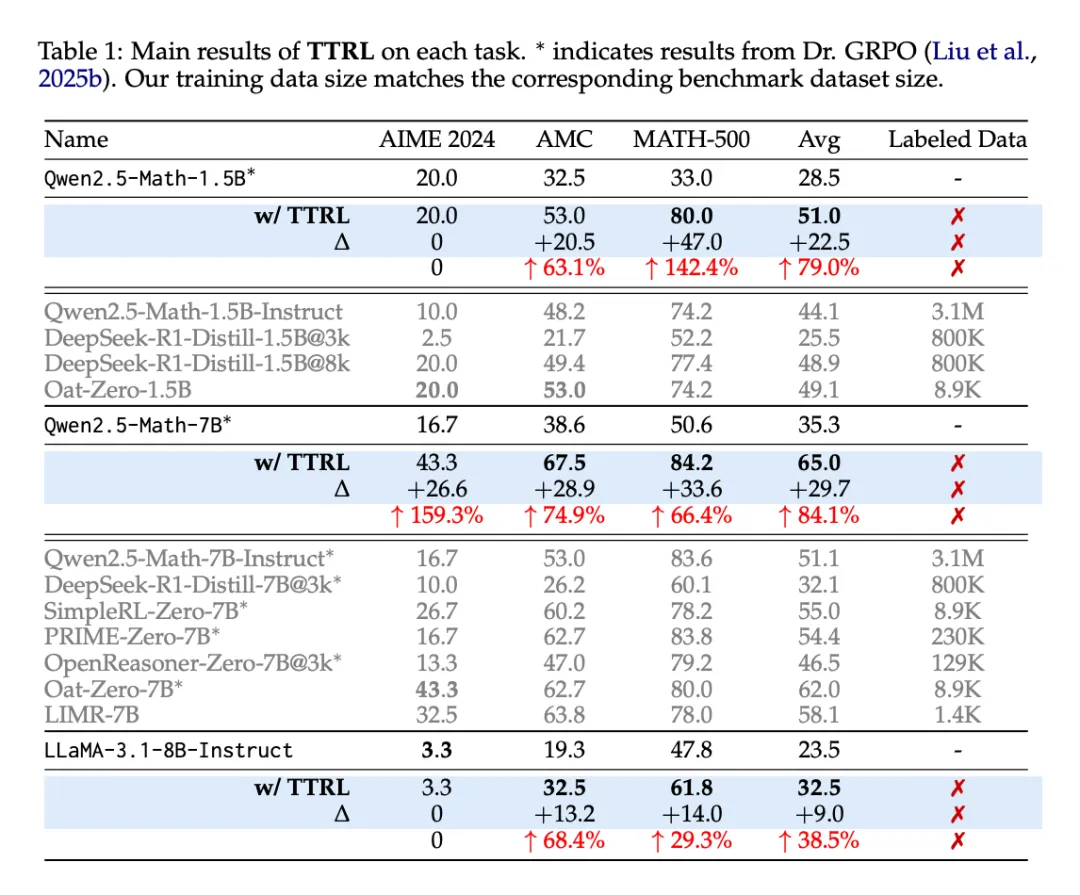
TTRL 自然扩展。另一个值得注意的现象是,随着模型大小的增加(从 1.5B 到 7B),其在 AIME 2024 和 AMC 上的性能提升也在增加,这凸显了 TTRL 的自然扩展行为:更大的模型可以在自我改进过程中产生更准确的多数投票奖励,从而更有效地学习新数据。不过,LLaMA-3.1-8B-Instruct 和 Qwen2.5-Math-1.5B 可能由于容量有限,未能通过 TTRL 在 AIME 2024 上取得有意义的进展。相比之下,Qwen2.5-Math-7B 的模型容量更大,知识更充分,因此可以从自我改进中获益,从而取得明显的性能提升(第 4.3 节会详细讨论这一点)。
TTRL 在目标任务之外也有很好的通用性。研究者以 Qwen2.5-Math-7B 为骨干,在每个基准上执行了 TTRL,并在其他基准上进行了进一步评估。图 3 展示了结果。尽管这种设置具有分布外的性质,但 TTRL 在所有基准上都取得了实质性的改进。这表明 TTRL 并没有依赖过拟合(过拟合会导致在其他任务上的取舍),而是在自我改进过程中获得了可推广的收益。
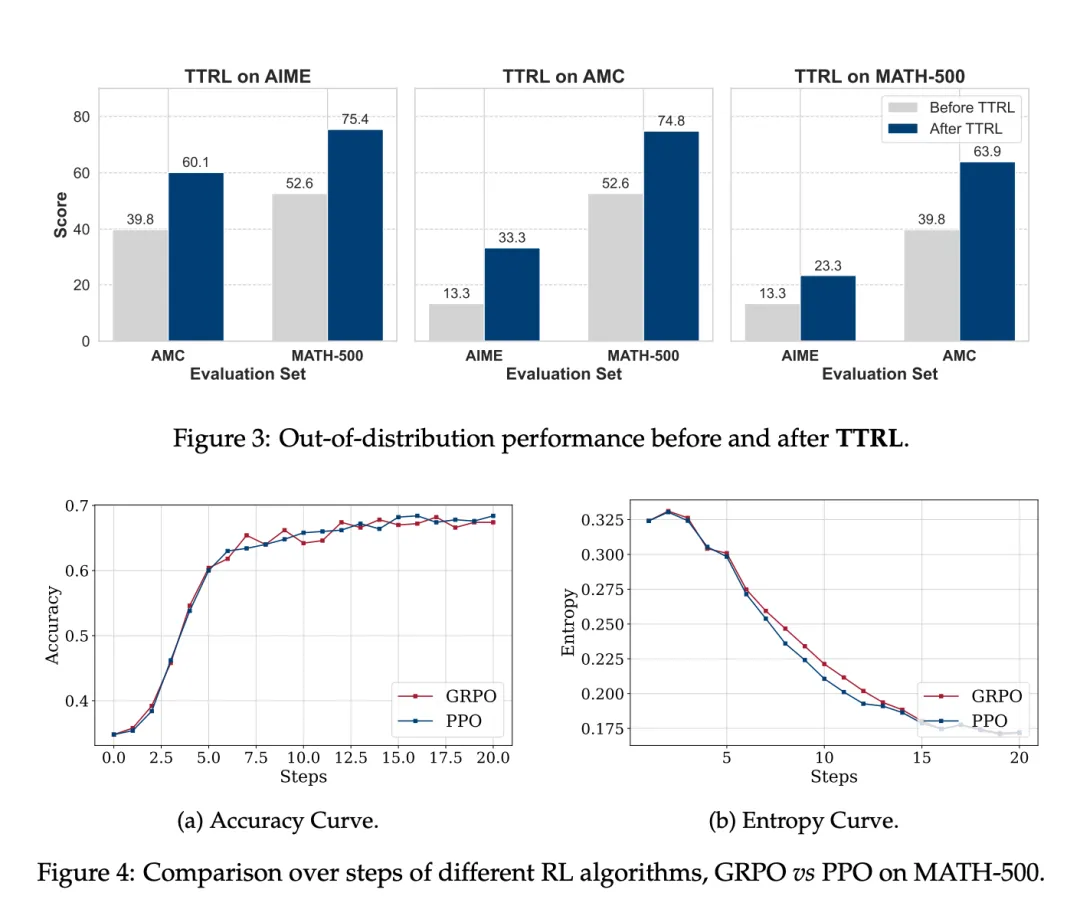
TTRL 与不同的 RL 算法兼容。图 4 展示了结果。研究者在 MATH-500 上使用 PPO 应用 TTRL,以评估其与不同强化学习算法的兼容性。PPO 和 GRPO 的性能轨迹非常接近。与 GRPO 相比,PPO 能产生更稳定的结果,同时实现相似的整体性能。
讨论
Q1:TTRL 的性能能有多好?
研究者使用了两个上限来分析 TTRL 的潜在性能。第一个上限是 Maj@N,用于计算 TTRL 训练过程中的奖励。第二个上限是在基准数据集上的直接训练,它假定可以访问 ground-truth 标签,因此会向策略模型泄露标签信息。
关键发现如下:
-
TTRL 不仅超越了其训练信号和初始模型的直观上界 Maj@N,还接近了用标注测试数据训练的直接 RL 的性能。这一进步可能要归功于 TTRL 使用 RL 进行测试时间训练:通过将基于投票的伪标签转换为奖励,它提高了有效监督的质量,同时使学习摆脱了 Maj@N 的限制。
-
TTRL 的经验上限是在测试数据上进行训练(即在测试数据上进行训练),这凸显了它与标准训练评估协议相比在功效上的潜在优势。
-
对于具有挑战性的任务,TTRL 只需使用 1.5B 模型即可达到经验上限。这表明,现在 LLM 可以通过 TTRL 有效地自我进化,从而在大规模数据集上实现无限制的终身学习。
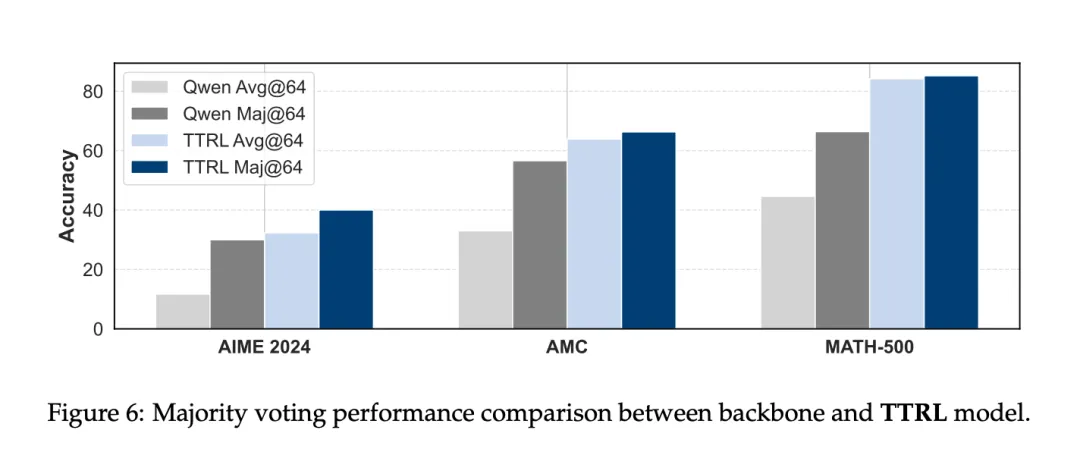
TTRL 受 Maj@N 监督,却超越了 Maj@N。图 6 展示了 TTRL 在 Qwen2.5-Math-7B 上的测试结果。可以看出,在所有基准测试中,TTRL Avg@64 均优于 Qwen2.5-Math-7B Maj@64,大大超出预期。此外,在应用多数表决时,TTRL 的性能也有大幅提升。
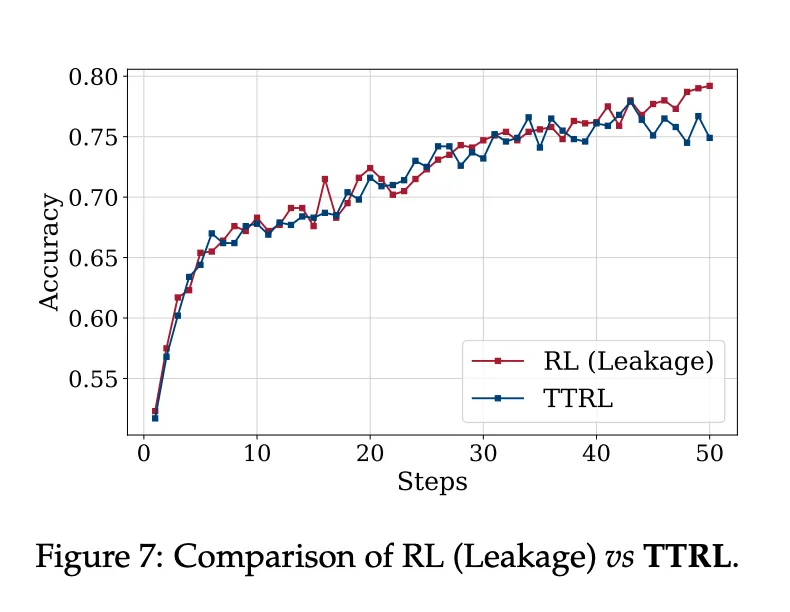
TTRL 的「性能增益法」基准训练,图 7 展示了结果。令人惊讶的是,TTRL 的性能曲线非常接近 RL(泄漏)的性能曲线。
Q2:TTRL 为何有效?
这一节主要分析了 TTRL 在无监督条件下实现稳定有效的 RL 的因素,包括两个关键方面:标签估计和奖励计算。
标签估计。TTRL 与标准 RL 算法的一个直接区别是,TTRL 涉及标签估计,而标签估计会带来奖励误差。研究者认为,尽管存在这些误差,TTRL 仍能正常工作,原因有以下两点:
(i) 现有研究表明,RL 可以容忍一定程度的奖励不准确性。此外,与通常依赖于记忆训练数据的监督微调(SFT)相比,RL 的泛化效果往往更好。在 RL 中,奖励通常是模糊的,主要是作为探索的方向信号,这导致了 RL 对奖励噪声的鲁棒性。
(ii) 之前的研究还从优化的角度研究了什么是好的奖励模型,发现更准确的奖励模型不一定是更好的教师。因此,由政策模型本身估计的奖励信号可能会为学习提供更合适的指导。
奖励计算。当模型能够通过多数投票估算出准确的标签时,随后估算出的奖励一般都是可靠的。然而,一个自然而然的问题出现了:为什么在 AIME 2024 等具有挑战性的基准上,即使模型无法估算出准确的标签,TTRL 仍然有效?
研究者表示,最根本的原因在于 RL 中奖励的定义。基于规则的奖励是根据预测答案是否与「标签」匹配来分配的。因此,即使估计的标签不是 ground-truth,只要它与错误预测的答案不同,系统仍可分配正确的「负」奖励。
为了提供更详细的案例研究,研究者在 Qwen2.5-Math-7B 上检验了 TTRL 在 AIME 2024 上的性能。图 8 显示了三个指标的变化曲线。
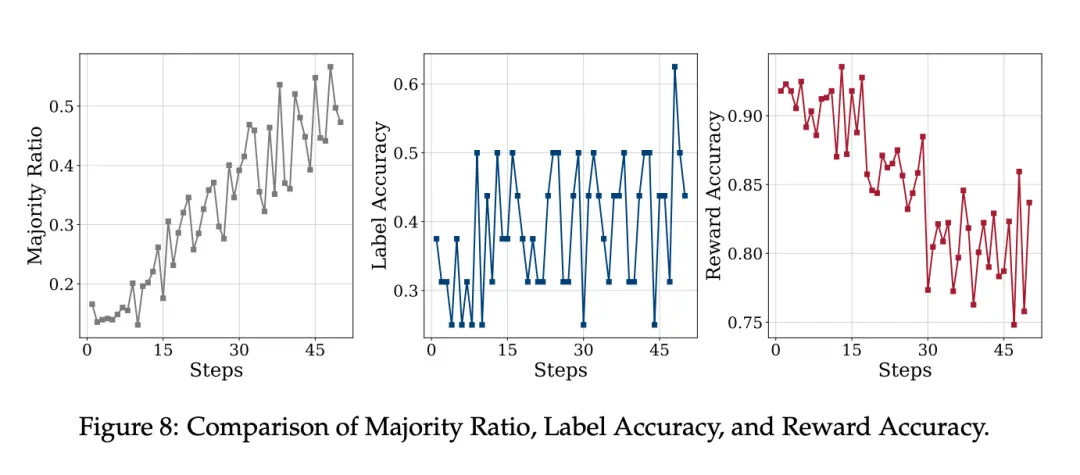
研究者发现了 TTRL 在 AIME 2024 上依然有效的两个主要原因:
- 首先,奖励比标签更密集,即使估计的标签不准确,也有更多机会恢复有用的学习信号。
- 其次,当模型能力较弱时,TTRL 给出的奖励可能更准确。
Q3:TTRL 何时失效?
在算法层面,TTRL 与现有的 RL 算法并无本质区别,因此继承了它们的一些特点,如对数据难度的敏感性、对先验的强烈依赖性以及在某些条件下崩溃的风险。
在实现层面上,这些问题因 TTRL 的限制而进一步扩大,TTRL 通过多数投票来估计标签,并且只在稀疏和以前未见过的测试数据上运行,在某些情况下可能会导致失败。
在初步实验中,研究者发现了两个潜在问题:
缺乏对目标任务的先验知识。如表 2 所示,研究者发现,随着问题难度的增加,性能提高率和长度缩减率都呈下降趋势。这表明主干系统的可用先验知识不足以支持对更具挑战性问题的学习。
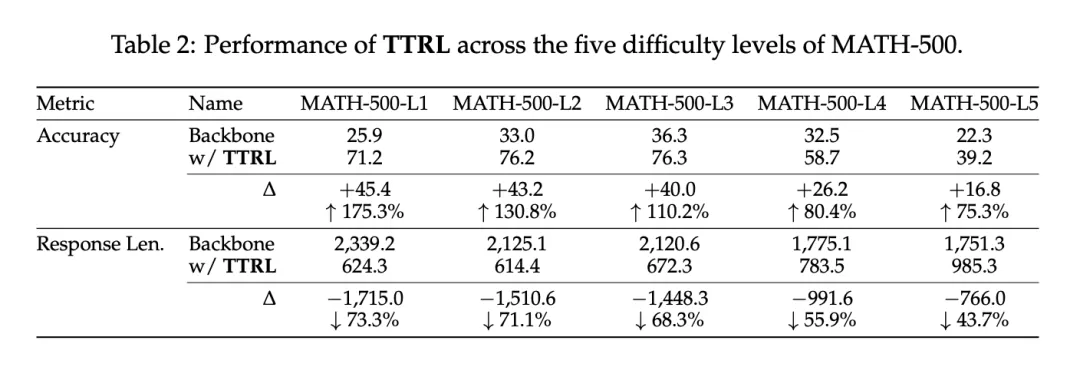
不恰当的 RL 超参数。图 10 比较了在 AIME 2024 上的几次失败尝试。

#MANIPTRANS
机器人也会挤牙膏?ManipTrans:高效迁移人类双手操作技能至灵巧手
研究团队由来自北京通用人工智能研究院(BIGAI)、清华大学和北京大学的跨专业研究者组成,致力于具身智能领域的前沿研究。团队成员在开发高效、智能的通用机器人技术,特别是机械灵巧手操作方面,拥有丰富的研究经验。一作为北京通用人工智能研究院研究员李恺林,其它作者为清华大学博士生李浦豪、北京通用人工智能研究院研究员刘腾宇、北京大学博士生李宇飏;通讯作者为北京通用人工智能研究院研究员黄思远。
近年来,具身智能领域发展迅猛,使机器人在复杂任务中拥有接近人类水平的双手操作能力,不仅具有重要的研究与应用价值,也是迈向通用人工智能的关键一步。
目前,数据驱动的具身智能算法仍需要精确、大规模且高度灵活的灵巧手动作序列。然而,传统的强化学习或真机遥操作方法通常难以高效获取此类数据。
为了解决这一问题,北京通用人工智能研究院联合清华大学、北京大学的研究人员提出了一种两阶段方法------ManipTrans,可在仿真环境中高效地将人类双手操作技能迁移至机器人灵巧手。
- 论文地址:MANIPTRANS: Efficient Dexterous Bimanual Manipulation Transfer via Residual Learning
- 论文链接:https://arxiv.org/pdf/2503.21860
- 项目主页:https://maniptrans.github.io
- 代码与数据集:https://github.com/ManipTrans/ManipTrans
ManipTrans 首先利用通用轨迹模仿器的预训练模型模仿人类手部动作;然后针对不同的操作技能,引入残差学习模块,结合基于物理的交互约束进行精细调整(如图 1 所示)。该方法将动作模仿与物理约束分离,使复杂的双手任务学习更加高效,执行更加精准。
基于 ManipTrans,研究团队同时发布了大规模灵巧手操作数据集 DexManipNet,涵盖了如盖笔帽、拧瓶盖等此前未曾深入探索的任务。
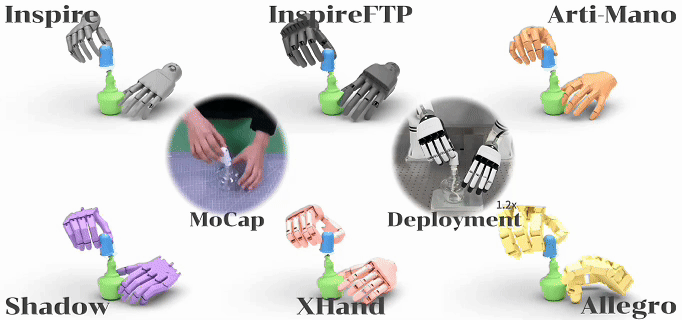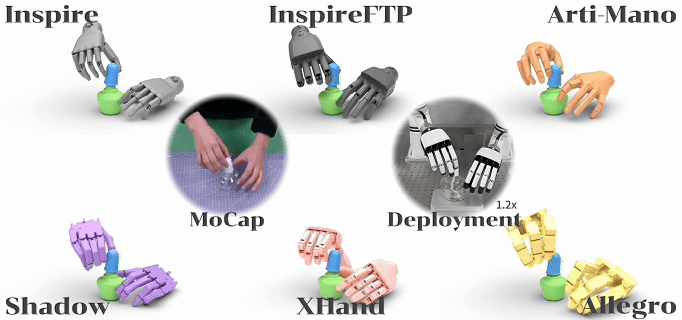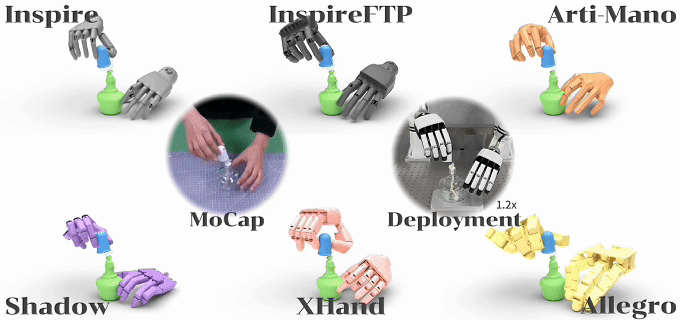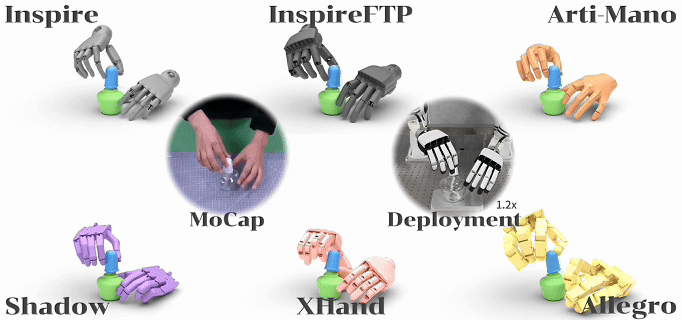
图1. 基于ManipTrans实现相同操作技能的跨型号灵巧手技能迁移
研究背景
人类双手在与环境交互中发挥着关键作用,这激发了对机器人灵巧手操作的广泛研究。如何快速获取大规模、精确且接近人类水平的灵巧手操作数据,已成为亟待解决的问题。
现有的基于强化学习的方法需要精心设计针对特定任务的奖励函数,这通常限制了任务的复杂性,并可能导致机器人动作的不自然;另一类基于遥操作的方法成本高昂、效率低下,且所采集的数据通常针对特定的本体,缺乏通用性。
目前,一种有潜力的解决方案是通过模仿学习,将人类的操作动作迁移到仿真环境中的灵巧手上,以生成自然的「手-物交互」。然而,实现精确且高效的迁移并非易事。由于人手和机器人手在形态上的差异,直接进行姿态重定向的效果并不理想。并且,尽管动作捕捉得到的数据相对准确,但在高精度任务中,误差的累积仍可能导致任务失败。此外,双手操作引入了高维度的动作空间,显著增加了高效策略学习的难度,因此,先前的大多数工作通常止步于单手的抓取任务。
研究方法
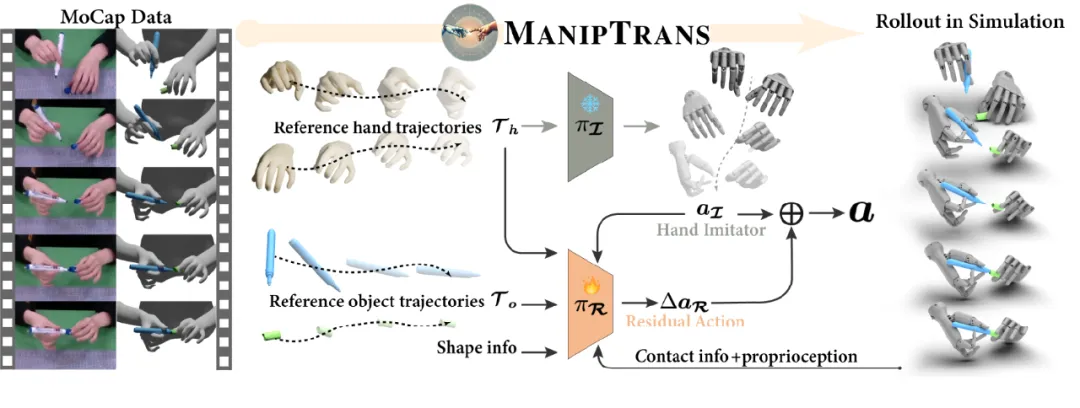
图2. 本文提出的ManipTrans方法框架图
针对上述挑战,本文提出了一种简洁而有效的方法------ManipTrans(如图 2 所示),旨在实现操作技能,特别是双手协同技能,在仿真环境下从人手向机械灵巧手的迁移。核心思想是将迁移过程划分为两个阶段:第一阶段,实现手部运动的轨迹模仿;第二阶段,在满足物理交互约束的前提下,对动作进行微调。
具体而言,首先预训练一个通用模型,以准确模仿人类手指的运动;在此基础上,引入残差学习模块,对灵巧手的动作进行微调,着重针对以下两点:1)确保手指与物体表面的稳定接触;2)协调双手,保证复杂情况下双手操作的高精度和高保真执行。
本文将该问题建模为隐式马尔可夫决策过程(MDP),在两个阶段均采用 PPO 算法以最大化折扣回报。在第一阶段,设计奖励函数,约束灵巧手跟随参考的人手轨迹,同时确保动作的稳定性和平滑性。其中,手指模仿奖励函数「鼓励」灵巧手的关键点位置与人手保持一致,特别是与物体接触最频繁的拇指、食指和中指的指尖位置是否对齐,此设计有效解决了形态不一致的问题。
在第二阶段,残差模块输出动作的补偿项,通过与第一阶段的动作相加,实现微调。该模块额外考虑了以下信息:1)物体的质心位置和所受重力,以增强对力矩的感知;2)基于空间基点集(BPS)表示的物体形状;3)灵巧手关键点与物体的空间位置关系;4)仿真环境提供的指尖接触力。第二阶段特别加入了接触力奖励函数,鼓励更加稳定的手物接触。在训练过程中,引入了随机参考状态初始化和课程学习策略,提高了收敛速度和训练稳定性。
综上,ManipTrans 的设计在第一阶段缓解人手与灵巧手之间的形态差异,在第二阶段捕捉细微的交互动作。通过将手指模仿与物理交互约束解耦,显著降低了动作空间的复杂度,同时提升了训练效率。本文在一系列复杂的单手和双手操作任务中,验证了该方法的有效性和高效性,任务甚至涵盖了铰链物体的操作。为评估该方法的泛化能力,本文进行了跨本体的实验,验证了 ManipTrans 可应用于具有不同自由度和形态的灵巧手,无需额外参数调节。此外,基于 ManipTrans 方法得到的双手操作数据,也在真机部署中得到了验证。
DexManipNet 数据集

图3. 灵巧手白板写字

图4. 双手舀取物体
基于 ManipTrans 方法,本研究将两个大型「手-物交互」数据集(OakInk V2 和 FAVOR)迁移至灵巧手,构建了 DexManipNet 数据集。该数据集涵盖了 61 种具有挑战性的任务,包含对 1200 多件物体的 3300 条灵巧手操作序列,总计约 134 万帧的数据量。其中,约有 600 个序列涉及复杂的双手操作任务(如图 3、图 4 所示),充分展示了机器人在高难度操作场景下的能力。

图5. 灵巧手拨开牙膏盖

图6. 双手协同完成倾倒入试管操作
此外,研究人员在真机平台上重放(replay)了 DexManipNet 的数据轨迹,使用了两台有 7 个自由度的机械臂和一对灵巧手,部署结果展示了此前未曾实现的精细灵巧操作能力。例如,在「拨开牙膏盖」的任务中,左手稳固握持牙膏管,右手的拇指和食指灵巧地拨开小巧的牙膏盖,这些细微而复杂的动作往往难以通过遥操作精确捕捉(如图 5、图 6 所示)。
实验结果
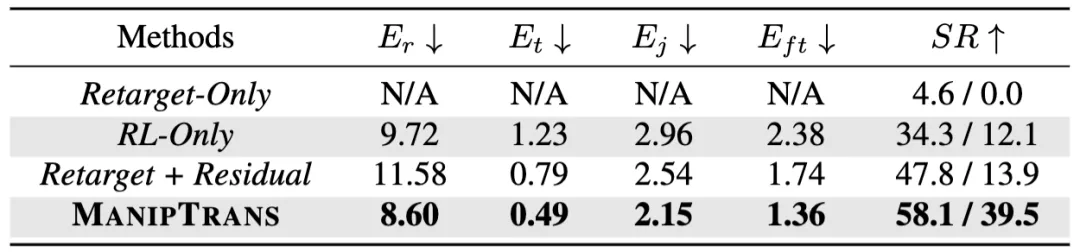
表1. ManipTrans与基线方法定量对比
本文将 ManipTrans 与两大类现有方法------基于强化学习的方法和基于优化的方法,进行了对比评估。结果显示,ManipTrans 在各项指标上均优于基线方法,展现了在单手和双手操作任务中的高精度(如表 1 所示)。定性和定量分析证实了,ManipTrans 的两阶段迁移框架能够有效捕捉手指的细微运动并与物体的交互,提高了任务成功率和运动的真实感。

图7. 跨本体迁移实验

图8. 双手操作铰链物体
此外,研究展示了 ManipTrans 在不同型号灵巧手上的可扩展性。该框架仅依赖人类手指与灵巧手关键点之间的对应关系,无需过多参数调整即可适配不同形态和自由度的灵巧手(如图 7 所示)。文章还在铰链物体操作数据集 ARCTIC 上进行了验证。通过对奖励函数的微调,添加铰链物体运动角度奖励,成功实现了灵巧手对铰链物体的指定角度旋转操作(如图 8 所示),展现了 ManipTrans 方法在复杂操作任务中的潜力。