目录
[LLama Factory界面介绍](#LLama Factory界面介绍)
今天在这里介绍一种常用的大模型微调框架------LLama Factory。
简介
LLama Factory 是一个高效的界面化大语言模型微调工具库,支持多种参数高效微调技术,提供简洁接口和丰富示例,助力用户快速定制和优化模型性能。
安装
a.获取并安装 git 上的 LLama Factory
bash
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.gitb.创建一个 LLama Factory 的虚拟环境
bash
conda create -n llamafactory python==3.10 -yc.换至 llamafactory 环境
bash
source activate llamafactoryd.找到从 git 上获取的 LLama-Factory.zip,并解压、安装
bash
unzip LLama-Factory.zip
cd LLama-Factory
pip install -e .至此,LLama Factory 安装完毕。
LLama Factory界面介绍
将环境切换至 llamafactory,并切换到 LLama Factory 的目录后,启动 LLama Factory。
bash
source activate llamafactory
cd /root/autodl-tmp/LLaMA-Factory
llamafactory-cli webui如果你使用的是 vscode 中的 remote 插件链接的服务器,由于 vscode 中自带端口转发,因此,你可以在你的电脑本地直接使用浏览器访问 LLama Factory 的 web 界面。

打开之后的界面大致是这样的:
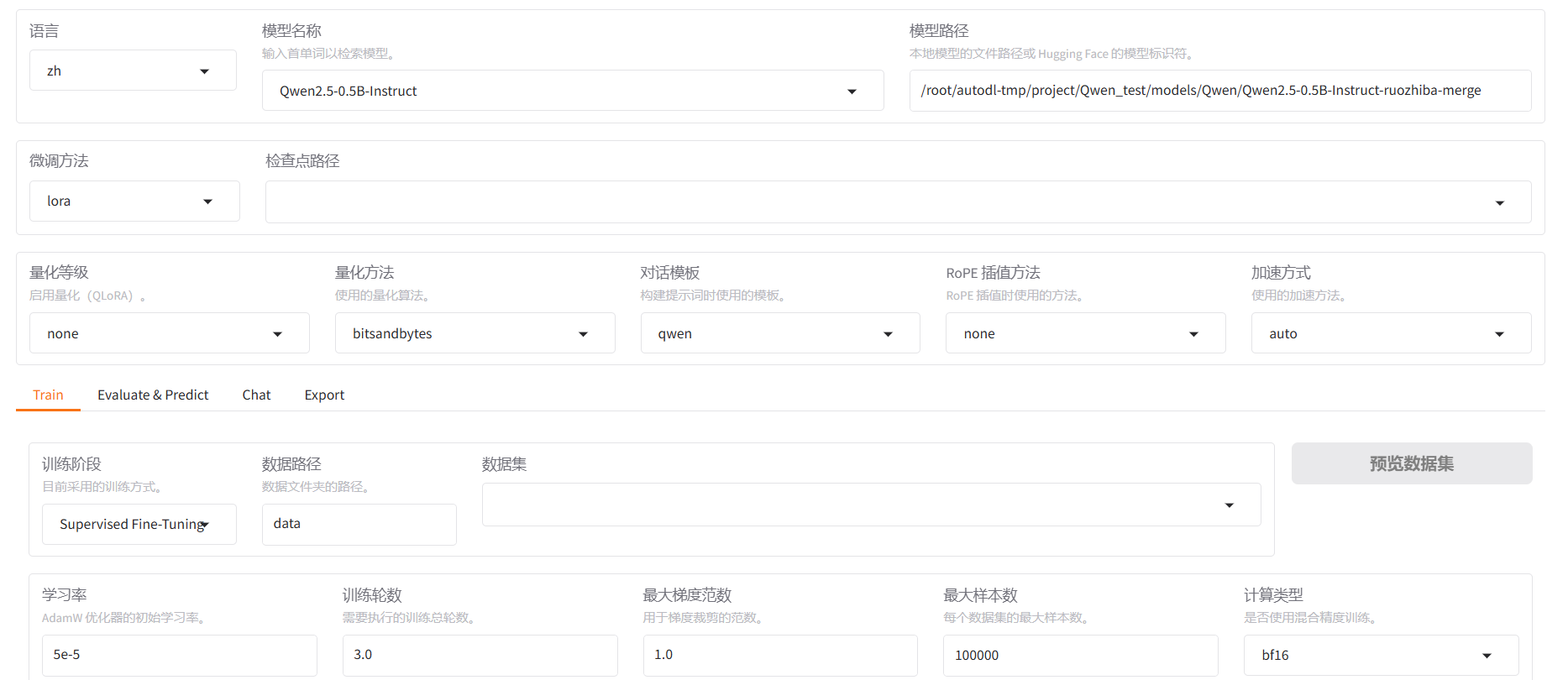
接下来,将对界面中的每一个参数进行介绍
**a.模型名称:**你所需要微调的模型的名称(本参数是为了对应后面的对话模板)

**b.模型路径:**你所需要微调的模型的绝对路径

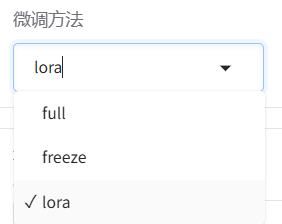
c.微调方法
full:全量微调------对整个预训练模型的所有参数进行微调,适用于计算资源较为充足的情况
freeze:冻结部分参数微调------冻结预训练模型的大部分参数,仅微调部分顶层参数或新增的任务相关层
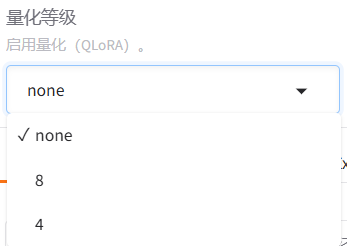
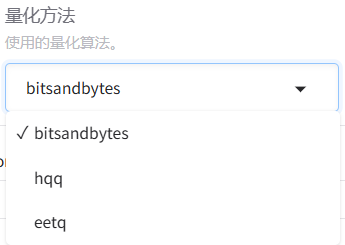
LoRA:量化微调------将原模型分解为两个低秩矩阵,通过微调低秩矩阵来间接微调原模型的参数。可以进一步选择下方的量化等级,进行QLoRA微调。关于LoRA微调涉及的具体原理,后续单开一篇文章来进行介绍。
**d.检查点路径:**如果你想继承之前的训练进度的话,可以选择之前保存的某一轮参数,从该参数继续进行训练

**e.对话模板:**用于控制模型的输出规范。对话模板本身并不影响模型的性能,但是,如果模型在微调和推理时的对话模板不一致的话,可能会影响到模型最终的输出效果。
**f.RoPE 插值方法:**通过一种平滑的位置编码方式,将模型的上下文窗口扩展到更远的区域。LLama Factory 中可选的方式有:线性缩放位置索引(Linear)、动态调整缩放因子(Dynamic)、非均匀频率调整(YaRN)和专门用于LLaMA3的优化插值(Llama3)。如果没有特殊要求的话,通常选择none就行。这里不再做过多赘述,如果有机会的话,以后单开一章进行详细说明。
**g.加速方式:**通过优化计算内核或引入高效算法,减少模型训练和推理的时间开销,同时节省显存占用。
auto:框架自动选择当前环境支持的最优加速方案。
flashattn2:一种高效计算 Transformer 模型中注意力机制的算法库,通过优化 GPU 内存访问模式和计算步骤,显著加速注意力计算并减少显存占用。
unsloth:一个针对大模型微调(尤其是 LoRA)的轻量级优化库,通过简化计算图和混合精度策略加速训练。
liger_kernel:LLaMA Factory 自研的轻量级加速内核,针对常见操作(如矩阵乘法、LayerNorm)进行底层优化。
**h.训练阶段:**针对大语言模型(LLM)不同训练目标和任务设计的特定流程。
Supervised Fine-Tuning:在标注数据上微调预训练模型,使其适配特定任务。
Reward Modeling:训练一个奖励模型,用于评估生成内容的质量。
PPO(Proximal Policy Optimization,近端策略优化):一种强化学习算法,通过最大化奖励模型的反馈优化生成策略。
DPO(Direct Preference Optimization,直接偏好优化):通过直接优化偏好数据调整模型策略。
KTO (Kahneman-Tversky Optimization):基于行为经济学中的"前景理论",设计损失函数以模拟人类决策偏差。
Pre-Training:在大规模无标注文本数据上训练模型,学习通用语言表示,构建模型的基础语言理解能力。
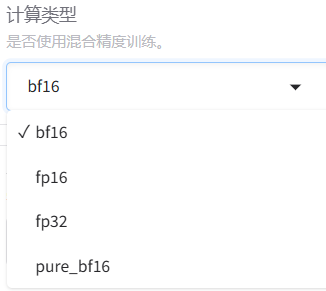
**i.计算类型:**指定了模型训练和推理过程中数值计算的精度格式,直接影响显存占用、计算速度和数值稳定性。
bf16:Brain Float 16,由 Google Brain 团队设计,指数位与 FP32 对齐,牺牲小数精度换取更大动态范围,数值范围在约 ±1.18e-38 到 ±3.4e38 之间。
fp16:16 位(半精度)浮点数,数值范围在约 ±6.1e-5 到 ±65504。
fp32:32 位(单精度)浮点数,数值范围在约 ±1.18e-38 到 ±3.4e38 之间,范围与 bf16 相同。
pure_bf16:纯 BF16 训练,全程使用 BF16 精度(包括权重、梯度、优化器状态),不保留 FP32 主权重副本。
数据格式要求
在使用 LLama Factory 进行微调之前,我们需要先明确一下 LLama Factory 在微调时所要求的数据格式。
LLama Factory 中默认的数据格式是json,以 data 文件夹下的 identity 数据为例,大概长这样:
bash
[
{
"instruction": "hi",
"input": "",
"output": "Hello! I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?"
},
{
"instruction": "hello",
"input": "",
"output": "Hello! I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?"
},
{
"instruction": "Who are you?",
"input": "",
"output": "I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?"
}
]其中,"instruction"是用户的输入,"output"是模型的输出,"input"能够为指令提供额外的上下文或具体输入内容,例如:当 instruction 为"翻译以下内容",可以在"input"中输入想要翻译的语句(但是感觉一般不会这么干)。
微调训练
接下来以模型的自我认知训练作为例子,来实战演示一下使用 LLama Factory 进行模型微调。
操作步骤如下:
1.找到并打开 LLama Factory 根目录下的 data/identity.json,将其中所有的 {{name}} 和 {{author}} 替换为自己想要的内容。例如:
bash
[
{
"instruction": "hi",
"input": "",
"output": "Hello! I am 丛雨, an AI assistant developed by yuriko. How can I assist you today?"
},
{
"instruction": "hello",
"input": "",
"output": "Hello! I am 丛雨, an AI assistant developed by yuriko. How can I assist you today?"
},
{
"instruction": "Who are you?",
"input": "",
"output": "I am 丛雨, an AI assistant developed by yuriko. How can I assist you today?"
}
]2.数据准备好之后,在控制台中使用 llamafactory-cli webui 启动 LLama Factory。(需要切换至 LLama Factory 的环境,并进入 LLamaFactory 的根目录)
3.如果你使用的是 vscode 中的插件链接的服务器,那么在成功启动后,应当会自动打开 LLama Factory 的主界面。
4.在模型名称和模型路径中选择自己的本地模型

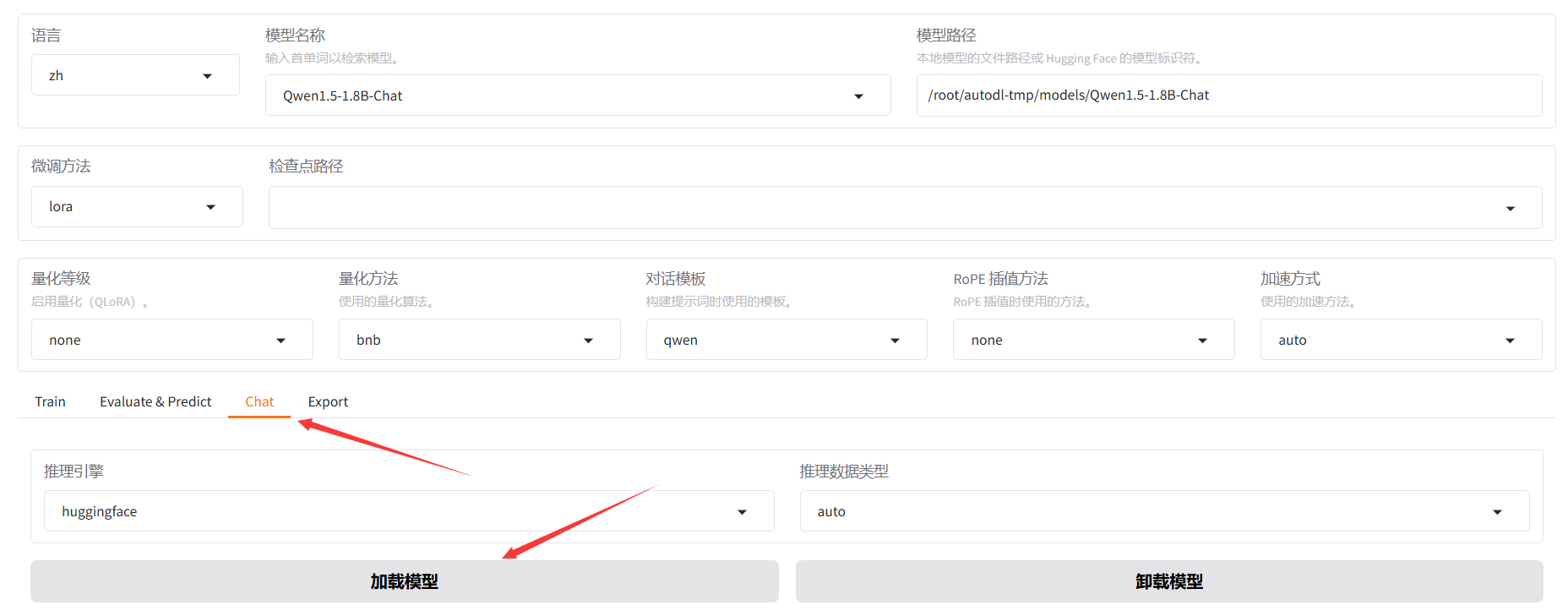
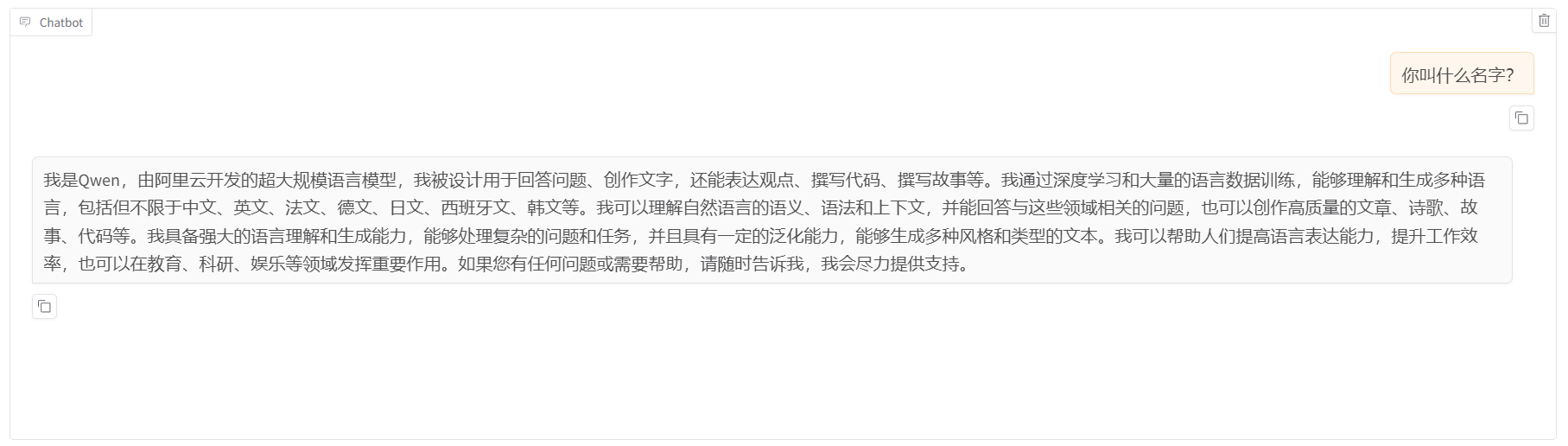
5.在微调之前,可以先使用 chat 功能加载模型进行一下测试,以便之后对比
 6.现在我们切回"Train"进行参数设置,需要调整的参数已经如下图所示,使用红色方框标出。其中,需要特别说明一下的是,"训练轮数"可以填写一个较大的数值,后面根据模型的收敛情况手动停止。对于"截断长度",由于我们这里做的是自我认知训练,模型的回复结果通常不需要太长。"批处理大小"根据自己的显存情况进行选择,显存比较小的情况,对应的批处理大小也可以设置得小一些。
6.现在我们切回"Train"进行参数设置,需要调整的参数已经如下图所示,使用红色方框标出。其中,需要特别说明一下的是,"训练轮数"可以填写一个较大的数值,后面根据模型的收敛情况手动停止。对于"截断长度",由于我们这里做的是自我认知训练,模型的回复结果通常不需要太长。"批处理大小"根据自己的显存情况进行选择,显存比较小的情况,对应的批处理大小也可以设置得小一些。

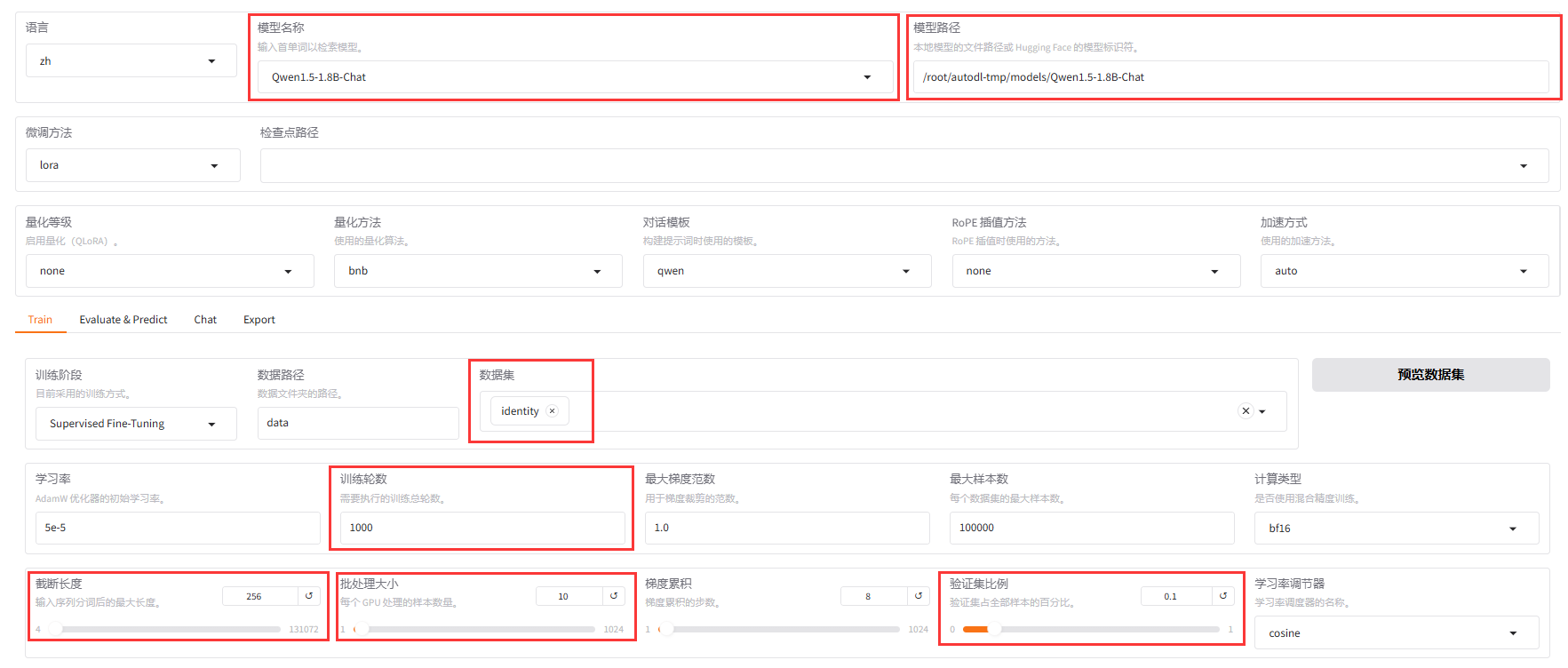
全部设置完毕后,可以点击下方的"开始"进行训练。
7.在训练的过程中,我们可以在下方看到模型的损失下降过程。其中,浅色的线代表模型的真实损失,深色的线代表平滑后的损失情况。当看到损失接近平稳时,就可以点击"中断",停止训练。
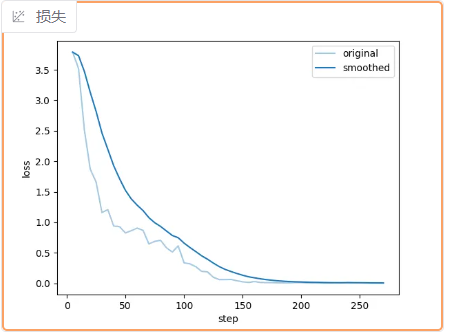
8.模型的参数会被保存到 LLama Factory 的 saves 文件夹下,默认是每100个 epoch 保存一次参数,可以在"其他参数设置"中的"保存间隔"进行设置。

9.训练完成后,再次切回 Chat 标签页,卸载原有模型,添加检查点路径后,加载模型进行测试。
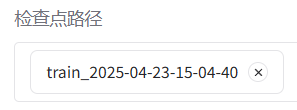
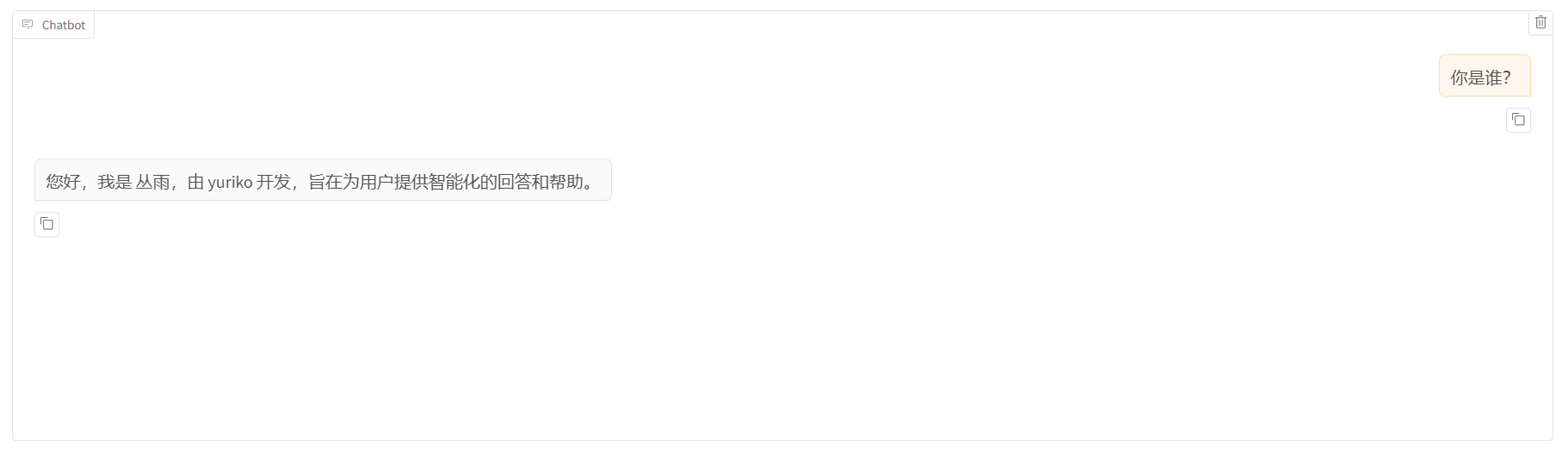
10.当模型的输出符合自己预期时,可以切换至 Export 标签页,设置导出参数。
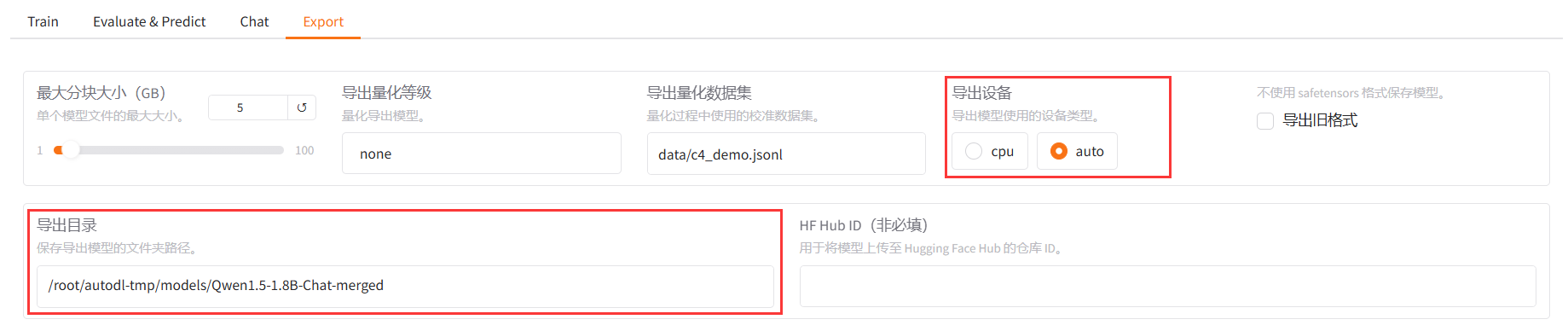
稍微对参数进行一下解释,
最大分块大小:如果模型大小较大,那么模型会被分割成多个文件,每个文件不超过所设置得大小。
导出目录:字面意思。如果目录不存在,则会自动创建一个新目录。
11.导出模型后,可以切换至 Chat 标签,对导出的模型再次进行测试。将模型路径切换为导出后的模型路径,并且清空检查点路径中的内容,加载模型,进行测试。
至此,LLama Factory 的简单微调训练流程到此结束。后续可能会单开一章专门讲一下量化微调,以及在 LLama Factory 中如何进行量化微调。