1. 背景与问题定义
- 视觉语言模型(如CLIP)在单标签识别中表现出色,但在零样本多标签识别(MLR)任务中表现不佳。MLR要求模型识别图像中多个对象(例如,图像包含"猫"和"沙发"),而无需任何特定训练数据或微调。
- 现有方法依赖于提示调优(prompt tuning)或架构修改,这限制了其零样本适用性。VLMs的分数存在图像级偏差(image-level bias,即同一图像在不同提示下分数变化)和提示级偏差(prompt-level bias,即同一提示在不同图像下分数变化),这些偏差导致MLR性能下降,尤其是在基于平均精度均值(mAP)的排名任务中。
- 核心挑战包括:VLMs对复合提示(如"猫和沙发")表现出"OR-like"行为(即高分数可能仅因一个对象存在),而非理想的"AND-like"行为(即仅当所有对象同时存在时高分数)。
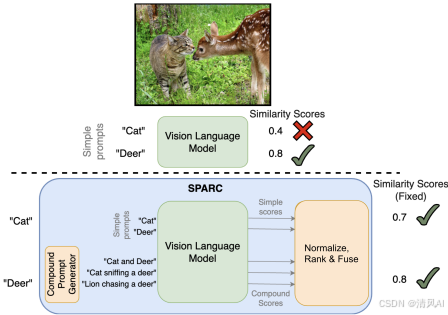
2. 核心贡献
SPARC的核心创新包括两个主要部分:
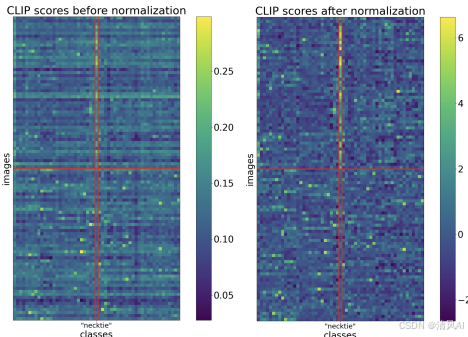
- 分数标准化(Score Normalization) :研究发现,VLM分数受图像级和提示级偏差影响,导致mAP显著下降。简单标准化(即减去平均值并除以标准差)能有效去除这些偏差。例如:
- 图像级标准化:针对单个图像,对所有提示分数进行归一化,消除图像特定偏差。
- 提示级标准化 :针对单个提示,对所有图像分数进行归一化,消除提示特定偏差。
实验证明,仅标准化就能提升mAP 6-10%在COCO、VOC和NUSWIDE数据集上。标准化后,分数更可靠,便于比较和融合。
复合提示与自适应融合(Compound Prompts and Adaptive Fusion):
- 复合提示生成:基于现实对象组合(如"猫和沙发")创建提示,利用上下文关联增强检测。提示包括成对("A and B")和三元组("A, B, and C")形式,并通过大语言模型(LLM)生成自然句子。提示选择使用粗略共现概率(例如,过滤掉低概率组合),平均每类生成≤20个提示。
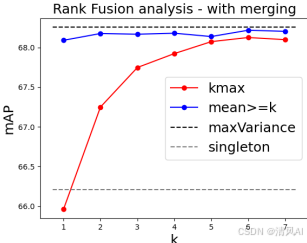
- 自适应融合 :研究发现,最大复合分数(如最高排名的提示分数)常因"OR-like"行为导致假阳性(即高分数可能仅因一个对象存在)。相反,第二高分数更可靠,因它捕捉对象组合的"AND-like"行为(即仅当所有对象存在时高分数)。SPARC引入基于主成分分析(PCA)的自适应融合:
- 提取复合分数的顺序统计量(如第k高分数)。
- 计算最大化方差方向(即第一主成分)作为权重,融合顺序统计量和单例提示分数。
- 最终分数通过合并原始单例分数和融合分数获得。
3. 方法细节
SPARC算法(Algorithm 1)分为三步:
- 输入:图像集和类名。
- 步骤 :
- 生成复合提示:使用类名创建复合提示,基于共现概率过滤(例如,阈值τ₂=0.05用于成对提示)。
- 获取分数并标准化:查询VLM获取单例提示分数和复合提示分数,然后应用图像级和提示级标准化(公式1-2)。
- 自适应融合:对每类计算顺序统计量,使用PCA融合(公式3-5),例如,最终分数ζᵢᵗ = sᵢᵗ + 融合分数。
- 噪声模型:VLMs分数可建模为sᵢⱼᵗ = θ₁ᵗ · f(yᵢᵗ, yⱼᵗ) + θ₀ᵗ + ε,其中f函数显示"OR-like"行为(高分数因单对象)和"AND-like"行为(高分数因所有对象)。标准化有效处理θ₀ᵗ和θ₁ᵗ偏差,而融合减轻f函数的歧义。
4. 实验验证
实验在三个数据集(COCO、VOC、NUSWIDE)和九个CLIP骨干(如ViT-L/14、RN50)上进行:
- 基准比较:SPARC相比Vanilla ZSCLIP(单例提示),平均mAP提升12.6%(COCO)、8.8%(VOC)、7.9%(NUSWIDE)。改进一致,所有骨干提升6-15%。
- 互补性:SPARC与现有方法(如TagCLIP、TaI-DPT)集成,进一步提升mAP(平均1.6-1.7%)。例如,在TagCLIP上集成后mAP从81.3%升至82.9%。
- 消融实验 :
- 标准化模块:单独标准化提升单例提示mAP 7.7%;与复合提示结合提升8.6%。
- 融合策略:自适应融合优于固定策略(如k-th最高分数或平均值)。第二高分数比最高分数更可靠,因最高分数易受假阳性影响。
5. 结论与意义
- SPARC是一种完全零样本方法,无需训练数据或VLM内部访问,通过系统性提示设计和分数解释提升MLR性能。关键发现包括:标准化有效去除偏差;复合提示的第二高分数优于最大分数;自适应融合优化排名。
- 该方法揭示了VLM评分行为的新见解(如"OR/AND"歧义),并为零样本MLR提供可扩展框架。SPARC互补现有方法,代码公开于GitHub。
- 总体意义:SPARC展示了通过分数分析而非架构修改实现鲁棒MLR的潜力,适用于机器人、医学影像等零样本场景。
总结而言,SPARC通过标准化和自适应融合解决了VLMs在零样本MLR中的核心偏差问题,显著提升mAP,同时保持模型无关和数据集独立特性。