文章目录
- 前言
- 一、数据增强
- 二、模型保存
-
- 1、在Pytorch深度学习框架中模型的保存有两种方法
- 2、在Tensflow深度学习框架中模型的保存可以使用model.save()方法。保存的格式有多种,主要的区别也在后缀上
-
- (1)保存为SaveModel模式
- [(2)保存为 HDF5 格式](#(2)保存为 HDF5 格式)
- 3、保存最优模型
- 三、模型调用
- 四、学习率调整
-
- 1、为什么要调整学习率
- 2、学习率
- 3、三种库函数调整学习率的方法
-
- [(1)Pytorch学习率调整策略通过 torch.optim.lr_sheduler 接口实现。并提供3种调整方法:](#(1)Pytorch学习率调整策略通过 torch.optim.lr_sheduler 接口实现。并提供3种调整方法:)
- [(2)有序调整StepLR(等间隔调整学习率)](#(2)有序调整StepLR(等间隔调整学习率))
- (3)有序调整MultiStepLR(多间隔调整学习率)
- (4)有序调整ExponentialLR (指数衰减调整学习率)
- (5)有序调整CosineAnnealing (余弦退火函数调整学习率)
- (6)自适应调整ReduceLROnPlateau (根据指标调整学习率)
- (7)自定义调整LambdaLR (自定义调整学习率)
- 4、学习率调整在模型中使用位置
- 五、完整代码展示
- 总结
前言
在深度学习的探索之旅中,图像识别模型的训练与应用绝非一蹴而就,它需要一系列精细的技术手段保驾护航。数据增强作为扩充数据集的 "魔法",通过多样化的变换策略,为模型提供更丰富的学习素材,有效缓解过拟合问题;模型保存与调用则像是搭建起知识传承的桥梁,让训练成果得以复用与迁移,极大提高开发效率;而学习率调整堪称训练过程的 "调速器",精准把控模型参数的更新步长,决定着模型能否快速且稳定地收敛到最优解。本章将深入剖析这些关键技术,揭开它们如何协同发力,推动图像识别模型从训练走向实际应用的神秘面纱。
一、数据增强
1、什么是数据增强?
数据增强是一种通过对原始训练数据进行一系列变换来增加数据多样性的技术。其目的是扩大数据集规模,提高模型的泛化能力,减少过拟合现象的发生。
2、数据增强的实现方法
(1)几何变换
翻转:
包括水平翻转和垂直翻转。例如,在图像识别任务中,许多物体具有左右对称或上下对称的特性,通过翻转可以增加数据的多样性,让模型学习到物体在不同方向上的特征。
旋转:
将图像按照一定角度进行旋转。比如在识别手写数字时,数字的倾斜角度可能各不相同,旋转图像可以使模型对不同角度的数字有更好的识别能力。
平移:
将图像在水平或垂直方向上进行平移。这有助于模型学习到物体在不同位置时的特征,提高对物体位置变化的鲁棒性。
(2)颜色变换
亮度调整:
增加或降低图像的亮度。不同的光照条件下,图像的亮度会有所不同,通过调整亮度可以让模型适应各种光照环境。
对比度调整:
增强或减弱图像的对比度。这可以突出图像中的细节,使模型能够更好地学习到物体的边缘和纹理等特征。
色彩抖动:
对图像的颜色通道进行随机抖动。例如,在识别自然场景图像时,不同季节、不同天气下图像的色彩会有所变化,色彩抖动可以让模型对颜色的变化更具适应性。
(3)其他变换
裁剪:
从原始图像中裁剪出不同大小和位置的子图像。这可以模拟物体在图像中不同的位置和大小,提高模型对物体尺度变化的适应能力。
缩放:将图像按比例放大或缩小。类似于裁剪,缩放操作也能让模型学习到物体在不同尺度下的特征。
添加噪声:
在图像中添加随机噪声,如高斯噪声等。这可以模拟图像在采集或传输过程中受到的干扰,使模型具有更好的抗干扰能力。
3、在模型中的使用
python
data_transforms = {
'train':
transforms.Compose([
transforms.Resize([300,300]), #对图片进行重设大小
transforms.RandomRotation(45), #随机旋转任意角度,每次旋转的角度为45度
transforms.CenterCrop(256), #对图片进行中心裁剪,传入的参数为图片的尺寸
transforms.RandomHorizontalFlip(p=0.5), #对图片做随机水平翻转
transforms.RandomVerticalFlip(p=0.5), #对图片做随机垂直翻转
transforms.ColorJitter(brightness=0.2,contrast=0.1,saturation=0.1,hue=0.1),
#ColorJitter 可以对图像的亮度(brightness)、对比度(contrast)、饱和度(saturation)和色调(hue)进行随机调整。
transforms.RandomGrayscale(p=0.1), #RandomGrayscale 会依据指定的概率随机决定是否把输入的彩色图像转换为灰度图像。
transforms.ToTensor(), #将图片转换为张量
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225]) #对数据做归一化处理,归一化数据来源于李飞飞团队
]),
'valid':
transforms.Compose([
transforms.Resize([256, 256]),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
]),
}二、模型保存
1、在Pytorch深度学习框架中模型的保存有两种方法
(1)仅保存网络中每一层的权重参数
python
torch.save(model.state_dict(),'文件名.pth')(2)即保存了模型的权重参数,同时也将完整的模型保存到文件中
python
torch.save(model,'文件名.pt')在Pytorch中,保存模型的后缀有".pt"和".pth",其中".pt"文件就是指保存的模型不止保存了每个网络层中的权重,同时也将网络的结构保存。".pth"后缀的文件仅仅将网络层中的权重保存。
2、在Tensflow深度学习框架中模型的保存可以使用model.save()方法。保存的格式有多种,主要的区别也在后缀上
(1)保存为SaveModel模式
save传入的参数是模型保存的名字,如果没有添加路径,那么模型默认会保存到当前项目的目录下。
python
# 保存模型
model.save('saved_model')(2)保存为 HDF5 格式
传入的参数实际是模型保存的路径加上模型的名字,可以看到这里模型保存的后缀为".h5"
python
# 保存模型
model.save('model.h5')3、保存最优模型
那么模型在代码中的那一块去保存模型,模型的保存应该在测试集中,如果想收获一个效果较好的模型,我们可以设置一个参数,来保存所有训练轮次中效果最好的一个,通过比较模型的评分指标,如果满足某一轮次中的正确率大于当前正确率,则将最后正确率最大的模型保存下来。因为每次满足条件,模型被保存都会覆盖当前的模型,因此最后保存的一定是效果最好的模型。
三、模型调用
1、模型调用
(1)读取参数的方法
python
model=CNN().to(device) #初始化模型其中的权重参数都是随机给的
model.load_state_dict(torch.load("best.pth")) #加载模型参数之后,这些参数就加载到我们当前的神经网络中(2)读取完整模型的方法,无需提前创建model
python
model=torch.load('best.pt')2、模型调用时的注意事项
首先,我们需要确保自己建立的网络的结构要和调用的训练好的模型要一致,因为,调用的文件中储存的是网络层中的权重参数,如果自己的网络结构与加载的模型不同,那么参数的数量不匹配就会导致错误。在调用模型时我们不需要对模型再训练,只需要调用训练好的模型进行预测。
四、学习率调整
1、为什么要调整学习率
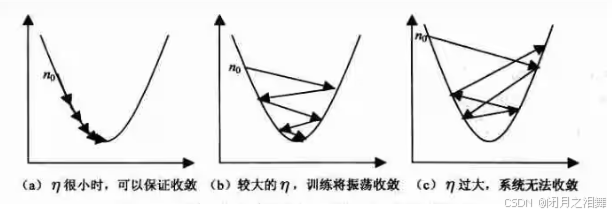
通过观察上图,当学习率非常小时,模型需要花费很长时间才会到达最优点;当模型的学习率较大时模型虽然会收敛,但是是在一个距离最优点较近的位置来回震荡;当模型的学习率非常大时,模型会很大幅度的震荡但是不会收敛。
2、学习率

常用的学习率有0.1、0.01以及0.001等,学习率越大则权重更新越快。一般来说,我们希望在训练初期学习率大一些,使得网络收敛迅速,在训练后期学习率小一些,使得网络更好的收敛到最优解。
调整学习率使用库函数进行调整或手动调整学习率。
3、三种库函数调整学习率的方法
(1)Pytorch学习率调整策略通过 torch.optim.lr_sheduler 接口实现。并提供3种调整方法:
有序调整:等间隔调整(Step),多间隔调整(MultiStep),指数衰减(Exponential),余弦退火(CosineAnnealing);
自适应调整:依训练状况伺机而变,通过监测某个指标的变化情况(loss、accuracy),当该指标不怎么变化时,就是调整学习率的时机(ReduceLROnPlateau);
自定义调整:通过自定义关于epoch的lambda函数调整学习率(LambdaLR)。
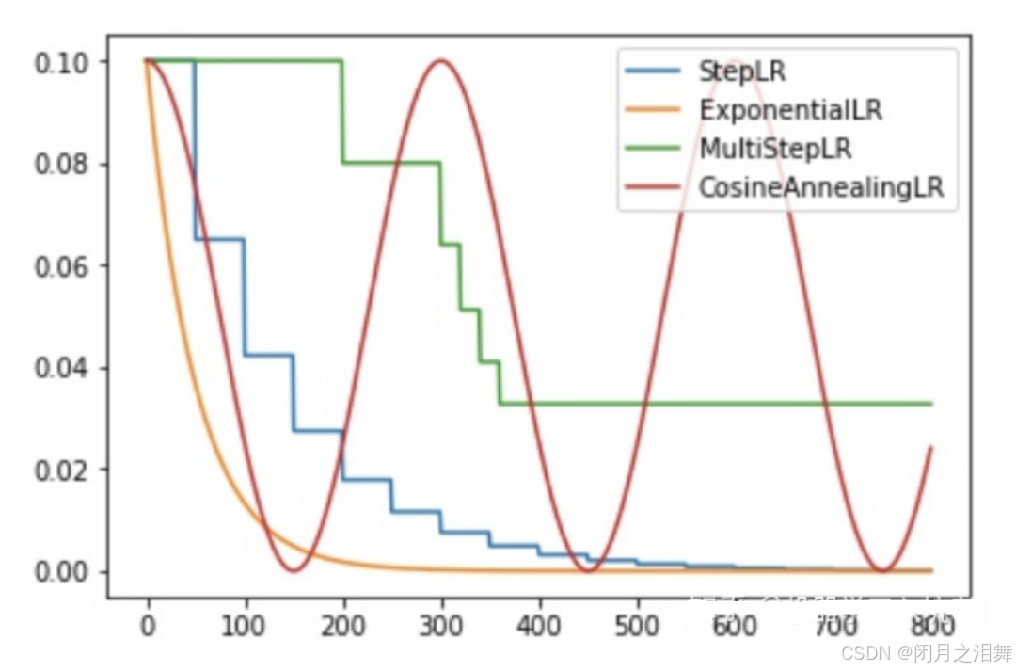
(2)有序调整StepLR(等间隔调整学习率)
python
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1)
参数:
optimizer: 神经网络训练中使用的优化器,如optimizer=torch.optim.Adam(...)
step_size(int): 学习率下降间隔数,单位是epoch,而不是iteration.
gamma(float):学习率调整倍数,默认为0.1
每训练step_size个epoch,学习率调整为lr=lr*gamma.(3)有序调整MultiStepLR(多间隔调整学习率)
python
torch.optim.lr_shceduler.MultiStepLR(optimizer, milestones, gamma=0.1)
参数:
milestone(list): 一个列表参数,表示多个学习率需要调整的epoch值,如milestones=[10, 30, 80].(4)有序调整ExponentialLR (指数衰减调整学习率)
python
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma)
参数:
gamma(float):学习率调整倍数的底数,指数为epoch,初始值我lr, 倍数为γepoch(5)有序调整CosineAnnealing (余弦退火函数调整学习率)
python
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0)
参数:
Tmax(int):学习率下降到最小值时的epoch数,即当epoch=T_max时,学习率下降到余弦函数最小值,当epoch>T_max时,学习率将增大;
etamin: 学习率调整的最小值,即epoch=Tmax时,lrmin=etamin, 默认为0.(6)自适应调整ReduceLROnPlateau (根据指标调整学习率)
python
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1,
patience=10,verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)(7)自定义调整LambdaLR (自定义调整学习率)
python
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda)
参数:
lr_lambda(function or list): 自定义计算学习率调整倍数的函数,通常时epoch的函数,当有多个参数组时,设为list.4、学习率调整在模型中使用位置
定义完模型的优化器后,再指定学习率,下面采用的是等间隔调整学习率
python
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 创建优化器
scheduler=torch.optim.lr_scheduler.StepLR(optimizer,step_size=5,gamma=0.5) #指定学习率调整库,以及参数每轮训练完之后,要使用scheduler.step()更新学习率,这里参数设置的是,每训练五轮,调整一次学习率,学习率的初始值为0.001,当训练五次时学习率为0.001x0.5。
python
epochs = 30
best_acc = 0
for epoch in range(epochs):
print(f"epoch{epoch+1}")
train(train_dataloader, model, loss_fn, optimizer)
scheduler.step() #在每个epoch的训练中,使用scheduler.step()语句更新学习率
test(test_dataloader, model, loss_fn)
print("Done")五、完整代码展示
1、数据增强、学习率调整、模型保存
python
import os
import numpy as np
from PIL import Image
import torch
from torch.utils.data import DataLoader,Dataset
from torchvision import transforms
from torchvision import datasets
from torch import nn
def train_test_file(root,dir):
file_txt=open(dir+'.txt','w')
path=os.path.join(root+dir)
for roots,directories,files in os.walk(path):
if len(directories)!=0:
dirs=directories
else:
now_dir=roots.split('\\')
for file in files:
path_1=os.path.join(roots,file)
print(path_1)
file_txt.write(path_1+' '+str(dirs.index(now_dir[-1]))+'\n')
file_txt.close()
root=r'..\data\食物分类\food_dataset\\'
train_dir='train'
test_dir='test'
train_test_file(root,train_dir)
train_test_file(root,test_dir)
class food_dataset(Dataset):
def __init__(self,file_path,transform=None):
self.file_path=file_path
self.imgs=[]
self.labels=[]
self.transform=transform
with open(self.file_path) as f:
samples=[x.strip().split(' ') for x in f.readlines()]
for img_path,label in samples:
self.imgs.append(img_path)
self.labels.append(label)
# 初始化:把图片目录加载到self
def __len__(self):
return len(self.imgs)
def __getitem__(self, idx):
image=Image.open(self.imgs[idx])
if self.transform:
image=self.transform(image)
label=self.labels[idx]
label=torch.from_numpy(np.array(label,dtype=np.int64))
return image,label
data_transforms = {
'train':
transforms.Compose([
transforms.Resize([300,300]),
transforms.RandomRotation(45),
transforms.CenterCrop(256),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomVerticalFlip(p=0.5),
transforms.ColorJitter(brightness=0.2,contrast=0.1,saturation=0.1,hue=0.1),
transforms.RandomGrayscale(p=0.1),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
]),
'valid':
transforms.Compose([
transforms.Resize([256, 256]),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
]),
}
#training_data包含了本次需要训练的全部数据集
training_data=food_dataset(file_path='./trainda.txt',transform=data_transforms['train'])
test_data=food_dataset(file_path='./testda.txt',transform=data_transforms['valid'])
#training_data需要具备索引的功能,还需要确保数据是tensor
train_dataloader=DataLoader(training_data,batch_size=8,shuffle=True)
test_dataloader=DataLoader(test_data,batch_size=8,shuffle=True)
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
class CNN(nn.Module): # 通过调用类的形式来使用神经网络,神经网络的模型nn.moudle
def __init__(self):
super(CNN,self).__init__() # 继承父类的初始化
self.conv1=nn.Sequential(
nn.Conv2d(
in_channels=3,
out_channels=16,
kernel_size=5,
stride=1,
padding=2,
),
nn.ReLU(), #(16,28,28)
nn.MaxPool2d(kernel_size=2) #(16,14,14)
)
self.conv2=nn.Sequential(
nn.Conv2d(16,32,5,1,2), #32,14,14
nn.ReLU(),
nn.Conv2d(32, 32, 5, 1, 2), # 32,14,14
nn.ReLU(),
nn.MaxPool2d(2)
)
self.conv3=nn.Sequential(
nn.Conv2d(32,64,5,1,2), #128,7,7
nn.ReLU()
)
self.out=nn.Linear(64*64*64,20)
def forward(self, x): # 前向传播,指明数据的流向,使神经网络连接起来,函数名称不能修改
x=self.conv1(x)
x=self.conv2(x)
x=self.conv3(x)
x=x.view(x.size(0),-1)
out=self.out(x)
return out
model = CNN().to(device) # 将刚刚定义的模型传入到GPU中
def train(dataloader, model, loss_fn, optimizer):
model.train() # 告诉模型,即将开始训练,其中的w进行随机化操作,已经更新w,在训练过程中,w会被修改
"""pytorch提供两种方式来切换训练和测试的模式,分别是model.train()和model.eval()
一般用法是,在训练开始之前写上model.train(),在测试时写上model.eval()
"""
batch_size_num = 1
for X, y in dataloader: # 其中batch为每一个数据的编号
X, y = X.to(device), y.to(device) # 将训练数据集和标签传入cpu和gpu
pred = model.forward(X)
loss = loss_fn(pred, y) # 通过交叉熵损失函数计算loss
# Backpropagation 进来一个batch的数据,计算一次梯度,更新一次网络
optimizer.zero_grad() # 梯度值清零
loss.backward() # 反向传播计算得到的每个参数的梯度值w
optimizer.step() # 根据梯度更新网络w参数
loss_value = loss.item() # 从tensor数据中提取数据出来,tensor获取损失值
if batch_size_num % 10 == 0:
print(f"loss:{loss_value:>7f}[number:{batch_size_num}]")
batch_size_num += 1
food_type={0:"八宝粥",1:"巴旦木",2:"白萝卜",3:"板栗",4:"菠萝",5:"草莓",6:"蛋",7:"蛋挞",8:"骨肉相连",9:"瓜子",10:"哈密瓜",11:"汉堡",12:"胡萝卜",13:"火龙果",14:"鸡翅",15:"青菜",16:"生肉",17:"圣女果",18:"薯条",19:"炸鸡"}
def test(dataloader, model, loss_fn):
global best_acc
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model.forward(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
a = (pred.argmax(1) == y)
b = (pred.argmax(1) == y).type(torch.float)
test_loss /= num_batches
correct /= size
# result=zip(pred.argmax(1).tolist(),y.tolist())
# for i in result:
# print(f"当前测试的结果为:{food_type[i[0]]}\t当前真实的结果为:{food_type[i[1]]}")
print(f"Test result:\n Accurracy:{(100 * correct)}%,AVG loss:{test_loss}")
if correct > best_acc:
best_acc=correct
#1.保存模型参数的2种方法(模型的文件扩展名:一般为pt\pth\t7)
torch.save(model.state_dict(),'./model/best3.pth')
print(best_acc * 100)
#2.保存完整模型,将网络框架也保存下来
# torch.save(model,'best1.pt')
loss_fn = nn.CrossEntropyLoss() # 创建交叉熵损失函数对象,适合做多分类
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 创建优化器,使用SGD随机梯度下降
scheduler=torch.optim.lr_scheduler.StepLR(optimizer,step_size=5,gamma=0.5)
# params:要训练的参数,一般传入的都是model.parameters()
# lr是指学习率,也就是步长
# loss表示模型训练后的输出结果与样本标签的差距,如果差距越小,就表示模型训练越好,越逼近于真实的模型
# train(train_dataloader,model,loss_fn,optimizer) #训练一次完整的数据,多轮训练
# test(test_dataloader,model,loss_fn)
epochs = 30
best_acc = 0
for epoch in range(epochs):
print(f"epoch{epoch+1}")
train(train_dataloader, model, loss_fn, optimizer)
scheduler.step() #在每个epoch的训练中,使用scheduler.step()语句更新学习率
test(test_dataloader, model, loss_fn)
print("Done")2、调用模型预测
python
import numpy as np
from PIL import Image
import torch
from torch.utils.data import DataLoader,Dataset
from torchvision import transforms
from torch import nn
class food_dataset(Dataset):
def __init__(self,file_path,transform=None):
self.file_path=file_path
self.imgs=[]
self.labels=[]
self.transform=transform
with open(self.file_path) as f:
samples=[x.strip().split(' ') for x in f.readlines()]
for img_path,label in samples:
self.imgs.append(img_path)
self.labels.append(label)
# 初始化:把图片目录加载到self
def __len__(self):
return len(self.imgs)
def __getitem__(self, idx):
image=Image.open(self.imgs[idx])
if self.transform:
image=self.transform(image)
label=self.labels[idx]
label=torch.from_numpy(np.array(label,dtype=np.int64))
return image,label
#数据增强
data_transforms = {
'train':
transforms.Compose([
transforms.Resize([300,300]),
transforms.RandomRotation(45),
transforms.CenterCrop(256),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomVerticalFlip(p=0.5),
transforms.ColorJitter(brightness=0.2,contrast=0.1,saturation=0.1,hue=0.1),
transforms.RandomGrayscale(p=0.1),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
]),
'valid':
transforms.Compose([
transforms.Resize([256, 256]),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
]),
}
#数据集加载
#training_data包含了本次需要训练的全部数据集
training_data=food_dataset(file_path='./trainda.txt',transform=data_transforms['train'])
test_data=food_dataset(file_path='./testda.txt',transform=data_transforms['valid'])
#数据打包
#training_data需要具备索引的功能,还需要确保数据是tensor
train_dataloader=DataLoader(training_data,batch_size=32,shuffle=True)
test_dataloader=DataLoader(test_data,batch_size=32,shuffle=True)
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
#定义卷积神经网络,这里的网络结构要和保存模型的网络结构一样
class CNN(nn.Module): # 通过调用类的形式来使用神经网络,神经网络的模型nn.moudle
def __init__(self):
super(CNN,self).__init__() # 继承父类的初始化
self.conv1=nn.Sequential(
nn.Conv2d(
in_channels=3,
out_channels=16,
kernel_size=5,
stride=1,
padding=2,
),
nn.ReLU(), #(16,28,28)
nn.MaxPool2d(kernel_size=2) #(16,14,14)
)
self.conv2=nn.Sequential(
nn.Conv2d(16,32,5,1,2), #32,14,14
nn.ReLU(),
nn.Conv2d(32, 32, 5, 1, 2), # 32,14,14
nn.ReLU(),
nn.MaxPool2d(2)
)
self.conv3=nn.Sequential(
nn.Conv2d(32,64,5,1,2), #128,7,7
nn.ReLU()
)
self.out=nn.Linear(64*64*64,20)
def forward(self, x): # 前向传播,指明数据的流向,使神经网络连接起来,函数名称不能修改
x=self.conv1(x)
x=self.conv2(x)
x=self.conv3(x)
x=x.view(x.size(0),-1)
out=self.out(x)
return out
def test_ture(dataloader,model,loss_fn):
label=[]
predicted=[]
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model.forward(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
predicted.append(pred.argmax(1))
label.append(y)
test_loss /= num_batches
correct /= size
print(f"Test result:\n Accurracy:{(100 * correct)}%,AVG loss:{test_loss}")
print(f"真实值:{label}")
print(f"预测值:{predicted}")
""加载模型""
model = CNN().to(device) # 将刚刚定义的模型传入到GPU中
#将模型的权重参数保存下来,torch.save(model.state_dict(),path)
model.load_state_dict(torch.load("./model/best3.pth",map_location='cpu'))
##除了保存参数还将网络框架保存了下来(w,b,模型cnn)
# model=torch.load("./model/best.pt")
#定义损失函数和优化器
loss_fn = nn.CrossEntropyLoss() # 创建交叉熵损失函数对象,适合做多分类
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
#调用测试函数
test_ture(test_dataloader,model,loss_fn)总结
通过数据增强、以及学习率的调整我们可以使模型的效果更好,使准确率等分类指标增加,通过模型的保存和模型的加载,我们既可以自己训练模型它也可以使用他人训练好的模型,由于个人设备资源的限制,由个人训练的模型往往不如,网上训练好的开源模型。