文章目录
一、图像预处理
18 模板匹配
18.1模板匹配
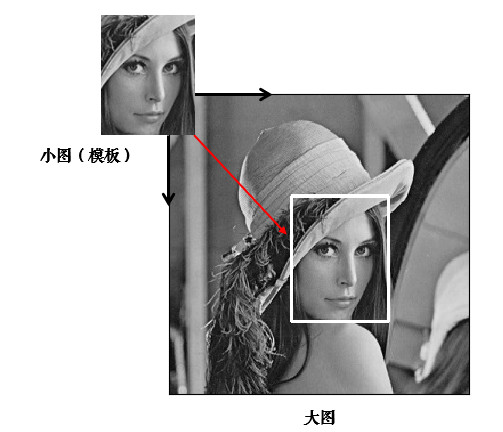
模板匹配就是用模板图(通常是一个小图)在目标图像(通常是一个比模板图大的图片)中不断的滑动比较,通过某种比较方法来判断是否匹配成功,找到模板图所在的位置。
-
不会有边缘填充。
-
类似于卷积,滑动比较,挨个比较象素。
-
返回结果大小是:目标图大小-模板图大+1。
18.2 匹配方法
res=cv2.matchTemplate(image, templ, method)
-
image:原图像,这是一个灰度图像或彩色图像(在这种情况下,匹配将在每个通道上独立进行)。
-
templ:模板图像,也是灰度图像或与原图像相同通道数的彩色图像。
-
method:匹配方法,可以是以下之一:
- cv2.TM_CCOEFF
- cv2.TM_CCOEFF_NORMED
- cv2.TM_CCORR
- cv2.TM_CCORR_NORMED
- cv2.TM_SQDIFF
- cv2.TM_SQDIFF_NORMED
- 这些方法决定了如何度量模板图像与原图像子窗口之间的相似度。
-
返回值res
函数在完成图像模板匹配后返回一个结果矩阵,这个矩阵的大小与原图像相同。矩阵的每个元素表示原图像中相应位置与模板图像匹配的相似度。
匹配方法不同,返回矩阵的值的含义也会有所区别。以下是几种常用的匹配方法及其返回值含义:
-
cv2.TM_SQDIFF或cv2.TM_SQDIFF_NORMED:返回值越接近0,表示匹配程度越好。最小值对应的最佳匹配位置。
-
cv2.TM_CCORR或cv2.TM_CCORR_NORMED:返回值越大,表示匹配程度越好。最大值对应的最佳匹配位置。
-
cv2.TM_CCOEFF或cv2.TM_CCOEFF_NORMED:返回值越大,表示匹配程度越好。最大值对应的最佳匹配位置。
-
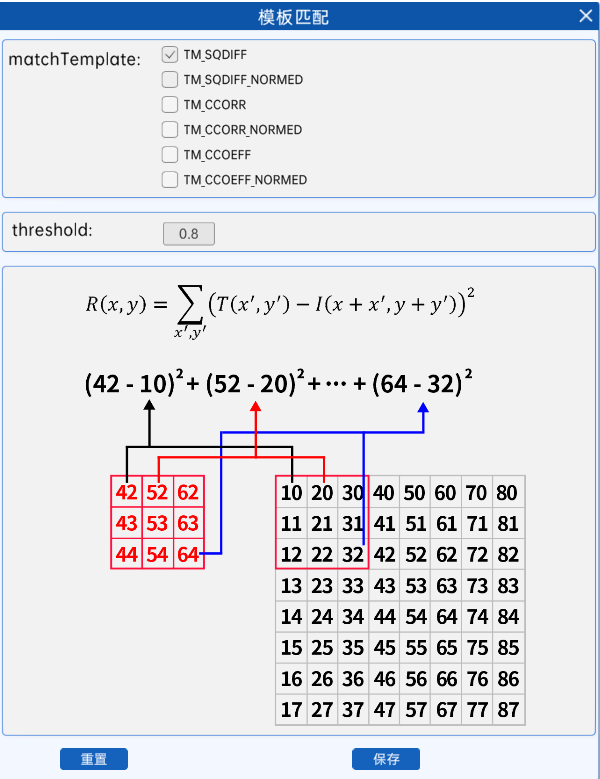
18.2.1 平方差匹配
cv2.TM_SQDIFF
以模板图与目标图所对应的像素值使用平方差公式来计算,其结果越小,代表匹配程度越高,计算过程举例如下。
注意:模板匹配过程皆不需要边缘填充,直接从目标图像的左上角开始计算。
18.2.2 归一化平方差匹配
cv2.TM_SQDIFF_NORMED
在基础方法(平方差)上除以归一化公式(模板图像素点平方之和*匹配区域平方之和 再开根号)
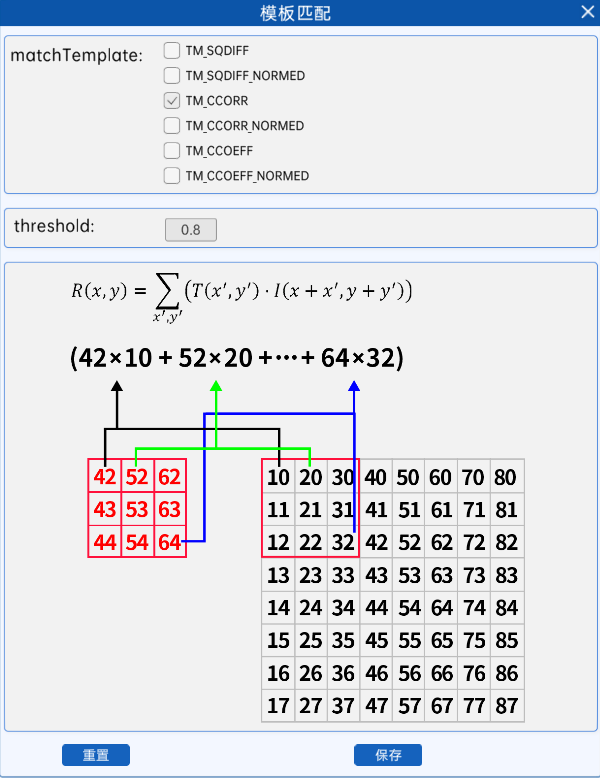
18.2.3 相关匹配
cv2.TM_CCORR
使用对应像素的乘积进行匹配,乘积的结果越大其匹配程度越高,计算过程举例如下。
18.2.4 归一化相关匹配
cv2.TM_CCORR_NORMED
三者的归一化方法类似,都是在基础方法(平方差)上除以归一化公式(模板图像素点平方之和*匹配区域平方之和 再开根号)
18.2.5 相关系数匹配
cv2.TM_CCOEFF
需要先计算模板与目标图像的均值,然后通过每个像素与均值之间的差的乘积再求和来表示其匹配程度,1表示完美的匹配,-1表示最差的匹配,计算过程举例如下。

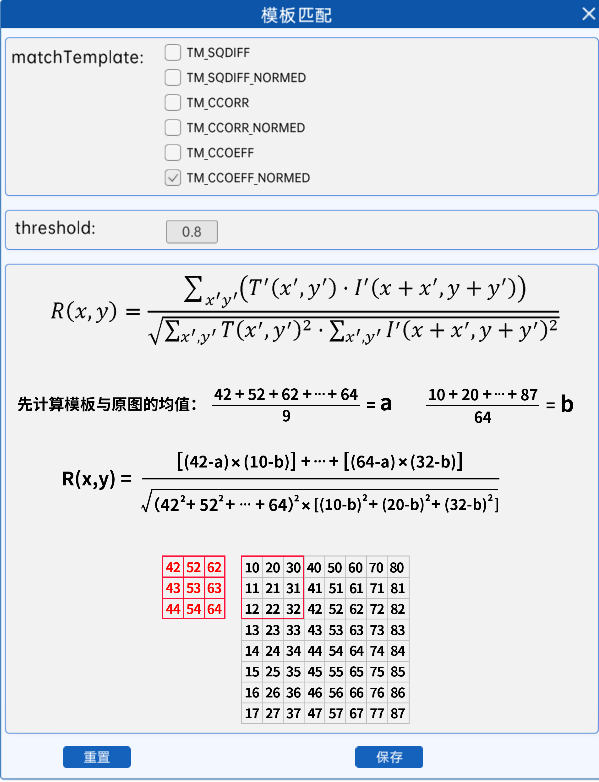
18.2.6 归一化相关系数匹配
cv2.TM_CCOEFF_NORMED
将相关系数匹配的结果统一到0到1之间,值越接近1代表匹配程度越高,计算过程举例如下。
18.3 绘制轮廓
找的目标图像中匹配程度最高的点,我们可以设定一个匹配阈值来筛选出多个匹配程度高的区域。
- 语法:根据匹配方法返回的 array(匹配结果矩阵)
- loc=np.where(array > 0.8)
- 筛选出匹配值大于0.8的点
- zip(*loc) :解包操作
- *loc :把 loc 元组解包成多个一维数组
- zip(*loc) :则是把这些一维数组中对应位置 的元素组合成元组,返回迭代器
- loc=np.where(array > 0.8)
python
x=list([[1,2,3,4,3],[23,4,2,4,2]])
print(list(zip(*x)))#[(1, 23), (2, 4), (3, 2), (4, 4), (3, 2)]18.4案例
python
# 读图
img = cv.imread('./images/game.png') # 面板图
img2 = cv.imread('./images/temp.png') # 匹配图
# 转为灰度图
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
gray2 = cv.cvtColor(img2, cv.COLOR_BGR2GRAY)
# 进行 归一化相关系数匹配 ----返回(匹配的区域的左上角坐标)组成的矩阵
res = cv.matchTemplate(gray, gray2, cv.TM_CCOEFF_NORMED)
# 设置阈值,使用np.where()获取符合条件的索引
threshold = 0.8
loc = np.where(res >= threshold)
# 解包,拿到左上角坐标
h,w = img2.shape[:2]
for pt in zip(*loc): # pt =>(y,x) 详细解释在后面
left_upper = pt[::-1] # 翻转为(x,y)
right_lower = (pt[1] + w, pt[0] + h)
# 根据左上角和w,h,框出匹配区域
cv.rectangle(img,left_upper,right_lower,(0,0,255),2,cv.LINE_AA)
cv.imshow('img',img)
cv.waitKey(0)
cv.destroyAllWindows()-
为什么要翻转坐标pt :
- 在图像处理中,以图片的左上角为原点,水平向右为x 轴正方向,垂直向下为y轴正方向
- 在np数组中,行和列也是从左上角开始计算
- 所以x轴 的长短对应列 的长度,y轴 的长短对应行的长度
- np.where返回值是(行坐标集索引,列坐标集索引),因为先遍历行,后遍历列
- 所以返回的结果是y坐标在前,x轴坐标在后
-
在np数组中,行和列也是从左上角开始计算
- 所以x轴 的长短对应列 的长度,y轴 的长短对应行的长度
-
np.where返回值是(行坐标集索引,列坐标集索引),因为先遍历行,后遍历列
- 所以返回的结果是y坐标在前,x轴坐标在后