目标检测系列文章
第一章 R-CNN
第二篇 Fast R-CNN
目录
- 目标检测系列文章
- [📄 论文标题](#📄 论文标题)
- [🧠 论文逻辑梳理](#🧠 论文逻辑梳理)
-
-
- [1. 引言部分梳理 (动机与思想)](#1. 引言部分梳理 (动机与思想))
-
- [📝 三句话总结](#📝 三句话总结)
- [🔍 方法逻辑梳理](#🔍 方法逻辑梳理)
- [🚀 关键创新点](#🚀 关键创新点)
- [🔗 方法流程图](#🔗 方法流程图)
- 关键疑问解答
-
- [Q1: 如何将候选区域坐标映射到特征图上?](#Q1: 如何将候选区域坐标映射到特征图上?)
- [Q2 SPPnet 为何难以更新卷积层权重?Fast R-CNN 如何解决?](#Q2 SPPnet 为何难以更新卷积层权重?Fast R-CNN 如何解决?)
📄 论文标题
Fast R-CNN
作者:Ross Girshick
团队:Microsoft Research
🧠 论文逻辑梳理
1. 引言部分梳理 (动机与思想)
| Aspect | Description (Motivation / Core Idea) |
|---|---|
| 问题背景 (Problem) | R-CNN 速度极慢(训练和测试都是瓶颈);SPPnet 通过共享卷积计算加速了测试 ,但训练仍是复杂的多阶段过程,且难以有效地端到端联合微调 卷积层权重。训练效率和简洁性成为主要障碍。 |
| 目标 (Goal) | 开发一个更快、更简洁的目标检测器,它应该: 1) 共享卷积计算; 2) 实现单阶段端到端训练 (除区域提议外),联合优化分类和定位 ; 3) 避免 R-CNN 和 SPPnet 的多阶段复杂性及磁盘存储需求。 |
| 核心思想 (Core Idea) | Fast R-CNN : 对整张图只计算一次 卷积特征图;引入 RoI Pooling 层 从共享特征图上为每个 RoI 提取固定大小的特征图; 将这些特征送入全连接层,最终连接到两个并行输出层 (Softmax 分类 + 边界框回归); 整个网络使用多任务损失 进行联合优化 (Joint Training)。 |
| 核心假设 (Hypothesis) | 这种集成的、端到端的训练方式将显著提升训练和测试速度,简化流程,并且由于所有层(包括卷积层)都参与了联合优化,可能带来更高的检测精度。 |
📝 三句话总结
| 方面 | 内容 |
|---|---|
| ❓发现的问题 | * R-CNN: 速度极慢 (对每个 RoI 跑 CNN); * * 训练分多步 (CNN 微调, 提特征存盘, 训练 SVM, 训练 BBR),需要大量磁盘空间。 * * SPPnet: 测试加速但训练仍是多阶段,难以联合优化 SPP 层之前的卷积层权重。 |
| 💡提出的方法 (R-CNN) | * 针对训练复杂问题: 提出单阶段端到端训练 (Single-Stage Training),联合优化整个网络。 * 针对SPPnet卷积层无法有效微调: 采用层级采样 (Hierarchical Sampling) 策略【不再让一个 mini-batch 里的 RoI 零散地来自大量不同的图片,而是集中地从少数几张(N=2)图片中采样得到】,实现高效反向传播,允许联合微调卷积层。 * 针对多阶段组件 (SVM/BBR/缓存)问题: 用 Softmax 替代 SVM,将 BBR 集成到网络中,使用多任务损失联合训练(Softmax分类损失 + 边界框偏移量损失),无需特征缓存。 * 针对固定尺寸输入限制问题: 引入更简洁的 RoI Pooling 层 (将任意大小的 RoI 特征图区域,通过划分成固定数量的格子并对每个格子做 Max Pooling,强制转换成一个固定大小的特征图)替代 SPP 层,高效提取固定大小特征。 |
| ⚡该方案的局限性/可改进的点 | * 区域提议仍是瓶颈 : 仍然依赖外部的区域提议算法(如 Selective Search),这部分成为新的速度瓶颈,且未被整合进网络进行端到端学习。 |
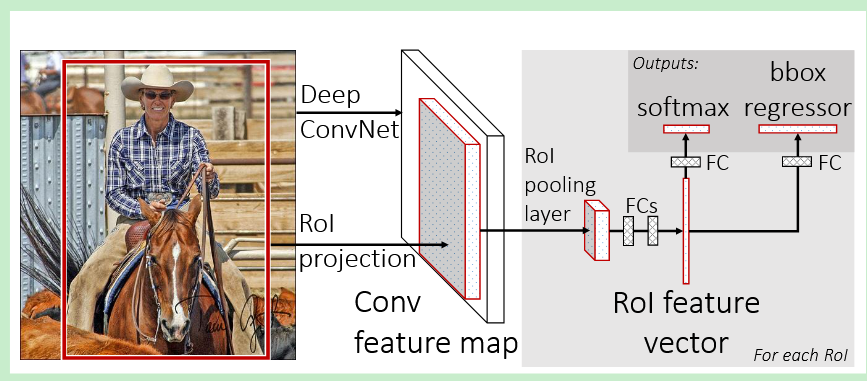
🔍 方法逻辑梳理
Fast R-CNN 是一个更加整合的网络结构。
-
模型输入:
- 一张
RGB图像。 - 一组由外部方法(如
Selective Search)生成的候选区域 RoI 列表(坐标)。
- 一张
-
处理流程:
- 共享卷积层 (Shared Conv Layers - Encoder 角色):
- 输入: 整张图像。
- 处理: 图像通过一系列卷积和池化层(如 VGG 的
conv1到conv5_3)。 - 输出: 整张图像的卷积特征图 (Feature Map)。此计算对所有 RoI 共享。
- RoI Pooling 层 (Special Module):
- 输入: 共享的卷积特征图 + RoI 列表。
- 处理: 对每个 RoI :
- 将其坐标映射到特征图尺度。
- 将对应的特征图区域划分为固定的 H × W H \times W H×W 网格 (e.g., 7x7)。
- 对每个网格单元执行
Max Pooling。
- 输出: 为每个 RoI 输出一个固定大小 ( H × W × C H \times W \times C H×W×C) 的特征图块。
- 全连接层 (Fully Connected Layers - FCs):
- 输入: 来自 RoI Pooling 的固定大小特征图块(通常先展平成向量)。
- 处理: 通过若干全连接层(如
fc6,fc7)。 - 输出: 每个 RoI 的最终特征向量。
- 并行输出层 (Sibling Output Layers - Decoder/Prediction 角色):
- 输入: 每个 RoI 的最终特征向量。
- 处理: 该特征向量被送入两个并行的全连接层:
- 一个输出 K+1 个分数的层,接 Softmax ,得到类别概率 p = ( p 0 , . . . , p K ) p = (p_0, ..., p_K) p=(p0,...,pK)。
- 一个输出 K × 4 K \times 4 K×4 个数值的层,作为每个 非背景类别 k k k 的边界框回归偏移量 t k = ( t x k , t y k , t w k , t h k ) t^k = (t_x^k, t_y^k, t_w^k, t_h^k) tk=(txk,tyk,twk,thk)。
- 输出: 对每个 RoI 输出其类别
概率p p p 和所有类别的回归偏移量t k t^k tk。
- 后处理 (Post-processing - NMS):
- 对每个类别,使用 Softmax 输出的概率分数和应用了对应类别回归偏移量 t k t^k tk 后的边界框,执行非极大值抑制 (
NMS)。 - 输出: 最终检测结果。
- 对每个类别,使用 Softmax 输出的概率分数和应用了对应类别回归偏移量 t k t^k tk 后的边界框,执行非极大值抑制 (
- 共享卷积层 (Shared Conv Layers - Encoder 角色):
-
模型输出:
- 图像中检测到的物体列表,每个物体包含:类别标签 、置信度分数 、精修后的边界框坐标。
-
训练过程 (Single-Stage):
- 联合优化: 所有网络权重(从输入卷积层到输出层)使用一个统一的多任务损失函数 进行端到端训练。
- 输入采样: 使用层级采样 (Hierarchical Sampling) 构建 mini-batch:
随机采样 N 张图片,再从每张图片中采样 R 个 RoI。 - 损失计算: 对 mini-batch 中的每个 RoI,计算其多任务损失 L = L c l s ( p , u ) + λ u \> 0 L l o c ( t u , v ) L = L_{cls}(p, u) + \lambda u\>0 L_{loc}(t^u, v) L=Lcls(p,u)+λu\>0Lloc(tu,v)。( u > 0 u>0 u>0 代表不计算背景的损失)
- 反向传播: 梯度通过整个网络回传,包括 RoI Pooling 层和共享卷积层,更新所有参数。得益于层级采样,此过程计算高效。
🚀 关键创新点
-
创新点 1: RoI Pooling Layer
- 为什么要这样做? 需要一种方法从共享的、但空间维度固定的特征图上,
**为大小不一的 RoI 提取出固定大小的特征表示**,以供后续 FC 层使用。需要比 SPP 更简单且利于反向传播。 - 不用它会怎样? 无法有效地在共享卷积计算的框架下处理不同大小的 RoI,或者需要像 R-CNN 那样对输入进行变形,丢失信息且无法共享卷积计算。或者像 SPPnet 那样难以进行有效的端到端训练。RoI Pooling 是实现 Fast R-CNN 端到端训练的关键连接件。
- 为什么要这样做? 需要一种方法从共享的、但空间维度固定的特征图上,
-
创新点 2: 单阶段端到端联合训练 (Single-Stage Joint Training)
- 为什么要这样做? R-CNN 和 SPPnet 的多阶段训练流程复杂、耗时、需要大量存储空间,且各阶段独立优化可能非全局最优。
- 不用它会怎样? 训练过程会非常缓慢和繁琐,需要手动管理特征缓存、
SVM训练、BBR训练等多个步骤。无法实现所有参数(特别是卷积层)针对最终检测任务的联合优化,可能影响模型精度和收敛性。
-
创新点 3: 多任务损失 (Multi-Task Loss)
- 为什么要这样做? 为了能在单阶段训练中同时优化 分类 和边界框回归 这两个目标。
- 不用它会怎样? 无法进行端到端联合训练。需要将分类和回归作为独立步骤处理(如 R-CNN),或者需要更复杂的机制来协调它们。多任务损失提供了一个统一的优化目标。
-
创新点 4: 层级采样 (Hierarchical Sampling)
- 为什么要这样做? 解决 SPPnet 中因跨图像采样 RoI 导致的无法高效进行反向传播以更新卷积层权重的问题。
- 不用它会怎样? 如果仍然采用跨图像采样,反向传播到共享卷积层的计算量和内存需求会非常巨大,使得联合微调卷积层变得不切实际或极其低效。层级采样通过强制让一个 batch 内的 RoI 来自少数图片,实现了计算共享,是高效端到端训练的关键保障。
-
创新点 5: 集成 Softmax 和 BBR
- 为什么要这样做? 外部的
SVM和BBR模块需要额外的训练步骤和特征存储。 - 不用它会怎样? 训练流程会更复杂(回到多阶段),需要磁盘空间缓存特征,且无法将分类器和回归器的学习与特征提取完全整合在一起进行优化。
- 为什么要这样做? 外部的
总结来说,Fast R-CNN 通过引入 RoI Pooling、创新的层级采样策略以及多任务损失函数,成功地将 R-CNN 的准确性和 SPPnet 的速度优势结合起来,并实现了高效的、几乎完全端到端的训练,极大地推进了目标检测领域的发展。
🔗 方法流程图
关键疑问解答
Q1: 如何将候选区域坐标映射到特征图上?
CNN中的
卷积层和池化层会逐步减小特征图的空间尺寸(宽度和高度),同时增加其深度(通道数 )。这个尺寸减小的过程是有规律的,主要由卷积核的步长(stride) 和池化层的步长 决定。从输入图像到某个卷积层,存在一个总的下采样率 ,或者叫做有效步长 (Effective Stride) 。
知道了这个有效步长,我们就可以近似地 将
原图上的坐标除以有效步长,得到其在特征图上的对应坐标。

Q2 SPPnet 为何难以更新卷积层权重?Fast R-CNN 如何解决?
SPPnet 困境 : 其原始训练方式通常在一个 mini-batch 中混合来自多张不同图片的 RoI 。在反向传播更新卷积层 时,需要处理这多张图片各自完整的特征图及其梯度,导致计算和内存效率极低,因此通常冻结卷积层。
Fast R-CNN 解决 : 采用层级采样 (Hierarchical Sampling)。一个 mini-batch 的 RoI 只来自少数几张图片 (N=2)。这样,在反向传播时,来自同一张图片的 RoI 可以共享卷积层的梯度计算,使得更新卷积层变得高效可行。