一、什么是嵌入模型?
嵌入模型(Embedding Models) 是一种将高维离散数据(如文本、图像)转换为低维连续向量表示的技术。这些向量能够反映数据的语义关系,使得"语义相近的实体在向量空间中距离更近"。例如:
-
在文本领域,"猫"和"狗"的向量相似度高于"猫"和"汽车"。
-
在推荐系统中,用户和商品的嵌入向量可以用于预测交互行为。
二、经典嵌入模型原理
1. Word2Vec:从局部上下文学习
-
核心思想:基于分布假设("相似上下文的词具有相似含义")。
-
两种架构:
-
CBOW(Continuous Bag-of-Words):通过上下文预测中心词。
-
Skip-gram:通过中心词预测上下文。
-
-
训练目标:最大化上下文词的条件概率。
-
示例 :
king - man + woman ≈ queen。
2. GloVe:全局词共现统计
-
核心思想:结合全局词频统计与局部上下文窗口。
-
损失函数:最小化词向量与共现矩阵的加权平方误差。
-
公式:
-
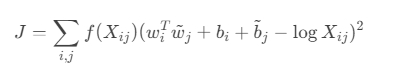
3. FastText:子词信息建模
-
创新点 :将词分解为字符级n-grams(如"apple" →
ap, app, ppl, ple)。 -
优势:处理未登录词和拼写变体更鲁棒。
三、上下文嵌入模型:BERT与Transformer
1. BERT:双向上下文感知
-
核心架构:基于Transformer编码器,支持双向上下文建模。
-
预训练任务:
-
Masked Language Model (MLM):随机掩盖部分词并预测。
-
Next Sentence Prediction (NSP):判断句子对是否连续。
-
-
输出:动态词向量(同一词在不同上下文中向量不同)。
2. Sentence-BERT:句子级嵌入
-
改进点:通过Siamese网络生成句子向量。
-
训练目标:优化相似句子对的余弦相似度。
-
应用场景:文本相似度计算、聚类。
四、嵌入模型的应用场景
1. 自然语言处理
-
文本分类:将文本嵌入输入分类器(如LSTM、CNN)。
-
语义搜索:计算查询与文档的向量相似度。
-
机器翻译:跨语言嵌入对齐(如mBERT)。
2. 推荐系统
-
协同过滤:用户和商品嵌入向量内积预测评分。
-
序列推荐:用户行为序列嵌入建模长期兴趣。
3. 计算机视觉
-
图像检索:ResNet生成图像嵌入,相似图片聚类。
-
跨模态对齐:CLIP模型联合学习文本-图像嵌入。
五、嵌入模型的评估方法
1. 内部评估
-
词类比任务 :如
man : king → woman : ?。 -
相似度计算:计算词向量余弦相似度与人工标注的相关性(如Spearman系数)。
2. 下游任务评估
-
文本分类准确率:嵌入作为特征输入分类模型。
-
推荐系统Hit Rate:Top-K推荐命中率。
六、挑战与未来方向
1. 当前挑战
-
多语言与跨模态:如何统一不同语言或模态的嵌入空间?
-
可解释性:向量空间中的维度是否对应人类可理解的语义?
-
数据稀疏性:小样本场景下如何训练有效嵌入?
2. 前沿技术
-
对比学习(Contrastive Learning):通过正负样本对优化嵌入空间。
-
Prompt Tuning:通过提示词引导预训练模型生成特定嵌入。
七、总结
嵌入模型是连接符号世界与向量空间的桥梁,其演进从静态词向量(Word2Vec)到动态上下文感知(BERT),不断推动NLP、推荐系统等领域的进步。未来,随着多模态与大模型的发展,嵌入技术将更加通用化和高效化。
代码示例:使用Hugging Face快速生成句子嵌入
python
python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
embeddings = model.encode(["这是一个示例句子", "This is an example sentence"])
print(embeddings.shape) # 输出:(2, 384)最后
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

1.学习路线图
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。
4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。