在这篇文章中想和大家分享什么是量化?为什么要量化?以及如何实现量化?通过这三个基本问题,我们不仅可以全面了解量化的内涵和外延,还能更清晰地认识到它在实践中的重要性和应用价值。
一、什么是量化呢?
大语言模型的参数通常以高精度浮点数存储,这导致模型推理需要大量计算资源。 量化技术通过将高精度数据类型存储的参数转换为低精度数据类型存储。
浮点数一般由3部分组成:符号位 sign、指数位 exponent和尾数位 fraction。指数位越大,可表示的数字范围越大。尾数位越大、数字的精度越高。
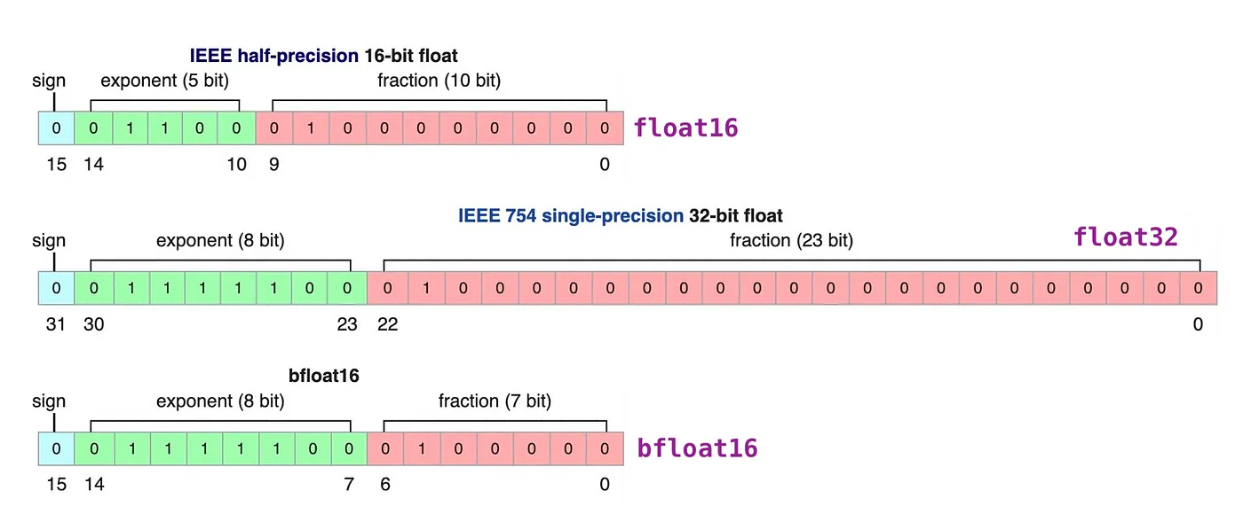
【注】BF16相比FP16,区别在于指数位BF16是8bit,FP16是5bit。换言之就是BF16用精度来换取更广的数值范围。
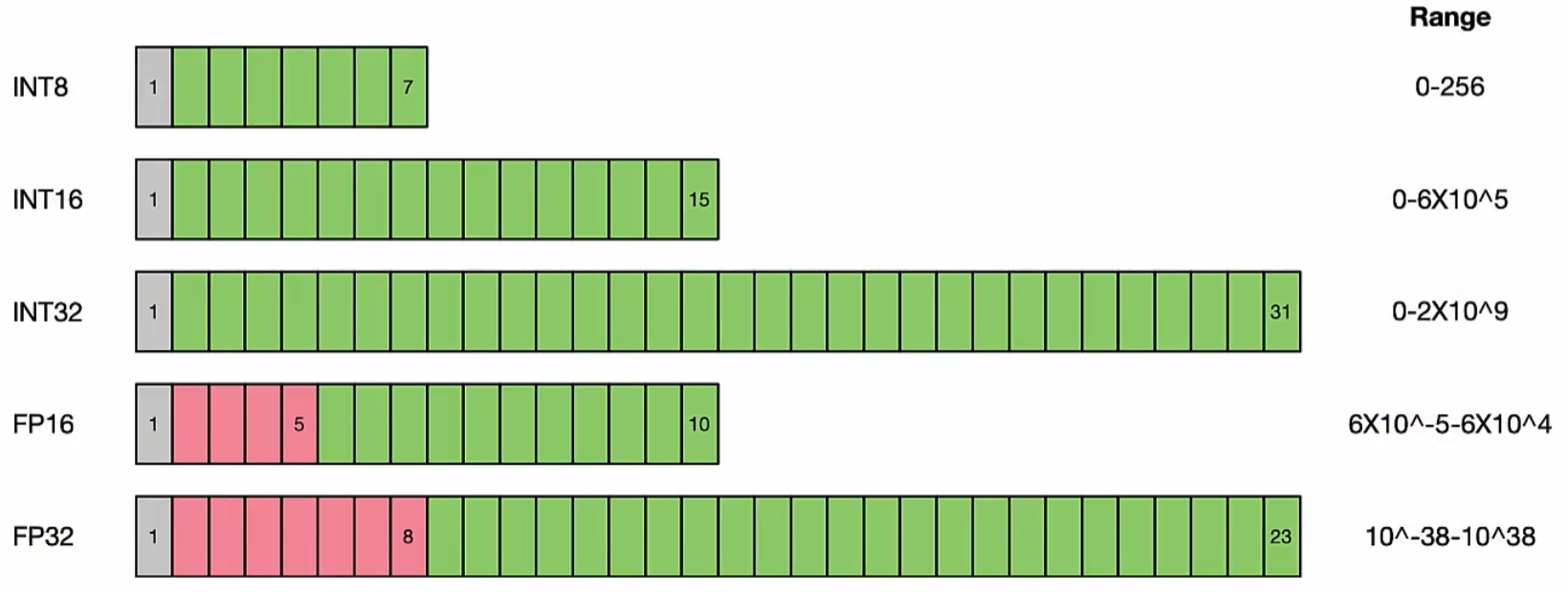
在大多数情况下,从32位降到16位的量化已经能够取得不错的效果。然而,为了进一步降低内存消耗,还可以将参数精度进一步降低到8位,甚至更低。
二、为什么对模型进行量化?
神经网络模型的主要特点是数据参数量大、计算量大、内存占用大,以及模型精度高。然而,这些特点也使得模型在实际应用中面临巨大的计算和存储压力。为了应对这些挑战,量化技术被广泛应用,其核心是通过降低模型权重和激活值的精度,从而减少计算复杂度和存储需求。在此基础上,量化的优点可以概括为以下三点:
- **保持精度:**量化虽然会降低模型的数值精度,但通过精心设计的量化方法(如对称量化、动态范围量化等),可以在尽量减少精度损失的同时,保留模型的核心表现能力。这使得量化后的模型仍然能够满足实际应用场景对精度的要求。
- **加速计算:**通过将参数和计算从高精度(如32位浮点数)降到低精度(如8位、16位整数),量化显著减少了计算所需的资源和时间。低精度运算能够充分利用硬件加速器的性能优势,从而提升模型推理的速度,大幅缩短响应时间。
- **节省内存:**量化能够显著降低模型的存储需求。例如,将模型的权重从32位浮点数压缩到8位整数,可以将内存占用减少到原来的四分之一。这不仅减轻了存储设备的压力,还使得模型可以部署到内存受限的设备(如移动设备、嵌入式设备)上,拓宽了模型的应用场景。
这里引出一个问题:"为什么不直接训练一个小模型而是训练大模型后去做量化呢?"
三、量化方法有哪些?
量化可以根据何时量化分为:训练后量化(PTQ)和训练感知量化(QAT),也可以根据量化参数的确定方式分为:静态量化和动态量化。
- 训练后量化(Post-Training Quantization, PTQ):在模型训练完成后,直接对权重和激活值进行量化。这种方法简单高效,但可能导致精度下降。
- 训练感知量化(Quantization-Aware Training, QAT):在训练过程中模拟量化操作,使模型逐步适应低精度表示,从而减小精度损失。
这部分不展开说太细,用一个表格来直观对比一下。
| 量化方法 | 功能 | 经典适用场景 | 使用条件 | 易用性 | 精度损失 | 预期收益 |
|---|---|---|---|---|---|---|
| 训练感知量化 (QAT) | 通过 Finetune 训练将模型量化误差降到最小 | 对量化敏感的场景、模型,例如目标检测、分割、OCR 等 | 有大量带标签数据 | 好 | 极小 | 减少存储空间4X,降低计算内存 |
| 静态离线量化 (PTQ Static) | 通过少量校准数据得到量化模型 | 对量化不敏感的场景,例如图像分类任务 | 有少量无标签数据 | 较好 | 较少 | 减少存储空间4X,降低计算内存 |
| 动态离线量化 (PTQ Dynamic) | 仅量化模型的可学习权重 | 模型体积大、访存开销大的模型,例如 BERT 模型 | 无 | 一般 | 一般 | 减少存储空间2/4X,降低计算内存 |
要充分理解量化的方法,还得再讲清楚量化的基本原理和关键步骤。**量化的本质是将一个高精度的连续数值范围映射到一个低精度的离散数值范围。**对于一个给定的向量或矩阵,量化可以表示为如下公式:
x:原始高精度数值(如FP32)x_min和x_max:数值范围的最小值和最大值s:缩放因子,用于将高精度数值映射到低精度范围q:量化后的离散整数值(如INT8范围是 -128, 127 或 0, 255)
通过这种方法,原始的浮点数被映射到一个有限的整数表示范围,既减少了存储需求,也降低了计算复杂度。量化计算的关键在于确定量化的范围、计算出合适的缩放因子。可以看下面这个图更好理解一些(图是线性映射量化)。
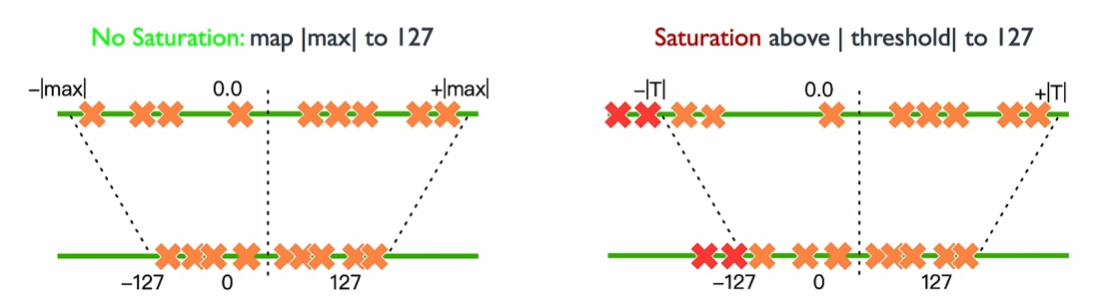 映射到INT8,左边是无饱和方式,右边是饱和方式
映射到INT8,左边是无饱和方式,右边是饱和方式
线性量化又可以分成对称量化和非对称量化。这里我没有谈到非线性量化,大家感兴趣可以自己去看看论文。
 左边是对称量化,右边是非对称量化
左边是对称量化,右边是非对称量化
补充一个点,反量化是个啥?
- 量化 :将浮点数值通过缩放因子和偏移量(
x_min)映射到整数范围。 - 反量化:在推理时,将量化整数还原为近似的浮点数,以恢复部分精度。
最后,给一个实际llamafactory文档中有关量化技术的说明,用来拓展阅读:
再附上两篇论文来介绍时下最流行的量化方法GPTQ和AWQ:
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers![]() https://arxiv.org/abs/2210.17323
https://arxiv.org/abs/2210.17323
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration![]() https://arxiv.org/abs/2306.00978
https://arxiv.org/abs/2306.00978