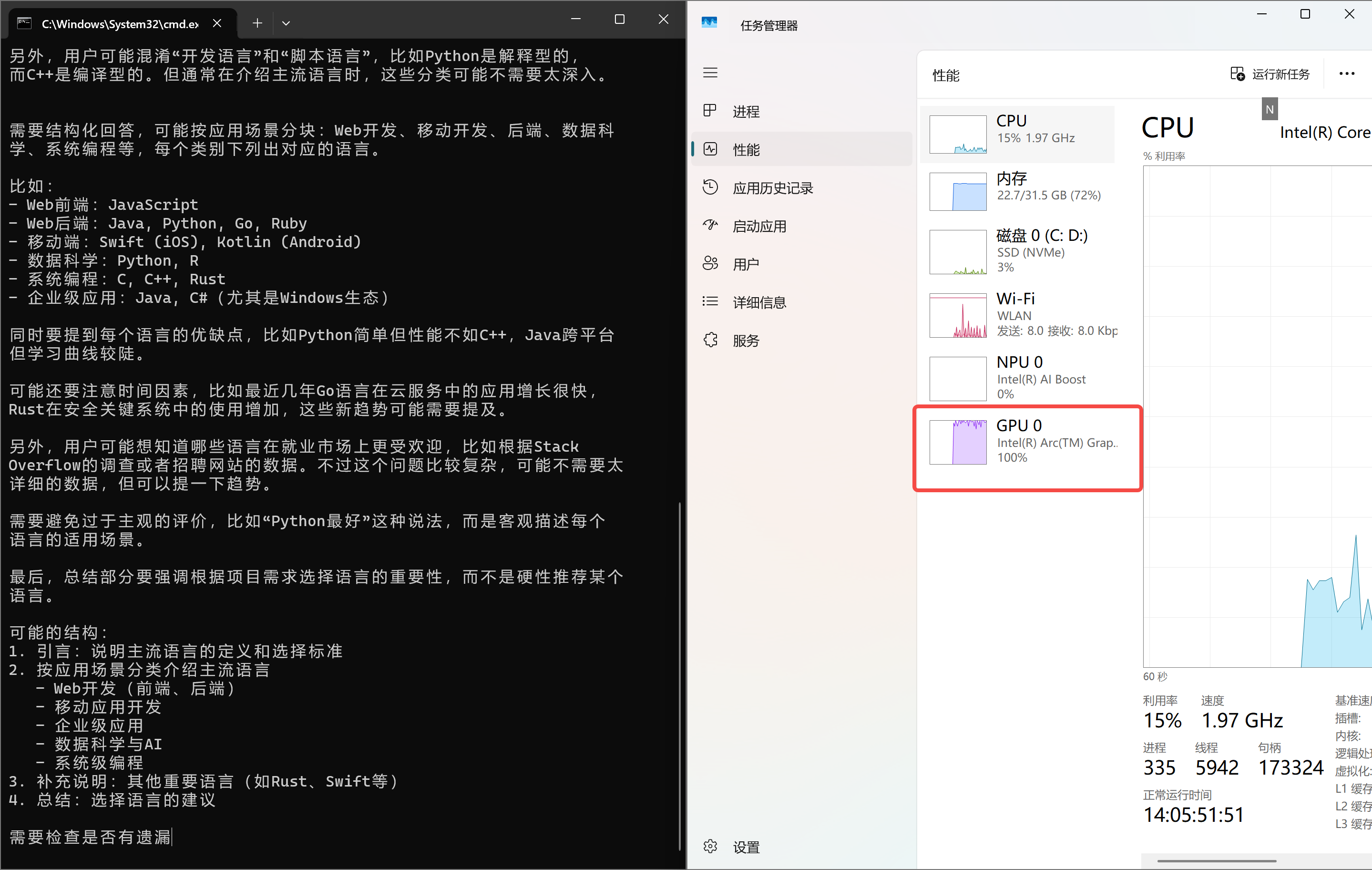
很多小伙伴是不是也想尝试一下用自己的笔记本私有化部署一个大模型,百度上搜了一些教程,发现ollama是最省事的,然后一顿操作,确实可以了,但是很慢,而且发现如下图所示,为什么这个NPU和GPU都没有用,其实是版本装错了, Ollama 默认配置没有启用你的 Intel Arc GPU 和 NPU,加上模型 / 系统适配问题导致资源没利用起来,今天教大家怎么充分利用GPU。
文章目录
- [1.下载Ollama 英特尔优化版](#1.下载Ollama 英特尔优化版)
- [2. 运行ollama](#2. 运行ollama)
- [3. 下载大模型](#3. 下载大模型)
- [4. 测试效果](#4. 测试效果)
1.下载Ollama 英特尔优化版
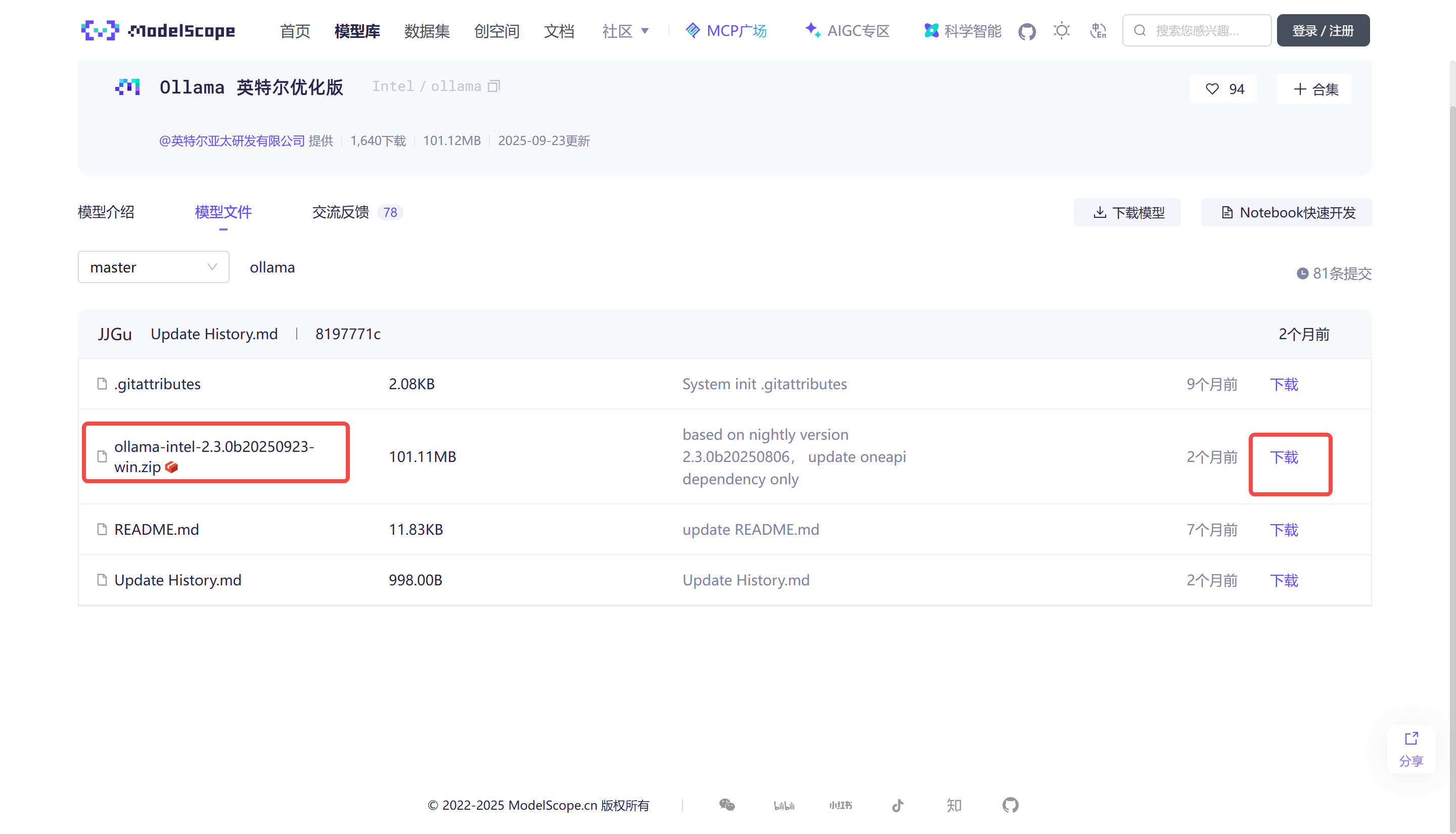
下载 Ollama 英特尔 Windows 优化版。
然后,将 zip 文件解压到一个文件夹中。
2. 运行ollama
打开刚才解压后的文件夹,在文件夹上面的路径中输入cmd,然后敲回车,就会出现一个cmd命令行目录。
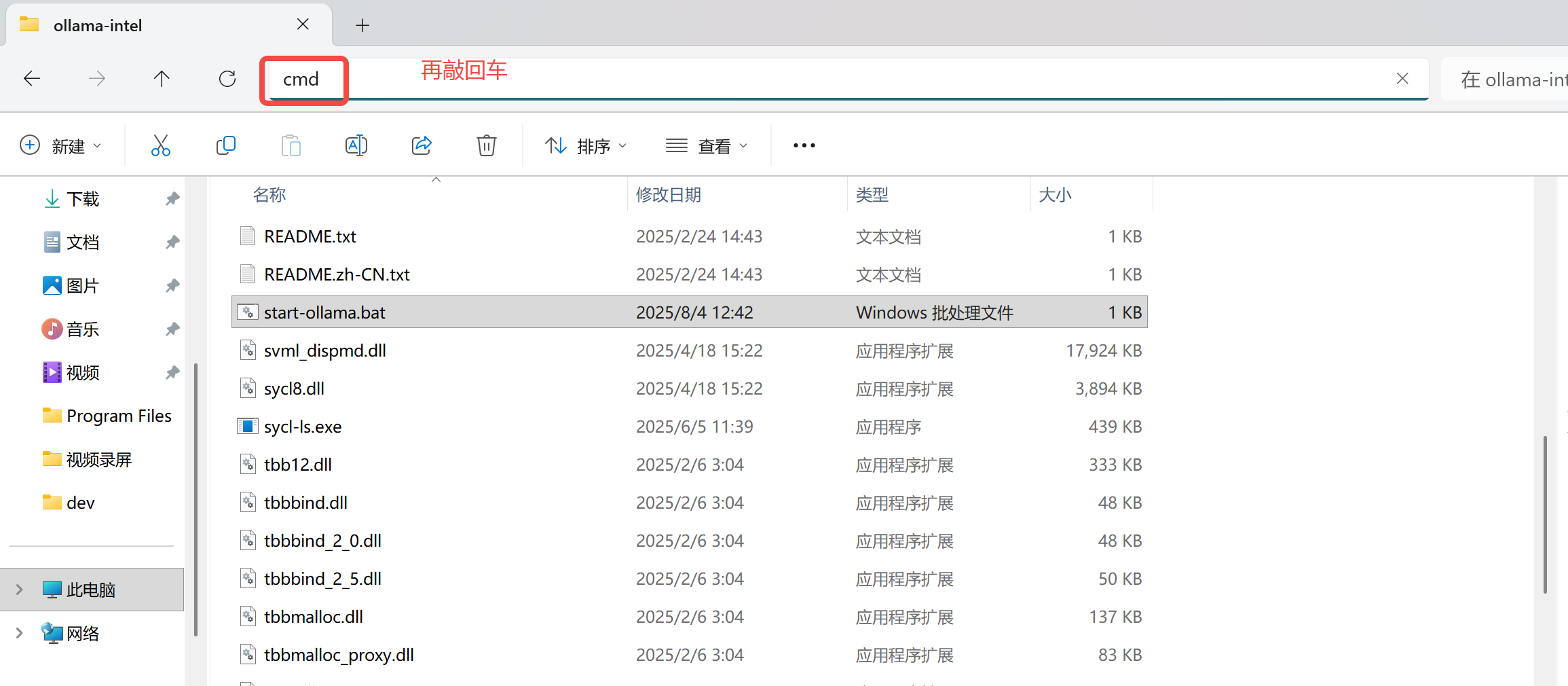
在命令提示符中运行 start-ollama.bat 即可启动 Ollama Serve。随后会弹出一个窗口,如下所示
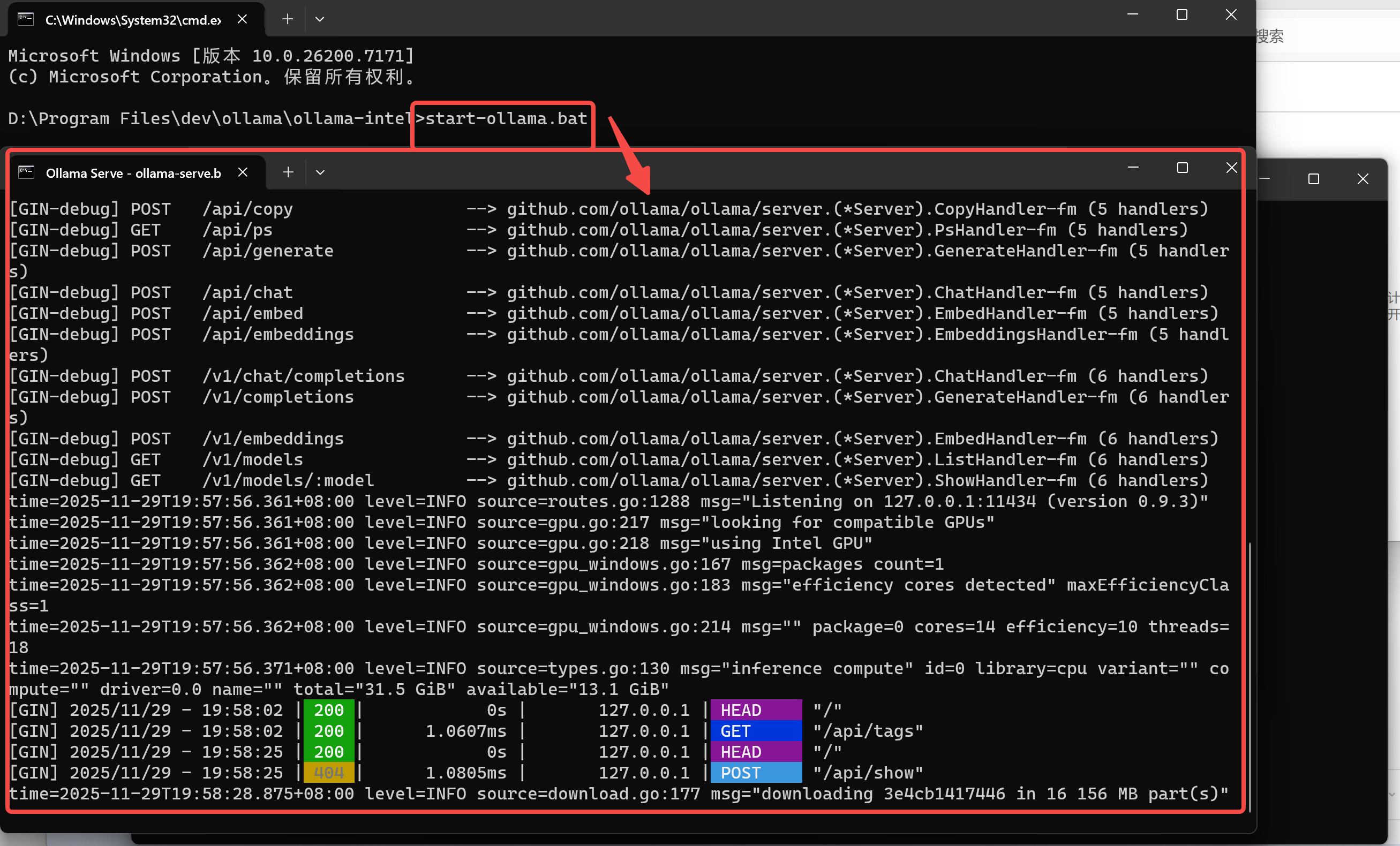
3. 下载大模型
在ollama官网中找到要下载的网站,最大显存可以对标自己笔记本内存*0.8。
模型网站:https://ollama.com/search
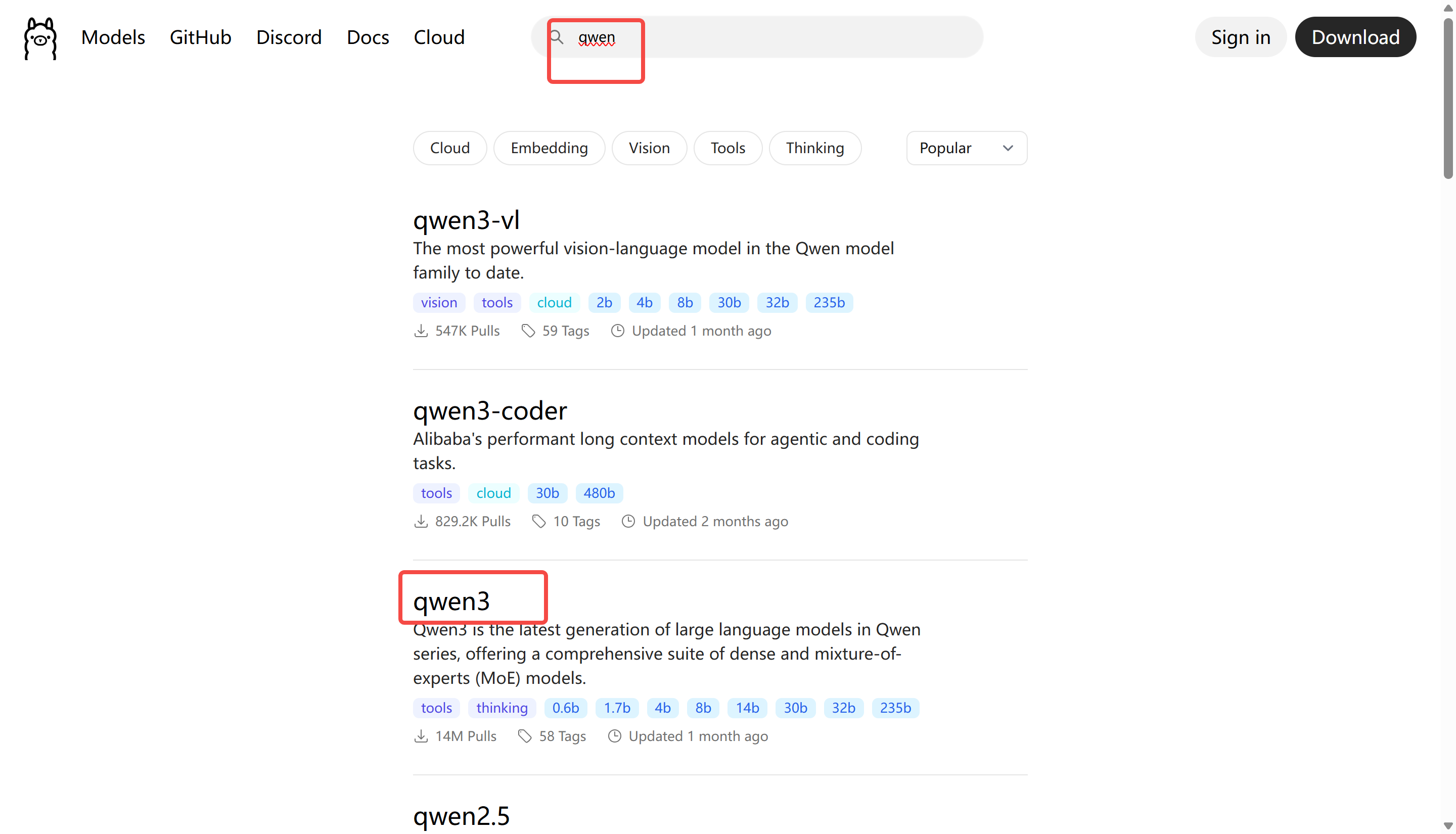
目前来看推荐qwen3,点开之后选择对应的版本,这里可以先下载一个4b的看看效果,如下图所示

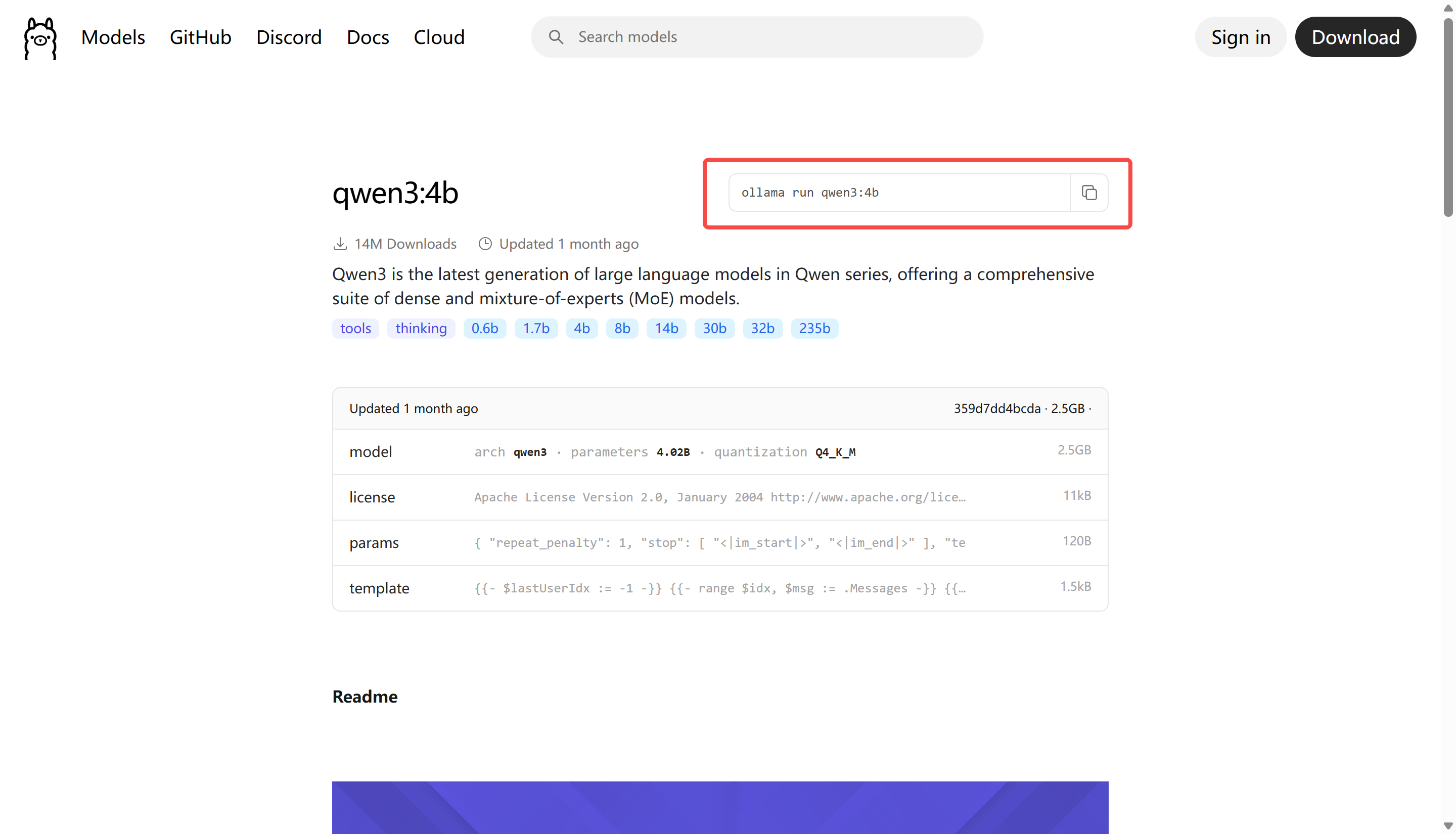
接下来通过在相同的命令提示符(非弹出的窗口)中运行 ollama run qwen3:4b(可以将当前模型替换为你需要的模型),即可在 Intel GPUs 上使用 Ollama 运行 LLMs:
4. 测试效果
安装完大模型之后,可以随便问一个问题,这时候可以看到,GPU已经100%了,说明已经不是单纯靠cpu了,一定充分利用intel自带的GPU了。