文章目录
- [1 计算图](#1 计算图)
- [2 叶子结点](#2 叶子结点)
- [2 自动求导](#2 自动求导)
-
- [2.1 示例](#2.1 示例)
- [2.2 权重求导](#2.2 权重求导)
- [4 梯度函数](#4 梯度函数)
本文环境:
- Pycharm 2025.1
- Python 3.12.9
- Pytorch 2.6.0+cu124
1 计算图
计算图是用来描述运算的有向无环图,由节点(Node)和边(Edge)组成。
- 结点表示数据(如向量,矩阵,张量)。
- 边表示运算(如加法、乘法、激活函数)。
表达式 y = ( x + w ) ∗ ( w + 1 ) y = (x + w) * (w + 1) y=(x+w)∗(w+1) 可拆解为:
- a = x + w a=x +w a=x+w
- b = w + 1 b=w+1 b=w+1
- y = a ∗ b y=a *b y=a∗b
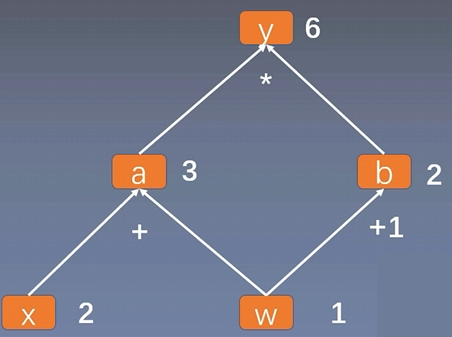
在动态图中,每一步操作即时生成计算节点,可灵活插入调试代码。
| 特性 | 动态图(PyTorch) | 静态图(TensorFlow 1.x) |
|---|---|---|
| 搭建方式 | 运算与建图同时进行(即时执行) | 先定义完整计算图,再执行(延迟执行) |
| 灵活性 | 高,可随时修改计算流程 | 低,计算图固定后不可更改 |
| 调试难度 | 易调试(逐行执行) | 难调试(需先构建完整图) |
| 性能优化 | 运行时优化较少 | 可预先优化计算路径(如算子融合) |
2 叶子结点
- 叶子结点:用户创建的结点称为叶子结点(如 x 与 w),是计算图的根基。
- is_leaf:指示张量是否为叶子结点。
代码示例
python
import torch
w = torch.tensor(1., requires_grad=True)
x = torch.tensor(2., requires_grad=True)
a = w + x
b = w + 1
y = a * b
w.is_leaf, x.is_leaf, a.is_leaf, b.is_leaf, y.is_leaf
2 自动求导
自动梯度计算:通过构建计算图(Computational Graph)自动计算张量的梯度,无需手动推导。
tensor.backward()

gradient:多梯度权重。retain_graph:保留计算图(默认释放,用于多次反向传播)。create_graph:创建导数计算图(用于高阶求导)。inputs:梯度将被累积到 .grad 中的输入,所有其他张量将被忽略。如果没有提供,则梯度将被累积到用于计算:attr:tensors 的所有叶子张量
2.1 示例
例如,当 x = 2 , w = 1 x=2,w=1 x=2,w=1 时
y = x w 2 + ( x + 1 ) w + x y=xw^2+(x+1)w+x y=xw2+(x+1)w+x
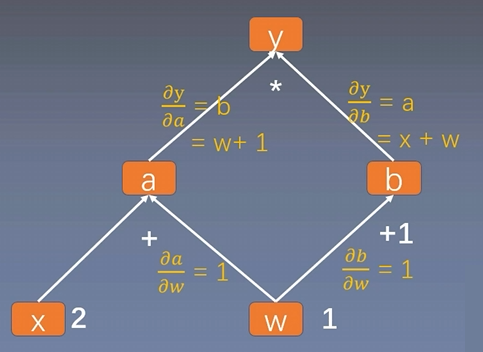 \\begin{aligned}\\frac{\\partial y}{\\partial w}\&=\\frac{\\partial y}{\\partial a}\\frac{\\partial a}{\\partial w}+\\frac{\\partial y}{\\partial b}\\frac{\\partial b}{\\partial w}\\\\\&=b\*1+a\*1\\\\\&=(w+1)+(x+w)\\\\\&=2\*w+1\\\\\&=2\*1+2+1\\\\\&=5\\end{aligned}
\\begin{aligned}\\frac{\\partial y}{\\partial w}\&=\\frac{\\partial y}{\\partial a}\\frac{\\partial a}{\\partial w}+\\frac{\\partial y}{\\partial b}\\frac{\\partial b}{\\partial w}\\\\\&=b\*1+a\*1\\\\\&=(w+1)+(x+w)\\\\\&=2\*w+1\\\\\&=2\*1+2+1\\\\\&=5\\end{aligned}
代码示例
python
import torch
w = torch.tensor(1., requires_grad=True)
x = torch.tensor(2., requires_grad=True)
a = w + x
b = w + 1
y = a * b
y.backward()
w.grad, x.grad, a.grad, b.grad, y.grad
注意
- 反向传播后,非叶子节点(如
A,B,Y)的梯度默认被释放以节省内存。 - 使用
retain_grad()保留非叶子节点梯度。
代码示例
python
import torch
w = torch.tensor(1., requires_grad=True)
x = torch.tensor(2., requires_grad=True)
a = w + x
a.retain_grad() # 保留 a 的梯度
b = w + 1
y = a * b
y.backward()
w.grad, x.grad, a.grad, b.grad, y.grad
2.2 权重求导
代码示例
python
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = w + x
b = w + 1
y0 = a * b # (x + w) * (x + 1) dy0/dw = 5
y1 = a + b # (x + w) + (x + 1) dy1/dw = 2
loss = torch.cat([y0, y1], dim=0)
grad_tensors = torch.tensor([1., 1.])
loss.backward(gradient=grad_tensors) # [1., 1.] * [5., 2.]
w.grad, x.grad
将权重改为 [1., 2.]。
python
grad_tensors = torch.tensor([1., 2.])
loss.backward(gradient=grad_tensors) # [1., 2.] * [5., 2.]
w.grad, x.grad
torch.autograd.grad()

功能:求取梯度。
outputs:用于求导的张量,如 loss。inputs:需要梯度的张量。grad_outputs:多梯度权重。retain_graph:保存计算图。create_graph:创建导数计算图,用于高阶求导。only_inputs:当前已废弃(deprecated),会被直接忽略。allow_unused:控制是否允许输入中存在未被使用的变量。- 如果设为
False(默认值取决于materialize_grads),当输入的某些变量在前向计算中未被使用时,会直接报错(因为这些变量的梯度始终为零)。 - 如果设为
True,则跳过这些未使用的变量,不会报错,其梯度返回None。
- 如果设为
is_grads_batched:是否将grad_outputs的第一维度视为批处理维度。如果设为True,会使用 PyTorch 的vmap原型功能,将grad_outputs中的每个向量视为一个批处理样本,一次性计算整个批量的向量-雅可比积(而非手动循环计算)。materialize_grads:控制是否将未使用输入的梯度显式置零(而非返回None)。- 如果设为
True,未被使用的输入的梯度会返回零张量;若设为False,则返回None。 - 如果
materialize_grads=True且allow_unused=False,会直接报错(因为逻辑冲突)。
- 如果设为
代码示例
python
x = torch.tensor([3.], requires_grad=True) # x = 3
y = x * x # y = x^2
grad_1 = torch.autograd.grad(y, x, create_graph=True) # 1 阶导:y = 2x
grad_2 = torch.autograd.grad(grad_1, x) # 2 阶导:y = 2
grad_1, grad_2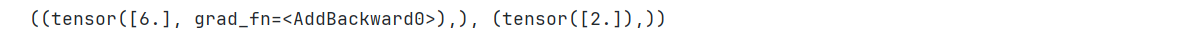
autograd 小贴士
-
梯度不自动清零。
pythonw = torch.tensor([1.], requires_grad=True) x = torch.tensor([2.], requires_grad=True) for i in range(3): a = w + x b = w + 1 y = a * b y.backward() print(w.grad, x.grad) # w.grad.zero_() # 梯度不自动清零,则会累加 # x.grad.zero_()
-
依赖于
requires._grad = True叶子结点的结点,requires._grad默认为True。pythonw = torch.tensor([1.], requires_grad=True) x = torch.tensor([2.], requires_grad=True) a = w + x b = w + 1 y = a * b a.requires_grad, b.requires_grad, y.requires_grad
-
叶子结点不可执行
in-place操作原地修改数据,否则自动求导结果会出现错误。pythona = torch.ones((1, )) print(id(a), a) a = a + 1 print(id(a), a) a += 1 # in-place 操作原地修改数据 print(id(a), a)
4 梯度函数
grad_fn:记录创建张量时的运算方法,用于反向传播时的求导规则。
y.grad_fn=<MulBackward0>a.grad_fn=<AddBackward0>b.grad_fn=<AddBackward0>
代码示例
python
w.grad_fn, x.grad_fn, a.grad_fn, b.grad_fn, y.grad_fn