
PPO(2017,OpenAI)核心改进点
Proximal Policy Optimization (PPO):一种基于信赖域优化的强化学习算法,旨在克服传统策略梯度方法在更新时不稳定的问题,采用简单易实现的目标函数来保证学习过程的稳定性
- 解决问题:在强化学习中,直接优化策略会导致不稳定的训练,模型可能因为过大的参数更新而崩溃
- PPO 系列有很多算法:Proximal Policy Optimization (PPO), TRPO
- model-free,off-policy,actor-critic, stochastic 策略
| 核心改进点 | 说明 |
|---|---|
| 剪切目标函数 | 使用剪切函数 clip 限制策略更新的幅度,避免策略大幅更新导致性能崩溃 |
| off-policy | importance sampling 每个采样数据可用于多轮更新,提升样本利用率,提高学习效率 |
博文目录
-
- PPO(2017,OpenAI)核心改进点
- [PPO 网络更新](#PPO 网络更新)
- [策略网络更新详细理论推导,从 policy gradient 原始式子开始推](#策略网络更新详细理论推导,从 policy gradient 原始式子开始推)
- [PPO / PPO2 / TRPO 优化器总结](#PPO / PPO2 / TRPO 优化器总结)
- [基于 stable_baselines3 的快速代码示例](#基于 stable_baselines3 的快速代码示例)
PPO 网络更新
策略网络
PPO 使用旧策略和新策略的比值来定义目标函数,在保持改进的同时防止策略变化过大:
Importance Sampling
设有目标分布 p ( x ) p(x) p(x),想要计算期望
E p f ( x ) = ∫ f ( x ) p ( x ) d x ≈ 1 N ∑ i = 1 N f ( x i ) \mathbb{E}pf(x) = \int f(x)p(x)dx \approx \frac{1}{N} \sum^N{i=1}f(x_i) Epf(x)=∫f(x)p(x)dx≈N1i=1∑Nf(xi)由于直接从 p ( x ) p(x) p(x) 采样困难,引入一个容易采样的分布 q ( x ) q(x) q(x),那么可以写成: E p f ( x ) = ∫ f ( x ) p ( x ) q ( x ) q ( x ) d x \mathbb{E}_pf(x) = \int f(x) \frac{p(x)}{q(x)} q(x) dx Epf(x)=∫f(x)q(x)p(x)q(x)dx于是,有近似估计: E p f ( x ) ≈ 1 N ∑ i = 1 N f ( x i ) p ( x i ) q ( x i ) \mathbb{E}pf(x) \approx \frac{1}{N} \sum{i=1}^N f(x_i) \frac{p(x_i)}{q(x_i)} Epf(x)≈N1i=1∑Nf(xi)q(xi)p(xi)
其中 x i ∼ q ( x ) x_i \sim q(x) xi∼q(x) 独立采样而得, 权重项 w ( x ) = p ( x ) q ( x ) w(x) = \frac{p(x)}{q(x)} w(x)=q(x)p(x) 被称为重要性权重(Importance Weight)
- 注意:如果 q ( x ) q(x) q(x) 和 p ( x ) p(x) p(x) 不够接近,重要性权重 w ( x ) w(x) w(x) 波动很大,估计的方差会非常大,导致估计不稳定,所以 PPO 里面引入了 clip
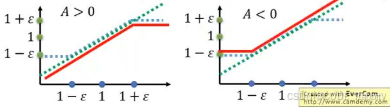
L C L I P ( θ ) = E t min ( r t ( θ ) A t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A t ) , where r t = π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) L^{CLIP}(\theta) = {\mathbb{E}}t \left \\min \\left( r_t(\\theta) {A}_t, \\text{clip}(r_t(\\theta), 1 - \\epsilon, 1 + \\epsilon) {A}_t \\right) \\right, \text{where } r_t = \frac{\pi\theta(a_t|s_t)}{\pi_{\theta_\text{old}}(a_t|s_t)} LCLIP(θ)=Etmin(rt(θ)At,clip(rt(θ),1−ϵ,1+ϵ)At),where rt=πθold(at∣st)πθ(at∣st)
- Advantage 优势函数 A t θ ′ {A}_t^{\theta '} Atθ′:如 Q ( s t , a t ) − V ( s t ) Q(s_t, a_t) - V(s_t) Q(st,at)−V(st)
- 剪切系数 ϵ \epsilon ϵ:如 0.2
价值网络
L V F ( θ μ ) = E t ( V θ μ ( s t ) − R t ) 2 L^{VF}(\theta^\mu) = \mathbb{E}_t \left (V_{\\theta\^\\mu}(s_t) - R_t)\^2 \\right LVF(θμ)=Et(Vθμ(st)−Rt)2
- 真实或估算的回报 R t R_t Rt:如 ∑ k = 0 n = γ k r t + k \sum^n_{k=0} = \gamma^k r_{t+k} ∑k=0n=γkrt+k
总损失函数
PPO 的总损失是策略损失、值函数损失和熵正则项 (鼓励探索) 的加权和:
L ( θ ) = L C L I P ( θ ) − c 1 L V F ( θ μ ) + c 2 H ( π ( s t ) ) L(\theta) = L^{CLIP}(\theta) - c_1 L^{VF}(\theta^\mu) + c_2 H(\pi(s_t)) L(θ)=LCLIP(θ)−c1LVF(θμ)+c2H(π(st))
- c 1 , c 2 c_1, c_2 c1,c2:权重系数,常用 c 1 = 0.5 c_1=0.5 c1=0.5, c 2 = 0.01 c_2=0.01 c2=0.01
策略网络更新详细理论推导,从 policy gradient 原始式子开始推
∇ θ R ˉ θ = E ( s t , a t ) ∼ π θ A θ ( s t , a t ) ∇ log π θ ( a t ∣ s t ) \nabla_\theta \bar{R}\theta = \mathbb{E}{(s_t,a_t) \sim \pi_\theta} \left A\^\\theta(s_t, a_t) \\nabla \\log \\pi_\\theta(a_t \| s_t) \\right ∇θRˉθ=E(st,at)∼πθAθ(st,at)∇logπθ(at∣st)
- Use π θ \pi_\theta πθ to collect data. When θ \theta θ is updated, we have to sample training data again.
- Goal: Using the sample from π θ ′ \pi_{\theta'} πθ′ to train θ \theta θ. θ ′ \theta' θ′ is fixed, so we can re-use the sample data.
∇ R ˉ θ = E τ ∼ π θ ′ ( τ ) p θ ( s t , a t ) p θ ′ ( s t , a t ) A θ ′ ( s t , a t ) ∇ log π θ ( a t ∣ s t ) = E τ ∼ π θ ′ ( τ ) π θ ( a t ∣ s t ) p θ ( s t ) π θ ′ ( a t ∣ s t ) p θ ′ ( s t ) A θ ′ ( s t , a t ) ∇ log π θ ( a t ∣ s t ) ≈ E τ ∼ π θ ′ ( τ ) π θ ( a t ∣ s t ) π θ ′ ( a t ∣ s t ) A θ ′ ( s t , a t ) ∇ log π θ ( a t ∣ s t ) \nabla \bar{R}\theta = \mathbb{E}{\tau \sim \pi_{\theta'}(\tau)} \left \\frac{p_\\theta(s_t, a_t)}{p_{\\theta'}(s_t, a_t)} A\^{\\theta '}(s_t, a_t) \\nabla \\log \\pi_\\theta(a_t \| s_t) \\right = \mathbb{E}{\tau \sim \pi{\theta'}(\tau)} \left \\frac{\\pi_\\theta(a_t \| s_t)p_\\theta(s_t)}{\\pi_{\\theta'}(a_t \| s_t)p_\\theta'(s_t)} A\^{\\theta '}(s_t, a_t) \\nabla \\log \\pi_\\theta(a_t \| s_t) \\right \\ \approx \mathbb{E}{\tau \sim \pi{\theta'}(\tau)} \left \\frac{\\textcolor{red}{\\pi_\\theta(a_t \| s_t)}}{\\pi_{\\theta'}(a_t \| s_t)} A\^{\\theta '}(s_t, a_t) \\textcolor{red}{\\nabla \\log \\pi_\\theta(a_t \| s_t)} \\right \text{} ∇Rˉθ=Eτ∼πθ′(τ)pθ′(st,at)pθ(st,at)Aθ′(st,at)∇logπθ(at∣st)=Eτ∼πθ′(τ)πθ′(at∣st)pθ′(st)πθ(at∣st)pθ(st)Aθ′(st,at)∇logπθ(at∣st)≈Eτ∼πθ′(τ)πθ′(at∣st)πθ(at∣st)Aθ′(st,at)∇logπθ(at∣st)
上一步的近似,是因为看到各种 state 的可能和采取什么 action,采取什么策略关系不大,或者 哈哈哈哈 这项没法算,直接忽略~继续!根据 ∇ f ( x ) = f ( x ) ∇ log ( x ) \nabla f(x) = f(x) \nabla \log(x) ∇f(x)=f(x)∇log(x),我们让 f ( x ) ← π θ ( a t ∣ s t ) f(x) \leftarrow \pi_\theta(a_t | s_t) f(x)←πθ(at∣st),那么
π θ ( a t ∣ s t ) ∇ log ( π θ ( a t ∣ s t ) ) → ∇ π θ ( a t ∣ s t ) \textcolor{red}{\pi_\theta(a_t | s_t)\nabla \log( \pi_\theta(a_t | s_t))}\to \textcolor{blue}{ \nabla \pi_\theta(a_t | s_t)} πθ(at∣st)∇log(πθ(at∣st))→∇πθ(at∣st)
那么, ∇ R ˉ θ \nabla \bar{R}\theta ∇Rˉθ 可以进一步表示为 E τ ∼ π θ ′ ( τ ) ∇ π θ ( a t ∣ s t ) π θ ′ ( a t ∣ s t ) A θ ′ ( s t , a t ) \mathbb{E}{\tau \sim \pi_{\theta'}(\tau)} \left \\frac{\\textcolor{blue}{\\nabla\\pi_\\theta(a_t \| s_t)}}{\\pi_{\\theta'}(a_t \| s_t)} A\^{\\theta '}(s_t, a_t) \\right Eτ∼πθ′(τ)πθ′(at∣st)∇πθ(at∣st)Aθ′(st,at)
PPO / PPO2 / TRPO 优化器总结
| 方法 | 优化目标公式 | 推荐程序实现顺序 | 主要说明 |
|---|---|---|---|
| TRPO (Trust Region Policy Optimization) | E r ( θ ) A π θ old ( s , a ) \mathbb{E}\leftr(\\theta)A\^{\\pi_{\\theta_{\\text{old}}}}(s,a)\\right Er(θ)Aπθold(s,a) 受限于: E D KL ( π θ old ( ⋅ ∣ s ) ∥ π θ ( ⋅ ∣ s ) ) ≤ δ \mathbb{E}\leftD_{\\text{KL}}(\\pi_{\\theta_{\\text{old}}}(\\cdot|s)\\parallel\\pi_{\\theta}(\\cdot|s))\\right\leq\delta EDKL(πθold(⋅∣s)∥πθ(⋅∣s))≤δ | ⭐️ | - 明确KL散度约束,保证更新安全 - 算法复杂,求解开销大 - 理论保证较好,实践中偏慢 |
| PPO (Proximal Policy Optimization) | E r ( θ ) A − β K L ( θ , θ ′ ) \mathbb{E}r(\\theta)A -\beta KL(\theta, \theta') Er(θ)A−βKL(θ,θ′) | ⭐️ ⭐️ | - 近似代替TRPO的约束 - 简单易实现 - 有强大的实用性能 |
| PPO2 (PPO的稳定改进版) | E min ( r ( θ ) A , clip ( r ( θ ) , 1 − ϵ , 1 + ϵ ) A ) \mathbb{E}\left\\min\\left(r(\\theta)A,\\text{clip}(r(\\theta),1-\\epsilon,1+\\epsilon)A\\right)\\right Emin(r(θ)A,clip(r(θ),1−ϵ,1+ϵ)A) | ⭐️ ⭐️ ⭐️ | - OpenAI Baselines 实现版本 - 细节优化稳定性更好 - GAE使优势估计更准确,训练更快 |
基于 stable_baselines3 的快速代码示例
python
import gymnasium as gym
from stable_baselines3 import PPO
# 创建环境
env = gym.make("CartPole-v1")
env.reset(seed=0)
# 初始化模型
model = PPO("MlpPolicy", env, verbose=1)
# 训练模型
model.learn(total_timesteps=100_000)
model.save("ppo_cartpole_v1")
# 测试模型
obs, _ = env.reset()
total_reward = 0
for _ in range(200):
action, _ = model.predict(obs, deterministic=True)
obs, reward, terminated, truncated, _ = env.step(action)
total_reward += reward
if terminated or truncated:
break
print("Test total reward:", total_reward)参考资料:PPO 详解