1.把spark安装包复制到你存放安装包的目录下,例如我的是/opt/software
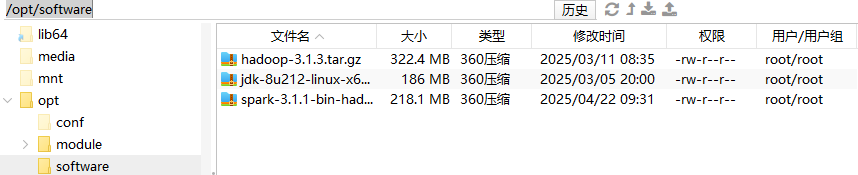
cd /opt/software,进入到你存放安装包的目录
然后tar -zxvf 你的spark安装包的完整名字 -C /opt/module,进行解压。例如我的spark完整名字是spark-3.1.1-bin-hadoop3.2.tgz,所以我要输入的命令是
tar -zxvf spark-3.1.1-bin-hadoop3.2.tgz -C /opt/module

2.配置spark的环境变量
进入到/etc/profile.d目录下
自己新建一个存放修改spark环境变量的文件,例如我的是my_env.sh,在里面添加配置的内容
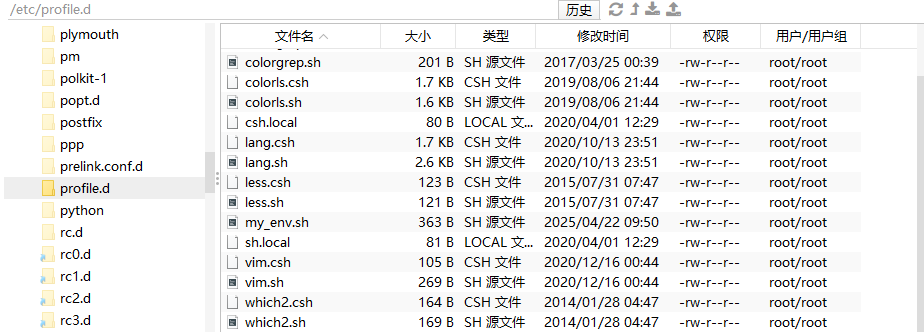
添加以下内容
# spark 环境变量
export SPARK_HOME=/opt/module/spark-yarn
export PATH=PATH:SPARK_HOME/bin:$SPARK_HOME/sbin
保存修改,回到输入命令界面,输入source /etc/profile,重新刷新环境变量,让修改的环境变量生效。
在输入 echo $PATH回车,出现spark-local/bin:/opt/module/spark-local/sbin说明我们已经配置好spark的环境变

同步给其他的设备: xsync /etc/profile.d/
3.修改hadoop的配置。/opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml。因为测试环境虚拟机内存较少,防止执行过程进行被意外杀死,添加如下配置。
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
把这个设置分发到其他节点。使用xsync /opt/module/hadoop-3.1.3/etc/hadoop/同步一下。
4.修改spark配置。 把三个文件的名字重新设置一下。
workers.tempalte 改成 workers,spark-env.sh.template 改成 spark-env.sh,
spark-defaults.conf.template 改成 spark-defaults.conf。
然后,在workers文件中添加
hadoop100
hadoop101
hadoop102
在spark-env.sh文件中,添加如下
SPARK_MASTER_HOST=hadoop100
SPARK_MASTER_PORT=7077
HADOOP_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
export SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://hadoop100:8020/directory"
在spark-defaults.conf文件中,添加如下
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop100:8020/directory
spark.yarn.historyServer.address=hadoop100:18080
spark.history.ui.port=18080
5.同步配置文件到其他设备。xsync /opt/module/spark-yarn/sbin
( 五 ) 启动集群
注意这里要同时启动hadoop和spark。
1.启动hdfs和yarn。使用我们之前配置的脚本:myhadoop start
- 启动spark和spark的历史服务器。进入/opt/module/spart-yarn/sbin,运行: ./start-all.sh 和 ./start-history-server.sh
并通过jps去检查是否有对应的进程。
( 六 ) 提交任务到集群
使用spark-submit提交任务
spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster /opt/module/spark-standalone/examples/jars/spark-examples_2.12-3.1.1.jar 10
( 七 ) 查看运行结果
- 在yarn任务面板页面中可以看到任务的信息。http://hadoop101:8088/cluster
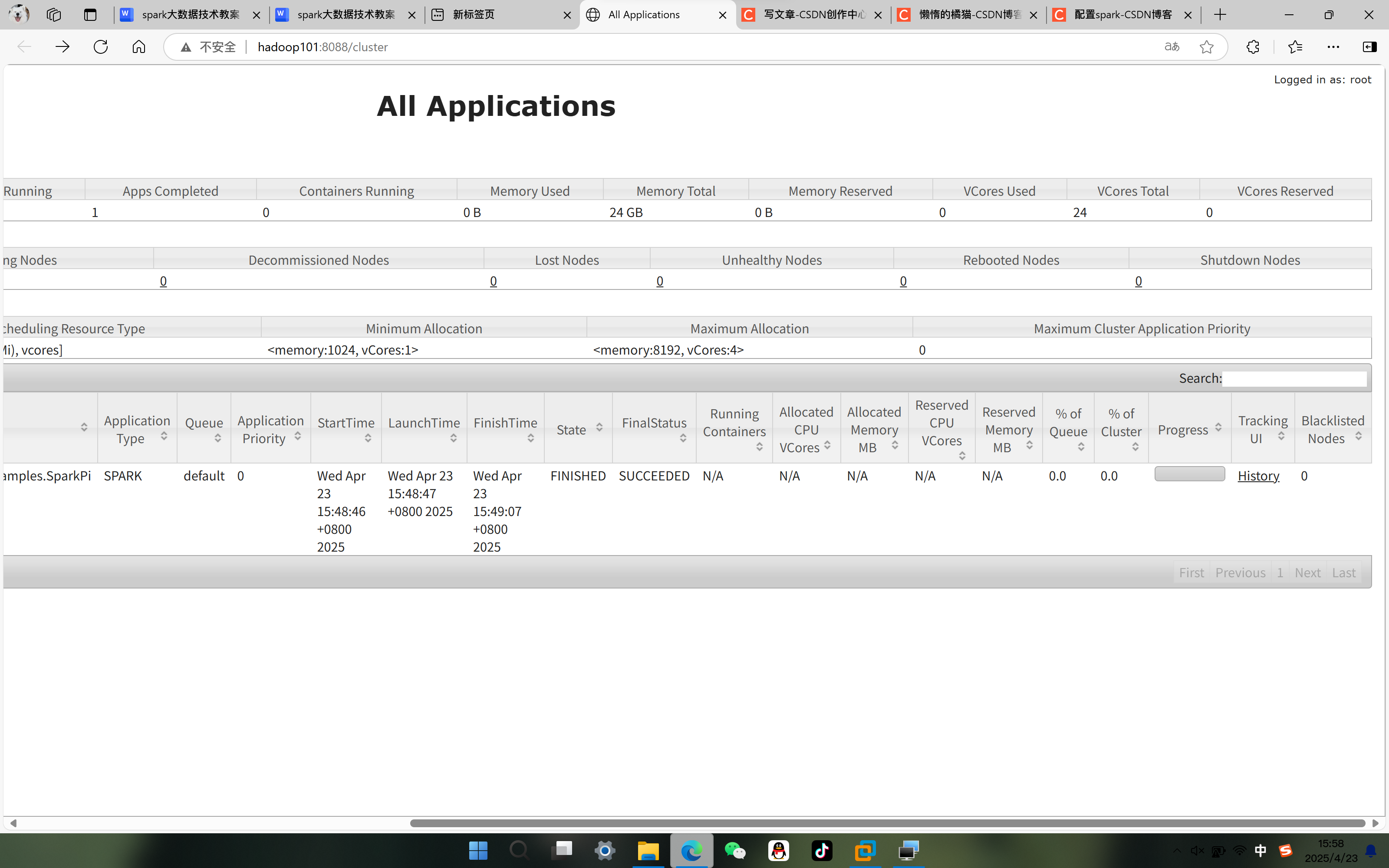
如果可以看任务信息,说明任务运行成功!