1、数据结构
下面是本文中用到的数据表结构,主要是保存聊天历史,操作日志,agent定义以及定时提醒用的。结构简单,不做过多说明。
2、代码分析方法
接下来的内容,我打算使用一种以"实现具体需求为目的"的方法来描述在上文中提到的一些工作。这种方法目的性强,便于读者快速了解需要的内容,但又不会太繁琐。本文行文还是一贯执行上篇中所说的,不会在代码浪费很多笔墨,主要在于介绍思路,相信思路清晰了,实现可以有自己更多的方式。
在本章中,我们打算实现上篇中截图提到的 从自然语言出统计分析结果 这样一个效果。
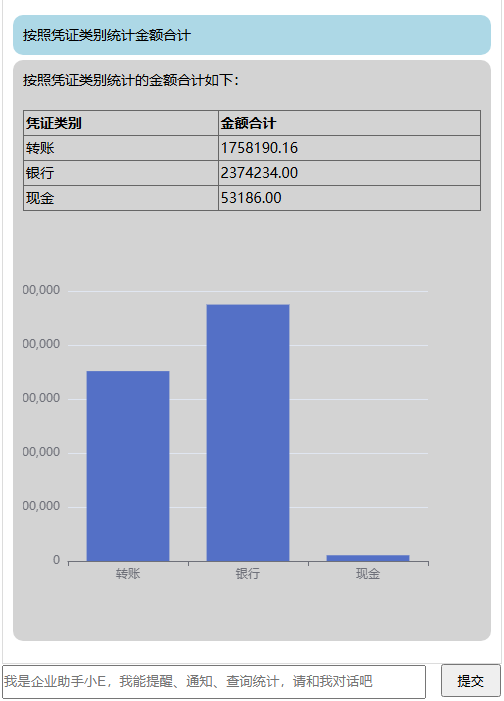
再开始之前,先大概介绍一下Agent调用大模型进行对话(信息交流)的逻辑步骤。
我们通过Agent调用大模型(本文使用的大模型是阿里千问)就是调用开放的接口,通过接口,按照一定的格式(JSON)将信息传递给大模型,大模型处理后,再以特定格式(JSON)返回。(下文都已自然语言举例)
例如:
Agent提交:你好,我叫张三
大模型回复:您好......
这样就完成了一次对话。
大模型本没有记忆(不会保存对话记录),因此下一次你再和他聊天,问他"我叫什么名字",大模型是不会知道的,为了让大模型能像两个熟悉的人对话一样有记忆功能,我们每次提交请求都要把之前的历史记录一起提交:
例如:
Agent上次提交:你好,我叫张三
大模型上次回复:您好......
Agent提交:我叫什么名字?
大模型回复:您叫张三...
在AI话语环境中,单次对话叫文本补全,像我们刚才带上之前对话内容的叫聊天。
在agent的大模型交互的信息中,除了我们在聊天界面上看到的信息外,还有一些是隐藏信息,是Agent在后台随着聊天信息一起提交给大模型的补充内容,而这些隐藏的补充内容往往对于大模型怎么回复你至关重要。
在提交的聊天信息JSON中,有至少三种类型的信息,分别是 user,system和assistant。这里user就是指人类提交的内容,比如:"你好,我叫张三" 这样的,assistant是大模型对于请求的回复内容。system类型的就是我们刚才说的隐藏的重要的提示信息。这些隐藏信息重要到已经单独发展成一门单独的研究课程,他叫提示词工程。而我们为了完成本文中的目的,使用的就是sytem类型的提示词给大模型。
再回到我们本文的目的:让大模型根据我们的自然语言进行统计分析。
先说一下我们目前具有的基础内容:我们有一个叫 凭证分录 的数据表,这个表里面存储了各种资金往来的记录,一列叫做凭证类别,包含转账、现金、银行三种。还有两列分别叫 贷方金额 和借方金额,他们的意思可以从字面理解。
表面上,我们会提交请求:按凭证类别统计金额合计。
在背后Agent把我们这个 凭证分录 的表结构一起提交给大模型,包括表名称/意义,每个字段的名称和意思,如果更详细一点,还会包含字段的数据类型。如果有多张表单,还可能包含表之间的关系描述等。其实就是相当于把整个数据词典一起提交了。
但是如果只提交这些内容,大模型依然没有办法给我们想要的统计结果,最多他能根据你提交的数据表结构生成一个用以查询数据的sql语句,因为他不知道怎么查数据。解决这个问题,我们有2中方法,一种是把数据源描述信息也一起发给大模型,让大模型自己查(可以吗?没试过),但是这种方式我觉得太危险了。另一种就是我们接受大模型的sql语句,然后自己查。使用后面这种方法,就要提到另一个名词functioncall。
funcationcall是OpenAI提出的为了解决大模型无法与外界沟通的方法,目前不是所有的大模型都原生支持functioncall,对于不支持functioncall的大模型,我们也可以是用提示词工程来完成外部函数调用的功能。
在提交统计请求时,不但把数据词典一起提交,同时还提交了一个方法/函数(tool),这个函数名(自己起的)叫Stat,他接受一个string类型的参数sqlStr。并且告诉大模型,如果你接受到数据统计方面的任务,可以调用这个函数,并且把使用根据我提交给你的数据词典而生成的解决用户统计问题的sql语句填入到这个参数中。
例如用户请求:按凭证类别统计金额合计。
大模型返回的内容就包含了一个functioncall的部分,大意如下:
调用函数名:Stat
函数参数sqlStr为:select 凭证类别, sum(贷方金额+借方金额) as 金额合计 from 凭证分录 group by 凭证类别
在上面的例子中,大模型根据自己掌握的知识,把你的"金额合计"在这次上下文环境中理解为 贷方金额+借方金额,当然你也可以通过system提示词告诉大模型"金额合计"的具体解释。
在我们拿到大模型返回的信息后,发现了funcationcall的信息,并且知道了这个参数,我们就调用我们已经写好的这个Stat函数,并传递参数sqlString,在这个函数中,我们可以实现从数据库中查询数据,并已表格和图表的形式返回给用户。
在本文的代码中,我是把这部分工作(以表格和图表展现给用户)也交给了大模型做。具体方式就是在Stat函数中,使用查询得到一个DataSet对象,把这个DataSet对象转成xml,然后在把这个xml提交给大模型,并且告诉大模型:我这里有一个xml文件,你把它转成html的表格方式展现,同时按照我的要求,把xml的数据转成图表JSON方式返回给我。
到此就完成了我们本文开头提出的任务。
回顾一下本文的内容,在我初次使用大模型的解决访问的时候,当时我对于大模型的理解写了几点总结,和各位分享:
大模型的特点:
1、聪明:可以像人类一样和他对话,他会理解你表达的内容。
2、超强记忆力(不是本身的记忆力,而是在对话中包含历史记录):你告诉他的话会被记住,并且在一个完整的聊天过程中会不断地回忆起你曾经说的话。
3、学习能力特别强,还会举一反三。
是不是很简单,不知所云。这也是我对于第一次接触到一个陌生的东西,从好奇到跟兴趣、再到开始熟悉、使用他的一个过程。