目录
[1 分桶表基础概念](#1 分桶表基础概念)
[1.1 什么是分桶表](#1.1 什么是分桶表)
[1.2 分桶与分区的区别](#1.2 分桶与分区的区别)
[2 分桶表设计与创建](#2 分桶表设计与创建)
[2.1 创建分桶表语法](#2.1 创建分桶表语法)
[2.2 分桶键选择原则](#2.2 分桶键选择原则)
[2.3 桶数确定策略](#2.3 桶数确定策略)
[3 分桶表数据加载](#3 分桶表数据加载)
[3.1 标准数据加载流程](#3.1 标准数据加载流程)
[3.2 分桶表数据验证](#3.2 分桶表数据验证)
[4 分桶Join优化原理](#4 分桶Join优化原理)
[4.1 Map端Join优化](#4.1 Map端Join优化)
[4.2 Sort-Merge Bucket Join](#4.2 Sort-Merge Bucket Join)
[5 优化实践](#5 优化实践)
[5.1 分桶与分区联合应用](#5.1 分桶与分区联合应用)
[5.2 分桶采样优化](#5.2 分桶采样优化)
[5.3 动态调整分桶策略](#5.3 动态调整分桶策略)
[6 常见问题与解决方案](#6 常见问题与解决方案)
[6.1 数据倾斜问题](#6.1 数据倾斜问题)
[6.2 分桶失效场景](#6.2 分桶失效场景)
[6.3 分桶表维护](#6.3 分桶表维护)
[8 总结](#8 总结)
引言
在大数据领域,Hive作为Hadoop生态系统中最受欢迎的数据仓库工具,其性能优化一直是数据工程师关注的核心问题。本文将深入探讨Hive中一种高效的数据组织方式------分桶表(Bucketed Table),从基础概念到高级优化技巧,特别是其在Join操作中的卓越表现,为您呈现一份完整的实践指南。
1 分桶表基础概念
1.1 什么是分桶表
分桶表(Bucketed Table)是Hive中一种特殊的数据组织方式,它根据指定列的哈希值将数据均匀分布到固定数量的"桶"(Bucket)中。每个桶对应一个文件,相同列值的数据一定会被分配到同一个桶中。
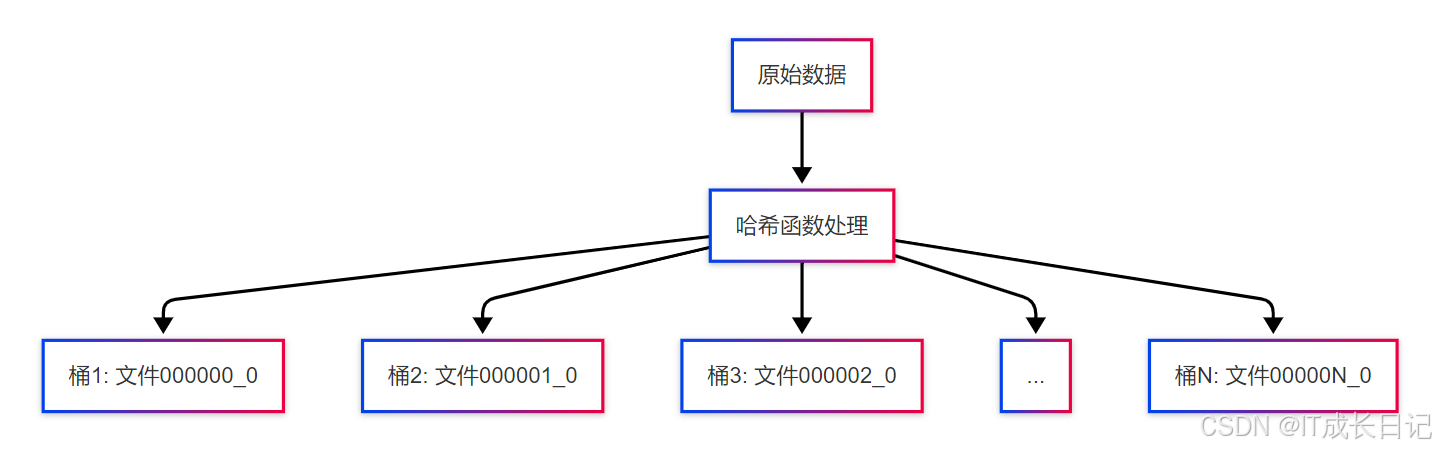
分桶核心特点:
- 数据均匀分布:通过哈希算法确保数据均匀分布
- 固定桶数量:建表时确定且不可更改
- 高效定位:已知分桶列值可直接定位到具体桶
1.2 分桶与分区的区别
|----------|-------------------|----------------------|
| 特性 | 分桶(Bucketing) | 分区(Partitioning) |
| 组织方式 | 哈希值划分 | 列值划分目录 |
| 文件数量 | 固定(建表时指定) | 随分区数增长 |
| 适用场景 | JOIN优化、数据采样 | 时间范围查询、数据归档 |
| 数据分布 | 均匀分布 | 可能倾斜 |
| 变更成本 | 高(需重写数据) | 低(可动态添加) |
2 分桶表设计与创建
2.1 创建分桶表语法
CREATE TABLE bucketed_table (
col1 data_type,
col2 data_type,
...
)
CLUSTERED BY (bucket_column)
INTO num_buckets BUCKETS
[STORED AS file_format];-
示例
CREATE TABLE user_behavior (
user_id BIGINT,
item_id BIGINT,
behavior_time TIMESTAMP
)
CLUSTERED BY (user_id)
INTO 32 BUCKETS
STORED AS ORC
TBLPROPERTIES ("orc.compress"="SNAPPY");
2.2 分桶键选择原则
- 高频JOIN列:选择常用于JOIN条件的列
- 高基数列:列的不同值数量应远大于桶数
- 低倾斜列:避免值分布严重不均的列
- 业务关键列:如用户ID、订单ID等
2.3 桶数确定策略
- 与数据量成正比:通常每桶100-300MB数据为宜
- 与集群能力匹配:建议为Reducer数量的整数倍
- 考虑未来发展:预留20%-30%增长空间
- 质数原则:使用质数可减少哈希冲突
- 计算公式
桶数 ≈ 总数据量 / 每个Reducer处理量
3 分桶表数据加载
3.1 标准数据加载流程
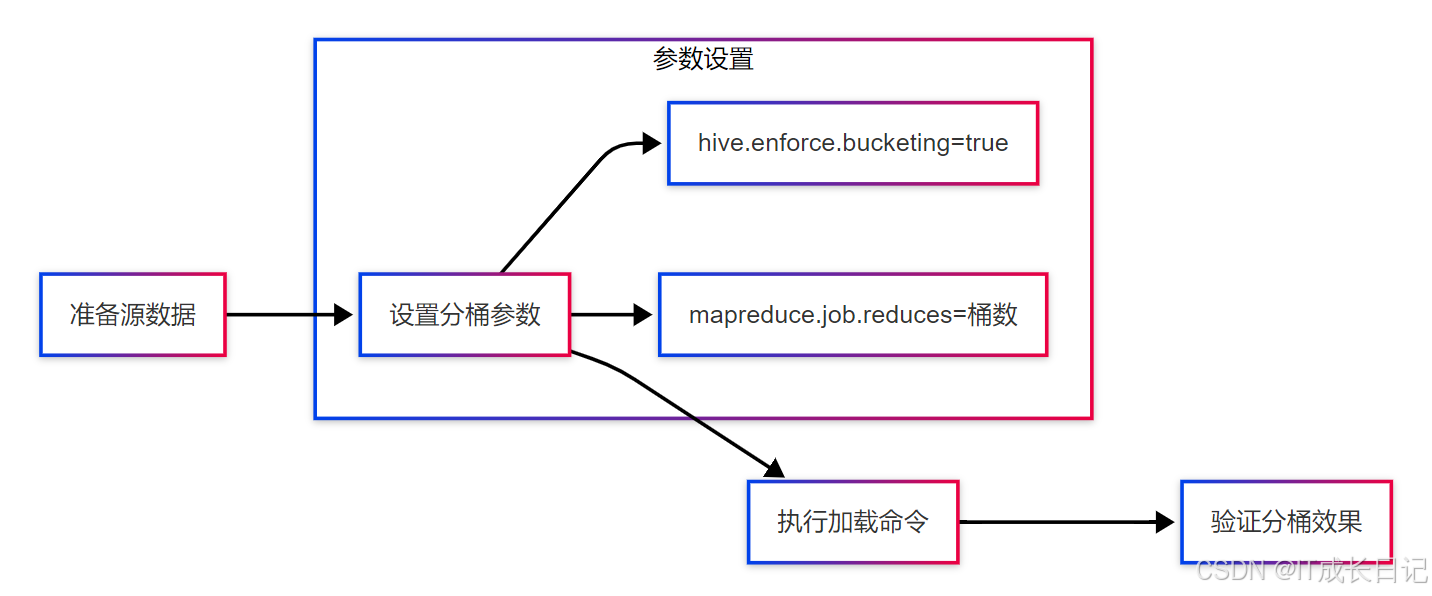
-
具体实现
-- 启用分桶配置
SET hive.enforce.bucketing=true;
SET mapreduce.job.reduces=32; -- 与桶数一致-- 从查询加载数据
INSERT INTO TABLE bucketed_table
SELECT * FROM source_table;
3.2 分桶表数据验证
-- 检查桶文件数量
hadoop fs -ls /user/hive/warehouse/db.db/bucketed_table;
-- 验证数据分布
SELECT
hash(user_id) % 32 as computed_bucket,
count(*) as row_count
FROM bucketed_table
GROUP BY hash(user_id) % 32
ORDER BY computed_bucket;4 分桶Join优化原理
4.1 Map端Join优化
- 当两个表使用相同分桶列且桶数成倍数关系时,可触发Map端Join:
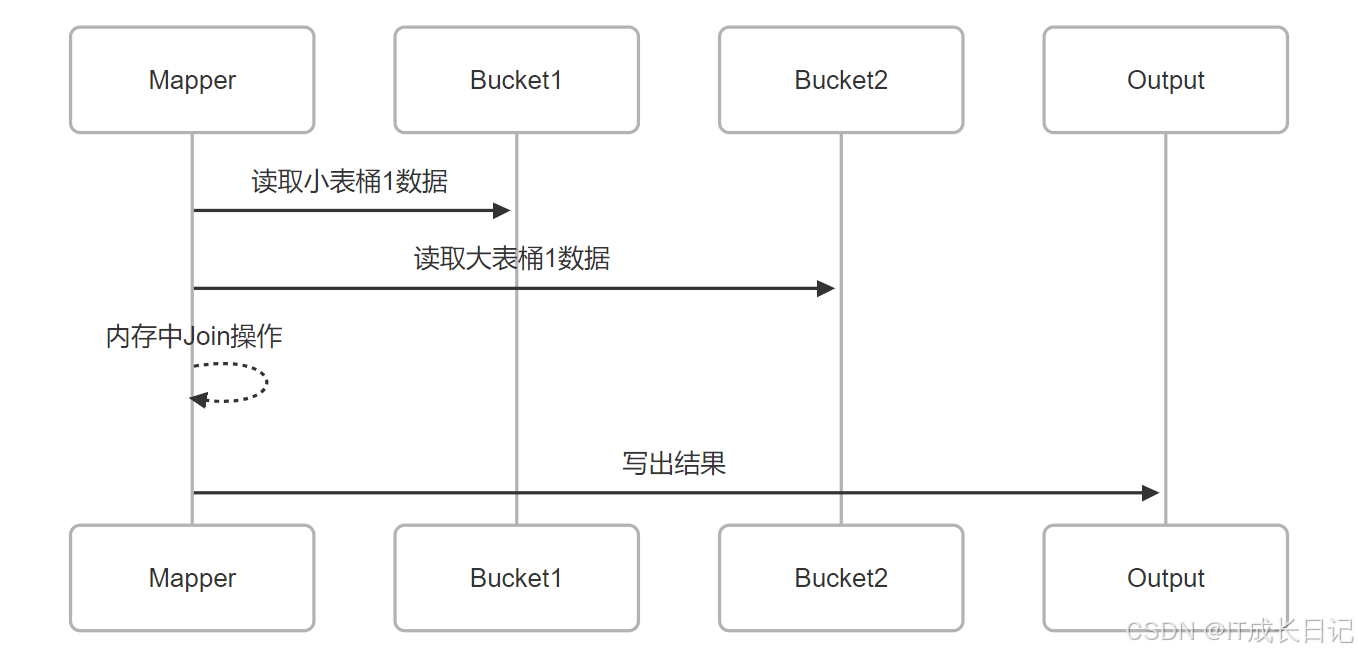
条件要求:
- 两表分桶列相同
- 小表桶数是大表的约数
- hive.optimize.bucketmapjoin=true
4.2 Sort-Merge Bucket Join
-
更高效的Join方式,避免全表扫描:
-- 设置优化参数
SET hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
SET hive.optimize.bucketmapjoin.sortedmerge=true;-- 执行Join
SELECT /+ MAPJOIN(b) / a., b.
FROM bucketed_table_a a
JOIN bucketed_table_b b
ON a.user_id = b.user_id; -
工作原理:
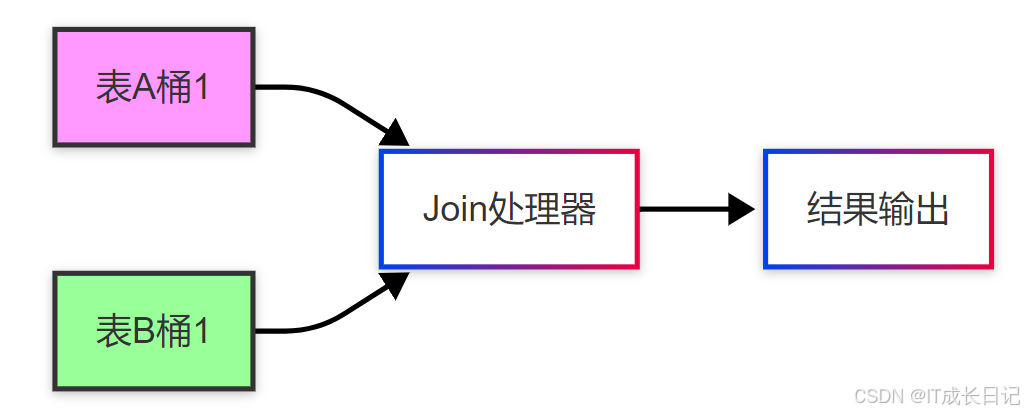
5 优化实践
5.1 分桶与分区联合应用
CREATE TABLE user_events (
event_id BIGINT,
user_id BIGINT,
event_time TIMESTAMP
)
PARTITIONED BY (dt STRING)
CLUSTERED BY (user_id) INTO 64 BUCKETS
STORED AS ORC;联合优势:
- 先按分区剪枝,减少数据量
- 再通过分桶精确数据定位
- 双重优化查询性能
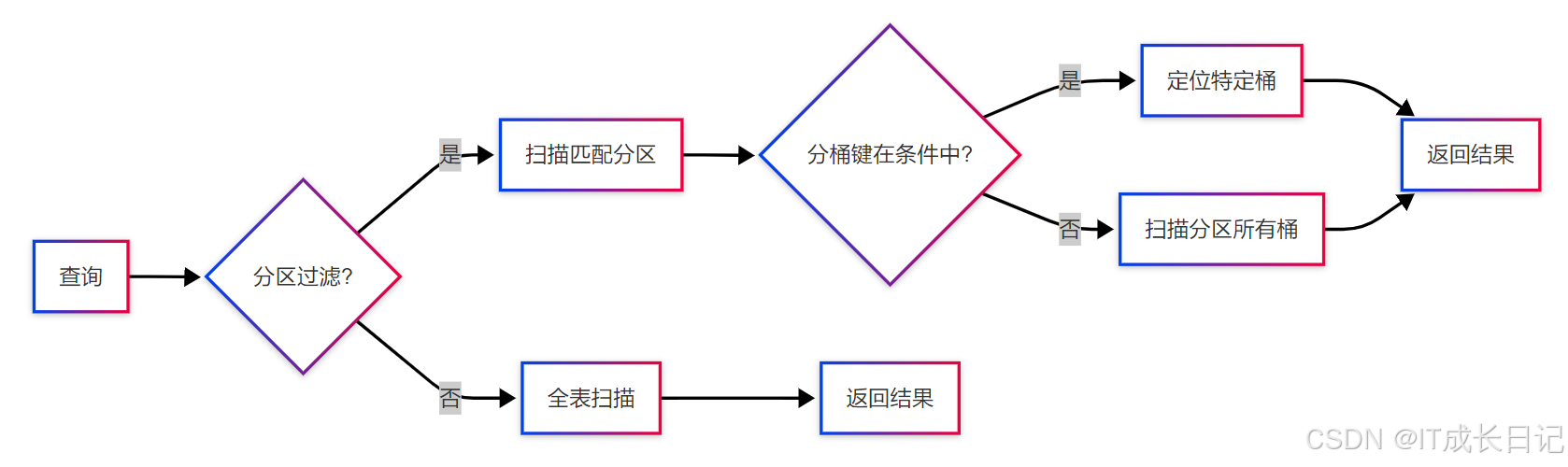
5.2 分桶采样优化
-- 基于分桶的快速采样
SELECT * FROM bucketed_table
TABLESAMPLE(BUCKET 3 OUT OF 32 ON user_id);采样优势:
- 避免全表扫描
- 结果更具代表性
- 性能提升显著
5.3 动态调整分桶策略
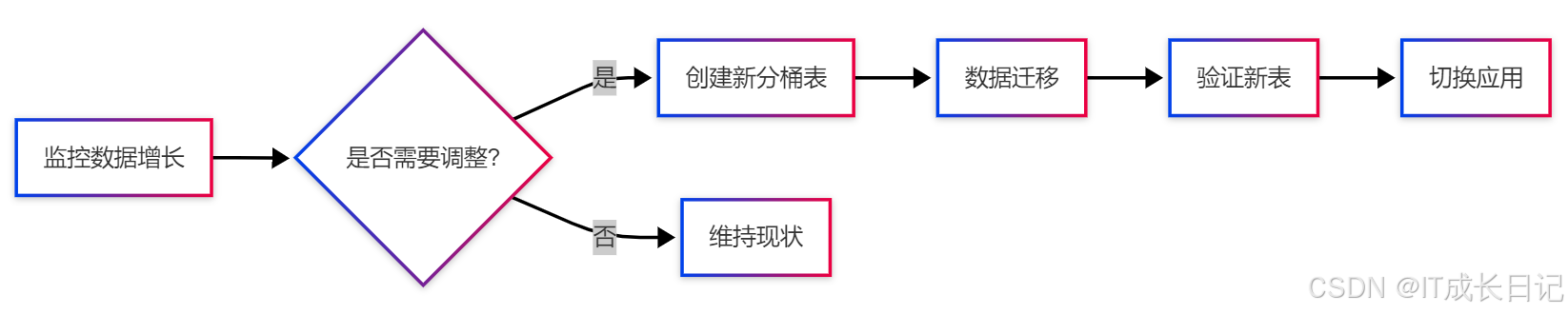
6 常见问题与解决方案
6.1 数据倾斜问题
-
诊断方法:
-- 查看各桶数据量
SELECT
hash(user_id)%32 as bucket_num,
count(*) as row_count
FROM bucketed_table
GROUP BY hash(user_id)%32
ORDER BY row_count DESC;
解决方案:
- 选择更均匀的分桶列
- 对倾斜值单独处理
- 增加桶数量
6.2 分桶失效场景
常见原因:
- 未设置hive.enforce.bucketing
- Reducer数量不等于桶数
-
使用LOAD DATA直接加载
-
修复方案:
-- 正确加载方式
SET hive.enforce.bucketing=true;
SET mapreduce.job.reduces=32; -- 等于桶数INSERT OVERWRITE TABLE bucketed_table
SELECT * FROM source_table;
6.3 分桶表维护
-- 修复元数据
ANALYZE TABLE bucketed_table COMPUTE STATISTICS;
ANALYZE TABLE bucketed_table COMPUTE STATISTICS FOR COLUMNS;
-- 小文件合并
SET hive.merge.mapfiles=true;
SET hive.merge.size.per.task=256000000;
INSERT OVERWRITE TABLE bucketed_table
SELECT * FROM bucketed_table;8 总结
设计阶段:
- 谨慎选择分桶列
- 合理设置桶数量
- 考虑与分区的联合使用
实施阶段:- 确保正确加载数据
- 验证数据分布均匀性
- 收集统计信息
运维阶段:- 监控数据倾斜
- 定期维护分桶表
- 适时调整分桶策略
Hive分桶技术是提升大数据处理效率的利器,特别是在Join操作和数据分析场景中表现突出。通过合理应用分桶表,企业可以显著降低计算资源消耗,提升查询性能。