常用序列预测模型
-
-
- (1)AR(自回归)模型
- (2)ARIMA模型
- (3)Prophet模型
- (4)LSTM模型
- (5)Transformer模型
- (6)模型评估
-
- [6.1 MAE(平均绝对误差)](#6.1 MAE(平均绝对误差))
- [6.2 MSE(均方误差)](#6.2 MSE(均方误差))
- [6.3 RMSE(均方根误差)](#6.3 RMSE(均方根误差))
-
(1)AR(自回归)模型
AR(自回归)模型,全称Autoregressive model,是统计上一种处理时间序列数据的方法。这个模型主要是利用同一变量的过去值(即滞后值)来预测该变量的未来值,并假设这些变量之间存在线性关系。
p阶自回归模型表示为AR§,数学表达式如下:
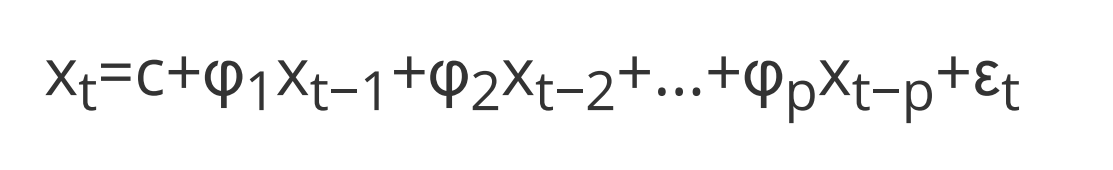
- c是常数
- φi 是自相关系数
- ε是时间t处的随机误差(或称为白噪声)
- xt−1,xt−2,...,xt−p 为滞后值
AR模型处理过程如下:
-
非平稳序列的识别
-
- 首先,通过观察时间序列图或进行统计测试(如ADF检验)来识别序列是否平稳。非平稳序列通常具有随时间变化的均值或方差。
-
差分法使序列平稳
-
- 对于非平稳序列,一个常见的平稳化方法是进行一阶差分。即,计算每个时刻的观测值与前一时刻观测值之间的差。差分后的序列通常具有更稳定的均值和方差。 假设原始非平稳序列为{Xt},则一阶差分序列为{ΔXt = Xt - Xt-1}。
-
应用AR(1)模型
-
- 在差分后的平稳序列上应用AR(1)模型。 在差分后的序列上,我们可以使用历史数据来估计模型的参数(c和φ),然后使用这些参数来预测未来的值。
-
预测与评估
-
- 使用估计的AR(1)模型对差分后的序列进行预测,然后将预测值转换回原始尺度(通过累加差分)。评估预测的准确性可以使用各种统计指标,如均方误差(MSE)或平均绝对误差(MAE)。
AR模型的优点是模型简单,可以用自身变数数列来进行预测。缺点是这种方法受到一定的限制,它要求数据必须具有自相关性,否则预测结果可能不准确。
举例:假设我们有一个非平稳的时间序列数据,例如某商品的销售量数据。这个序列可能存在某种趋势或季节性模式,使得它不是平稳的。
python
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.ar_model import AutoReg
# 创建一个简单的非平稳时间序列数据(带有线性趋势)
np.random.seed(0)
n_samples = 100
time = np.arange(n_samples)
x = 0.5 * time + np.random.normal(size=n_samples)
# 使用一阶差分使序列平稳
diff_x = np.diff(x)
# 绘制原始非平稳序列和差分后的平稳序列
plt.figure(figsize=(12, 6))
plt.subplot(2, 1, 1)
plt.plot(time, x, label='Original Non-Stationary Series')
plt.title('Original Non-Stationary Series')
plt.xlabel('Time')
plt.ylabel('Value')
plt.subplot(2, 1, 2)
plt.plot(time[:-1], diff_x, label='First Order Difference')
plt.title('First Order Difference (Stationary Series)')
plt.xlabel('Time')
plt.ylabel('Value')
plt.show()
# 使用AutoReg来拟合AR(1)模型
model = AutoReg(diff_x, lags=1)
model_fit = model.fit()
# 打印模型摘要
print(model_fit.summary())
# 预测差分后的序列
forecast_steps = 5
forecast_index = np.arange(len(diff_x), len(diff_x) + forecast_steps)
forecast_values = model_fit.predict(start=len(diff_x), end=len(diff_x) + forecast_steps - 1)
# 逆差分运算 + 加上最后一个原始值
cumulative_forecast = np.cumsum(forecast_values) + x[-1]
# 绘制预测结果
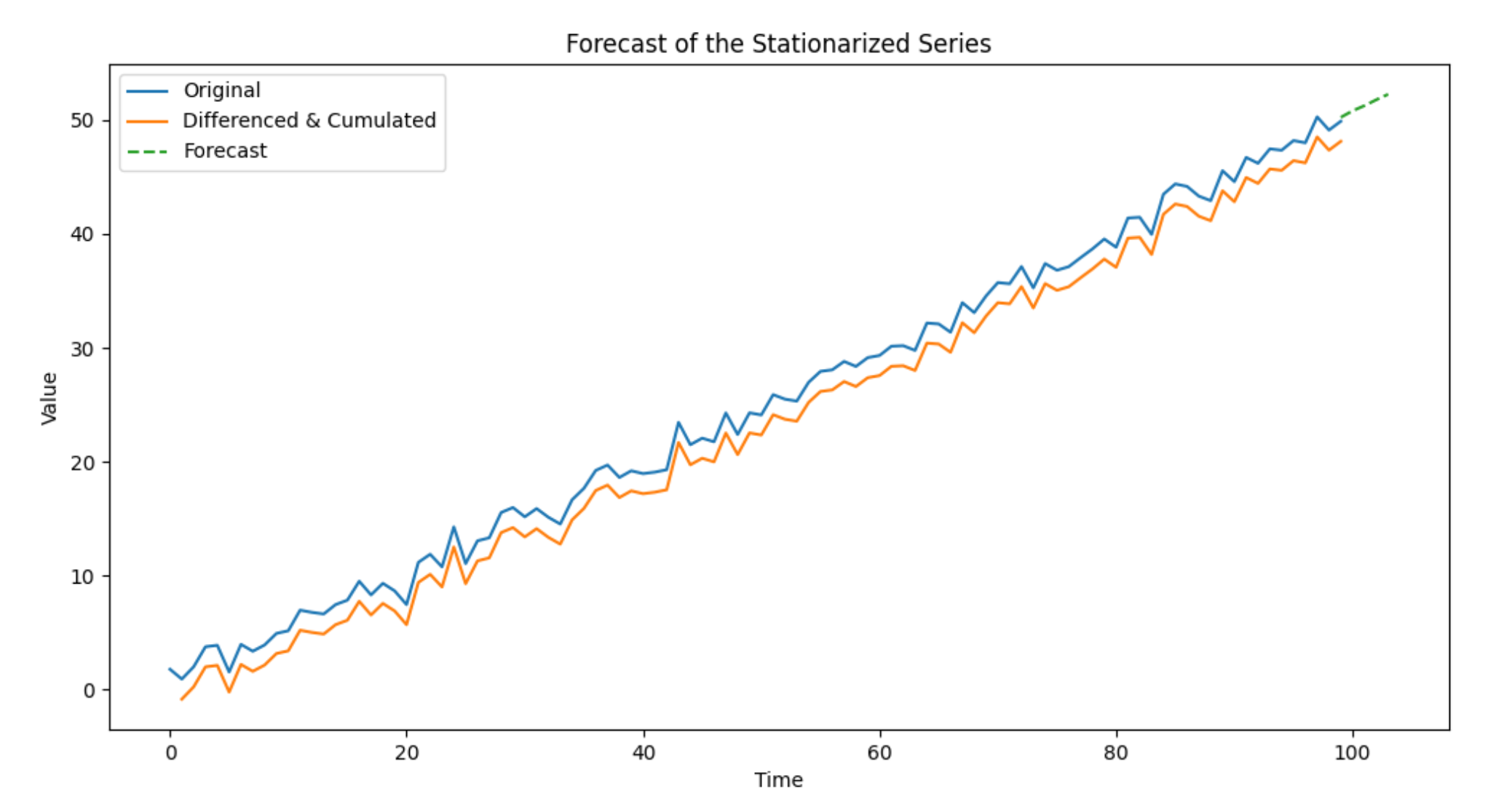
plt.figure(figsize=(12, 6))
plt.plot(time, x, label='Original')
plt.plot(time[1:], np.cumsum(diff_x), label='Differenced & Cumulated')
plt.plot(forecast_index, cumulative_forecast, label='Forecast', linestyle='--')
plt.title('Forecast of the Stationarized Series')
plt.xlabel('Time')
plt.ylabel('Value')
plt.legend()
plt.show()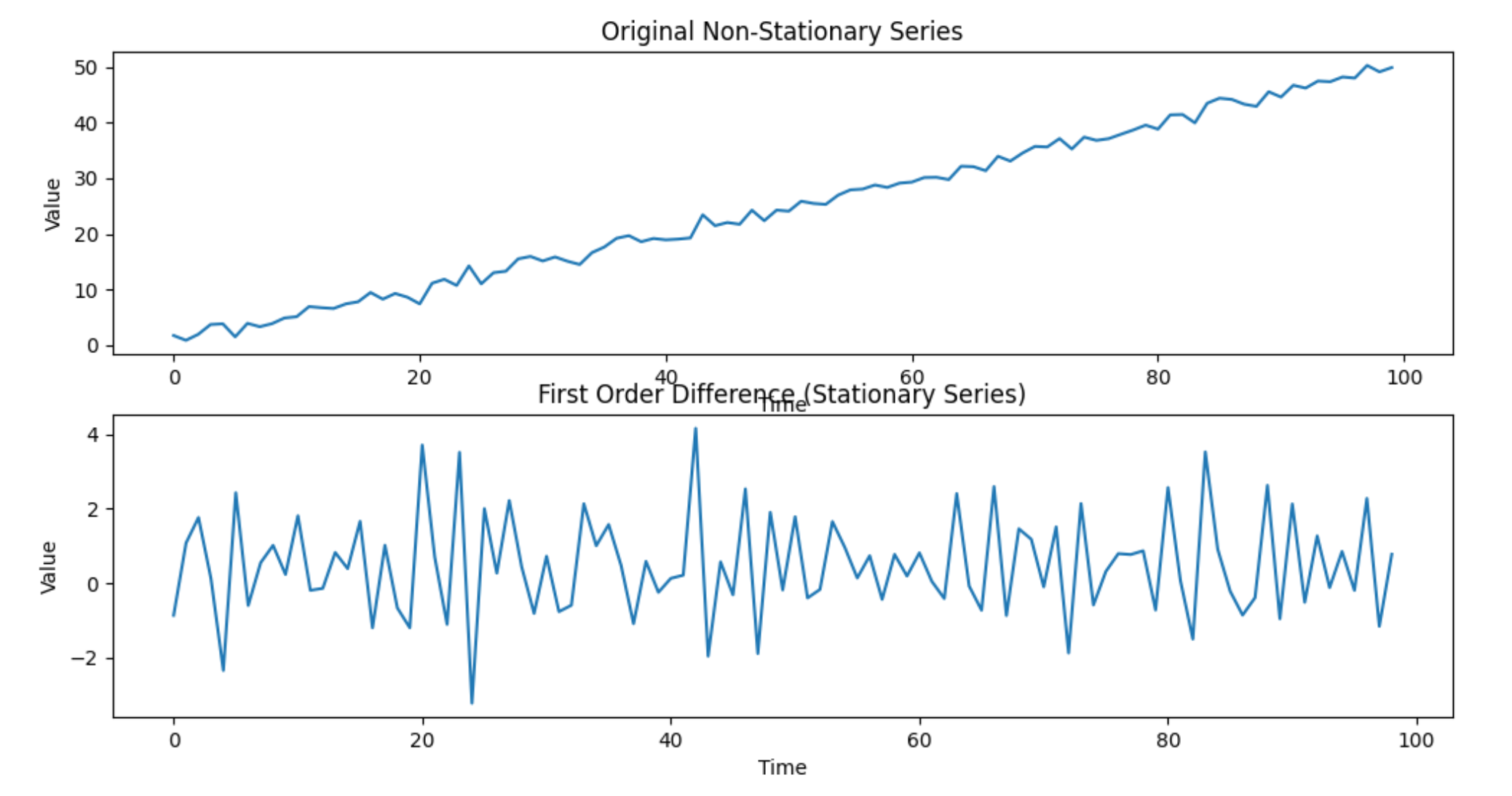
预测的效果看上去还是不错的。作为示例,这里没有提供真实走势的对比,也没有提供预测误差参数评估。
(2)ARIMA模型
ARIMA模型,全称为自回归整合移动平均模型(Autoregressive Integrated Moving Average Model)。ARIMA(p,d,q)中,AR代表"自回归",p为自回归项数;MA代表"滑动平均",q为滑动平均项数;d为使数据成为平稳序列所做的差分次数(阶数)。
ARIMA模型的核心思想:通过分析时间序列数据的历史信息,识别数据的内在规律和趋势,进而对未来进行预测。具体来说,ARIMA模型通过对数据的自回归部分(AR)、差分部分(I)和滑动平均部分(MA)进行建模,来捕捉数据的动态特性。
相比AR模型,ARIMA模型是一种更为复杂和灵活的时间序列预测方法,它结合了自回归、移动平均和差分三个部分,适用于各种类型的时间序列数据。而AR模型则是一种较为简单的方法,仅利用历史数据进行建模,适用于具有明显线性关系的平稳时间序列数据。
举例:本例是一个股票模拟的案例。
python
import numpy as np
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
import matplotlib.pyplot as plt
# 模拟时间序列数据(股票价格)
np.random.seed(0) # 为了可复现性
dates = pd.date_range(start='2020-01-01', periods=100, freq='B') # 每周五的数据
prices = np.cumsum(np.random.randn(100) * 100 + 5) + 100 # 模拟的股票价格
data = pd.DataFrame(prices, index=dates, columns=['Close'])
# ARIMA模型建模
# 1. 平稳性检验(这里省略,因为是模拟数据)
# 2. 确定模型的阶数(这里我们选择p=1, d=1, q=1作为示例)
p, d, q = 1, 1, 1
# 3. 建模
model = ARIMA(data['Close'], order=(p, d, q))
model_fit = model.fit()
# 4. 预测
n_steps = 10 # 预测未来10个时间点的值
forecast_steps = model_fit.get_forecast(steps=n_steps)
forecast_values = forecast_steps.predicted_mean
conf_int = forecast_steps.conf_int()
# 创建一个新的日期范围用于绘制预测值
forecast_dates = pd.date_range(start=data.index[-1] + pd.DateOffset(days=1), periods=n_steps, freq='B')
# 绘制原始数据
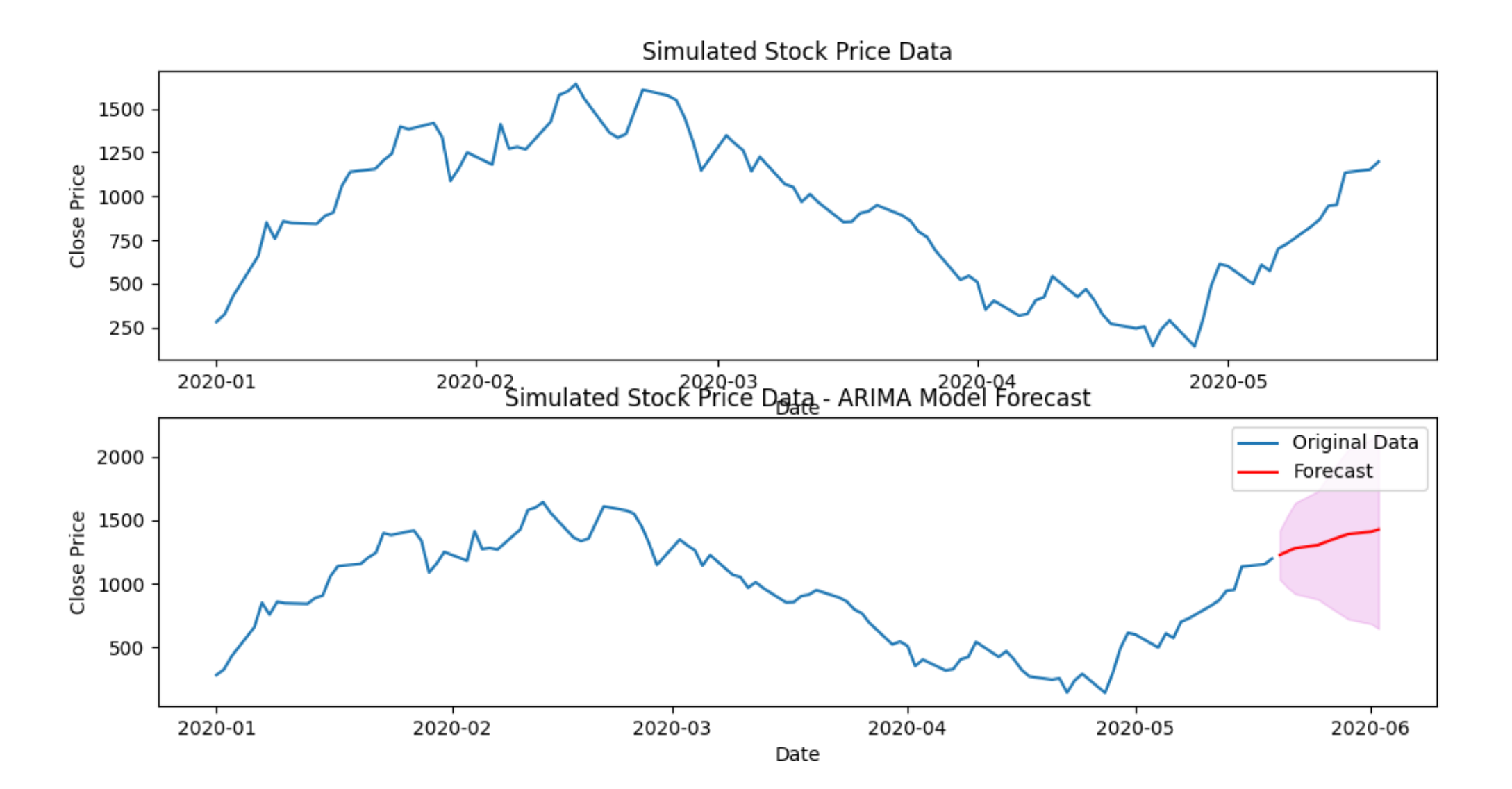
plt.figure(figsize=(12, 6))
plt.subplot(2, 1, 1)
plt.plot(data.index, data['Close'], label='Original Data')
plt.title('Simulated Stock Price Data')
plt.xlabel('Date')
plt.ylabel('Close Price')
# 绘制预测结果
plt.subplot(2, 1, 2)
plt.plot(data.index, data['Close'], label='Original Data')
plt.plot(forecast_dates, forecast_values, label='Forecast', color='red')
# 绘制置信区间
plt.fill_between(forecast_dates, conf_int.iloc[:, 0], conf_int.iloc[:, 1], color='m', alpha=.15)
# 添加图例、标题、轴标签等
plt.title('Simulated Stock Price Data - ARIMA Model Forecast')
plt.xlabel('Date')
plt.ylabel('Close Price')
plt.legend()
plt.show()预测的效果看上去还是不错的。作为示例,这里没有提供真实走势的对比,也没有提供预测误差参数评估。
(3)Prophet模型
Prophet模型是由Meta公司开发并开源的一个时间序列预测算法。该模型适用于具有明显周期性和季节性特征的时间序列数据,能够准确地进行短期到中期的预测。
Prophet模型将时间序列分解为趋势(trend)、季节性(seasonality)、节假日效应(holidays)以及剩余部分(remainder)。每一部分都有特定的应用场景。
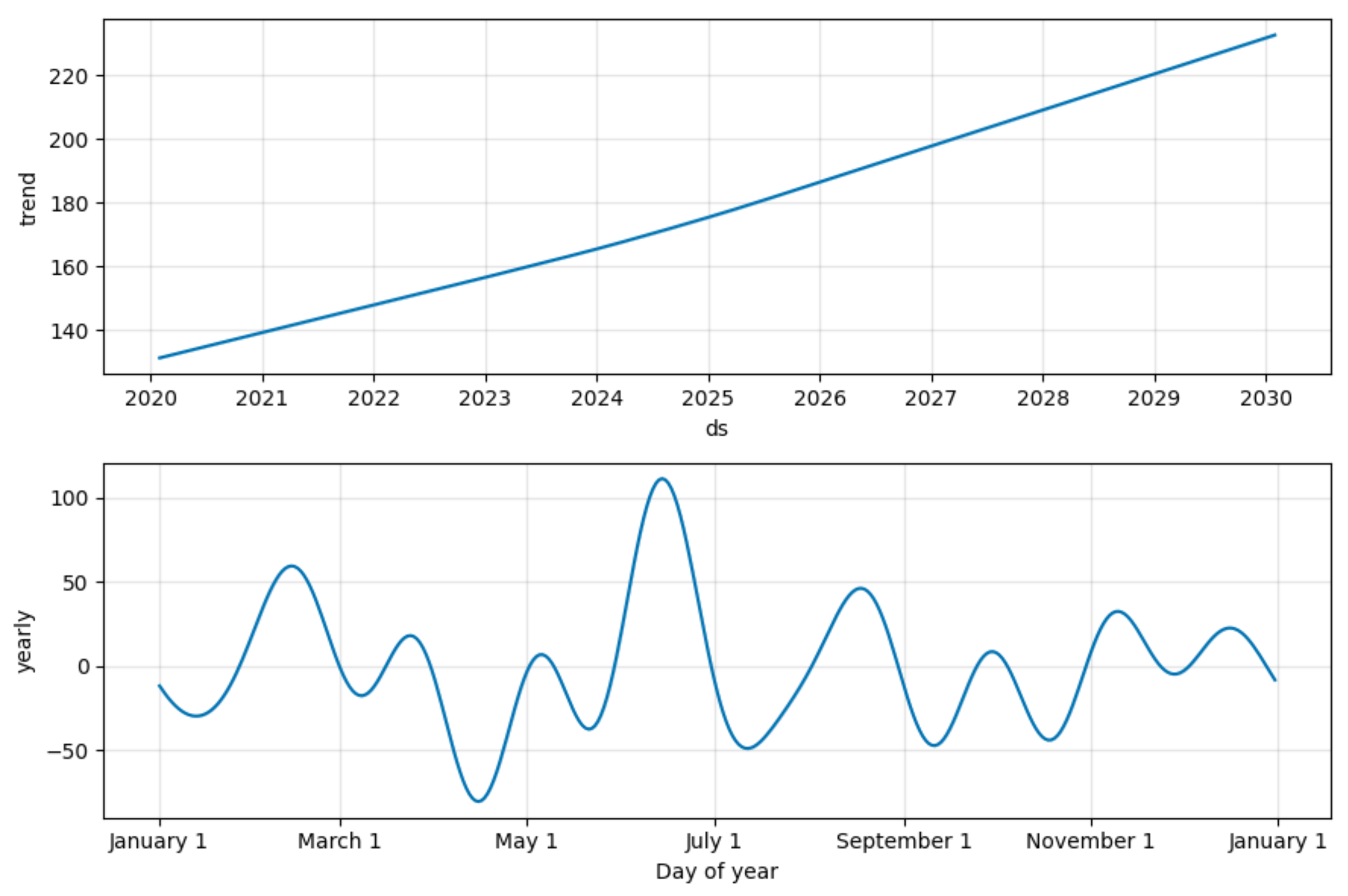
- 趋势(trend):这是时间序列的长期走势。我们可以用它来理解数据的基本走向,比如增长或减少的趋势。在商业分析中,趋势可以帮助预测未来的销售量、用户数等。
- 季节性(seasonality):这是在固定周期内重复出现的模式。例如,某些产品在一年中的某些月份销量会更高,这就是年度季节性;而一周中的某几天销量更高,则是周度季节性。季节性可以帮助我们了解业务的周期性波动,从而制定更有效的策略。
- 节假日效应(holidays):这是特定日期对数据的影响。例如,圣诞节、黑色星期五等特殊日子可能会导致销售量的显著增加。节假日效应可以帮助我们理解特殊事件对业务的影响。
- 剩余部分(remainder):这是模型无法解释的部分,通常包含了随机噪声和模型的误差。剩余部分可以帮助我们理解模型的拟合程度,以及是否存在未被模型捕捉到的模式。
下方是一个简单的示例
python
import numpy as np
import pandas as pd
from prophet import Prophet
import matplotlib.pyplot as plt
np.random.seed(0)
trend = np.linspace(100, 200, 120) # 线性趋势
seasonal = [40, 30, 24, 20] * 30 # 季度季节性
irregular = np.random.normal(0, 5, 120) # 随机不规则成分
data = trend + seasonal + irregular
# 生成pandas序列
index = pd.date_range(start='2020-01-01', periods=120, freq='M')
data = pd.DataFrame({'y': data}, index=index)
data = data.reset_index()
data = data.rename(columns={'index': 'ds'})
data.plot(x='ds',y='y', kind='line')
plt.title('Date vs Y Value')
plt.xlabel('Date')
plt.ylabel('Y Value')
plt.show()
m = Prophet()
m.fit(data)
# 创建未来的数据框架并预测
future = m.make_future_dataframe(periods=30)
forecast = m.predict(future)
# 绘制预测组件图
fig1 = m.plot_components(forecast)
plt.show()
# 绘制预测与原始数据的对比图
fig2 = m.plot(forecast)
# 提取原始数据的时间序列和预测值
original_data = data.set_index('ds')
forecast_data = forecast[['ds', 'yhat']].set_index('ds')
# 绘制原始数据
ax = fig2.gca()
original_data['y'].plot(ax=ax, color='blue', label='Actual')
# 绘制预测值
forecast_data['yhat'].plot(ax=ax, color='orange', label='Forecast', alpha=0.7)
# 添加图例
ax.legend()
# 显示图表
plt.show()原始数据序列。
用Prophet模型将序列分解为trend和seasonality。
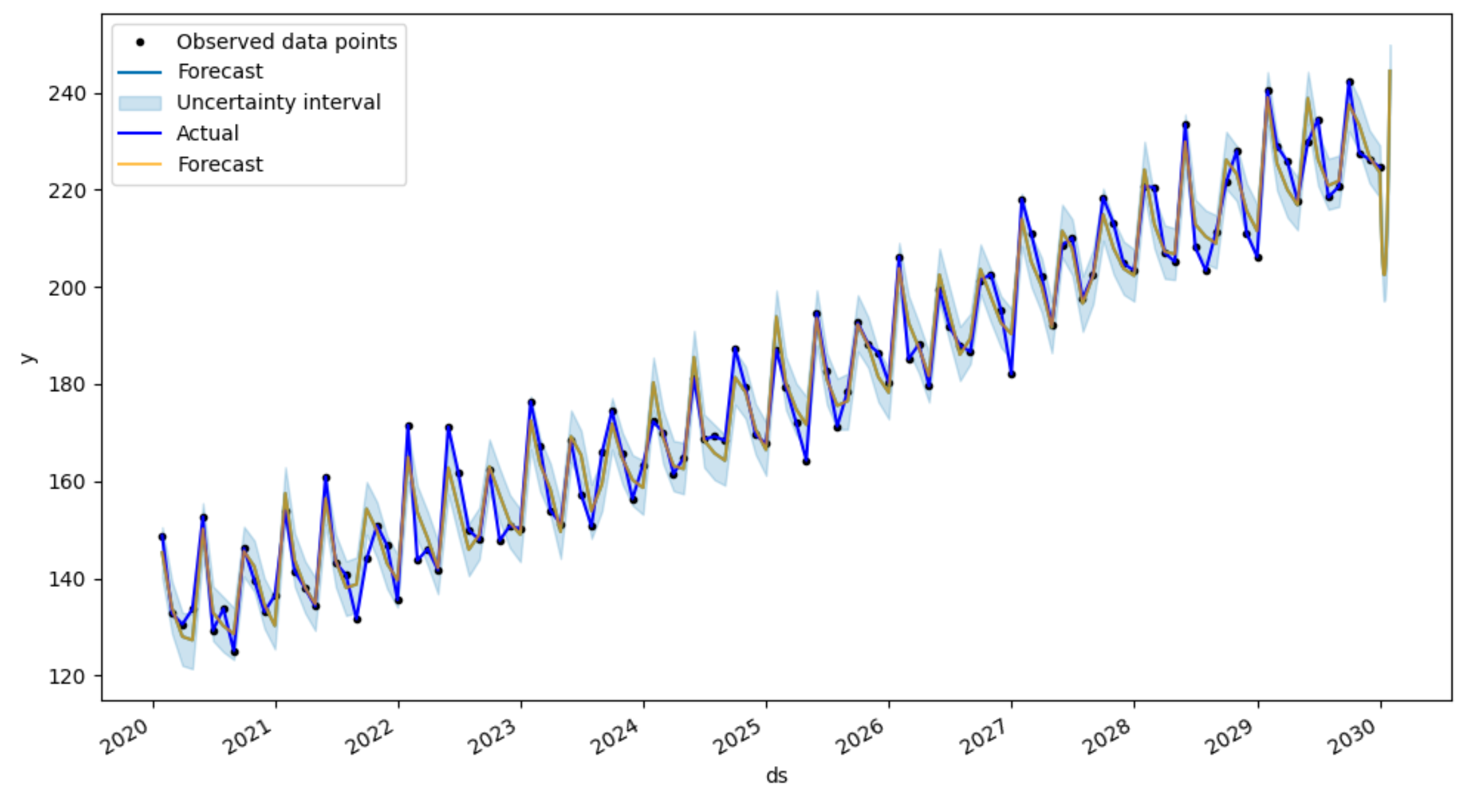
用Prophet模型预测序列未来30天走势,如黄色曲线所示。
(4)LSTM模型
LSTM 是一种特殊的循环神经网络(RNN),旨在解决传统 RNN 在处理长序列时遇到的梯度消失或梯度爆炸问题。LSTM 通过其内部的"门"结构(如输入门、遗忘门和输出门)来记住长期依赖关系,并有效地忽略不相关的信息。这种特性使得 LSTM 在处理时间序列数据时具有天然的优势,因为它可以捕捉数据中的长期和短期模式。
LSTM网络在时间序列预测中的主要优势包括:
- 捕捉长期依赖关系:传统的RNN在处理长序列时容易遇到梯度消失或梯度爆炸的问题,这限制了它们捕捉长期依赖关系的能力。而LSTM通过其内部的"门"结构(输入门、遗忘门和输出门)以及记忆单元,能够记住并有效地利用过去的重要信息,从而捕捉到时间序列数据中的长期依赖关系。
- 处理变长的输入序列:时间序列数据的一个特点是其长度通常是可变的。LSTM网络能够处理任意长度的输入序列,而不需要像传统神经网络那样需要固定大小的输入。这使得LSTM能够灵活地适应不同长度的时间序列数据。
- 减轻过拟合问题:LSTM网络中的多个参数和门结构使得它能够学习复杂的模式,同时也具有一定的正则化效果,从而减轻了过拟合问题。这意味着LSTM网络可以在较小的数据集上训练,而不需要大量的数据来避免过拟合。
- 适应非线性关系:时间序列数据中的变量之间通常存在非线性关系。LSTM网络作为一种深度学习模型,具有强大的非线性映射能力,能够处理这种复杂的非线性关系。
LSTM模型在金融领域,可以用于预测股票价格或货币汇率;在气象领域,它可以用于预测未来的天气模式;在交通领域,它可以用于预测交通流量或拥堵情况等。
(5)Transformer模型
Transformer模型是作为一种序列到序列(sequence-to-sequence)的模型提出的,主要用于自然语言处理(NLP)任务,如机器翻译。由于其强大的序列建模能力,Transformer模型也被广泛应用于各种序列预测任务中。
Transformer模型用于序列预测的优势如下:
- 长距离依赖建模:Transformer通过自注意力(self-attention)机制能够直接捕获输入序列中任意两个位置之间的依赖关系,这对于长序列预测非常有帮助。
- 并行计算:Transformer在编码器和解码器中都使用了自注意力机制,这使得模型可以并行处理整个输入序列,从而提高了计算效率。
- 灵活性:Transformer模型可以通过改变输入和输出的长度来适应不同的序列预测任务。此外,它还可以与各种其他模型或技术(如卷积神经网络、循环神经网络等)结合使用。
- 强大的表示能力:Transformer的多个自注意力层可以学习到输入序列的复杂表示,这对于提高预测准确性至关重要。
(6)模型评估
对于时间序列预测模型,常用的评估指标包括以下几种:
6.1 MAE(平均绝对误差)
MAE(Mean Absolute Error,平均绝对误差)是预测值与真实值之间的绝对差值的平均值。它给出了预测误差的平均大小,而不考虑误差的方向。
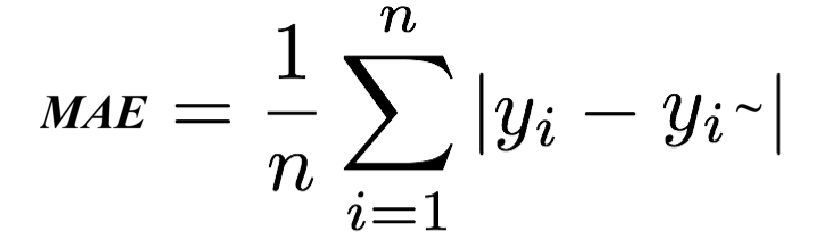
其中 yi 是第i个观测的真实值, yi~ 是对应的预测值,n是观测的数量。
MAE的优点是它对异常值不那么敏感,因为它使用的是绝对值。缺点是它对误差的惩罚不如MSE或RMSE严厉,因此在一些应用中可能无法充分反映预测误差的重要性。
6.2 MSE(均方误差)
MSE是预测值与真实值之间的差值的平方的平均值。它强调了大误差的重要性,因为误差被平方了,所以MSE对大的预测误差更为敏感。
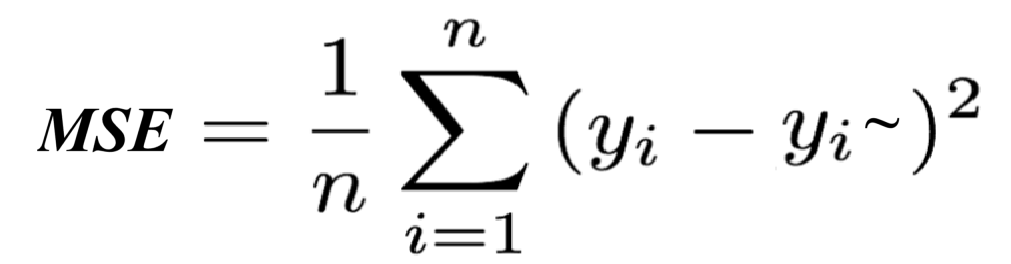
MSE的优点是它对误差的大小有更强的敏感度,这使得它在模型优化时更偏向于减少大的误差。缺点是它对异常值的敏感度高,异常值的存在可能导致MSE值的大幅波动。
6.3 RMSE(均方根误差)
RMSE是MSE的平方根,它将MSE的单位恢复到了原始数据的单位,使得RMSE的值与数据本身在相同尺度上,更易于解释。
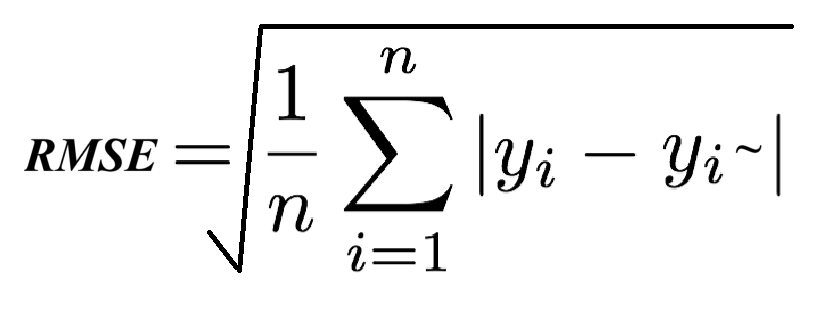
RMSE继承了MSE的所有特点,但它提供了与原始数据单位一致的误差度量,使得比较不同尺度的数据时更加直观。RMSE同样对大的预测误差敏感。