引言
在深度学习领域,卷积神经网络(CNN)已经在计算机视觉任务中取得了巨大成功。然而,从头开始训练一个高性能的CNN模型需要大量标注数据和计算资源。迁移学习(Transfer Learning)技术为我们提供了一种高效解决方案,它能够将预训练模型的知识迁移到新任务中,显著减少训练时间和数据需求。本文将全面介绍CNN迁移学习的原理、优势及实践方法。
1、内容
迁移学习是指利用已经训练好的模型,在新的任务上进行微调。迁移学习可以加快模型训练速度,提高模型性能,并且在数据稀缺的情况下也能很好地工作
2、步骤
1、选择预训练的模型和适当的层:通常,我们会选择在大规模图像数据集(如ImageNet)上预训练的模型,如VGG、ResNet等。然后,根据新数据集的特点,选择需要微调的模型层。对于低级特征的任务(如边缘检测),最好使用浅层模型的层,而对于高级特征的任务(如分类),则应选择更深层次的模型。
2、冻结预训练模型的参数:保持预训练模型的权重不变,只训练新增加的层或者微调一些层,避免因为在数据集中过拟合导致预训练模型过度拟合。
3、在新数据集上训练新增加的层:在冻结预训练模型的参数情况下,训练新增加的层。这样,可以使新模型适应新的任务,从而获得更高的性能。
4、微调预训练模型的层:在新层上进行训练后,可以解冻一些已经训练过的层,并且将它们作为微调的目标。这样做可以提高模型在新数据集上的性能。
5、评估和测试:在训练完成之后,使用测试集对模型进行评估。如果模型的性能仍然不够好,可以尝试调整超参数或者更改微调层。
Resnet网络:
原理:
卷积神经网络都是通过卷积层和池化层的叠加组成的。 在实际的试验中发现,随着卷积层和池化层的叠加,学习效果不会逐渐变好,反而出现2个问题:
1、梯度消失和梯度爆炸
梯度消失:若每一层的误差梯度小于1,反向传播时,网络越深,梯度越趋近于0
梯度爆炸:若每一层的误差梯度大于1,反向传播时,网络越深,梯度越来越大
2、退化问题
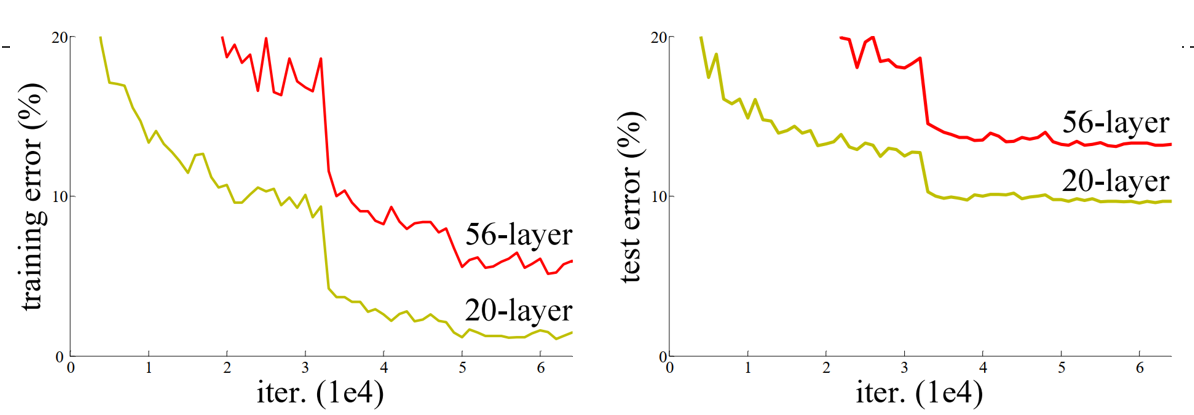
为了解决梯度消失或梯度爆炸问题,论文提出通过数据的预处理以及在网络中使用**BN(Batch Normalization)**层来解决。
为了解决深层网络中的退化问题,可以人为地让神经网络某些层跳过下一层神经元的连接,隔层相连,弱化每层之间的强联系。这种神经网络被称为 残差网络 (ResNets)。
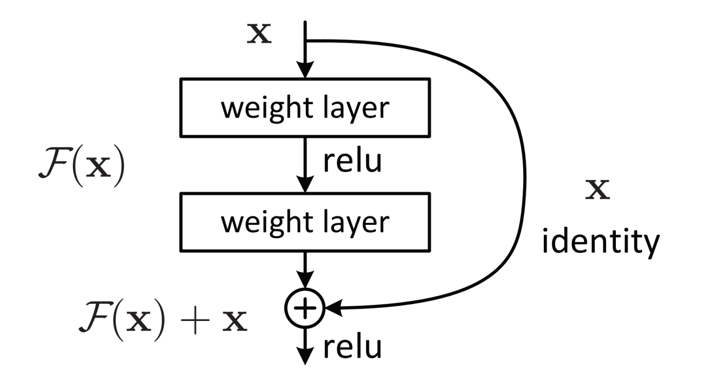
1、18层resnet结构:
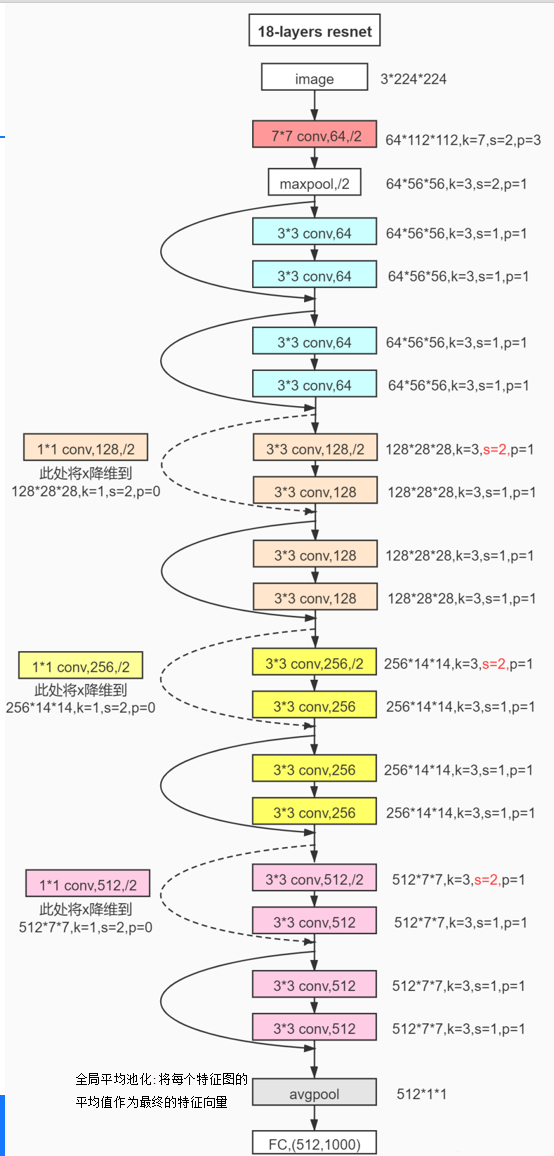
2、BN(Batch Normalization)
实例
1、导入相关的库
python
import torch
from torch.utils.data import DataLoader,Dataset #数据包管理工具,打包数据,
from torchvision import transforms
from torch import nn
import torchvision.models as models
from PIL import Image
import numpy as np2、调取模型并冻结参数
python
#不再需要自己来搭建模型了。预训练的文件也加载进去了。
# 将resnet18模型迁移到食物分类项目中.#残差网络是固定的网络结构,不需要你自己来类定义了。
resnet_model=models.resnet18(weights=models.ResNet18_Weights.DEFAULT)
#weights=models.ResNet18_Weights.DEFAULT表示使用在 ImageNet 数据集上预先训练好的权重
for param in resnet_model.parameters():
print(param)
param.requires_grad=False #冻结
#模型所有参数(即权重和偏差)的requires_grad属性设置为False,从而冻结所有模型参数,详细说明:
-
models.resnet18()加载ResNet18架构 -
weights=models.ResNet18_Weights.DEFAULT指定使用官方预训练权重 -
遍历所有参数并冻结
3、对网络模型进行微调
python
in_features=resnet_model.fc.in_features #获取模型原输入的特征个数
resnet_model.fc=nn.Linear(in_features,20) #创建一个全连接层4、保存需要训练的参数
python
params_to_update=[] #保存需要训练的参数,仅仅包含全连接层的参数
for param in resnet_model.parameters():
if param.requires_grad==True:
params_to_update.append(param)5、数据预处理
python
data_transforms={
'train':
transforms.Compose([
transforms.Resize([300, 300]),
transforms.RandomRotation(45), # 随机旋转,-45到45度之间随机选
transforms.CenterCrop(224), # 从中心开始裁剪[256,256]
transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转 选择一个概率概率
transforms.RandomVerticalFlip(p=0.5), # 随机垂直翻转
# transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),
transforms.RandomGrayscale(p=0.1), # 概率转换成灰度率,3通道就是R=G=B
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'valid':
transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
}数据预处理包括:
-
训练集使用多种数据增强(随机旋转、水平翻转等)
-
验证集只进行简单的resize和归一化
-
归一化参数使用ImageNet的均值和标准差
6、自定义数据集的类
python
class food_dataset(Dataset):
def __init__(self,file_path,transform=None):
self.file_path=file_path
self.imgs=[]
self.labels=[]
self.transform=transform
with open(self.file_path) as f:
samples=[x.strip().split(' ') for x in f.readlines()]
for img_path,label in samples:
self.imgs.append(img_path)
self.labels.append(label)
def __len__(self):
return len(self.imgs)
def __getitem__(self, idx):
image=Image.open(self.imgs[idx])
if self.transform:
image=self.transform(image)
label = self.labels[idx]
label = torch.from_numpy(np.array(label,dtype=np.int64))
return image,label这个自定义Dataset类:
-
从文本文件读取图像路径和标签
-
实现**
__len__** 和**__getitem__**方法,供DataLoader使用 -
应用指定的transform处理图像
7、数据加载器准备
python
# 创建训练集和测试集实例
training_data = food_dataset(file_path='trainda.txt', transform=data_transforms['train'])
test_data = food_dataset(file_path='testda.txt', transform=data_transforms['valid'])
# 创建数据加载器
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)数据加载器提供:
-
批量加载功能(batch_size=64)
-
训练数据随机打乱(shuffle=True)
-
多线程数据预读取
8、训练和测试流程
python
def train(dataloader,model,loss_fn,optimizer):
model.train() #告诉模型,我要开始训练,模型中w进行随机化操作,已经更新w。在训练过程中,w会被修改的
#pytorch提供2种方式来切换训练和测试的模式,分别是:model.train()和 model.eval()。
#一般用法是:在训练开始之前写上model.trian(),在测试时写上 model.eval()
for X,y in dataloader: #其中batch为每一个数据的编号
X,y=X.to(device),y.to(device) #把训练数据集和标签传入cpu或GPU
pred=model.forward(X) #.forward可以被省略,父类中已经对次功能进行了设置。自动初始化
loss=loss_fn(pred,y) #通过交叉熵损失函数计算损失值loss
# Backpropagation 进来一个batch的数据,计算一次梯度,更新一次网络
optimizer.zero_grad() #梯度值清零
loss.backward() #反向传播计算得到每个参数的梯度值w
optimizer.step() #根据梯度更新网络w参数
best_acc=0
def test(dataloader, model, loss_fn):
global best_acc
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model.forward(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size9、循环训练
python
# 定义损失函数和优化器
loss_fn = nn.CrossEntropyLoss() # 交叉熵损失
optimizer = torch.optim.Adam(params_to_update, lr=0.001) # Adam优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5) # 学习率调度
# 训练10个epoch
epoch = 10
for i in range(epoch):
print(f"Epoch {i + 1}")
train(train_dataloader, model, loss_fn, optimizer) # 训练
scheduler.step() # 更新学习率
test(test_dataloader, model, loss_fn) # 测试
print('Best accuracy:', best_acc) # 打印最佳准确率主循环流程:
-
定义损失函数和优化器
-
设置学习率调度器(每5个epoch学习率减半)
-
进行10轮训练和测试
-
打印最终最佳准确率
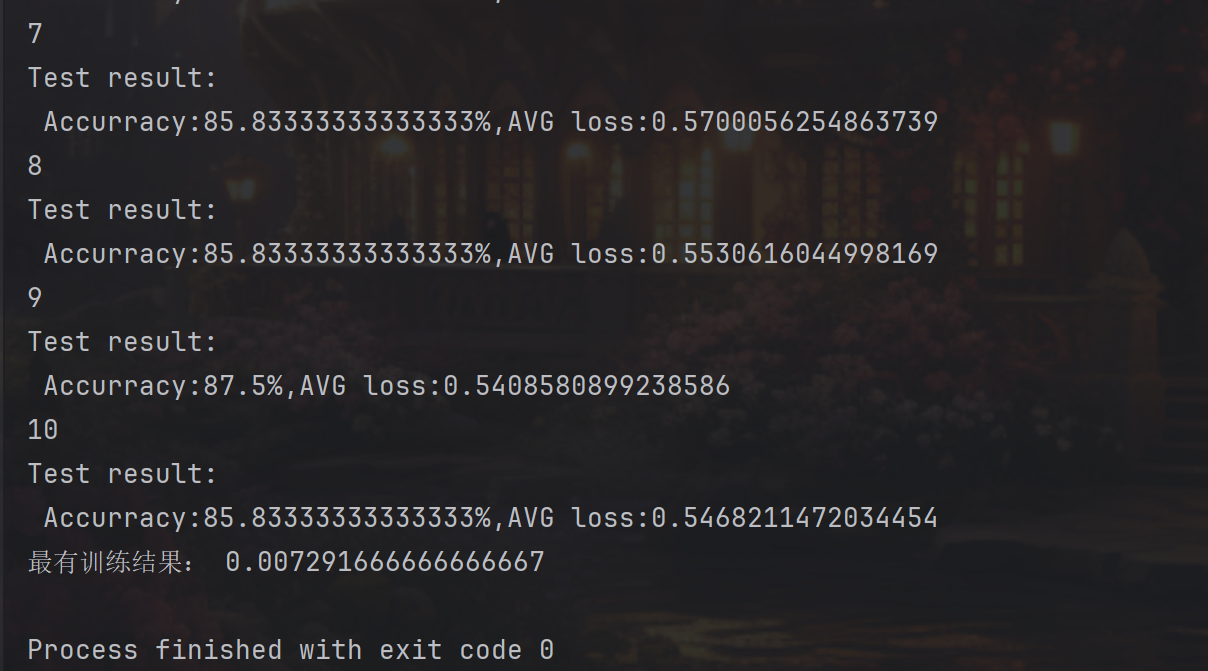
结果展示: