TL;DR
- 2024 年斯坦福大学提出的 OpenVLA,基于大语言模型实现机器人操控,代码完全开源。
Paper Notes
- Name:OpenVLA: An Open-Source Vision-Language-Action Model
- URL:https://openvla.github.io/
- 作者:斯坦福,PMLR 2024
- 开源:是
背景
- 机器人操控学习策略的一个关键弱点在于其无法泛化超出训练数据的范围:尽管现有策略可通过个体技能训练或语言指令训练来适应新的初始条件(如物体位置或光照条件),但它们在处理场景干扰物或新物体时缺乏鲁棒性,且在执行未见过的任务指令时表现不佳
- VLA 在机器人领域的广泛应用仍然面临挑战,主要包括:
- 1)现有的 VLA 主要是封闭的,公众难以获取
- 2)先前的研究未能探索如何高效地微调 VLA 以适应新任务,而这正是推广应用的关键
- 本文解决从一个预训练模型基础上微调视觉-语言-动作(VLA)模型,而不是从零开始训练新行为,从而获得稳健且具有良好泛化能力的视觉运动控制策略
方案
- 提出 OpenVLA,一个70 亿参数的开源 VLA,树立了通用机器人操控策略的新基准。
- 多层次视觉特征融合:OpenVLA 采用预训练的视觉条件语言模型作为主干,能够提取多个粒度的视觉信息
- 大规模、多样化数据训练:在 97 万条机器人操控轨迹(来自 Open-X Embodiment 数据集)上微调,该数据集涵盖多种机器人形态、任务和场景
- 突破 SOTA 结果:在 WidowX 和 Google 机器人平台的 29 项评估任务中,OpenVLA 绝对成功率比 55B 参数的 RT-2-X 提高了 16.5%,且模型规模缩小了一个数量级。
- 支持 LoRA 和模型量化
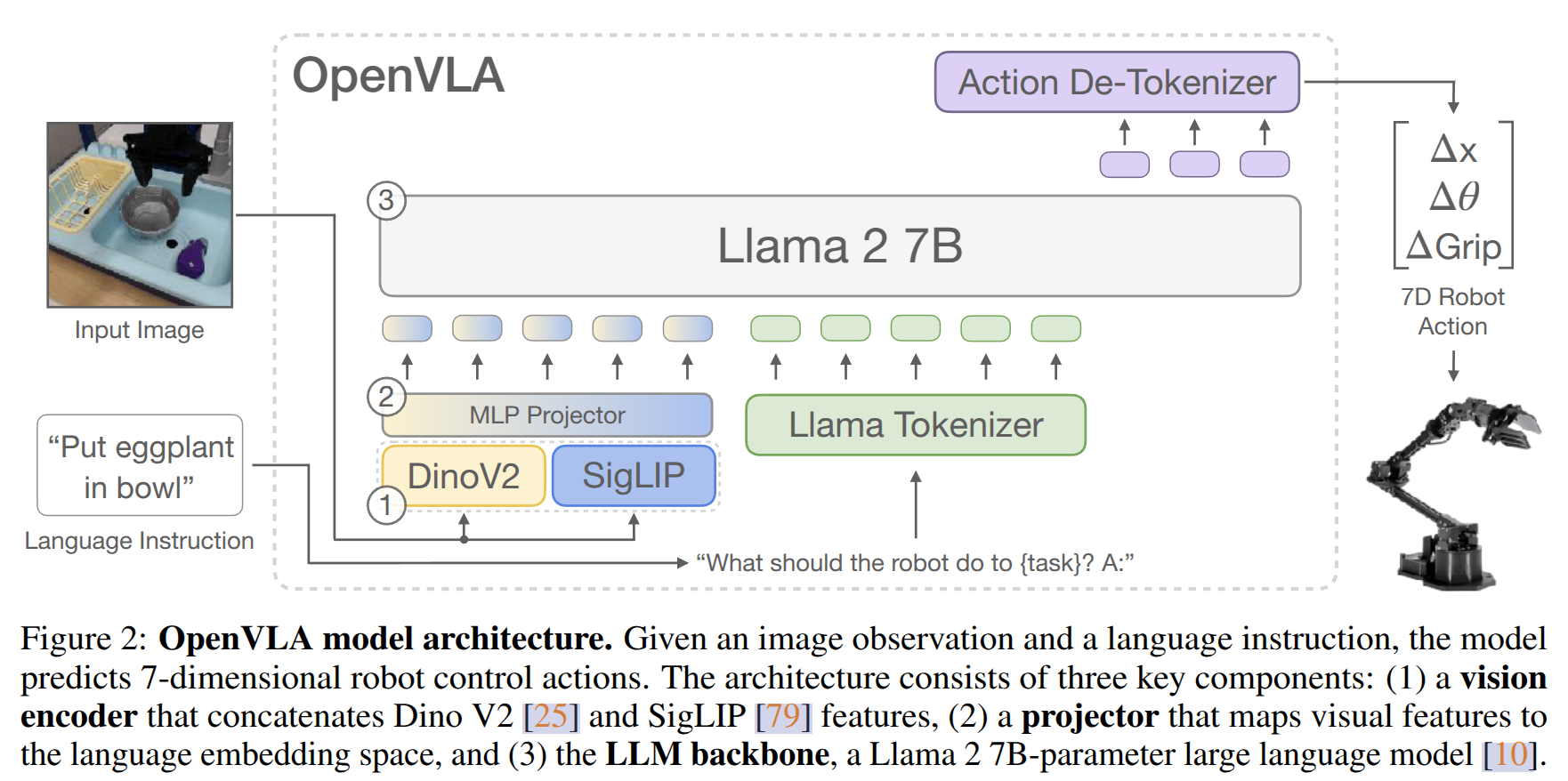
模型架构
- Prismatic-7B VLM 作为主干
- 2 层 MLP 投影层
- 7B llama2 作为语言模型主干
- 600M 参数的视觉编码器(SIGLIP + dinov2)
训练方法
-
VLA 的训练任务:将输入的观察图像和任务自然语言指令映射为机器人动作序列
-
动作离散化
- 连续动作空间 → 离散 token。采用 256 个离散 bin 对机器人动作进行离散化。
- 量化范围设定在训练数据的 1% - 99% 分位数区间,避免极端值影响离散化精度。
- 结果:每个 N 维机器人动作被编码为 N 个 ∈ 0, 255 的整数。
-
适配 Llama Tokenizer
- Llama tokenizer 仅预留了 100 个特殊 token,不足以存储 256 个离散动作 token。
- 解决方案:覆盖 Llama 词汇表中使用最少的 256 个 token,存储 OpenVLA 的动作 token(与 Brohan 等人的 RT-2 方法相同)。
-
损失函数
- 训练目标为标准的下一个 token 预测任务,计算预测动作 token 的交叉熵损失。
训练数据
- 使用 Open X-Embodiment:包含 70+ 个机器人数据集,超过 200 万条机器人轨迹
- 数据筛选与混合策略
- 只保留包含第三人称相机视角的操控数据,并采用单臂末端执行器控制
- 采用 Octo 的数据混合权重,去除低多样性数据,优先使用任务和场景更加多样化的数据
- 额外尝试了 DROID 数据集,但由于训练精度较低,在最终三分之一的训练过程中移除
关键设计
- VLM 主干
- LLaVA 在语言对齐任务(尤其是多对象操控)上优于 IDEFICS-1,成功率提升 35%
- Prismatic-7B 进一步提升 10% 成功率,并具备更强的空间推理能力,因此被选为 OpenVLA 的最终骨干
- 输入分辨率
- 对比:224 × 224px vs. 384 × 384px。
- 结果:高分辨率未提升性能,但计算量增加 3 倍,最终采用 224 × 224px 作为输入分辨率。
- 视觉编码器微调
- 以往 VLM 研究表明,冻结视觉编码器有助于保持其预训练特征
- 然而,在 VLA 任务中,微调视觉编码器对于增强机器人控制精度至关重要,因此我们选择对其进行微调
- 训练超参数
- 训练轮次:
- 典型的 LLM/VLM 仅遍历数据集 1-2 轮,但 VLA 训练需要更多迭代。
- OpenVLA 训练 27 轮,直至动作 token 预测精度超过 95%。
- 学习率:
- 通过实验确定最佳学习率 2e-5(与 VLM 预训练一致)。
- 学习率预热无明显提升,因此未采用。
- 训练轮次:
- 硬件:
- 训练:64 A100,训练 14 天
- 推理:bf16 占用 15G 显存。4090 上 6 Hz 推理速度
实验
-
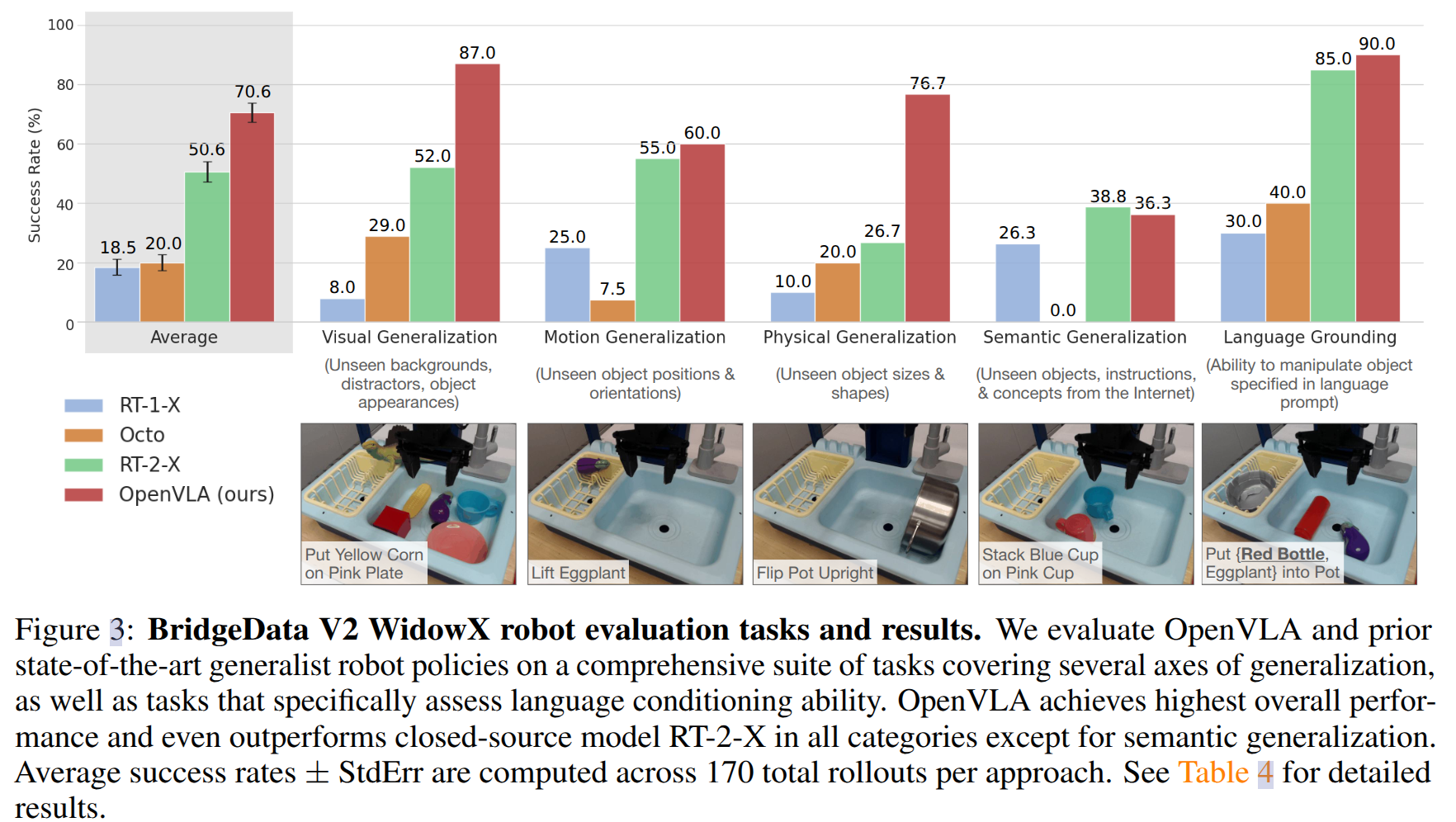
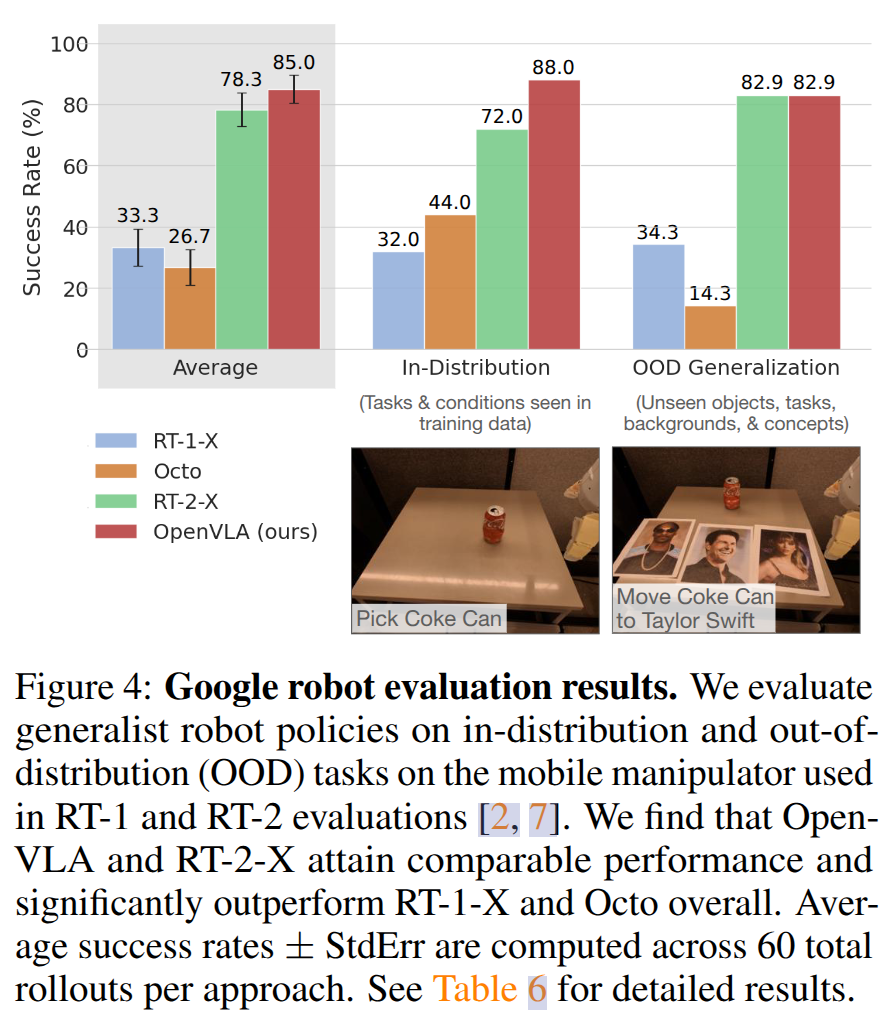
OpenVLA 在 Google 机器人评估中与 RT-2-X 具有相当的表现,在 BridgeData V2 评估中明显优于 RT-2-X,尽管其参数量小 (7B vs. 55B)。
-
新机器人平台上微调:相比从零训练,OpenVLA 预训练策略明显提升了适应性,表明大规模机器人预训练的优势。使用 10--150 个目标任务的展示数据进行小规模微调,微调后有较大的精度提升
- 8 A100 GPUs for 5-15 hours per task
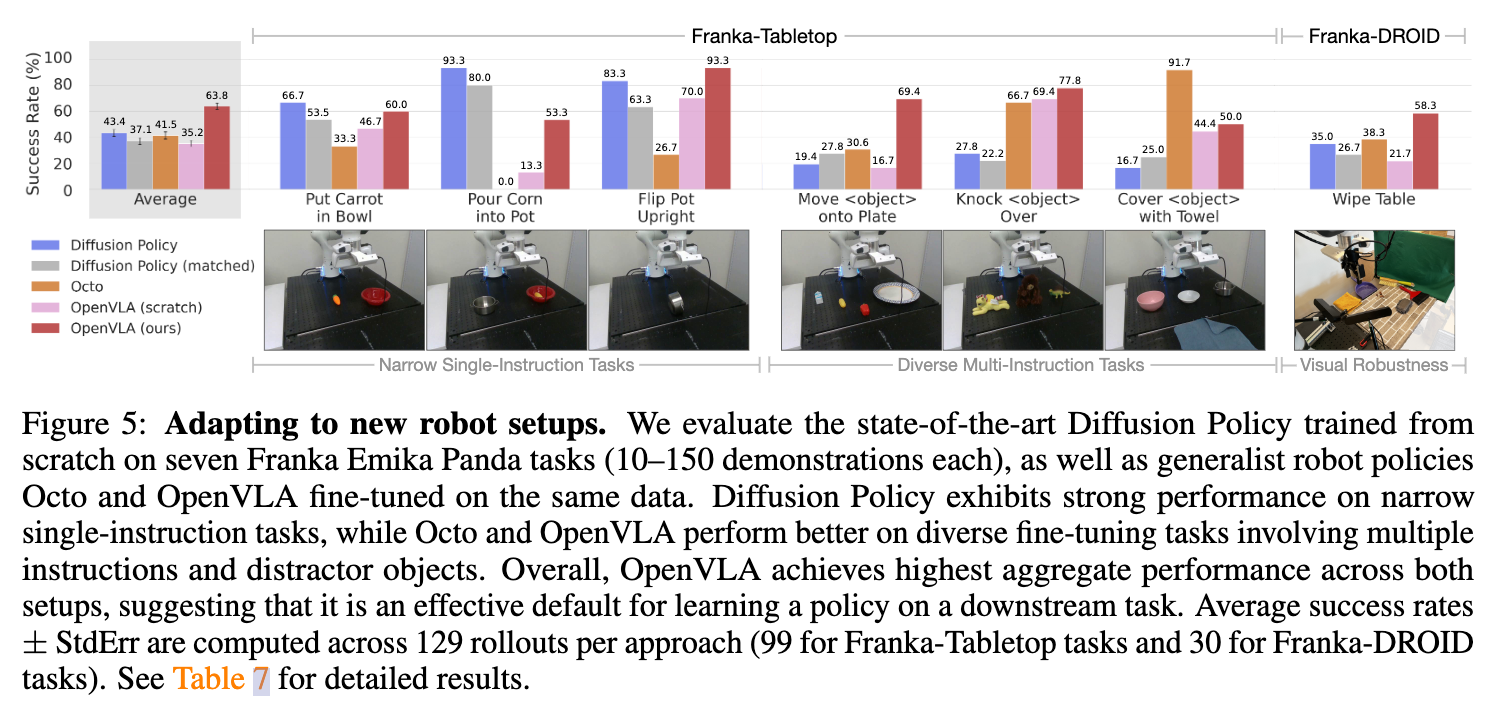
- 8 A100 GPUs for 5-15 hours per task
-
更高效的参数微调:
- sandwich fine-tuning 是 unfreeze vision encoder, token embedding matrix, and last layer,精度也不错。lora fine-tune 有最好的精度
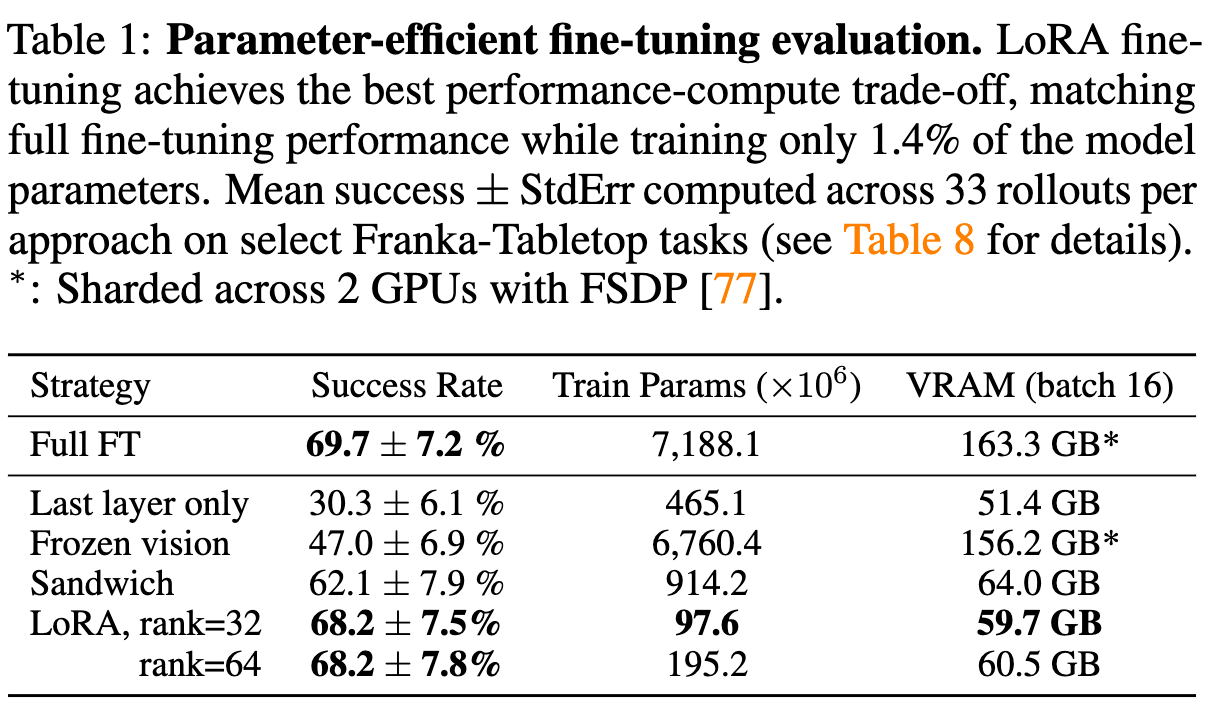
- sandwich fine-tuning 是 unfreeze vision encoder, token embedding matrix, and last layer,精度也不错。lora fine-tune 有最好的精度
-
通过量化提升推理速度,bfloat16 和 4 bit 都有比较好的吞吐
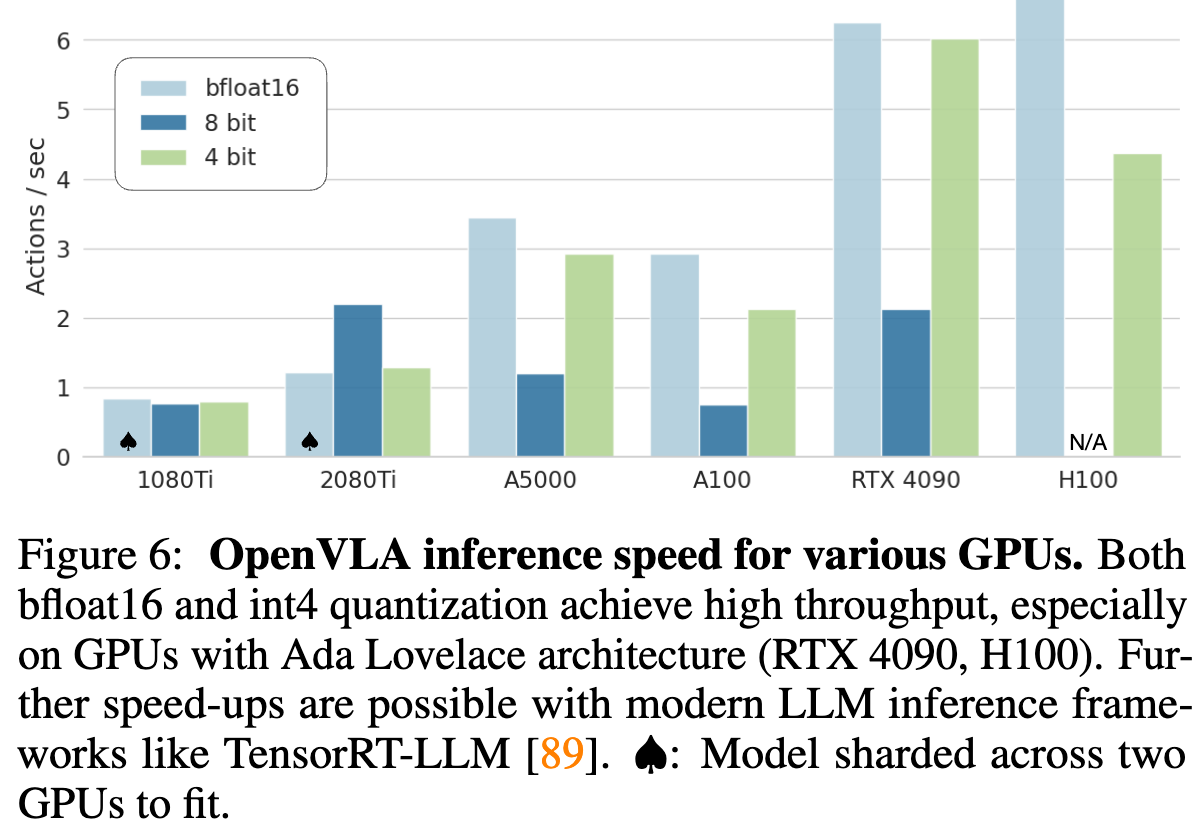
-
由于推理速度的降低,在采用 8 位量化时观察到性能显著下降。用于评估的A5000 GPU上,模型的运行频率仅为 1.2Hz,这与 BridgeData V2 任务中使用的 5Hz 非阻塞控制器的训练数据集相比,系统动态发生了显著变化。4 位量化模型的性能与 bfloat16 半精度推理相当。4位量化模型可以在A5000上以3Hz的频率运行,从而更接近数据收集期间的系统动态。

总结
- OpenVLA 提供了先进的 VLA 预训练模型及高效的微调方法
- 当前仅支持单图像输入,未来支持多图像输入应该有更大的提示空间
- 对于高频控制场景(如以 50Hz 运行的 ALOHA 系统),效率方面还有提升空间,推理时优化技术,如 speculative decoding 可能有用