大家心心念念的 DeepSeek V4 / R4,到现在还是没影儿。
但别急------在沉默了两个月后,DeepSeek 终于放出了正式版的 DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。
今天我们就一起看看这两个模型究竟如何~
DeepSeek V3.2
定位
日常任务与轻量级 Agent 场景,追求响应速度与成本效益。
性能亮点
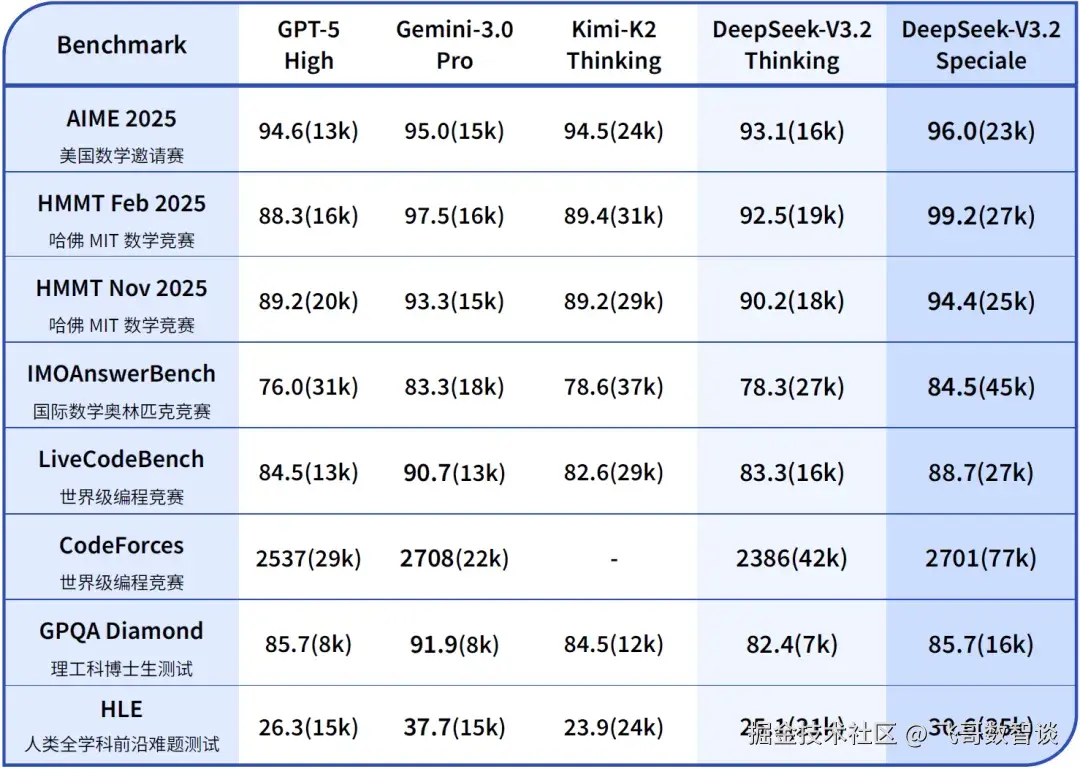
- 推理能力对标
GPT-5,略逊于Gemini 3.0 Pro,优于Kimi-K2-Thinking。 - 输出长度缩短 40%,计算开销降低 35%,长文本处理成本优化至 0.2美元/百万Token(预填充)。
- 首次支持 "思考模式中调用工具",实现多轮推理与工具交互的无缝融合。

技术创新
- DSA(DeepSeek Sparse Attention) :通过"闪电索引器"动态筛选关键 Token,将注意力计算复杂度从 O(L²) 降至 O(L·k),突破长上下文瓶颈。
- 强化学习优化:投入超预训练 10% 的算力,结合 GRPO 算法提升稳定性,在 Agent 任务中泛化能力显著增强。
DeepSeek-V3.2-Speciale
定位
探索模型能力边界,专注数学证明、算法竞赛等高阶任务。
性能亮点
- 在
IMO 2025、IOI 2025、ICPC 2025均达金牌水平(ICPC 全球第2名); - 推理性能媲美
Gemini 3.0 Pro,部分任务超越GPT-5。
技术创新
融合 DeepSeek-Math-V2 的定理证明模块,具备出色的指令跟随、严谨的数学证明与逻辑验证能力。
设计取舍
- 为最大化推理深度,放弃输出长度约束,Token 消耗达标准版 3 倍;
- 未优化日常对话,不支持工具调用,仅通过临时 API 开放研究用途。
使用
目前官网、APP、API 模型已由 DeepSeek-V3.2-Exp 升级为正式版 DeepSeek-V3.2,使用方式不变,大家可以自行尝试。
而 DeepSeek-V3.2-Speciale 仅提供 API 方式,可通过设置 base_url="https://api.deepseek.com/v3.2_speciale_expires_on_20251215"使用。
DeepSeek-V3.2-Speciale 最大输出长度默认为 128K,支持时间截止至 2025-12-15 23:59。
V/R 命名的终结
DeepSeek 最初模型是分为 V 系列 (普通模型)和 R 系列(推理模型)的,大家也一直都在等着 V4 / R4 的诞生。
但根据我的猜测,之后大概率没有 V/R 的区分了。
年初,推理模型刚刚兴起,V/R 可以方便的区分不同模型的技术架构,有利于品牌建立。
但现在模型的发展已经足够强大,DeepSeek 的品牌也足够深入人心,因此,今年 DeepSeek 明显转向按场景定义模型,比如这次的 V3.2(日常使用)和 V3.2-Speciale(研究专用)。
毕竟,我们已经从"炫技 "来到了"落地"阶段。
结语
不知道最近几天大家看没看 Ilya 的最新访谈《Scaling时代结束,研究时代开启》。
里面的观点,正好和 DeepSeek 坚持的 架构优化、强化学习等工程化手段 相印证。
过去一年 DeepSeek 一直没有发布大版本更新,或者,他们也在等着春节?就像去年那样。