1. 引言
Milvus 是一个强大的工具,帮助开发者处理大规模向量数据,尤其是在人工智能和机器学习领域。它可以高效地存储和检索高维向量数据,适合需要快速相似性搜索的场景。在 .NET 环境中,开发者可以通过 Milvus C# SDK 轻松连接和操作 Milvus 服务器,包括创建集合、插入数据和执行搜索等操作。
- Milvus 是一个开源向量数据库,专为 AI 和 ML 应用设计,支持高效相似性搜索。
- 它采用云原生架构,分为接入层、协调服务、工作节点和存储四层,便于扩展。
- 在 .NET 中,可通过 Milvus C# SDK(当前为 2.3.0-preview.1)操作 Milvus,安装简单,功能包括创建集合、插入数据和搜索。
- Milvus 在图像检索、推荐系统和 NLP 等场景中表现优异,最新版本为 2.5.9(2025 年 4 月 14 日)。
- Milvus 在性能上通常优于其他向量数据库,特别是在大规模数据处理中。
2. Milvus 概述
Milvus 是一个在 2019 年创建的开源向量数据库,其主要目标是存储、索引和管理由深度神经网络和其他机器学习(ML)模型生成的大规模嵌入向量。它能够处理万亿级别的向量索引,特别适用于非结构化数据的处理,例如图像、视频、音频和自然语言等,这些数据占全球数据的约 80%。
Milvus 的设计原则是云原生,将存储和计算分离,所有组件均为无状态。
Milvus 支持多种索引和度量,适合不同的应用场景。以下是支持的索引类型及其适用场景:
| 索引类型 | 分类 | 最佳适用场景 |
|---|---|---|
| FLAT | 无 | 小规模(百万级)数据集,追求精度 |
| IVF_FLAT | 无 | 平衡精度和查询速度 |
| IVF_SQ8 | 量化-based | 资源受限,减少内存消耗 |
| IVF_PQ | 量化-based | 高查询速度,牺牲一定精度 |
| HNSW | 图-based | 高搜索效率需求 |
| HNSW_SQ | 量化-based | 有限内存,次优精度 |
| SCANN | 量化-based | 高速度、高召回,大内存 |
| BIN_FLAT | 量化-based | 二进制数据,小数据集,精确搜索 |
| SPARSE_INVERTED_INDEX | 倒排索引 | 稀疏向量,文本搜索 |
相似性度量包括欧几里得距离(L2)、内积(IP)等,适用于浮点嵌入向量;对于二进制嵌入向量,支持汉明距离、Jaccard 距离等,特别适用于分子相似性搜索。
Milvus 还支持数据分区、分片、数据持久化、增量数据摄取、标量向量混合查询和时间旅行等高级功能。这些特性增强了其在生产环境中的灵活性和可靠性。
3. 向量数据库的概念与用例
向量数据库是一种专门用于存储和检索高维向量的数据库,优化了向量相似性搜索。它们通过近似最近邻(ANN)算法高效地找到与查询向量最相似的向量。这种能力在处理非结构化数据时尤为重要,因为非结构化数据(如电子邮件、照片、蛋白质结构)可以通过嵌入技术转换为向量,从而进行相似性分析。
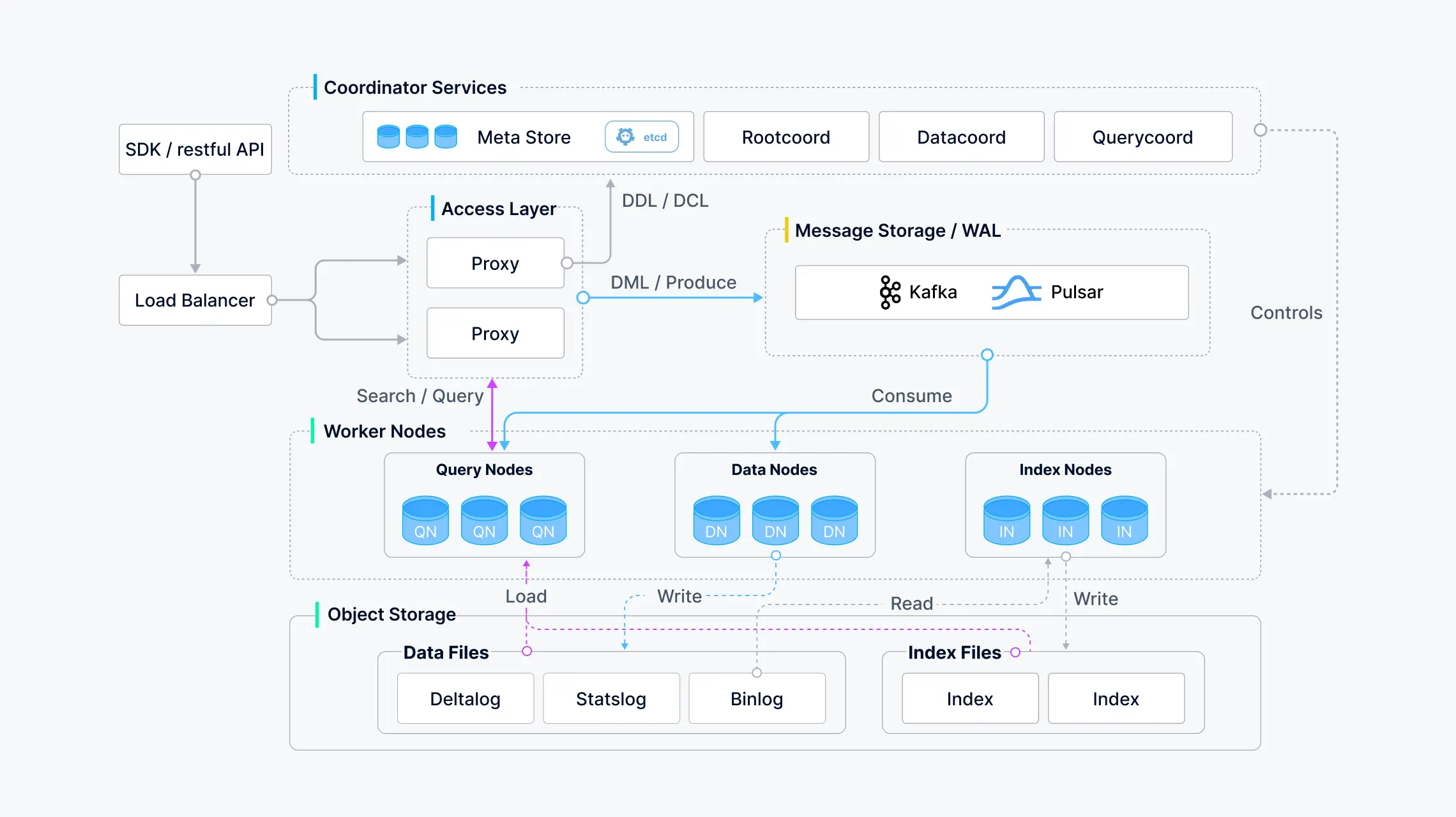 Milvus 架构图
Milvus 架构图
向量数据库结合了传统数据库的能力和独立向量索引的专门化,特别适合 AI 应用。Milvus 的典型应用场景包括:
这些场景展示了 Milvus 在 AI 应用中的广泛适用性,尤其是在检索增强生成(RAG)、语义搜索和混合搜索中。
4. Milvus 的架构与底层原理
Milvus 采用共享存储架构,分离存储和计算,确保计算节点具有水平扩展能力,其四层架构如下:
| 层级 | 功能描述 |
|---|---|
| 接入层 | 由无状态代理组成,验证客户端请求,减少返回结果,使用负载均衡(如 Nginx、Kubernetes Ingress)。 |
| 协调服务 | 管理任务分配、集群拓扑、负载均衡、时间戳生成,包括 Root Coordinator、Query Coordinator、Data Coordinator。 |
| 工作节点 | 执行 DML 命令,无状态,可在 Kubernetes 上扩展,包括查询节点、数据节点和索引节点。 |
| 存储 | 负责数据持久化,包括元数据存储(etcd)、日志代理(Pulsar/RocksDB)、对象存储(MinIO、S3)。 |
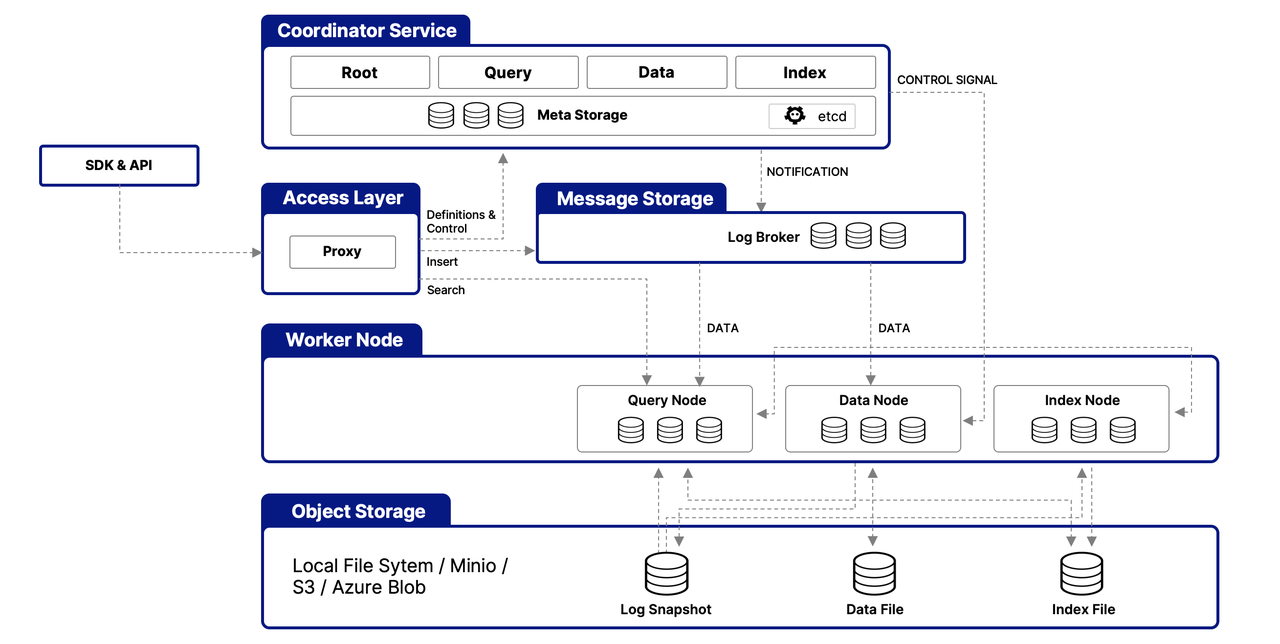 多层架构设计
多层架构设计
4.1 数据处理流程
Milvus 的数据处理包括:
- 数据插入:通过代理路由请求到分片,使用时间戳确保顺序,写入日志序列。
- 索引构建:在索引节点上构建,支持 SIMD 加速,未来计划支持异构计算。
- 数据查询:查询节点执行搜索,支持并发,分为增长段和密封段。
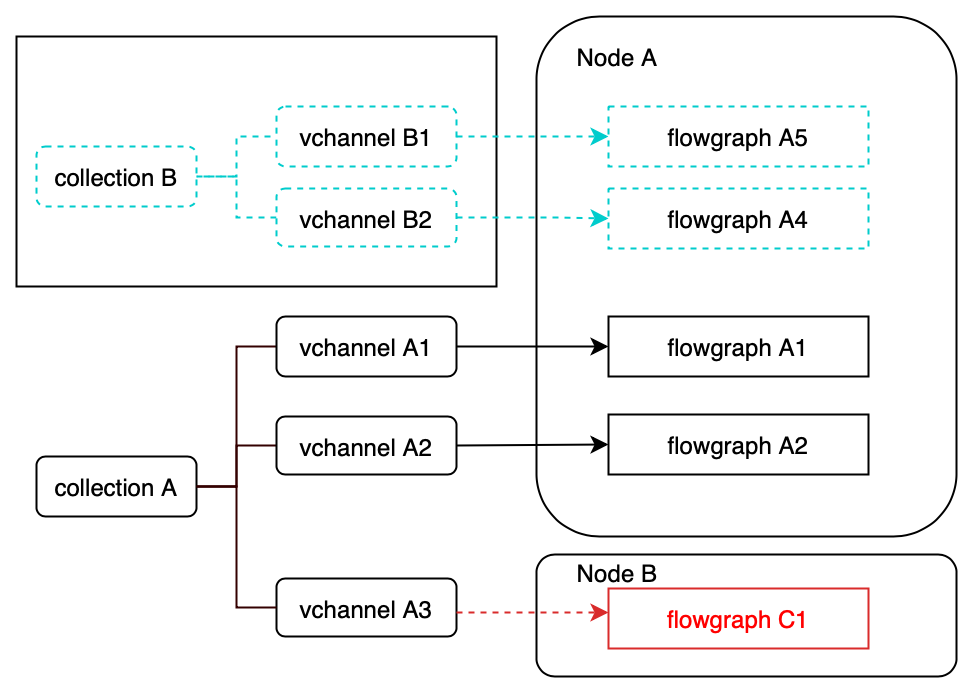 写入路径中的流程图
写入路径中的流程图
4.2 索引机制
Milvus 支持多种索引类型,每种索引有特定的参数和适用场景。例如,HNSW 索引适合高搜索效率,IVF_FLAT 适合平衡精度和速度。参数包括 nlist、M、efConstruction 等,详情见https://milvus.io/docs/index.md。
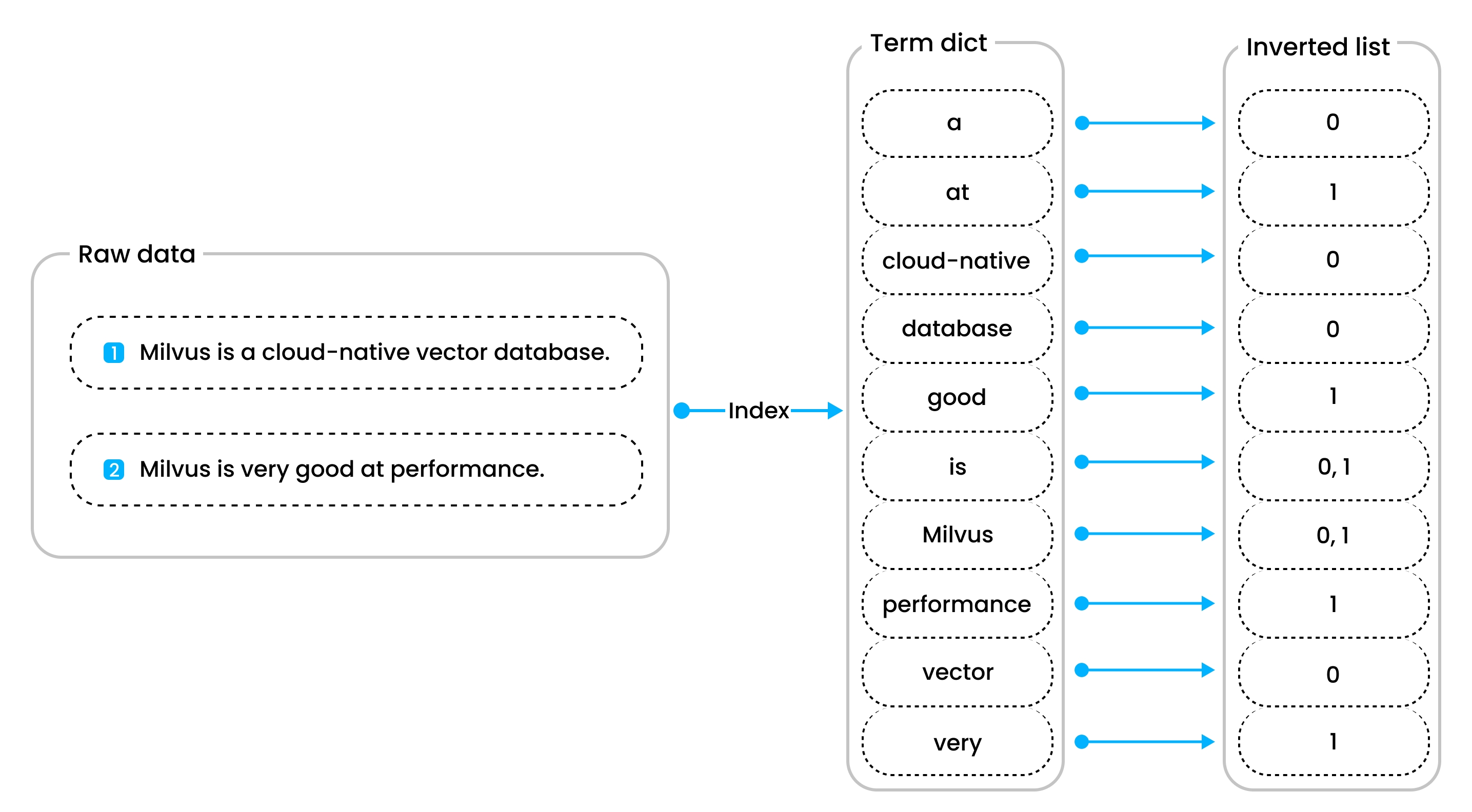 倒排索引图
倒排索引图 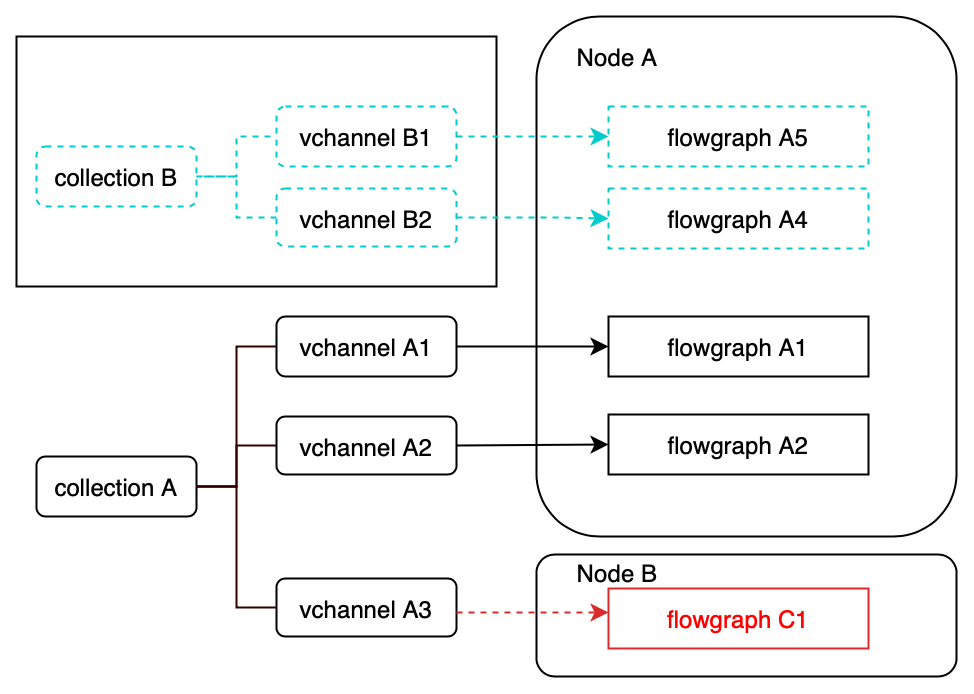 读取路径中的流程图
读取路径中的流程图
5.Milvus 的高性能
5.1 设计理念和架构优化
Milvus 的高性能主要源于其独特的设计理念和架构优化:
- 云原生架构与计算存储分离:Milvus 采用云原生设计,将计算和存储分离,所有组件无状态,避免了资源竞争,提升了大规模数据处理能力。
- 优化的向量索引算法:Milvus 支持多种高效的向量索引(如 HNSW、IVF_FLAT、SCANN),基于近似最近邻(ANN)算法,能在速度与精度间找到平衡,适合亿级甚至万亿级向量搜索。
- 数据分区与并行处理:通过数据分区和分片,Milvus 将大数据集划分为小块,并行执行查询,显著降低延迟。
- 高效查询处理:Milvus 针对向量搜索优化了查询机制,配备独立工作节点支持高并发,提升查询效率。
- 硬件加速与扩展性:Milvus 充分利用现代硬件(如 GPU 加速)和分布式系统,通过 Kubernetes 等实现弹性扩展。
总的来说,Milvus 的高性能得益于其云原生架构、先进的索引技术、分布式设计以及硬件优化,能够为现代 AI 应用提供低延迟和高吞吐量的支持。
5.2 性能测试
下图是在 sift50m 数据集和 IVF_SQ8 索引上运行的测试结果,其中比较了不同nlist/nprobe 对的召回率和查询性能。
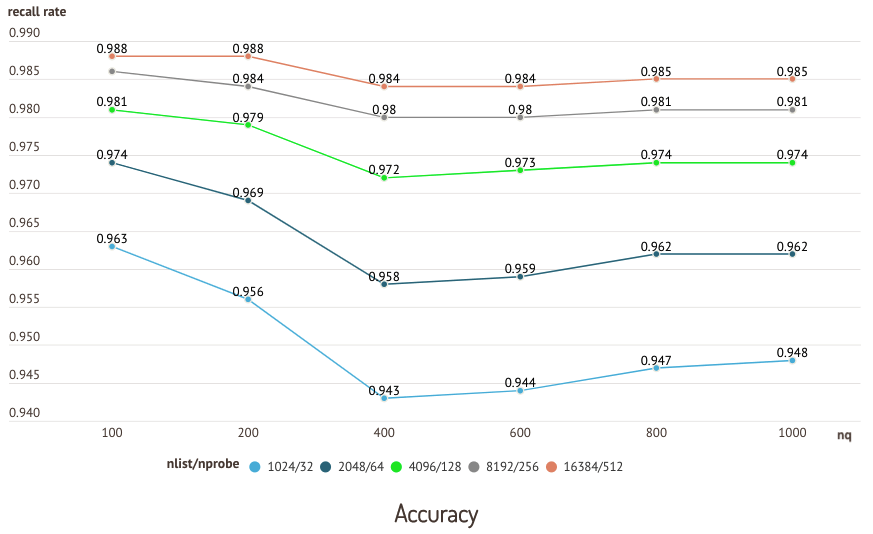 准确性测试
准确性测试 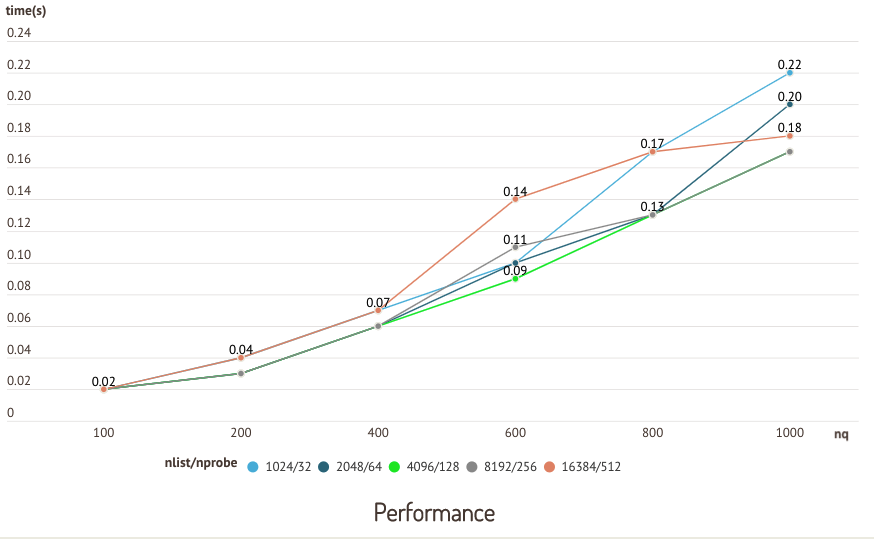 性能测试
性能测试
6. Semantic Kernel Vector Connectors 对 Milvus 的支持
6.1 向量连接器
Semantic Kernel Vector Connectors(简称"向量连接器")是 Semantic Kernel 框架中的一类工具,专门设计用于将 Semantic Kernel 和向量数据库进行连接和管理。向量数据库是一种存储高维向量数据的系统,这些向量通常是文本、图像等数据的嵌入(embeddings),用于表示数据的语义特征。向量连接器作为桥梁,让 Semantic Kernel 可以高效地存取这些向量数据,支持复杂的 AI 功能。
目前,Semantic Kernel 支持多种向量连接器,例如针对 Azure AI Search、Chroma、Milvus 和 Elasticsearch 等数据库的连接器,每种连接器都针对特定数据库优化,确保高效的数据操作。
6.2 主要功能
向量连接器为开发者提供了以下关键功能:
6.2.1 数据存储与管理
向量连接器允许将嵌入向量存储到向量数据库中,并支持插入、更新和删除操作。这些嵌入向量可以代表文本、图像等多种数据类型,帮助开发者轻松管理数据。
6.2.2 高效检索
向量连接器支持快速的向量检索,例如通过近似最近邻(ANN)搜索,找到与查询向量最相似的向量。这一功能在语义搜索和推荐系统中尤为重要。
6.2.3 统一抽象
向量连接器提供了一个统一的接口,隐藏了底层向量数据库的复杂性。开发者无需掌握每种数据库的具体实现细节即可使用,大大简化了开发过程。
6.3 典型应用场景
向量连接器在以下场景中表现出色:
6.3.1 语义搜索
在知识库或文档管理系统中,向量连接器可实现智能语义搜索。用户输入自然语言查询(如"查找关于预算的文档"),系统通过向量相似性返回相关结果。
6.3.2 推荐系统
在电商或内容平台中,向量连接器可存储用户和物品的嵌入向量,通过计算相似度为用户推荐相关产品或内容。
6.3.3 知识图谱
向量连接器可用于存储知识图谱中的实体嵌入向量,支持语义查询和推理,助力构建智能知识系统。
6.3 代码演示
❝
Microsoft.SemanticKernel.Connectors.Milvus 实现更强大的 AI 应用开发,但是这个包尚处于Alpha版本,接口随时可能会发生变化,大家现在只需要简单的看一下,等待最终版的发布就行了。以下代码由于该 Microsoft.SemanticKernel.Connectors.Milvus SDK 实现,此处只做Demo使用。
6.3.1 MilvusMemoryStore
MilvusMemoryStore store = new(Host{}, vectorSize: 5, port: {Port}, consistencyLevel: ConsistencyLevel.Strong);6.3.2 创建集合
await this.store.CreateCollectionAsync("collection1");6.3.3 插入数据
this.store.UpsertBatchAsync(CollectionName,
[
new MemoryRecord(
new MemoryRecordMetadata(
isReference: true,
id: "Some id",
description: "Some description",
text: "Some text",
externalSourceName: "Some external resource name",
additionalMetadata: "Some additional metadata"),
new[] { 10f, 11f, 12f, 13f, 14f },
key: "Some key",
timestamp: new DateTimeOffset(2023, 1, 1, 12, 0, 0, TimeSpan.Zero)),
new MemoryRecord(
new MemoryRecordMetadata(
isReference: false,
id: "Some other id",
description: "",
text: "",
externalSourceName: "",
additionalMetadata: ""),
new[] { 20f, 21f, 22f, 23f, 24f },
key: null,
timestamp: null),
]);6.3.4 数据搜索
List<(MemoryRecord Record, double SimilarityScore)> results =
this.Store.GetNearestMatchesAsync(CollectionName, new[] { 5f, 6f, 7f, 8f, 9f }, limit: 2, withEmbeddings: withEmbeddings).ToEnumerable().ToList();
Assert.True(result.Value.SimilarityScore > 0);
MemoryRecord record = result.Value.Record;
Assert.Equal("Some other id", record.Metadata.Id);
Assert.Equal(
withEmbeddings ? [20f, 21f, 22f, 23f, 24f] : [],
record.Embedding.ToArray());7. 官方 SDK 安装与使用
❝
此处只做简要演示,具体请看:https://www.cnblogs.com/code-daily/p/18761132
首先,通过 NuGet 安装 Milvus.Client 包。安装命令如下:
dotnet add package Milvus.Client安装完成后,可以通过以下步骤开始操作:
7.1 连接到 Milvus 服务器
使用 MilvusClient 类创建客户端实例。例如:
var milvusClient = new MilvusClient("localhost", username: "username", password: "password");请确保替换 "localhost" 为实际的 Milvus 服务主机地址。
7.2 创建集合:
定义集合的 schema,包括字段类型和维度。例如,创建一个图书搜索的集合:
string collectionName = "book";
MilvusCollection collection = milvusClient.GetCollection(collectionName);
//Check if this collection exists
var hasCollection = await milvusClient.HasCollectionAsync(collectionName);
if(hasCollection){
await collection.DropAsync();
Console.WriteLine("Drop collection {0}",collectionName);
}
await milvusClient.CreateCollectionAsync(
collectionName,
new[] {
FieldSchema.Create<long>("book_id", isPrimaryKey:true),
FieldSchema.Create<long>("word_count"),
FieldSchema.CreateVarchar("book_name", 256),
FieldSchema.CreateFloatVector("book_intro", 2L)
}
);7.3 插入数据
Random ran = new ();
List<long> bookIds = new ();
List<long> wordCounts = new ();
List<ReadOnlyMemory<float>> bookIntros = new ();
List<string> bookNames = new ();
for (long i = 0L; i < 2000; ++i)
{
bookIds.Add(i);
wordCounts.Add(i + 10000);
bookNames.Add($"Book Name {i}");
float[] vector = new float[2];
for (int k = 0; k < 2; ++k)
{
vector[k] = ran.Next();
}
bookIntros.Add(vector);
}
MilvusCollection collection = milvusClient.GetCollection(collectionName);
MutationResult result = await collection.InsertAsync(
new FieldData[]
{
FieldData.Create("book_id", bookIds),
FieldData.Create("word_count", wordCounts),
FieldData.Create("book_name", bookNames),
FieldData.CreateFloatVector("book_intro", bookIntros),
});
// Check result
Console.WriteLine("Insert count:{0},", result.InsertCount);7.4 创建索引
为向量字段创建索引以加速搜索。例如:
MilvusCollection collection = milvusClient.GetCollection(collectionName);
await collection.CreateIndexAsync(
"book_intro",
//MilvusIndexType.IVF_FLAT,//Use MilvusIndexType.IVF_FLAT.
IndexType.AutoIndex,//Use MilvusIndexType.AUTOINDEX when you are using zilliz cloud.
SimilarityMetricType.L2);
// Check index status
IList<MilvusIndexInfo> indexInfos = await collection.DescribeIndexAsync("book_intro");
foreach(var info in indexInfos){
Console.WriteLine("FieldName:{0}, IndexName:{1}, IndexId:{2}", info.FieldName , info.IndexName,info.IndexId);
}
// Then load it
await collection.LoadAsync();
}7.5 加载集合并执行搜索
加载集合后,可以执行向量搜索。例如,搜索与查询向量 0.12217915, -0.034832448 最相似的三部电影:
List<string> search_output_fields = new() { "book_id" };
List<List<float>> search_vectors = new() { new() { 0.1f, 0.2f } };
SearchResults searchResult = await collection.SearchAsync(
"book_intro",
new ReadOnlyMemory<float>[] { new[] { 0.1f, 0.2f } },
SimilarityMetricType.L2,
limit: 2);
// Query
string expr = "book_id in [2,4,6,8]";
QueryParameters queryParameters = new ();
queryParameters.OutputFields.Add("book_id");
queryParameters.OutputFields.Add("word_count");
IReadOnlyList<FieldData> queryResult = await collection.QueryAsync(
expr,
queryParameters);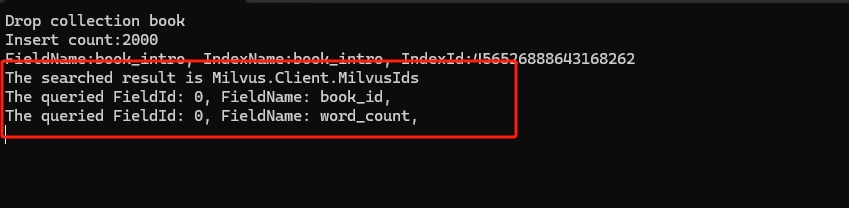
这些操作展示了 Milvus 在 .NET 环境下的基本使用方法,开发者可以根据实际需求调整参数和数据。
8. 结语
Milvus 是一个功能强大的向量数据库,特别适合需要高效向量相似性搜索的 AI 和 ML 应用。在 .NET 环境中,通过 Milvus C# SDK 或者 Semantic Milvus Connector,开发者可以轻松实现数据存储、索引和检索等操作。建议读者参考官方文档和社区资源进一步探索,例如 Milvus 官方文档 和 Milvus C# SDK GitHub。
9.引用
- Milvus 官方文档概述:https://milvus.io/docs/overview.md
- Milvus C# SDK GitHub 仓库:https://github.com/milvus-io/milvus-sdk-csharp)
- Milvus 连接器 NuGet 包:https://www.nuget.org/packages/Microsoft.SemanticKernel.Connectors.Milvus)
- MilvusMemoryStoreTests:https://github.com/microsoft/semantic-kernel/blob/main/dotnet/src/IntegrationTests/Connectors/Memory/Milvus/MilvusMemoryStoreTests.cs