
实现消息持久化
之前将Exchange,MSGQueue,Binding这三个类都存储在了数据库上
但是我们的Message这个消息不适合存储在数据库上面的,为什么呢?
- Message消息是不涉及到很复杂的增删改查的,所以一般不会使用到数据库上的很多功能
- Message消息的数量可能会非常多,数据库的访问效率并不高
所以Message消息不适合用数据库存储,就把这个Message类存储在文件中,在RabbitMQ上面也是这样做的
消息如何具体如何在文件中存储?
收到消息之后,这些消息都会被交换机给投递到具体的队列中去,
所以消息是依附于队列的,因此存储消息的时候,就把消息按照队列的维度展开,
此处已经有了一个data目录,(meta.db文件就在这个data目录中),
在data目录中去创建一些子目录,每个队列都有一个子目录,子目录的名字就是队列名,
把消息就存储在对应的队列目录中去:

queue_data.txt
而且,对于第一个文件:queue_data.txt文件,这个文件是一个二进制格式的文件,里面存储的是二进制的数据:
在这个二进制文件中具体是如何进行存储的?
在这个文件中做出如下约定:
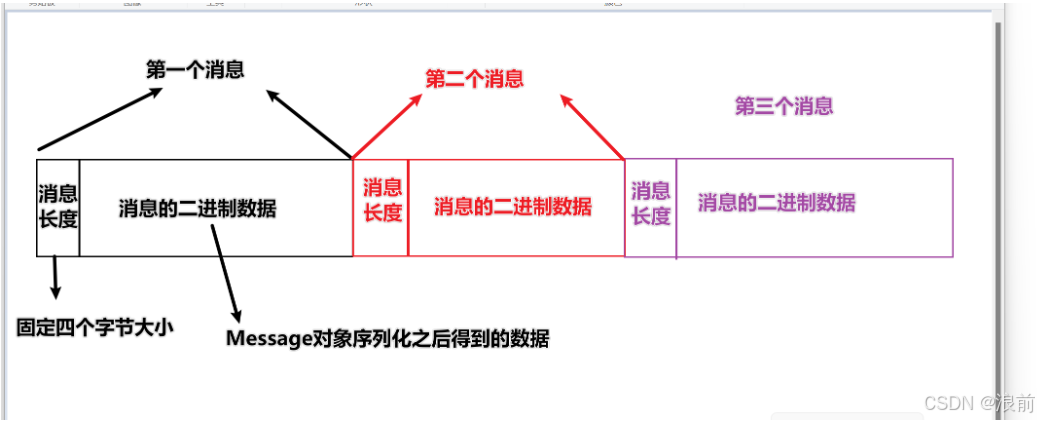
这个二进制文件中包含若干个消息,每个消息都是以二进制的方式存储的,
同时每个消息都是由两个部分组成:
- 消息长度(固定四个字节大小)
- 消息的二进制数据(对象序列化之后得到的数据)
如图所示:
我们进一步分析,这个消息的二进制数据里面又包含哪些东西呢?
如图所示:
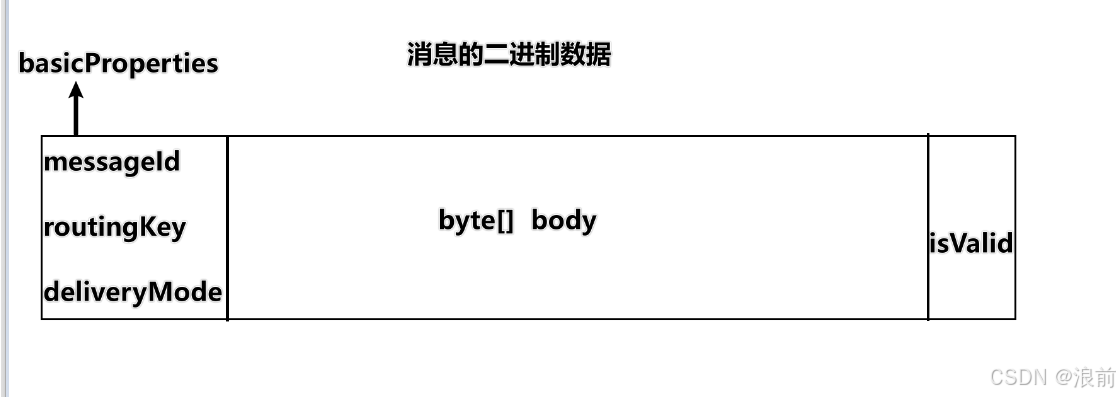
最后面的那个属性:isValid这个属性是用来标识当前这个消息在文件中是否有效的,那么这个属性的作用是什么呢?

但是随着时间的推移,这个消息文件会越来越大,而且无效消息也会越来越多,此时就需要针对当前数据文件,进行垃圾回收,
总结:
先固定四个字节,去描述整个消息的长度,然后根据消息长度,在这四个字节的后面填上消息的二进制数据。
我们后续在去进行序列化存储和反序列化解析的时候,就是按照上述的格式去展开的
而我们之前在Message对象中定义的offsetBeg和offsetEnd的使用方法如下所示:

如何实现垃圾回收的算法
使用复制算法,针对消息数据文件中的垃圾进行回收
复制算法实现方式:
直接遍历原有的消息数据文件,把所有的有效数据都拷贝到一个新的文件中,再把之前的整个旧的文件都删除掉即可。
但是复制算法适用的前提是:
在当前的空间中,有效的数据不多,大部分都是无效数据的时候,适合使用这个复制算法,
那么这个复制算法什么时候才触发一次呢,什么时候我们知道当前文件有效数据不多,垃圾很多呢
此处做出的约定是:
当总的消息数目超过2000个的时候,并且有效消息的数目低于总消息数据的50%,就触发一次垃圾回收
为什么总数目是2000个,为了避免垃圾回收太频繁,比如总的只有4个消息,两个消息是无效的,此时就触发垃圾回收...
上述的2000和50%是我随便设置的,我觉得这样很合理,那我就这样设置了,你也可以自己去自行设计垃圾回收触发的时机,可以自己根据实际的场景去灵活设置
queue_stat.txt
既然我们约定了这个策略,设置了总消息数目和有效消息数量这两个信息,那么这两个信息我们从哪里去获取到呢?
就是从刚刚的第二个文件:使用queue_stat.txt文件中去获取到总消息数目+有效消息数目
这个文件就是专门用来保存消息的统计信息的,这个文件中只存一行数据,而且是文本格式的数据
这一行数据有两列,第一列是queue_data.txt中总的消息数目,第二列是queue_data.txt中有效消息的数目
两者使用/t来分隔:
2000 /t 500
一共有2000个总消息数目,有效消息数目是500个
文件的拆分与合并
如果某个队列中,消息特别特别多,而且都是有效消息,
此时就会导致整个消息的数据文件特别大,后续针对这个文件的各种操作,成本就很高
如果这个文件的大小是10GB,此时如果触发了一次垃圾回收,整体的GC耗时就会很长
对于RabbitMQ来说,解决方案就是把一个大的文件,拆成多个小的文件,这个就是文件拆分
文件拆分:当单个文件长度达到一定阈值之后,就会拆分成两个文件,如果还是很大,那就一直拆下去
文件合并:每个单独的文件都会进行GC,如果GC之后,文件变小了很多,就可能会和相邻的其他文件合并为一个文件
通过上述的拆分合并,可以保证性能上可以即时响应
这一块的逻辑还是比较复杂的,我们的项目目前就不去实现了,我们只考虑单个文件的情况,如果HR问到了这个问题,就可以给出这个解决方案。
如果真的要实现,大致的思路如下所示:
需要专门的数据结构,去存储当前队列中有多少个数据文件,每个文件的大小是多少,消息数目是多少,无效消息数目是多少,
同时设计好策略,什么时候触发文件的拆分,什么时候触发文件的合并

创建MessageFileManager类
创建一个类叫做MessageFileManager针对硬盘上面的消息进行管理,
也就是针对文件进行管理,也就是针对存储消息的内容进行管理
而刚刚的DataBaseManager类是针对数据库操作进行管理的
后续我们需要在代码中操作这几个文件,那就直接操作下面的方法即可:就不必通过硬编码的方式去获取消息文件的路径了:
java
//这个方法:用来获取到指定队列对应的消息文件所在的路径:
private String getQueueDir(String queueName){
return "./data/" + queueName;
}
//这个方法用来获取该队列的消息数据文件路径:
private String getQueueDataPath(String queueName){
return getQueueDir(queueName) + "/queue_data.txt";
}
//这个方法用来获取到该队列的消息统计文件路径:
private String getQueueStatPath(String queueName){
return getQueueDir(queueName) + "/queue_stat.txt";
}同时定义一个内部类表示统计信息:
java
//定义一个内部类来表示该队列的统计信息:
static public class Stat{
public int totalCount; //总消息数量
public int validCount; //有效消息数量
}实现消息统计文件读写
统计文件的读写比较简单,消息数据文件的读写比较复杂,我们柿子先挑软的捏
第一个方法:读统计文件的方法:
这个方法大体步骤如下所示:
- 创建一个新的内部类Stat来存放读取的统计信息
- 使用Scanner来进行读取操作
- 使用nextInt方法先读取总的消息数量,然后读取有效消息数量
- 把读取到的总消息数量和有效消息数量放到新的Stat中
- 最后返回这个新的Stat
因为统计文件是第一个文本文件,我们直接使用Scanner来读取即可:
java
//使用这个方法来读统计文件:
private Stat readStat(String queueName) throws FileNotFoundException {
Stat stat1 = new Stat();
InputStream inputStream = new FileInputStream(getQueueStatPath(queueName));
Scanner scanner = new Scanner(inputStream);
//第一个整数是总的消息数量
stat1.totalCount = scanner.nextInt();
//第二个整数是有效消息数量:
stat1.validCount = scanner.nextInt();
return stat1;
}第二个方法:创建一个写统计文件的方法:
这个方法的大体步骤如下所示:
- 使用OutputStream来操作
- 使用PrintWriter来写入Stat的内容
- 最后刷新缓冲区
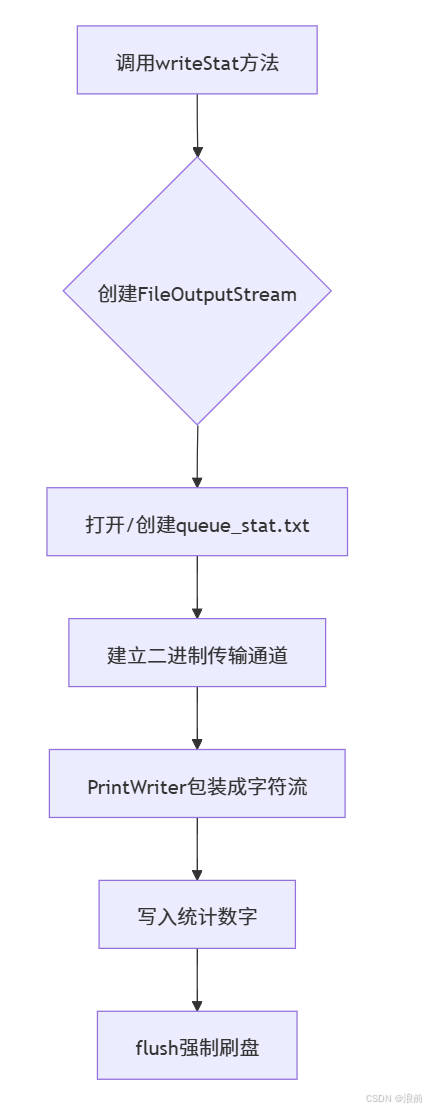
代码如下所示:
java
//这个方法用来写统计文件:
private void writeStat(String queueName, Stat stat) throws FileNotFoundException {
//使用PrintWrite来写文件:
OutputStream outputStream = new FileOutputStream(getQueueStatPath(queueName));
PrintWriter printWriter = new PrintWriter(outputStream);
printWriter.write(stat.totalCount + "/t" + stat.validCount);
//保证数据从缓冲区刷新到硬盘上去:
printWriter.flush();
}注意:OutputStream 打开文件会默认将源文件都清空,所以使用OutputStream每次去在文件中写入新的值的时候,旧的值都会被清空,新的数据覆盖了旧的数据
创建消息目录和文件:
刚刚文件的读写方法编写完毕,下面来编写文件的创建方法:
这个方法一共分为下面的四个步骤:
- 创建队列对应的消息目录
- 创建队列数据文件
- 创建消息统计文件
- 给消息统计文件设置一个初始值:0或者/t0
1:先创建队列对应的消息目录:
java
//1.先创建队列对应的消息目录
File baseDir = new File(getQueueDir(queueName));
if(!baseDir.exists()){
//不存在,就创建这个目录:
boolean ok = baseDir.mkdirs();
if(!ok){
throw new IOException("创建目录失败!baseDir="+baseDir.getAbsolutePath());
}
}2:创建队列数据文件
java
//2.创建队列数据文件:
File queueDataFile = new File(getQueueDataPath(queueName));
if(!queueDataFile.exists()){
boolean ok = queueDataFile.createNewFile();
if(!ok){
throw new IOException("创建队列数据文件失败:queueDataFile="+queueDataFile.getAbsolutePath());
}
}3:创建消息统计文件:
java
//3.创建消息统计文件:
File queueStatFile = new File(getQueueDataPath(queueName));
if(!queueStatFile.exists()){
boolean ok = queueStatFile.createNewFile();
if(!ok){
throw new IOException("创建消息文件失败:queueStatFile="+queueStatFile.getAbsolutePath());
}
}4:给消息统计文件设置一个初始值:0或者/t0
java
Stat stat = new Stat();
stat.totalCount = 0;
stat.validCount = 0;
writeStat(queueName,stat);总结,下面是这个创建消息目录文件的汇总代码:
java
//创建队列对应的文件和目录:
public void createQueueFiles(String queueName) throws IOException {
//1.先创建队列对应的消息目录
File baseDir = new File(getQueueDir(queueName));
if(!baseDir.exists()){
//不存在,就创建这个目录:
boolean ok = baseDir.mkdirs();
if(!ok){
throw new IOException("创建目录失败!baseDir="+baseDir.getAbsolutePath());
}
}
//2.创建队列数据文件:
File queueDataFile = new File(getQueueDataPath(queueName));
if(!queueDataFile.exists()){
boolean ok = queueDataFile.createNewFile();
if(!ok){
throw new IOException("创建队列数据文件失败:queueDataFile="+queueDataFile.getAbsolutePath());
}
}
//3.创建消息统计文件:
File queueStatFile = new File(getQueueDataPath(queueName));
if(!queueStatFile.exists()){
boolean ok = queueStatFile.createNewFile();
if(!ok){
throw new IOException("创建消息文件失败:queueStatFile="+queueStatFile.getAbsolutePath());
}
}
//4.给消息统计文件设置一个初始值:0或者/t0
Stat stat = new Stat();
stat.totalCount = 0;
stat.validCount = 0;
writeStat(queueName,stat);
}删除队列的目录和文件
这个方法的大体逻辑如下所示:
先删除文件,再删除目录
-
删除数据文件
-
删除统计文件
-
删除队列的目录
-
检测是否删除成功了
队列也是可以被删除的,当队列被删除之后,对应的消息文件之类的自然也要被删除的
java
//删除队列的文件和目录:
public void destroyQueueFiles(String queueName) throws IOException{
//先删除文件,再删除目录:
//第一步:删除数据文件:
File queueDataFile = new File(getQueueDataPath(queueName));
boolean ok1 = queueDataFile.delete();
//第二步:删除统计文件:
File queueStatFile = new File(getQueueStatPath(queueName));
boolean ok2 = queueStatFile.delete();
//第三步:删除队列的目录:
File baseDir = new File(getQueueDir(queueName));
boolean ok3 = baseDir.delete();
if(!ok1 || !ok2 || !ok3){
//有任意一个删除失败,抛出异常:
throw new IOException("删除队列和目录失败:baseDir = "+baseDir.getAbsolutePath());
}
}检查队列的目录和文件是否存在:
判定队列的数据文件和统计文件是否都存在:
如果有任何一个不存在,那么就判定这个消息是损坏的消息:
这个方法的使用场景:
后续生产者给brokerServer生产消息了,那么这个消息就可能需要被记录在文件上,取决于消息是否要持久化,
java
//检查队列的目录和文件是否存在:
public boolean checkFilesExits(String queueName){
//判定队列的数据文件和统计文件是否都存在:
File queueDataFile = new File(getQueueDataPath(queueName));
if(!queueDataFile.exists()){
//数据文件不存在
return false;
}
File queueStatFile = new File(getQueueStatPath(queueName));
if(!queueStatFile.exists()){
//统计文件不存在:
return false;
}
return true;
}