1.1Requests 类库的认知
1.1.1 认识请求类库
Requests是用Python语言编写,基于,采用Apache2 Licensed开源协议的。它比urllib更加方便,可以节约我们大量的工作,完全满足HTTP测试需求。urllibHTTP库
Requests官网地址:http://www.python-requests.org/en/master/
1.1.2 Requestsk 类库的运行原理
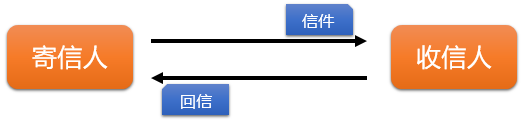
现实生活中的请求
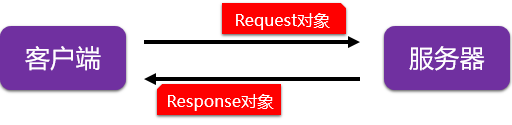
Requests 运行原理
1.1.3 Requests 类库的安装
如果需要使用requests库需要相关第三方模块用pip进行安装。
打开终端:
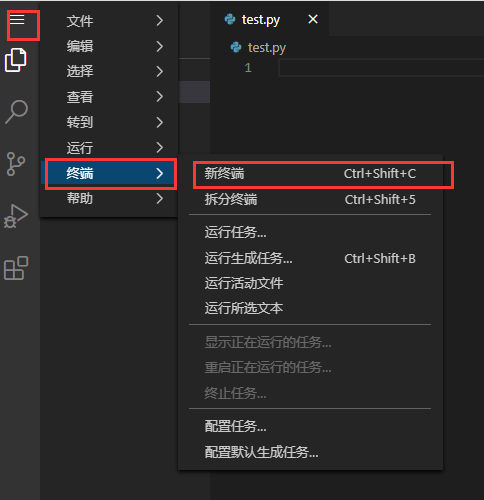
输入:pip3 install requests

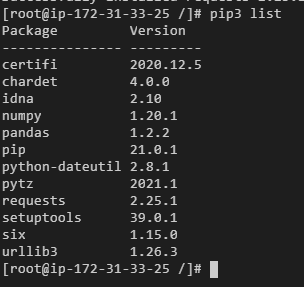
1.1.4 查看 Requests 类库是否安装
pip3 list
1.1.5 Requests 类库的测试
可以在目录下创建一个文件pycodepython
终端输入:
touch /home/ec2-user/pycode/test.py
之后点击,就可以在里面编辑我们的练习代码了。test.py
如何在本编辑器上运行 '.py 文件
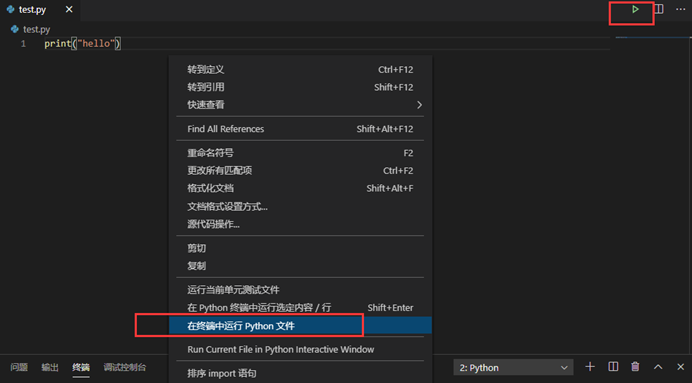
右键单击 - 在终端中运行Python文件 来运行
或者
点击右上角三角形运行
测试使用requests获取百度首页HTTP请求的返回状态。
200表示连接成功,
404表示失败和HTTP响应内容的字符串形式。
import requests
ret = requests.get('http://www.baidu.com')
print(ret.status_code)
print(ret.text)
输出结果:
200
<!DOCTYPE html>
<!--STATUS OK--><html lang="cn" >...</html>
1.2Requests类库的介绍
1.2.1 Requests类库的主要方法
| 方法 | 说明 |
|---|---|
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head() | 获取HTML网页头信息的方法,对应于HTTP的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() | 向HTML网页提交局部修改请求,对应于HTTP的PATCH |
| requests.delete() | 向HTML页面提交删除请求,对应于HTTP的DELETE |
| requests.request() | 构造一个请求,支撑上列各方法的基础方法 |
1.2.2 Requests类库的对象分析
这里我们为例,它是获取HTML网页的主要方法,对应于HTTP的GET。requests.get()
import requests
ret = requests.get('http://httpbin.org')
requests.get(url, params=None, **kwargs)
语法解析:
- get():构造一个向服务器请求资源的对象。Request
- ret变量:得到返回一个包含服务器资源的对象。Response
- url: 拟获取页面的url链接;
- params: url中的额外参数,字典或字节流格式,可选;
- **kwargs: 12个控制访问的参数。
1.2.3 Response对象的相关属性
Response对象包含爬虫返回的内容。
| 属性 | 说明 |
|---|---|
| status_code | HTTP请求的返回状态,200表示连接成功,404表示失败 |
| text | HTTP响应内容的字符串形式,即,url对应的页面内容 |
| content | HTTP响应内容的二进制形式 |
import requests
ret = requests.get('http://httpbin.org')
print("请求返回的状态值为 ", ret.status_code)
print("响应内容字符串为 ", ret.text)
print("响应内容的二进制形式为 ", ret.content)
print("头部信息集合为 ", ret.headers)
输出结果:
请求返回的状态值为 200
响应内容字符串为 <!DOCTYPE html>
<html>
···
</html>
响应内容的二进制形式为 b'<!DOCTYPE html>\n<html>\n...</html>'
头部信息集合为 {'Connection': 'keep-alive', 'Server': 'meinheld/0.6.1', ...}
1.2.4 理解响应对象的编码
| 属性 | 说明 |
|---|---|
| encoding | 从HTTP header中猜测的响应内容编码方式 |
| apparent_encoding | 从内容中分析出的响应内容编码方式(备选编码方式) |
- ret.encoding:如果header中不存在charset,则认为编码为ISO‐8859‐1;
- ret.text根据r.encoding显示网页内容;
- ret.apparent_encoding:根据网页内容分析出的编码方式可以看作是ret.encoding的备选。
import requests
ret = requests.get('http://httpbin.org/')
print("猜测的响应内容编码方式为 ", ret.encoding)
print("分析出的响应内容编码方式为 ", ret.apparent_encoding)
输出结果:
猜测的响应内容编码方式为 utf-8
分析出的响应内容编码方式为 Windows-1252
1.3网页爬取的通用代码框架
1.3.1 Requests类库的异常情况
在发送http请求时,由于各种原因,requests可能会请求失败而抛出异常。网络连接有风险,异常处理很重要

1.3.2 Requests类库的常见异常
| 异常 | 说明 |
|---|---|
| requests.ConnectionError | 网络连接错误异常,如DNS查询失败、拒绝连接等 |
| requests.HTTPError | HTTP错误异常 |
| requests.URLRequired | URL缺失异常 |
| requests.TooManyRedirects | 超过最大重定向次数,产生重定向异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求URL超时,产生超时异常 |
1.3.3 失败请求(非200响应)抛出异常处理
ret.raise_for_status()方法:主要处理如果不是200,产生异常。requests.HTTPError
import requests
ret = requests.get('http://httpbin.org/')
ret.raise_for_status()
ret.raise_for_status()在方法内部判断
ret.status_code是否等于200,不需要增加额外的if语句,该语句便于利用try‐except进行异常处理。
raise_for_status()能够判断返回的Response类型状态是不是200。如果是200,他将表示返回的内容是正确的,如果不是200,他就会产生一个HttpError的异常
1.3.4 通过代码框架的运用
import requests
def getHTMLText(url):
try:
ret = requests.get(url, timeout=30)
ret.raise_for_status()
ret.encoding = ret.apparent_encoding
return ret.text
except:
return "产生异常"
print(getHTMLText("http://www.baidu.com"))
print(getHTMLText("www.baidu.com"))
输出结果:
<!DOCTYPE html>
<!--STATUS OK--><html>...
</html>
产生异常
1.4HTTP 协议与 Requests 类库的方法
1.4.1 理解什么是 HTTP 协议
- HTTP,超文本传输协议,超文本传输协议;
- HTTP是一个基于"请求与响应"模式的、无状态的应用层协议;
- HTTP协议采用URL作为定位网络资源的标识。
网址格式:http://host:portpath - host: 合法的Internet主机域名或IP地址;
- port: 端口号,缺省端口为80;
- path: 请求资源的路径。
1.4.2 理解网址
HTTP,,超文本传输协议。Hypertext Transfer Protocol
HTTP URL 实例:
http://www.baidu.com
http://180.97.33.107
HTTP URL 的理解
URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源。
1.4.3 HTTP 协议相关方法
| 方法 | 说明 |
|---|---|
| GET | 请求获取URL位置的资源 |
| HEAD | 请求获取URL位置资源的响应消息报告,即获得该资源的头部信息 |
| POST | 请求向URL位置的资源后附加新的数据 |
| PUT | 请求向URL位置存储一个资源,覆盖原URL位置的资源 |
| PATCH | 请求局部更新URL位置的资源,即改变该处资源的部分内容 |
| DELETE | 请求删除URL位置存储的资源 |
1.4.4 HTTP 协议对资源的操作

通过URL和命令管理资源,操作独立无状态,网络通道及服务器成为了黑盒子。
1.4.5 理解 PATCH 和 PUT 的区别
假设URL位置有一组数据UserInfo,包括UserID、UserName等多个字段。
需求:用户修改了UserName,其他不变
- 采用PATCH,仅向URL提交UserName的局部更新请求
- 采用PUT,必须将所有20个字段一并提交到URL,未提交字段被删除
PATCH的最主要好处:节省网络带宽。
1.4.6 HTTP 协议与 Requests 类库对比
| HTTP 协议方法 | Requests 类库方法 | 功能一致性 |
|---|---|---|
| GET | requests.get() | 一致 |
| HEAD | requests.head() | 一致 |
| POST | requests.post() | 一致 |
| PUT | requests.put() | 一致 |
| PATCH | requests.patch() | 一致 |
| DELETE | requests.delete() | 一致 |
head ()方法
import requests
ret = requests.head('http://httpbin.org/get')
print("该资源的头部信息:", ret.headers)
print("url对应的页面内容:", ret.text)
输出结果:
该资源的头部信息: {'Connection': 'keep-alive', 'Server': 'meinheld/0.6.1', ...}
url对应的页面内容:
post ()方法
import requests
payload = {'key1': 'value1', 'key2': 'value2'}
ret = requests.post('http://httpbin.org/post', data=payload)
print(ret.text)
输出结果:
{
"args": {},
"data": "",
"files": {},
"form": {
"key1": "value1",
"key2": "value2"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "23",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.25.1",
"X-Amzn-Trace-Id": "Root=1-60361856-0938f4e929602c3862479df3"
},
"json": null,
"origin": "161.189.98.167",
"url": "http://httpbin.org/post"
}
1.5Requests 类库之 request 方法解析
1.5.1 request 方法的请求方式
语法:requests.request(method, url, **kwargs)
- method: 请求方式,对应get/put/post等7种。
- url: 获取页面的url链接。
- **kwargs: 控制访问的参数,共13个。
方法请求方式如下: - ret = requests.request('GET', url, **kwargs)
- ret = requests.request('HEAD', url, **kwargs)
- ret = requests.request('POST', url, **kwargs)
- ret = requests.request('PUT', url, **kwargs)
- ret = requests.request('PATCH', url, **kwargs)
- ret = requests.request('delete', url, **kwargs)
- ret = requests.request('OPTIONS', url, **kwargs)
1.5.2 request 方法的控制访问的参数
**kwargs: 控制访问的参数,均为可选项。
| 控制访问参数 | 说明 |
|---|---|
| params | 字典或字节序列,作为参数增加到url中 |
| data | 字典、字节序列或文件对象,作为Request的内容 |
| json | JSON格式的数据,作为Request的内容 |
| headers | 字典,HTTP定制头 |
| cookies | 字典或CookieJar,Request中的cookie |
| auth | 元组,支持HTTP认证功能 |
| files | 字典类型,传输文件 |
| timeout | 设定超时时间,秒为单位 |
| proxies | 字典类型,设定访问代理服务器,可以增加登录认证 |
| allow_redirects | True/False,默认为True,重定向开关 |
| stream | True/False,默认为True,获取内容立即下载开关 |
| verify | True/False,默认为True,认证SSL证书开关 |
| cert | 本地SSL证书路径 |
import requests
kv = {'word': 'Requests', 'ie': 'utf-8'}
ret = requests.request('GET', 'http://www.baidu.com/s', params=kv)
print(ret.url)
输出结果:
http://www.baidu.com/s?word=Requests\&ie=utf-8
2.1网络爬虫引发的问题
2.1.1 网络爬虫的尺寸分析
现在常用的网络爬虫按尺寸划分,可以分为三大类。
| 适合范围 | 使用规模 | 爬取速度 | 使用类库 |
|---|---|---|---|
| 爬取网页、玩转网页 | 小规模获取数据量小 | 不敏感 | Requsts 类库 |
| 爬取网站、爬取系列网站 | 中规模获取数据规模较大 | 敏感 | Scrapy类库 |
| 爬取全网 | 大规模全Internet搜索引擎 | 关键 | 定制开发 |
2.1.2 引发的诸多问题
- 性能骚扰
受限于编写水平和目的,网络爬虫将会为Web服务器带来巨大的资源开销。从而对网站运营者来说形成了"骚扰"。 - 法律风险
服务器上的数据有产权归属,网络爬虫获取数据后牟利将带来法律风险。 - 隐私泄露
网络爬虫可能具备突破简单访问控制的能力,获得被保护数据从而泄露个人隐私。
2.1.3 网络爬虫的限制
- 来源审查
判断User-Agent进行限制:检查来访HTTP协议头的User‐Agent域,只响应浏览器或友好爬虫的访问 - 发布公告
Robots协议:告知所有爬虫网站的爬取策略,要求爬虫遵守
> 通过这两种方法,互联网中形成了对爬虫在道德和技术的有效限制。
2.2机器人协议
2.2.1 机器人协议的作用
Robots是"机器人"的意思,Robots协议是 网络爬虫排除标准。Robots Exclusion Standard
- 作用:
网站告知网络爬虫哪些页面可以抓取。
- 形式:
在网站根目录下的robots.txt文件
2.2.2 京东的机器人协议
京东首页机器人协议地址:京东(JD.COM)-正品低价、品质保障、配送及时、轻松购物!
1) 机器人协议内容
```
User-agent: *
Disallow: /?*
Disallow: /pop/*.html
Disallow: /pinpai/*.html?*
User-agent: EtaoSpider
Disallow: /
User-agent: HuihuiSpider
Disallow: /
User-agent: GwdangSpider
Disallow: /
User-agent: WochachaSpider
Disallow: /
```
2) 机器人协议基本语法:
```
注释,*代表所有,/表示根目录。
User-agent 表示对于网络爬虫来源。
Disallow 表示不允许。
```
2.2.3 拥有和未拥有Robots协议的网站
淘宝网:https://www.taobao.com/robots.txt
唯品会:http://www.vip.com/robots.txt
百度:https://www.baidu.com/robots.txt
腾讯:http://www.qq.com/robots.txt
新浪新闻:http://news.sina.com.cn/robots.txt
2.2.4 Robots协议的遵守方式
2.2.4.1 机器人协议的使用
- 网络爬虫
自动或人工识别robots.txt,再进行内容爬取。
- 约束性
Robots协议是建议但非约束性,网络爬虫可以不遵守,但存在法律风险。
2.2.4.2 Robots协议的遵守建议
| 爬取范围 | 规模及用途 | Robots 协议遵守形式 |
|---|---|---|
| 爬取网页、玩转网页 | 访问量很小 | 可以遵守 |
| 爬取网页、玩转网页 | 访问量较大 | 建议遵守 |
| 爬取网站、爬取系列网站 | 非商业且偶尔爬取 | 建议遵守 |
| 爬取网站、爬取系列网站 | 具有商业利益 | 必须遵守 |
| 爬取全网 | 大规模全Internet搜索引擎 | 必须遵守 |
原则:类人行为可不参考Robots协议
2.3HTML基本概述
2.3.1 HTML网页技术简介
Internet 的意思是互联网,又称网际网路,也被叫做因特网、英特网,是网络与网络之间所串连成的庞大网络,在这个网络中有种类繁多的服务器和数不尽的计算机、终端。互联网并不等同万维网(W3C),万维网只是基于超文本相互链接而成的全球性系统,且是互联网所
能提供的服务其中之一。
在信息技术发达的今天,我们每天都可以感受到 Internet 技术在生活中的巨大作用。通过 Internet,我们可以每天浏览到最新的新闻,可以在电子商城选购自己心爱的物品,可以和世界各地的朋友一起玩游戏等。
网络技术应用中使用最广泛的就是网页技术,而我们要了解的是,网页技术属于一种 B/S架构的技术。
说明:B/S 结构,即 Browser/Server(浏览器/服务器)结构,就是只安装维护一个服务器(Server),而客户端采用浏览器(Browser)运行软件
- HTML是用来;描述网页的一种语言
- HTML指的是();超文本标记语言Hyper Text Markup Language
- HTML不是一种编程语言,而是一种();标记语言markup language
- 标记语言是一套();标记标签markup tag
- HTML使用来描述网页;标记标签
- HTML文件后缀名:或。*.html*.htm
2.3.2 HTML网页的基本组成结构
HTML 文件内容主要包含在和标记内,完整的网页文件应该包括头部和主体两大部分。<html></html>
头部的HTML标记是和,这里主要放置网页文件描述浏览器所需的基本信息。如表示描述浏览器解析的编码方式、HTML基本组成结构表示描述网页头标题显示的内容等。<head></head><meta charset="utf-8" /><title></title>
主体的标记是和包含所要描述的网页具体内容。<body></body>
<!DOCTYPE html > <!-- 文档类型声明 -->
<html> <!-- 文件内容主要包含在 <html> 和 </html> 标记内 -->
<head> <!-- 主要放置网页文件描述浏览器所需的基本信息 -->
<meta charset="UTF-8"> <!-- 当前字符编码的定义 -->
<title>我的网页</title> <!-- 描述网页头标题显示的内容 -->
</head>
<body> <!-- 描述的网页具体内容 -->
Hello World!
</body>
</html>
2.3.2.1 HTML标签语法
1) HTML 标签定义方式
- HTML标签是由包围的关键词,比如。HTML标签大多数是成对出现。尖括号<html>
语法:<开始标签> 具体内容 </结束标签>
<!DOCTYPE html >
<html>
<head>
<meta charset="UTF-8">
<title>标签的定义</title>
</head>
<body>
<p>这是第一个段落标签</p>
<p>这是第二个段落标签</p>
</body>
</html>
- 多数HTML标签中的内容是在开始标签与结束标签之间。某些HTML标签具有空内容,如:。<br />
语法:<标签 />
<!DOCTYPE html >
<html>
<head>
<meta charset="UTF-8">
<title>单标签的定义</title>
</head>
<body>
Hello World!<br/>
Hello China
</body>
</html>
1) HTML 标签属性定义
HTML标签可以设置,属性表示在元素中添加,属性一般描述于。
> 语法:<标签名 属性1="属性1的值" 属性2 = "属性2的值" ...>具体内容</标签名>属性附加信息开始标签
```html
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>标签的属性定义</title>
</head>
<body>
<p algin="center">这是第一个段落标签</p>
<p algin="right" style="color:red;">这是第二个段落标签</p>
</body>
</html>
```
2.4HTML 常用标签
2.4.1 HTML 常用基础标签
| 标签 | 作用 |
|---|---|
| <h1> ~ <h6> | 定义标题 |
| <p> | 定义一个段落 |
| <br /> | 定义一个强制换行 |
| | 定义一个空格符号 |
| <hr /> | 定义分隔线 |
| <!--内容--> | 定义注释,表示内容无法在页面中显示 |
| <blockquote> | 定义段落进行缩进 |
| <pre> | 定义保留文本原来的格式 |
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>常用标签</title>
</head>
<body>
<h1>标题标签H1</h1>
<h2>标题标签H2</h2>
<h3>标题标签H3</h3>
<hr />
<!-- 这是被注释的内容,无法在网页中看到 -->
<pre>
《静夜思》
李白
窗前明月光,
疑是地上霜。
举头望明月,
低头思故乡。
</pre>
</body>
</html>
2.4.2 HTML 图片和超链接标签
1 ) 图片标签 <img />
插入图片的HTML是单标签,通过 src 属性的值确定所插入图片的路径。<img />
语法:<img src="图像URL地址" />
可选参数:
- width:宽度
- height:高度
- title:提示文字
- alt:替代图片的文字
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>图片标签</title>
</head>
<body>
<img src="http://www.th7.cn/d/file/p/2016/04/08/208d59cca1f327556135519768639ef8.jpg" height="200" width="600" title="大数据" alt="这是大数据背景图" />
</body>
</html>
2 ) 超链接标签 <a></a>
超链接是网站中使用比较频繁的HTML标签。超链接的标签是。<a></a>
语法:超链接<a href="链接URL地址"></a>
可选参数:
- target:指定打开链接的的目标窗口
- title:指向链接时所显示的标题文字
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>超链接标签</title>
</head>
<body>
<a href="https://www.baidu.com">百度</a> <!-- 文本超链接 -->
<a href="http://www.taobao.com"><img src="http://static2.jihaoba.com/ueditor/20160628/57722c913cea7.jpg" width="200" height="80"/></a><!-- 图像超链接 -->
</body>
</html>
2.4.3 HTML 列表标签
列表就是在网页中将项目有序或无序地罗列形式显示。在HTML中常用列表分别有有序列表和无序列表。<ol><ul>
语法:
列表开始
<li>列表项1 开始
具体的列表项1 内容
</li>列表项1 结束
<li>列表项2 开始
具体的列表项2 内容
</li>列表项2 结束
......
列表结束
提示:HTML标签是可以嵌套的,所以列表也是可以嵌套的。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>列表标签</title>
</head>
<body>
<h2>有序列表</h2>
<ol>
<li>讲解HTML列表。</li>
<li>演示列表案例。</li>
<li>要求学员做好笔记。</li>
<li>布置练习题。</li>
<li>归纳学员练习时出现的问题。</li>
</ol>
<h2>无序列表</h2>
<ul>
<li>钓鱼岛最新消息:中国鹰击12导弹在世界超音速反舰导弹排行第一? </li>
<li>钓鱼岛最新消息:中国将震撼出手:反击美军预警机入侵钓鱼岛</li>
<li>钓鱼岛最新消息:钓鱼岛事件引发的抵制日货历史思考</li>
<li>钓鱼岛最新消息:中国驻日大使称日本应冷静对待钓鱼岛问题</li>
<li>钓鱼岛最新消息:国家海洋局局长称中国在维护海洋权益上绝不退让</li>
</ul>
</body>
</html>
2.4.4 HTML 表格标签
在HTML中标准的数据表格标签的子元素组成结构包括标题、表头组、表内容组和表尾组。<table>
| 标签 | 作用 |
|---|---|
| <table> | 定义表格 |
| <th> | 定义表格的表头 |
| <tr> | 定义表格的行 |
| <td> | 定义表格单元 |
| <caption> | 定义表格标题 |
| <thead> | 定义表格的页眉 |
| <tbody> | 定义表格的主体 |
| <tfoot> | 定义表格的页脚 |
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>表格标签</title>
</head>
<body>
<table>
<caption>XX学院学生信息表</caption>
<thead>
<th></th>
<th>学号</th>
<th>姓名</th>
<th>性别</th>
<th>家庭地址</th>
</thead>
<tfoot>
<tr>
<th></th>
<td></td>
<td></td>
<td></td>
<td>教务处制</td>
</tr>
</tfoot>
<tbody>
<tr>
<th>(1. )</th>
<td>100001</td>
<td>张三</td>
<td>男</td>
<td>重庆市大龙街道希望小区 3-7-2</td>
</tr>
<tr>
<th>(2. )</th>
<td>100002</td>
<td>李四</td>
<td>男</td>
<td>上海市黄浦区大洋花园 2-26-3</td>
</tr>
<tr>
<th>(3. )</th>
<td>100003</td>
<td>何梅</td>
<td>女</td>
<td>重庆市周同路康名家苑 5-31-1</td>
</tr>
</tbody>
</table>
</body>
</html>
表格中提供了单元格合并功能,分别有水平合并单元格()和垂直合并单元格()。colspanrowspan
2.4.5 HTML 区分标签
<div></div>是网页标记语言中的重要组成元素之一,网页通过可以实现页面的规划和布局。div
其中,可以是页面中任何合法的标签元素和文本。具体内容
div 标签中的常用属性
- id:定义HTML文件范围内的id唯一标识符;
- class:定义HTML文件范围内的class类标识符;
- title:定义元素的标题;
- style:定义HTML内联样式。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>区分标签</title>
<style>
.one{height:100px;
width:500px
background-color:#F00;}
.two{height:200px;
width:700px
background-color:#00F;}
</style>
</head>
<body>
<div class="one"></div>
<div class="two"></div>
</body>
</html>
2.4.6 HTML 无结构组合标签
<span></span>标签用于对文档中的行内元素进行组合,标签没有固定的格式表现。当对它应用时,它才会产生视觉上的变化。<span></span>样式
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>无结构组合标签</title>
</head>
<body>
<span>瀚海睿智大数据</span>
<span style="color:red;font-size:30px;">瀚海睿智大数据</span>
</body>
</html>
2.5 认识 CSS 层叠样式表
2.5.1 CSS 与 HTML 之间的关系
HTML既能显示网页内容,又能控制网页样式。而就是让网页的样式独立出来,以方便批量处理样式变更问题。CSS
CSS(Cascading Style Sheet),通常称之为层叠样式表。
CSS 优点:
- 制作、管理网页非常方便;
- 可以更加精细地控制网页的样式;
- CSS样式丰富多彩;
- CSS样式灵活多样。
2.5.2 CSS 语法构成
在现实应用中,经常用到的元素是、和。CSS规则选择器属性值
语法:
规则选择器 {
属性1:值1;
属性2:值2;
...}
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>区分标签</title>
<style>
.cont{color:#F00;
font-size:30px;}
</style>
</head>
<body>
<p class="cont">这是一个段落标签</p>
</body>
</html>
2.5.3 CSS 常用规则选择器
1 ) id 选择器
<style>
#main{...}
</style>
<body>
<div id="main"></div>
</body>
2 ) 类 选择器
<style>
.main{...}
</style>
<body>
<div class="main"></div>
</body>
3 ) 标签(元素) 选择器
<style>
div{...}
</style>
<body>
<div></div>
</body>
4) 相邻兄弟选择器
<style>
div+p{...}
</style>
<body>
<div></div>
<p></p>
</body>
5) 子元素选择器
<style>
div>p{...}
</style>
<body>
<div><p></p></div>
</body>
6) 后代选择器
<style>
div span{...}
</style>
<body>
<div><p><span></span></p></div>
</body>
7) 分组选择器
<style>
div,p{...}
</style>
<body>
<div></div>
<p></p>
</body>
8) 通配选择器
<style>
*{...}
</style>
<body>
<div></div>
</body>
9) 其他选择器
- 属性选择器
| 选择器 | 示例 | 说明 |
|---|---|---|
| attribute | 目标 | 选择所有带有 target 属性元素 |
| attribute=value | 目标=_blank | 选择所有使用 target="_blank"的元素 |
| attribute\~=value | 标题\~=学校 | 选择标题属性包含单词"school"的所有元素 |
| attribute=language | 朗 | =中日 |
- 伪类选择器
| 选择器 | 示例 | 说明 |
|---|---|---|
| :link | a:链接 | 选择所有未访问链接 |
| :hover | a:悬停 | 选择鼠标在链接上面时 |
| :active | a:活动 | 选择活动链接 |
| :visited | a:访问过 | 选择所有访问过的链接 |
| :focus | 输入:焦点 | 选择具有焦点的输入元素 |
| :first-child | div:第一个孩子 | 指定只有当元素是其父级的第一个子元素<div> |
- 伪元素选择器
| 选择器 | 示例 | 说明 |
|---|---|---|
| :after | div:after | 在每个元素之后插入内容<div> |
| :before | div:之前 | 在每个元素之前插入内容<div> |
| :first-letter | div:首字母 | 选择每一个元素的第一个字母<div> |
| :first-line | div:第一行 | 选择每一个元素的第一行<div> |
2.5.4 CSS 调用方式
通常 CSS 的调用方式基本可以分为 4 种
1) 内联样式表
通过标记的通用属性直接写在需要应用样式的标记中。style
<p style="color:red">显示红色文字</p>
2) 嵌入式样式表
通过标签嵌入在HTML文件的头部。<style></style>
<style type="text/css">
p {color:red;}
</style>
3) 外链接样式表
样式表以外部文件的形式存在,扩展名为。在标记之间使用标签将样式表文件链接到HTML文件中。.css<head></head><link/>
<link type="text/css" rel="stylesheet" href="mycss.css" />
4) 导入式样式表
使用导入外部的样式表文件,它可以写在标签内或外部样式表中。@import<style>
<style type="text/css"> @import url(mycss.css) </style>
2.6设计简单的网页
2.6.1 说明
可以在文件夹中 创建一个 文件。pycodeProductPage.html
终端输入:
cd /home/ec2-user/pycode
touch ProductPage.html
touch ProductPage.css
目录文件就会出现刚才创建的:
注: 如果没有,可以刷新浏览器,再重新打开此目录查看。
2.6.2 代码展示
ProductPage.html 文件代码如下:
<!DOCTYPE HTML >
<html>
<head>
<meta charset="utf-8">
<title>家庭接入终端_腾达(Tenda)官方网站</title>
<link type="text/css" rel="stylesheet" href="./ProductPage.css" />
</head>
<body>
<div id="header">
<div id="logo-nav">
<a href="Home.html"></a>
<ul>
<li><a href="#">家用产品</a></li>
<li><a href="#">商用产品</a></li>
<li><a href="#">产品导购</a></li>
<li><a href="#">服务支持</a></li>
<li><a href="#">官方商城</a></li>
<li><a href="#">以旧换新</a></li>
<li><a href="#">worldwide</a></li>
</ul>
</div>
</div>
<div id="content">
<div class="product-nav">
<div class="nav-cont">
<div class="nav-cont-left">
<a href="#">家用 接入终端</a>
</div>
<div class="nav-cont-right">
<a href="#">ADSL</a>
<a href="#">GPON</a>
<a href="#">EPON</a>
<a href="#">路由猫一体机</a>
</div>
</div>
</div>
<div class="product-items">
<div class="data-items">
<ul>
<li>
<a href="#">
<img src="/image/Python_Crawl/c0_001.png" />
<div class="chanpin">
<h3>HG201-E EPON家庭网关</h3>
<p>IEEE802.3ahEPON标准,超强兼容,最高上/下行速度率可达1.25Gbps</p>
</div>
</a>
</li>
<li>
<a href="#">
<img src="/image/Python_Crawl/c0_002.png" />
<div class="chanpin">
<h3>G103 GPON光纤接入终端</h3>
<p>符合GPON技术标准,超强兼容,上、下行速率可达2.5Gbps,千兆有线端口</p>
</div>
</a>
</li>
<li>
<a href="#">
<img src="/image/Python_Crawl/c0_003.png" />
<div class="chanpin">
<h3>E302 300M无线EPON光纤接入路由猫</h3>
<p>IEEE802.3ahEPON标准,超强兼容,极速光纤上网,最高支持1.25Gbps的接入速率</p>
</div>
</a>
</li>
<li>
<a href="#">
<img src="/image/Python_Crawl/c0_004.png" />
<div class="chanpin">
<h3>D9 即插即用ADSL2+ Modem</h3>
<p>即插即用,6000V超强防雷,最高上/下行速率可达1/24Mbps</p>
</div>
</a>
</li>
<li>
<a href="#">
<img src="/image/Python_Crawl/c0_005.png" />
<div class="chanpin">
<h3>G100 GPON光纤接入终端</h3>
<p>符合GPON规范,千兆以太网口,支持OMCI的远程管理、兼容各级运营商网络环境</p>
</div>
</a>
</li>
<li>
<a href="#">
<img src="/image/Python_Crawl/c0_006.png" />
<div class="chanpin">
<h3>D301 300M ADSL2+无线路由一体机</h3>
<p>支持DSL、LAN两种宽带接入,集300M无线、ADSL2+ Modem、全功能路由、交换机、防火墙</p>
</div>
</a>
</li>
</ul>
</div>
</div>
</div>
<div id="footer">
<div id="footer-top">
<ul>
<li>
<span>服务支持</span>
<p>
<a href="#">下载中心</a>
<a href="#">帮助文档</a>
<a href="#">视频中心</a>
</p>
</li>
<li>
<span>关于腾达</span>
<p>
<a href="#">公司介绍</a>
<a href="#">发展历程</a>
<a href="#">联系方式</a>
</p>
</li>
<li>
<span>工作机会</span>
<p>
<a href="#">社会招聘</a>
<a href="#">校园招聘</a>
</p>
</li>
<li>
<span>腾达商城</span>
<p>
<a href="#">天猫旗舰店</a>
<a href="#">京东旗舰店</a>
<a href="#">苏宁旗舰店</a>
</p>
</li>
<li>
<span>服务支持</span>
<p>
<a href="#">腾达官方微博</a>
<a href="#">腾达官方微信</a>
<a href="#">腾达官方Q群</a>
</p>
</li>
</ul>
<div>
<span>全国服务热线</span>
<h5>400-6622-666</h5>
<p>9:00-12:00 13:30-18:00<br />(仅收市话费)</p>
</div>
</div>
<div id="footer-bottom">
<ul>
<li><a href="#">使用条款</a></li>
<li><a href="#">隐私保护</a></li>
<li><a href="#">联系我们</a></li>
<li><a href="#">新闻中心</a></li>
</ul>
<div>深圳市吉祥腾达科技有限公司 © 1999 - 2016版权所有 粤ICP备05011718号</div>
</div>
</div>
</body>
</html>
ProductPage.css 文件代码如下:
@charset "utf-8";
*{margin:0;
padding:0;
border:0;
font-size:14px;
font-family:"微软雅黑", "黑体", "宋体";}
#header {width:100%;
height:75px;
background-color:#000;}
#footer { width:100%;
height:203px;
background-color:#000;
border-top:5px #ff6600 solid;
padding:60px 0 30px 0;}
#content {width:100%;
background-color:#f0f1f3;}
#logo-nav a :link,
#logo-nav a :visited,
#footer ul li a :link,
#footer ul li a :visited{text-decoration:none;
color:#FFF;}
#logo-nav a :hover,
#logo-nav a :active,
#footer #footer-top ul li a :hover,
#footer #footer-top ul li a :active,
#footer #footer-bottom ul li a :hover,
#footer #footer-bottom ul li a :active{ color:#ff6600;}
.nav-cont a :link,
.nav-cont a :visited,
.data-items a :link,
.data-items a :visited{text-decoration:none;
color:#000;}
#logo-nav {width:1200px;
height:100%;
margin:0 auto;}
#logo-nav >a {width:132px;
height:75px;
display:inline-block;
}
#logo-nav >ul {float:right;
width:830px;
height:75px;}
#logo-nav >ul >li { display:inline-block;
line-height:75px;
height:75px;}
#logo-nav ul li >a { display: inline-block;
font-size: 16px;
height: 75px;}
#logo-nav >ul >li :nth-last-child(3) a :link,
#logo-nav >ul >li :nth-last-child(3) a :visited{color: #ff6600;}
#logo-nav >ul >li :nth-last-child(2) a :link,
#logo-nav >ul >li :nth-last-child(2) a :visited{color:#fff;
font-size:12px;}
#logo-nav >ul >li input type="text"{ width: 83px;
height: 20px;
font-size: 12px;
background-color: #ff6600;
color: #fff;}
#logo-nav >ul >li input type="image" {position:relative;
top:5px;
left:-5px;}
#logo-nav >ul >li +li { margin-left:32px;}
.product-nav{width:100%;
height:60px;
background-color:#FFF;}
.nav-cont{width:1200px;
height:100%;
margin:0 auto;
line-height:60px;}
.nav-cont-left{
width:70%;
display:inline-block;
margin-left:45px;}
.nav-cont-right{width:25%;
display:inline-block;}
.nav-cont-right>a {margin-left:20px;}
.product-items{width:100%;
background-color:#f0f1f3;}
.data-items{ width:1200px;
margin:0 auto;
padding:20px 0 50px 0;}
.data-items ul li {list-style-type:none;
display:inline-block;
width:380px;
margin:0 17px 24px 0;}
.chanpin{background-color:#fff;
margin-top:5px;
padding:20px 0 20px 0;}
.data-items img {width:100%;}
.chanpin h3 {font-size:16px;
font-weight:normal;
width:90%;
margin:0 auto;
color:#000;}
.chanpin p {width:90%;
margin:0 auto;
margin-top:20px;
color:#999;}
#footer >#footer-top ,#footer >#footer-bottom {width:1200px;
margin:0 auto;}
#footer >#footer-top >ul {width:930px;
display:inline-block;}
#footer >#footer-top >ul li {display:inline-block;
width:135px;
margin-right:45px;
vertical-align:top;}
#footer >#footer-top >ul >li >span {font-size:16px;
color:#FFF;}
#footer >#footer-top >ul >li >p {margin-top:30px;
line-height:26px;}
#footer >#footer-top >ul >li a {display:block;
font-size:14px;
color:#ccc;
text-decoration:none;}
#footer >#footer-top >div {position:absolute;
height:129px;
display:inline-block;
padding-left:95px;
border-left:1px #ccc solid;}
#footer >#footer-top >div >span {font-size:16px;
color:#aaa;}
#footer >#footer-top >div >img {position:absolute;
top:-5px;
left:185px;}
#footer >#footer-top >div >h5 {font-size:22px;
color:#eee;
font-weight:normal;
margin-top:5px;}
#footer >#footer-top >div >p {margin-top:10px;
color:#aaa;
line-height:20px;
font-size:14px;}
#footer >#footer-top >div >a {position:absolute;}
#footer >#footer-bottom >ul {width:780px;
display:inline-block;}
#footer >#footer-bottom >ul >li {display:inline-block;
margin:40px 5px 0 0;}
#footer >#footer-bottom >ul >li >a {font-size:12px;}
#footer >#footer-bottom >div {width:415px;
display:inline-block;
font-size:12px;
color:#FFF;}
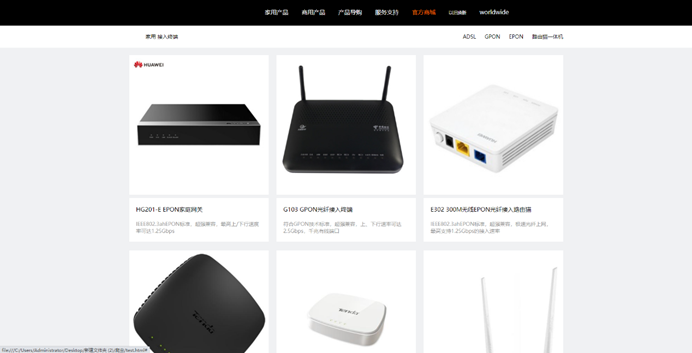
2.6.3效果展示
点击
在浏览器中输入网址:
http://域名:5500/ProductPage.html
效果展示:
3.1Beautiful Soup类库的认知
3.1.1 认识漂亮的汤类库
Beautiful Soup是一个可以从或文件中提取数据的Python库。HTMLXML
美丽汤官网:Beautiful Soup: We called him Tortoise because he taught us.
美丽的汤官网中文文档:Beautiful Soup 4.4.0 文档 --- beautifulsoup 4.4.0q 文档
3.1.2 美丽的汤类库的安装
在Virtualenv虚拟环境中安装Beautiful Soup类库。
安装命令:pip3 install beautifulsoup4

3.1.3 美丽的汤类库的测试
测试HTML页面地址:This is a python demo page
import requests
from bs4 import BeautifulSoup
ret = requests.get("http://python123.io/ws/demo.html")
uhtext = ret.text
soup = BeautifulSoup(uhtext, 'html.parser')
print(soup.prettify())
输出结果:
<html>
<head>
<title>
This is a python demo page
</title>
</head>
<body>
<p class="title">
....
</p>
</body>
</html>
3.1.4 XPath与selector的作用
XPath是一种表达式语言,它的返回值可能是节点,节点集合,原子值,以及节点和原子值的混合等。
selector是当前元素定义的CSS样式,它的返回值可能是id选择器、class选择器、标签(元素)选择器等。
腾达产品网的商品图片为例
获取网页中图像的。Copy XPath
粘贴文本://*@id="content"/div2/div/ul/li1/a/img2
获取网页中图像的。Copy Selector
粘贴文本:#content > div.product-items > div > ul > li:nth-child(1) > a > img:nth-child(2)
3.2Beautiful Soup类库的基本元素
3.2.1 理解Beautiful Soup类库功能原理
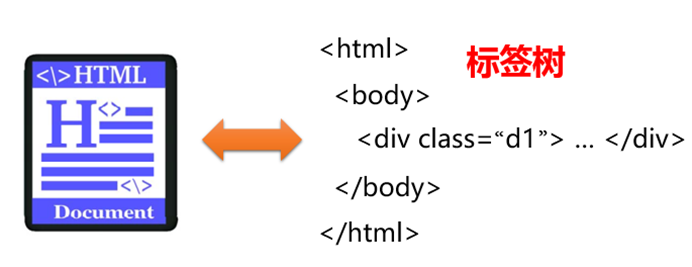
Beautiful Soup类库是、、"标签树"的功能库。解析遍历维护
标签树中有具体标签名称,标签的属性0-N个。
3.2.2 美汤类库的使用
美丽的汤类库,也叫beautifulsoup4或bs4。
1) 美丽的汤类库的引用
from bs4 import BeautifulSoup 或
import bs4

from bs4 import BeautifulSoup
soup1 = BeautifulSoup("<div>测试数据</div>", "html.parser")
soup2 = BeautifulSoup(open("/root/theia/pycode/ProductPage.html", encoding="UTF-8"), 'html.parser')
print(soup1.prettify())
print(soup2.prettify())
注: 文件需要把上一章所写的网页和python文件放到同一目录ProductPage.html
输出结果:
<div>
测试数据
</div>
<!DOCTYPE HTML>
<html>
<head>
<meta charset="utf-8"/>
...
</head>
<body>
...
</body>
</html>
3.2.3 美丽的汤类库解析器
soup = BeautifulSoup('<div>测试数据</div>','html.parser')
html.parser就是bs4的HTML解析器
| 解析器 | 使用方法 | 使用条件 |
|---|---|---|
| bs4的HTML解析器 | BeautifulSoup(mk,'html.parser') | 安装bs4库 |
| lxml的HTML解析器 | BeautifulSoup(mk,'lxml') | pip3 install lxml |
| lxml的XML解析器 | BeautifulSoup(mk,'xml') | pip3 install lxml |
| html5lib的解析器 | BeautifulSoup(mk,'html5lib') | pip install html5lib |
3.2.4 BeautifulSoup类的基本元素
例如:<p class="txt_con">...</p>
| 基本元素 | 说明 |
|---|---|
| Tag | 标签,最基本的信息组织单元,分别用<>和</>标明开始和结束 |
| Name | 标签的名称,的名称是'p',格式:<p>...</p><tag>.name |
| Attributes | 标签的属性,字典形式组织,格式:<tag>.attrs |
| NavigableString | 标签内非属性字符串,中字符串,格式:<>...</><tag>.string |
| Comment | 标签内字符串的注释部分,一种特殊的注释类型 |
3.2.5 标签相关属性运用
import requests
from bs4 import BeautifulSoup
ret = requests.get("http://python123.io/ws/demo.html")
uhtext = ret.text
soup = BeautifulSoup(uhtext, 'html.parser')
print(soup.title)
print(soup.p)
输出结果:
<title>This is a python demo page</title>
<p class="title"><b>The demo python introduces several python courses.</b></p>
任何存在于HTML语法中的标签都可以用访问获得,当HTML文档中存在多个相同对应内容时,返回第一个。soup.<tag><tag>soup.<tag>
import requests
from bs4 import BeautifulSoup
ret = requests.get("http://python123.io/ws/demo.html")
uhtext = ret.text
soup = BeautifulSoup(uhtext, 'html.parser')
tag标签的Name
print(soup.a.name) # 获取a标签的名称
print(soup.a.parent.name) # 获取a标签父类元素的名称
print(soup.a.parent.parent.name) # 获取a标签父类的父类元素的名称
tag标签的Attributes
print(soup.a.attrs) # 获取a标签属性的字典
print(soup.a.attrs'href') # 获取a标签指定的属性值
print(type(soup.a.attrs)) # 一个<tag>可以有0或多个属性,字典类型
print(type(soup.a)) # a标签是be4的元素标签
tag标签的NavigableString
print(soup.a.string) # 获取a标签的文本内容
print(soup.p.string) # 获取P标签的文本内容
print(type(soup.p.string)) # NavigableString可以跨越多个层次
tag标签的Comment
newsoup = BeautifulSoup('<b><!--第一次见面的问候语--></b><p>How Do You Do</p>', 'html.parser')
print(newsoup.b.string)
print(type(newsoup.b.string)) # Comment是一种特殊类型
输出结果:
a
p
body
{'href': 'http://www.icourse163.org/course/BIT-268001', 'class': 'py1', 'id': 'link1'}
http://www.icourse163.org/course/BIT-268001
<class 'dict'>
<class 'bs4.element.Tag'>
Basic Python
The demo python introduces several python courses.
<class 'bs4.element.NavigableString'>
第一次见面的问候语
<class 'bs4.element.Comment'>
3.3基于bs4库的HTML内容遍历
3.3.1 HTML基本格式分析
分析This is a python demo page的树形结构。
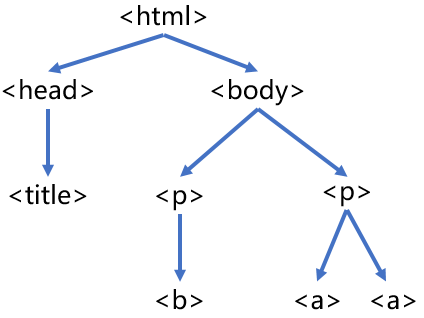
<>...</>构成了所属关系,形成了标签的树形结构。
分析树形结构遍历模型。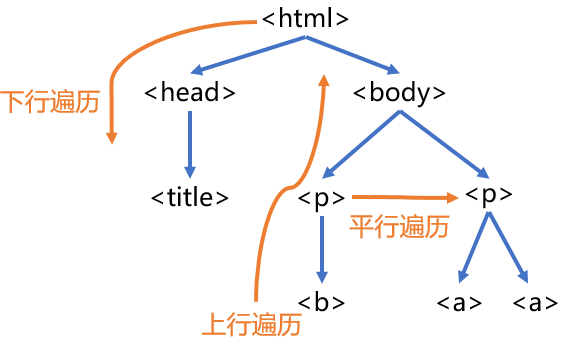
3.3.2 标签树的下行遍历
BeautifulSoup类型是标签树的根节点。
| 属性 | 说明 |
|---|---|
| .contents | 子节点的列表,将所有子节点存入列表<tag> |
| .children | 子节点的迭代类型,用于循环遍历子节点 |
| .descendants | 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历 |
import requests
from bs4 import BeautifulSoup
ret = requests.get("http://python123.io/ws/demo.html")
uhtext = ret.text
soup = BeautifulSoup(uhtext, 'html.parser')
print(soup.body.contents) # 获取body所有的子节点元素列表
print(len(soup.body.contents)) # 获取body所有子节点元素的个数
for child in soup.body.contents:
print(child)
for child in soup.body.descendants:
print(child)
输出结果:
'\\n', \
\
5
<p class="title"><b>The demo python introduces several python courses.</b></p>
....
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>
Advanced Python
3.3.3 标签树的上行遍历
| 属性 | 说明 |
|---|---|
| .parent | 节点的父标签 |
| .parents | 节点先辈标签的迭代类型,用于循环遍历先辈节点 |
import requests
from bs4 import BeautifulSoup
ret = requests.get("http://python123.io/ws/demo.html")
uhtext = ret.text
soup = BeautifulSoup(uhtext, 'html.parser')
print(soup.title.parent)
print(soup.html.parent)
遍历所有先辈节点,包括soup本身,所以要区别判断
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)
输出结果:
<head><title>This is a python demo page</title></head>
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>
</body></html>
p
body
html
document
3.3.4 标签树的平行遍历
| 属性 | 说明 |
|---|---|
| .next_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .previous_sibling | 返回按照HTML文本顺序的上一个平行节点标签 |
| .next_siblings | 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 |
| .previous_siblings | 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签 |
注意:平行遍历发生在同一个父节点下的各节点间。
import requests
from bs4 import BeautifulSoup
ret = requests.get("http://python123.io/ws/demo.html")
uhtext = ret.text
soup = BeautifulSoup(uhtext, 'html.parser')
print(soup.a.next_sibling)
print(soup.a.next_sibling.next_sibling)
print(soup.a.previous_sibling)
for sibling in soup.a.next_sibling: # 遍历后续节点
print(sibling)
for sibling in soup.a.previous_sibling: # 遍历前续节点
print(sibling)
输出结果:
and
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
a
...
:
3.4基于bs4库的HTML格式输出
3.4.1 bs4库的prettify()方法
import requests
ret = requests.get("http://python123.io/ws/demo.html")
uhtext = ret.text
print(uhtext)
输出结果:
<html><head><title>This is a python demo page</title></head>
<body>
...
</body></html>
能否让HTML内容更加"友好"的显示?
import requests
ret = requests.get("http://python123.io/ws/demo.html")
uhtext = ret.text
print(uhtext)
from bs4 import BeautifulSoup
soup = BeautifulSoup(uhtext, 'html.parser')
print(soup.prettify())
输出结果:
<html>
<head>
<title>
This is a python demo page
</title>
</head>
<body>
...
</body>
</html>
.prettify()为HTML文本<>及其内容增加更加。可用于标签,方法:。'\n'.prettify()<tag>.prettify()
print(soup.a.prettify())
输出结果:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">
Basic Python
</a>
3.4.2 bs4库的编码
虽然bs4库将任何HTML输入都变成utf‐8编码,Python 3.x默认支持编码是utf‐8,解析无障碍。
由于Windows系统默认编码方式是,如果读取中文网站是出现中文字符乱码的形式。GBK
解决办法
import requests
from bs4 import BeautifulSoup
ret = requests.get("https://www.baidu.com")
ret.encoding = 'UTF-8' # 解决中文网站是出现中文字符乱码问题
uhtext = ret.text
soup = BeautifulSoup(uhtext, 'html.parser')
print(soup.prettify())
输出结果:
<!DOCTYPE html>
<!--STATUS OK-->
<html>
...
</html>
3.5BeautifulSoup类库选择器
3.5.1 通过标签名称查找
在CSS中标签名不加任何修饰,类名前加,id名前加等等。类库也可以利用类似的方法来筛选元素,用到的方法是,返回类型是类型。.#BeautifulSoupsoup.select()list
import requests
from bs4 import BeautifulSoup
ret = requests.get("http://python123.io/ws/demo.html")
uhtext = ret.text
soup = BeautifulSoup(uhtext, 'html.parser')
print(soup.select('title'))
print(soup.select('p'))
输出结果:
\
[<p class="title"><b>The demo python introduces several python courses.</b></p>, <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>]
3.5.2 通过类名查找
import requests
from bs4 import BeautifulSoup
ret = requests.get("http://python123.io/ws/demo.html")
uhtext = ret.text
soup = BeautifulSoup(uhtext, 'html.parser')
print(soup.select('.title'))
print(soup.select('.course'))
输出结果:
\
\
[<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>]
3.5.3 通过id名查找
import requests
from bs4 import BeautifulSoup
ret = requests.get("http://python123.io/ws/demo.html")
uhtext = ret.text
soup = BeautifulSoup(uhtext, 'html.parser')
print(soup.select('#link1'))
print(soup.select('#link2'))
输出结果:
import requests
from bs4 import BeautifulSoup
ret = requests.get("http://python123.io/ws/demo.html")
uhtext = ret.text
soup = BeautifulSoup(uhtext, 'html.parser')
print(soup.select('#link1'))
print(soup.select('#link2'))
3.5.4 组合查找
import requests
from bs4 import BeautifulSoup
ret = requests.get("http://python123.io/ws/demo.html")
uhtext = ret.text
soup = BeautifulSoup(uhtext, 'html.parser')
print(soup.select('head > title'))
print(soup.select('.course a'))
输出结果:
\
\Basic Python\, \Advanced Python\
3.5.5 属性查找
import requests
from bs4 import BeautifulSoup
ret = requests.get("http://python123.io/ws/demo.html")
uhtext = ret.text
soup = BeautifulSoup(uhtext, 'html.parser')
print(soup.select('pclass'))
print(soup.select('aid\*=link'))
[<p class="title"><b>The demo python introduces several python courses.</b></p>, <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>]
\Basic Python\, \Advanced Python\
3.6BeautifulSoup 类库搜索文档树
3.6.1 搜索文档树的相关方法
除了前面讲解的HTML树形结构的搜索方式外,接下来讲解搜索文档树的相关方法。
| 方法 | 说明 |
|---|---|
| .find_all() | 指定搜索元素的子节点,返回列表类型 |
| .find() | 指定搜索元素的子节点且只返回一个结果 |
| .find_parents() | 在先辈节点中搜索,返回列表类型 |
| .find_parent() | 在先辈节点中返回一个结果 |
| .find_next_siblings() | 在后续平行节点中搜索,返回列表类型 |
| .find_next_sibling() | 在后续平行节点中返回一个结果 |
| .find_previous_siblings() | 在前序平行节点中搜索,返回列表类型 |
| .find_previous_sibling() | 在前序平行节点中返回一个结果 |
3.6.2 find_all ()方法相关参数运用
语法:.find_all(, , , ,nameattrsrecursivestring**kwargs)
1) 参数解释
- name: 对标签名称的检索字符串
-
- 字符串
- 正则表达式
- 列表
- 真
- 方法
- attrs: 对标签属性值的检索字符串,可标注属性检索
- recursive: 是否对子孙全部检索,默认True
- string: <>...</>中字符
2 ) 名称参数
- name-传字符串
- import requests
- from bs4 import BeautifulSoup
- ret = requests.get("http://python123.io/ws/demo.html")
- uhtext = ret.text
- soup = BeautifulSoup(uhtext, 'html.parser')
- print(soup.find_all('a'))
- 输出结果:
- name-传正则表达式
- import requests
- import re
- from bs4 import BeautifulSoup
- ret = requests.get("http://python123.io/ws/demo.html")
- uhtext = ret.text
- soup = BeautifulSoup(uhtext, 'html.parser')
-
name-传正则表达式
- for tag in soup.find_all(re.compile("^b")):
- print(tag.name)
- 输出结果:
- body
- b
- name-传列表
- import requests
- import re
- from bs4 import BeautifulSoup
- ret = requests.get("http://python123.io/ws/demo.html")
- uhtext = ret.text
- soup = BeautifulSoup(uhtext, 'html.parser')
-
name-传列表
- print(soup.find_all('a', 'b'))
- 输出结果:
-
\
- name-传True
- import requests
- import re
- from bs4 import BeautifulSoup
- ret = requests.get("http://python123.io/ws/demo.html")
- uhtext = ret.text
- soup = BeautifulSoup(uhtext, 'html.parser')
-
传True
- for tag in soup.find_all(True):
- print(tag.name)
- 输出结果:
- html
- head
- title
- body
- p
- b
- p
- a
- a
- name-传方法
如果包含属性也包含 属性,那么将返回:classidTrue
import requests
from bs4 import BeautifulSoup
ret = requests.get("http://python123.io/ws/demo.html")
uhtext = ret.text
soup = BeautifulSoup(uhtext, 'html.parser')
def has_class_but_no_id(tag):
return tag.has_attr('class') and tag.has_attr('id')
传方法
print(soup.find_all(has_class_but_no_id))
输出结果:
\Basic Python\, \Advanced Python\
3 ) 关键字参数
import requests
import re
from bs4 import BeautifulSoup
ret = requests.get("http://python123.io/ws/demo.html")
uhtext = ret.text
soup = BeautifulSoup(uhtext, 'html.parser')
print(soup.find_all(id="link1"))
print(soup.find_all(href=re.compile("BIT-1001870001")))
print(soup.find_all(href=re.compile("BIT-1001870001"), id="link2"))
print(soup.find_all('a', class_='py1'))
print(soup.find_all(attrs={"class": "title"}))
输出结果:
\
\
3 ) 文本参数
import requests
import re
from bs4 import BeautifulSoup
ret = requests.get("http://python123.io/ws/demo.html")
uhtext = ret.text
soup = BeautifulSoup(uhtext, 'html.parser')
print(soup.find_all(text=" and "))
print(soup.find_all(text=" and ", "Advanced Python", "Basic Python"))
print(soup.find_all(text=re.compile("Python")))
输出结果:
' and '
'Basic Python', ' and ', 'Advanced Python'
'Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\\r\\n', 'Basic Python', 'Advanced Python'
4 ) limit 参数
import requests
import re
from bs4 import BeautifulSoup
ret = requests.get("http://python123.io/ws/demo.html")
uhtext = ret.text
soup = BeautifulSoup(uhtext, 'html.parser')
print(soup.find_all("a", limit=1))
输出结果:
5 ) 递归参数
import requests
import re
from bs4 import BeautifulSoup
ret = requests.get("http://python123.io/ws/demo.html")
uhtext = ret.text
soup = BeautifulSoup(uhtext, 'html.parser')
print(soup.html.find_all("head", recursive=False))
输出结果:
\
3.7美观的汤类库解析网页
3.7.1 本地网页解析过程
将第三章所制作的腾达产品页为例。进行爬取相关产品标题以"G"开头的所有数据信息。网页组成结构
from bs4 import BeautifulSoupimport reinfo = []with open("./ProductPage.html", "r", encoding="UTF-8") as localdata: soup = BeautifulSoup(localdata, "html.parser") images = soup.select( '#content > div.product-items > div > ul > li > a > img') titles = soup.select( '#content > div.product-items > div > ul > li > a > div > h3') contents = soup.select( '#content > div.product-items > div > ul > li > a > div > p') for title, content, image in zip(titles, contents, images): data = { 'title': title.string, 'content': content.string, 'image': image.attrs['src'] } info.append(data)for i in info: if re.match(r'^G', i['title']): print(i['title'], i['content'], i['image'])输出结果:G103 GPON光纤接入终端` `符合GPON技术标准,超强兼容,上、下行速率可达2.5Gbps,千兆有线端口 /image/crawler-basics-exercise-instructions//image/Python_Crawl/G103.jpgG100 GPON光纤接入终端` `符合GPON规范,千兆以太网口,支持OMCI的远程管理、兼容各级运营商网络环境 /image/crawler-basics-exercise-instructions//image/Python_Crawl/G100.jpg3.7.2 Internet中的网页解析过程
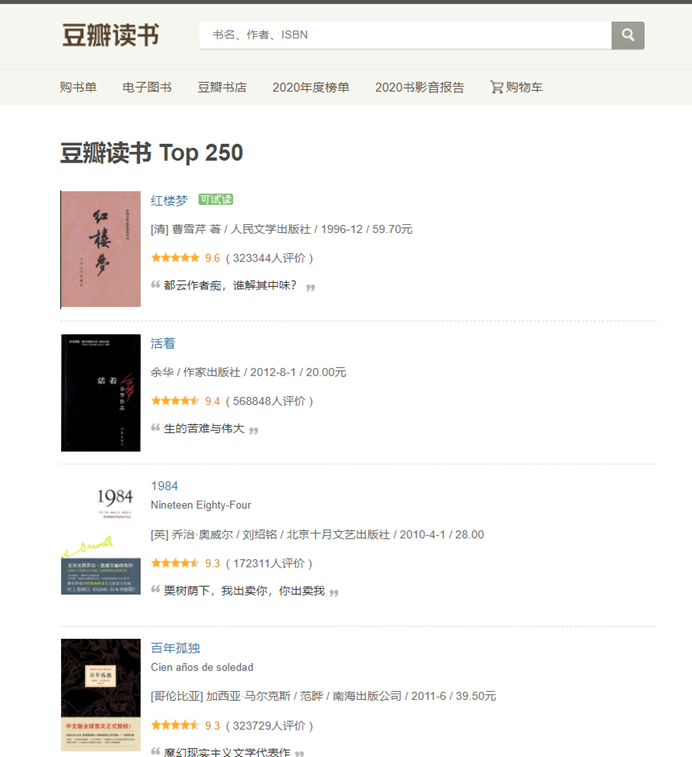
实例爬取豆瓣图书top250。
要求:
爬取书名,作者出版社,评分,评价人数等信息。
from bs4 import BeautifulSoupimport requestsimport redatainfo = []headers = { "User-Agent": "Mozilla/5.0(WindowsNT10.0;Win64;x64) AppleWebKit/537.36(KHTML, likeGecko) Chrome/79.0.3945.117Safari/537.36"}for i in range(0, 250, 25): url = 'https://book.douban.com/top250?start={}'.format(i) ret = requests.get(url,headers=headers) soup = BeautifulSoup(ret.text, 'html.parser') titles = soup.select('div.pl2 > a') infos = soup.select('p.pl') rating_nums = soup.select('span.rating_nums') numbers = soup.select('span.pl') images = soup.select('a.nbg > img') for title, info, rating_num, number, image in zip(titles, infos, rating_nums, numbers, images): t = re.sub(r'[\n ]', '', title.text) data = { 'title': t, 'image': image['src'], 'info': info.text.strip(), 'rating_num': rating_num.text + '分', } print('--'*80) print(data)输出结果:----------------------------------------------------------------------------------------------------------------------------------------------------------------{'title': '红楼梦', 'image': 'https://img1.doubanio.com/view/subject/s/public/s1070959.jpg', 'info': '[清] 曹雪芹` `著 / 人民文学出版社 / 1996-12 / 59.70元', 'rating_num': '9.6分'}----------------------------------------------------------------------------------------------------------------------------------------------------------------{'title': '活着', 'image': 'https://img3.doubanio.com/view/subject/s/public/s29053580.jpg', 'info': '余华 / 作家出版社 / 2012-8-1 / 20.00元', 'rating_num': '9.4分'}...{'title': '给青年诗人的信', 'image': 'https://img1.doubanio.com/view/subject/s/public/s28378127.jpg', 'info': '[奥] 里尔克 / 冯至 / 雅众文化/云南人民出版社 / 2015-12 / 29.00元', 'rating_num': '9.0分'}----------------------------------------------------------------------------------------------------------------------------------------------------------------{'title': '被讨厌的勇气:"自我启发之父"阿德勒的哲学课', 'image': 'https://img2.doubanio.com/view/subject/s/public/s33323852.jpg', 'info': '岸见一郎 / 渠海霞 / 机械工业出版社 / 2015-3-1 / 39.8', 'rating_num': '8.6分'}4.1 正则表达式的作用
1 ) 正则表达式简介
正则表达式,又称规则表达式。(正则表达式,在代码中常简写为regex、regexp或re),计算机科学的一个概念。正则表通常被用来检索、替换那些符合某个模式(规则)的文本。
- 正则表达式是用来简洁表达一组字符串的表达式;
- 正则表达式是一种通用的字符串表达框架;
- 正则表达式是一种针对字符串表达"简洁"和"特征"思想的工具;
- 正则表达式可以用来判断某字符串的特征归属。
2 ) 正则表达式在文本处理中常用地方 - 表达文本类型的特征(病毒、入侵等);
- 同时查找或替换一组字符串;
- 匹配字符串的全部或部分;
- 最主要应用在字符串匹配中;
4.2 正则表达式的语法
正则表达式语法由和构成。字符操作符
| 正则表达式 | 对应匹配的字符串 |
|---|---|
| P(Y|ZT_ZT_哎呀)?N | 'PN'、'PYN'、'PYTN'、'PYTHN'、'PYTHON' |
| PYTHON+ | 'PYTHON'、'PYTHONN'、'PYTHONNN' ... |
| PYTHON | 'PYTON'、'PYHON' |
| PY\^TH?上 | 'PYON'、'PYaon'、'PYbON'、'PYcON'... |
| PY{:3}N | 'PN'、'PYN'、'PYYN'、'PYYYN'... |
4.2.1 正则表达式常用操作符
| 操作符 | 说明 | 实例 |
|---|---|---|
| . | 表示任何单个字符 | |
| 字符集,对单个字符给出取值范围 | abc表示a、b、c,a‐z表示a到z单个字符 | |
| \^ | 非字符集,对单个字符给出排除范围 | \^abc表示非a或b或c的单个字符 |
| * | 前一个字符0次或无限次扩展 | abc* 表示 ab、abc、abcc、abccc 等 |
| + | 前一个字符1次或无限次扩展 | abc+ 表示 abc、abcc、abccc 等 |
| ? | 前一个字符0次或1次扩展 | abc?表示 ab、abc |
| $#124; | 左右表达式任意一个 | abc|def 表示 abc、def |
| {m} | 扩展前一个字符m次 | ab{2}c表示abbc |
| {m,n} | 扩展前一个字符m至n次(含n) | [ab{1,2}c表示abc、abbc |
| ^ | 匹配字符串开头 | ^abc表示abc且在一个字符串的开头 |
| $ | 匹配字符串结尾 | abc$表示abc且在一个字符串的结尾 |
| ( ) | 分组标记,内部只能使用 |操作符 | (abc)表示abc,(abc|def)表示abc、def |
| \d | 数字,等价于0‐9 | |
| \w | 单词字符,等价于A‐Za‐z0‐9_ |
4.1.2 正则表达式常用实例
- 正则表达式常用实例
| 实例 | 匹配作用 |
|---|---|
| ^A‐Za‐z+$ | 由26个字母组成的字符串 |
| ^A‐Za‐z0‐9+$ | 由26个字母和数字组成的字符串 |
| ^‐?\d+$ | 整数形式的字符串 |
| ^0‐91‐90‐9$ | 正整数形式的字符串 |
| 1‐9\d{5} | 中国境内邮政编码 |
| \\u4e00‐\\u9fa5 | 匹配中文字符 |
| \d{3}-\d{8}|\d{4}‐\d{7} | 国内电话号码,023‐67783047 |
1 ) 匹配 IP 地址实例
IP地址字符串形式的正则表达式(IP地址分4段,每段0‐255)
\d+.\d+.\d+.\d+ 或 \d{1,3}.\d{1,3}.\d{1,3}.\d{1,3}
2) 精确写法
-
0‐99: 1‐9?\d
-
100‐199: 1\d{2}
-
200‐249: 20‐4\d
-
250‐255: 250‐5
((1‐9?\d|1\d{2}|20‐4\d|250‐5).){3}(1‐9?\d|1\d{2}|20‐4\d|250‐5)
4.3Re 类库的基本运用
4.3.1 Re 类库的介绍
Re类库是的标准库,主要用于字符串匹配。Python
1) 调用方式: import re
2) 正则表达式的表示类型
- raw string type(原生字符串类型)
re库采用raw string类型表示正则表达式,表示为:。r'text'
例如: ,r'1‐9\d{5}'r'\d{3}‐\d{8}|\d{4}‐\d{7}'
raw string是不包含对转义符再次转义的字符串。
- re库也可以采用string类型表示正则表达式,但更繁琐。
例如:,'1‐9\\d{5}''\\d{3}‐\\d{8}|\\d{4}‐\\d{7}'
建议: 当正则表达式包含转义符时,使用。raw string
4.3.2 Re 类库主要功能函数
| 函数 | 说明 |
|---|---|
| re.search() | 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象 |
| re.match() | 从一个字符串的开始位置起匹配正则表达式,返回match对象 |
| re.findall() | 搜索字符串,以列表类型返回全部能匹配的子串 |
| re.split() | 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型 |
| re.finditer() | 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象 |
| re.sub() | 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串 |
4.4Re类库的Match对象
Match对象是一次匹配的结果,包含匹配的很多信息。
import rematch = re.search(r'[1‐9]\d{5}', "1208253")if match: print(match.group(0))print(type(match))输出结果:120825<class '_sre.SRE_Match'>1 ) 匹配对象属性
| 属性 | 说明 |
|---|---|
| .string | 待匹配的文本 |
| .re | 匹配时使用的patter对象(正则表达式) |
| .pos | 正则表达式搜索文本的开始位置 |
| .endpos | 正则表达式搜索文本的结束位置 |
2 ) 匹配对象方法
| 方法 | 说明 |
|---|---|
| .group(0) | 获得匹配后的字符串 |
| .start() | 匹配字符串在原始字符串的开始位置 |
| .end() | 匹配字符串在原始字符串的结束位置 |
| .span() | 返回(.start(), .end()) |
4.5Re类库的贪婪匹配和最小匹配
1 ) Re 类库的贪婪匹配
import rematch = re.search(r'PY.*N', 'PYANBNCNDN')print(match.group(0))输出结果:PYANBNCNDN提示: Re庫默认采用贪婪匹配,即输出匹配最长的子串。
2 ) Re 类库的最小匹配
如何输出最短的子串呢?
import rematch = re.search(r'PY.*?N', 'PYANBNCNDN')print(match.group(0))输出结果:PYAN3) 最小匹配操作符
| 操作符 | 说明 |
|---|---|
| *? | 前一个字符0次或无限次扩展,最小匹配 |
| +? | 前一个字符1次或无限次扩展,最小匹配 |
| ?? | 前一个字符0次或1次扩展,最小匹配 |
| {m,n}? | 扩展前一个字符m至n次(含n),最小匹配匹配 |
5.1认识Scrapy爬虫框架
5.1.1 简介
Scrapy是一个快速功能强大的网络爬虫框架。爬虫框架是实现爬虫功能的一个软件结构和功能组件集合。爬虫框架是一个半成品,能够帮助用户实现专业网络爬虫。
Scrapy官网:https://www.scrapy.org/
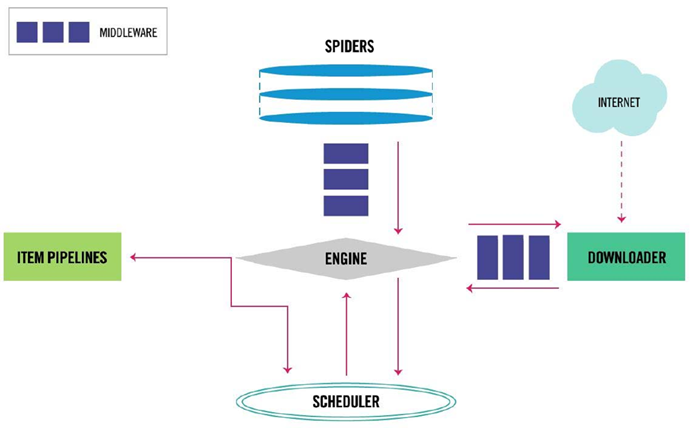
5.1.2 Scrapy爬虫框架结构组成
5.2Scrapy爬虫框架的安装
1 ) 执行安装 Scrapy 框架命令
终端输入:
pip3 install scrapy
注: 如果下载失败,并且出现以下提示:
You are using pip version 10.0.1, however version 21.0.1 is available. You should consider upgrading via the 'pip install --upgrade pip' command.
可以升级pip3来解决。
终端输入:
pip3 install --upgrade pip
之后再重新下载scrapy
2 ) 测试 Scrapy 框架是否安装成功
打开终端:
输入:python3
导入crapy包:
import scrapy

检查版本:
scrapy --v
5.3Scrapy 框架爬虫第一个实例
应用Scrapy爬虫框架主要是编写。配置型代码
打开文件夹:
1 ) 建立一个Scrapy爬虫工程
打开终端,进入目录:crawlCode
cd /home/ec2-user/crawlCode
然后执行如下命令:
scrapy startproject scrapydemo
2 ) 在工程中产生一个Scrapy爬虫
进入刚才建好的工程目录(/home/ec2-user/crawlCode/scrapydemo):
cd scrapydemo/
然后执行如下命令:
scrapy genspider demo python123.io
参数解释:scrapy genspider 爬虫名称 爬取的域名
该命令作用
- 生成一个名称为demo的spider。
- 在spiders目录下增加代码文件。demo.py
3) 文件说明 - scrapy.cfg: 项目的配置文件
- scrapydemo/: 该项目的python模块。之后您将在此加入代码。
- scrapydemo/items.py: 项目中的item文件。
- scrapydemo/pipelines.py: 项目中的管道文件。
- scrapydemo/settings.py: 项目的设置文件。
- scrapydemo/spiders/: 放置蜘蛛代码的目录。
设置文件 - 设置请求头:
DEFAULT_REQUEST_HEADERS {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0;赢64;x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"
} - 设置下载速度:
DOWNLOAD_DELAY = 1 - 是否遵守Robots协议:
ROBOTSTXT_OBEY = 假
4 ) 配置产生的蜘蛛爬虫 - 初始URL地址
- 获取页面后的解析方式
-*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
def start_requests(self):
urls = [
'http://www.python123.io/ws/demo.html'
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
fname = response.url.split('/')-1
with open(fname, 'wb') as f:
f.write(response.body)
self.log('保存的文件是 %s' % fname)
5) 运行爬虫文件
在目录下执行命令:/home/ec2-user/crawlCode/scrapydemo
scrapy crawl demo
注意: 是爬虫文件的名字(name)demo
5.4yield 关键字的使用
1 ) yield 生成器
- 包含语句的函数是一个生成器。yield
- 生成器每次产生一个值(yield语句),函数被冻结,被唤醒后再产生一个值。
- 生成器是一个不断产生值的函数。
def gen(n):
for i in range(n):
yield i**2
for i in gen(5):
print(i, "", end="")
生成器与普通写法区别
2) 普通写法
def square(n):
ls = i\*\*2 for i in range(n)
return ls
for i in square(5):
print(i, "", end="")
3) 生成器相比一次列出所有内容的优势:
- 更节省存储空间
- 响应更迅速
- 使用更灵活
5.5Scrapy 基本运用
1 ) 爬虫
使用步骤:
- 创建一个工程和Spider模板
- 编写蜘蛛
- 编写项管道
- 优化配置策略
数据类型: - Request类:表示一个HTTP请求。
- Response类:表示一个HTTP响应。
- Item类:表示一个从HTML页面中提取的信息内容。
2 ) 请求类
| 属性和方法 | 说明 |
|---|---|
| .url | Request对应的请求URL地址 |
| .method | 对应的请求方法,'GET' 'POST'等 |
| .headers | 字典类型风格的请求头 |
| .body | 请求内容主体,字符串类型 |
| .meta | 用户添加的扩展信息,在Scrapy内部模块间传递信息使用 |
| .copy() | 复制该请求 |
| .url | Response对应的URL地址 |
| .status | 对HTTP状态码,默认是200 |
| .headers | Response对应的头部信息 |
| .body | Response对应的内容信息,字符串类型 |
| .flags | 一组标记 |
| .request | 产生Response类型对应的Request对象 |
| .copy() | 复制该响应 |
3 ) Scrapy 爬虫提取信息的方法
Scrapy爬虫支持多种HTML信息提取方法:
- 美汤
- lxml
- 再
- XPath 选择器
- CSS 选择器