导包
python
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
from tqdm.auto import tqdm
import torch
import torch.nn as nn
import torch.nn.functional as F
print(sys.version_info)
for module in mpl, np, pd, sklearn, torch:
print(module.__name__, module.__version__)
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
print(device)
seed = 42数据准备
python
from torchvision import datasets
from torchvision.transforms import ToTensor
from torch.utils.data import random_split
# fashion_mnist图像分类数据集
train_ds = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
test_ds = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
# torchvision 数据集里没有提供训练集和验证集的划分
# 这里用 random_split 按照 11 : 1 的比例来划分数据集
train_ds, val_ds = random_split(train_ds, [55000, 5000], torch.Generator().manual_seed(seed))使用FashionMNIST图像分类数据集,先加载数据集,然后变成Tensor,然后把数据集分成测试集和验证集。
python
from torchvision.transforms import Normalize
# 遍历train_ds得到每张图片,计算每个通道的均值和方差
def cal_mean_std(ds):
mean = 0.
std = 0.
for img, _ in ds:
mean += img.mean(dim=(1, 2))
std += img.std(dim=(1, 2))
mean /= len(ds)
std /= len(ds)
return mean, std
# print(cal_mean_std(train_ds))
# 0.2860, 0.3205
transforms = nn.Sequential(
Normalize([0.2856], [0.3202])
) # 对每个通道进行标准化对数据进行标准化,标准化需要知道均值和方差。
python
from torch.utils.data.dataloader import DataLoader
batch_size = 32
# 从数据集到dataloader
train_loader = DataLoader(train_ds, batch_size=batch_size, shuffle=True, num_workers=4)
val_loader = DataLoader(val_ds, batch_size=batch_size, shuffle=False, num_workers=4)
test_loader = DataLoader(test_ds, batch_size=batch_size, shuffle=False, num_workers=4)定义模型
python
class CNN(nn.Module):
def __init__(self, activation="relu"):
super(CNN, self).__init__()
self.activation = F.relu if activation == "relu" else F.selu
#输入通道数,图片是灰度图,所以是1,图片是彩色图,就是3,输出通道数,就是卷积核的个数(32,1,28,28)
#输入x(32,1,28,28) 输出x(32,32,28,28)
self.conv1 = nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3, padding=1)
#输入x(32,32,28,28) 输出x(32,32,28,28)
self.conv2 = nn.Conv2d(in_channels=32, out_channels=32, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2, 2) #池化不能够改变通道数,池化核大小为2(2*2),步长为2 (28-2)//2+1=14
self.conv3 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, padding=1)
self.conv4 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, padding=1)
self.conv5 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1)
self.conv6 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, padding=1)
self.flatten = nn.Flatten()
# input shape is (28, 28, 1) so the fc1 layer in_features is 128 * 3 * 3
self.fc1 = nn.Linear(128 * 3 * 3, 128)
self.fc2 = nn.Linear(128, 10) #输出尺寸(32,10)
self.init_weights()
def init_weights(self):
"""使用 xavier 均匀分布来初始化全连接层、卷积层的权重 W"""
for m in self.modules():
if isinstance(m, (nn.Linear, nn.Conv2d)):
nn.init.xavier_uniform_(m.weight)
nn.init.zeros_(m.bias)
def forward(self, x):
act = self.activation
x = self.pool(act(self.conv2(act(self.conv1(x))))) # 1 * 28 * 28 -> 32 * 14 * 14
# print(x.shape)
x = self.pool(act(self.conv4(act(self.conv3(x))))) # 32 * 14 * 14 -> 64 * 7 * 7
# print(x.shape)
x = self.pool(act(self.conv6(act(self.conv5(x))))) # 64 * 7 * 7 -> 128 * 3 * 3
# print(x.shape)
x = self.flatten(x) # 128 * 3 * 3 ->1152
x = act(self.fc1(x)) # 1152 -> 128
x = self.fc2(x) # 128 -> 10
return x
for idx, (key, value) in enumerate(CNN().named_parameters()):
print(f"{key}\tparamerters num: {np.prod(value.shape)}") # 打印模型的参数信息不需要展平层。Conv2d就是卷积,一般是两层卷积一层池化,这样效果比较好。池化就是降采样,池化的作用就是使用某一位置的相邻输出的总体统计特征来代替网络在改位置的输出,可以大幅减少网络的参数量。降低参数量实际上就是把图像的尺寸减小,最后还是要展平,不然无法变成分类问题。池化是没有参数的,和激活函数类似。
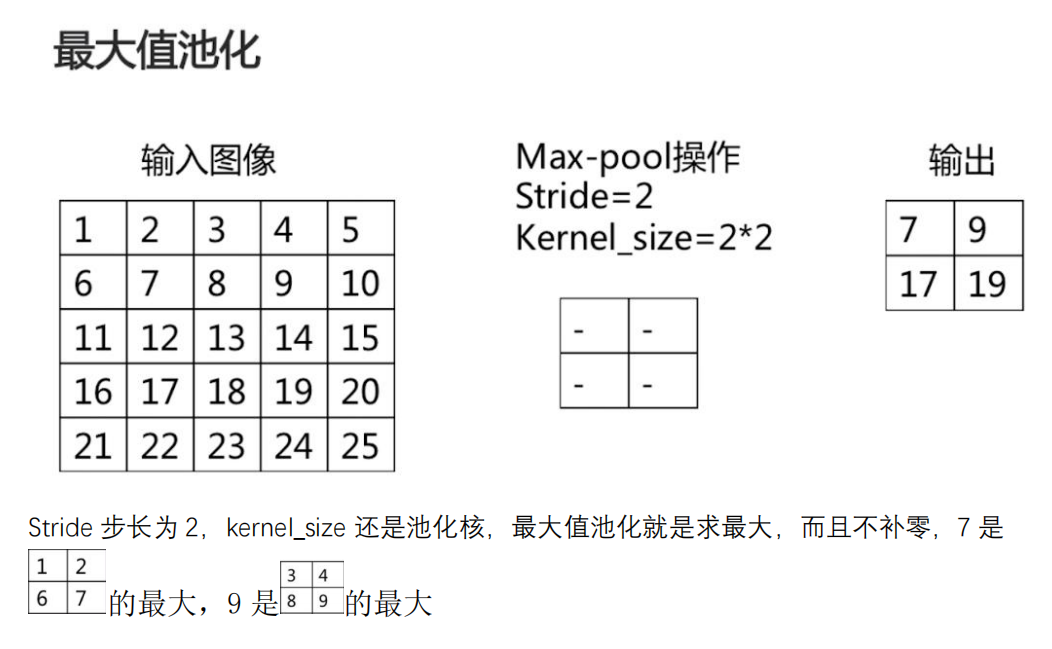
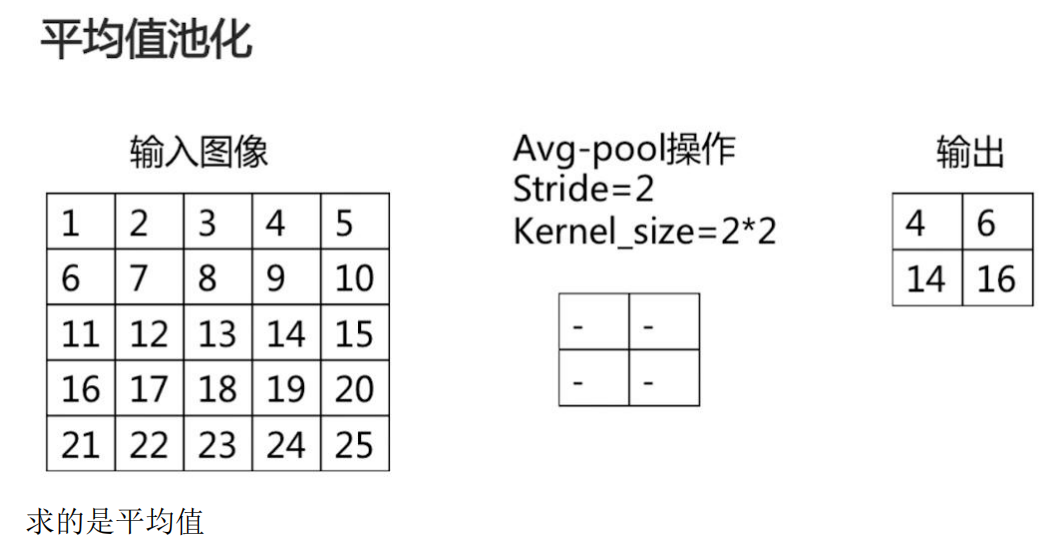
池化分为两种,一种是最大值池化,能够抑制网络参数误差造成的估计均值偏移的现象;一种是平均值池化,主要用来抑制领域之间差别过大,造成的方差过大。
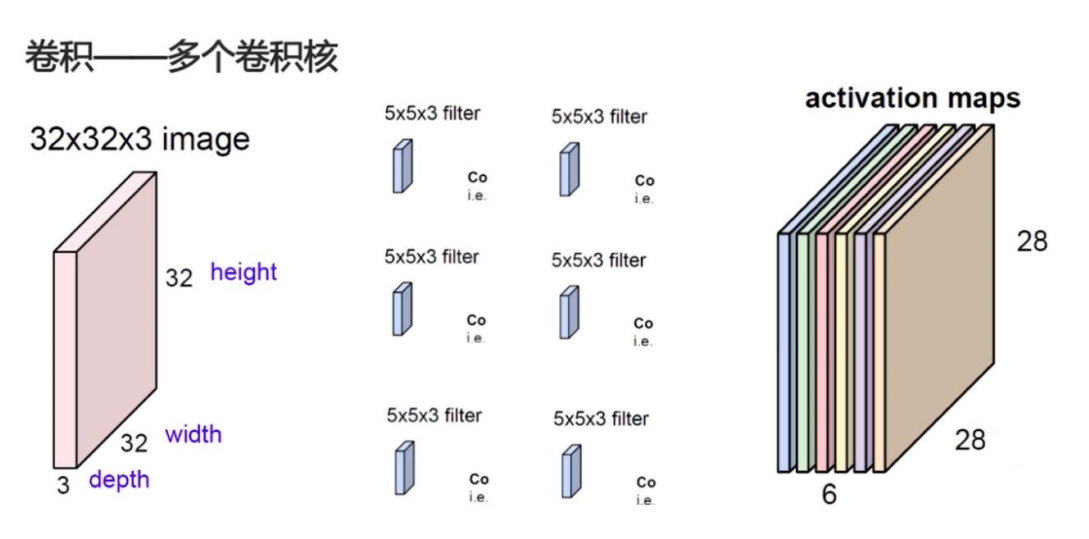
因为我们这里图像是黑白的,所以通道数就是1, 输入的图像参数分别是batch_size,通道数,宽,高;输入通道数是1,输出通道数是32:如下图,如果我们输入的图像是32*32*3,那么卷积核的尺寸同步要有3,这里不是矩阵运算,是对应位置相乘再求和,那么经过一个卷积和,假如没有padding,那么扫描过来就是28*28*1的,每个卷积核会在输入的所有通道上分别进行卷积操作,将各通道的结果相加,最终生成单通道的特征图。如果使用多个卷积核(例如n个),通过不同的卷积核学习高层特征,则输出通道数会变为n。一般卷积核的宽高是相等的,kernel_size定义。