目录
首先来深化下linux下一切皆文件
在linux中,windows里不是文件的东西,都被抽象成了文件。
这样做的好处是:开发者仅需使用一套API和开发工具,即可调取linux系统中绝大部分资源。
例:linux中几乎所有读(读文件)都使用read来进行,几乎所有改都使用write来进行。
缓冲区
1.缓冲区本质是一段内存空间。
2.将数据交给缓冲区的本质都是拷贝,所以write、read等方法都是拷贝。
为什么存在缓冲区
意义在于提高了使用缓冲区的进程的效率
怎么提高效率:
1.允许数据在缓冲区中积压,一次就可以刷新多次数据,变相减少了IO次数。
2.允许进程单位时间内,做更多的工作,变相提高了使用缓存,使用者的效率。
缓冲区刷新策略
1.无缓冲,立即刷新
2.有缓冲,遇到换行符刷新(比如显示器文件使用)
3.有缓冲,写满再刷新(普通文件使用)
还有其他方式会引起缓冲区刷新:1.进程强制刷新:fflush
2.进程结束自动刷新
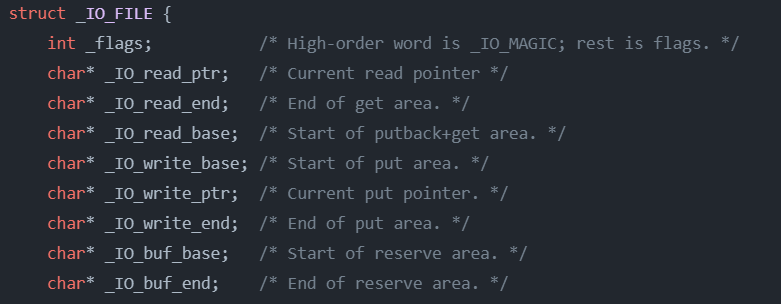
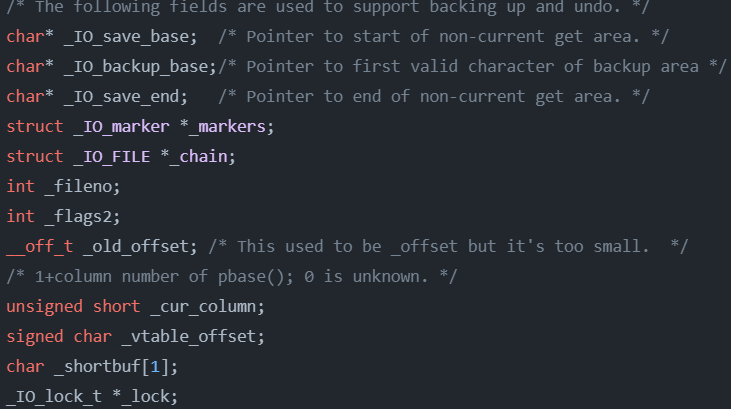
FILE
是C语言库定义的一个结构体,因为IO相关函数与系统调用接口对应,并且库函数封装系统调用,所以本质上,访问文件都是通过fd访问的,所以FILE内部也必定封装了fd。
大致结构如下:
其中_fileno就是fd
FILE结构体内部为我们维护了一个语言级别的缓冲区空间,就是上图中一组组的char*指针区域。
文件缓冲区-》内核缓冲区
FILE内的缓冲区就是文件缓冲区。
1.用户的数据是先写到语言级别缓冲区FILE中,然后再到strcut file中包含指针指向的文件内核缓冲区。
2.对于用户来说,只要把数据从文件缓冲区刷新到操作系统的内核缓冲区,就算是写入完毕了,其余的工作由操作系统来做。
为什么要有语言级缓冲区(文件缓冲区)
1.调用系统调用是有成本的,比较废时间,所以需要减少系统调用次数,等需要刷新时再刷新到内核缓冲区。
2.提高使用语言IO接口的效率。
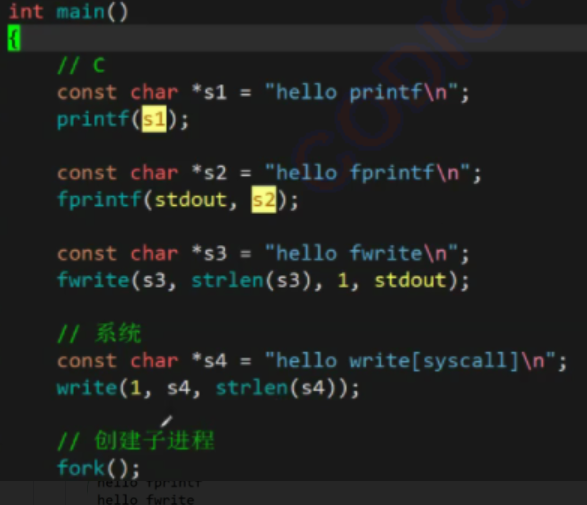
举个缓冲区例子
这段代码的直接运行结果是
而log.txt文件中:
这是为什么呢。
因为重定向后刷新策略变了,换行符不会刷新文件缓冲区了,所以数据就暂存到了log.txt的文件缓冲区,等到进程结束才会刷新到文件的内核缓冲区中,而write是直接刷新到内核缓冲区中的,所以如上。


补充
1.子进程fflush清空缓冲区,会进行写时拷贝,不会影响父进程。
2.操作系统中会有单独的执行流,会根据内存使用情况来动态刷新,尽管刷新条件不满足。
3.fsync函数:将内核缓冲区数据刷新到磁盘中。
小知识
1.重定向的全写是 数字>文件名 ,平常简写为 >文件名 ,默认是把1(标准输出)重定向。
>log.txt 2>&1这样可以把标准输出和标准错误都放到一个文件中。
2.&> 和 >& 是 bash 的快捷方式,表示将标准输出和标准错误输出都重定向到同一个文件。