1.遇到的问题:
在使用 Elasticsearch 时,可能会遇到以下错误:
java.lang.IllegalStateException: failed to obtain node locks, tried \[path_to_data] with lock id 0; maybe these locations are not writable or multiple nodes were started without increasing node.max_local_storage_nodes (was 1)?
如下面所示:

这个错误通常出现在以下两种情况下:
-
数据目录不可写:Elasticsearch 无法获取对数据目录的写权限。
-
多个节点冲突 :在同一台机器上启动了多个 Elasticsearch 节点,而没有修改
node.max_local_storage_nodes配置,导致冲突。
2.错误原因分析
Elasticsearch 在启动时,会在指定的 data 目录下创建一个锁文件,以确保同一目录只能由一个节点实例访问。如果出现了多个节点实例在同一目录下启动的情况,Elasticsearch 会抛出 failed to obtain node locks 错误。这通常发生在以下几种情形:
-
多个 Elasticsearch 实例试图使用相同的数据目录。
-
数据目录存在写权限问题,导致无法创建锁文件。
2.解决方法:
1. 确保数据目录可写(这一步的目的主要是为了确实是否有权限,一般解决不了这个问题)
确保 D:\servicescape\elasticsearch-6.8.6\data(这是我自己的根据你自己的来就行) 目录对 Elasticsearch 进程是可写的。可以尝试以下步骤:
-
检查权限 :右键点击
data文件夹,选择 属性 ,然后查看 安全 选项卡,确保 Elasticsearch 进程(或者当前用户)对该文件夹有写权限。 -
清空数据目录:如果你不需要保留现有的数据,可以尝试删除该目录下的所有文件,然后重启 Elasticsearch。
2. 修改 elasticsearch.yml 配置文件
Elasticsearch 配置文件 elasticsearch.yml 中有一个参数 node.max_local_storage_nodes,它决定了同一台机器上最多可以启动多少个 Elasticsearch 节点。如果你希望在同一台机器上启动多个节点,可以通过修改此配置来解决问题。
默认情况下,该参数的值是 1,表示每个数据目录只允许一个节点运行。我们可以通过增加该值来允许多个节点使用相同的数据目录。以下是具体操作步骤:
-
找到配置文件 : Elasticsearch 的
elasticsearch.yml配置文件通常位于安装目录的config文件夹下,比如:D:\servicescape\elasticsearch-6.8.6\config\elasticsearch.yml。 -
修改配置文件 : 打开
elasticsearch.yml配置文件,找到(或者添加)以下配置项:
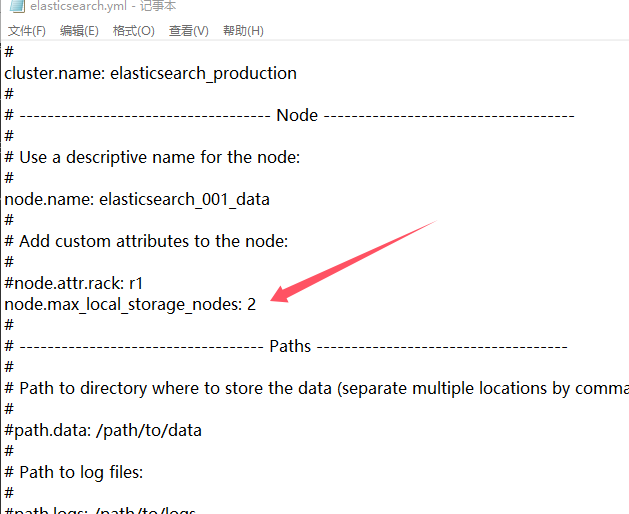
node.max_local_storage_nodes: 2
这将允许最多两个节点使用相同的数据目录。如果你希望使用更多节点,可以根据需要调整该值。
3.保存配置文件 。 重启 Elasticsearch
修改配置文件后,保存并关闭文件,然后重新启动 Elasticsearch。
如果你是通过命令行启动 Elasticsearch,可以使用以下命令:
bin\elasticsearch.bat
重启之后:
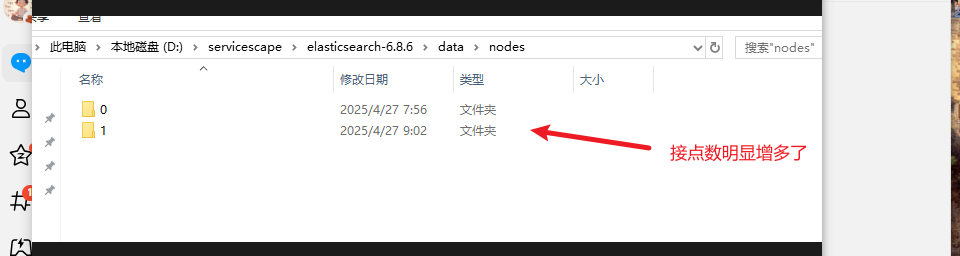
尽管通过修改 node.max_local_storage_nodes 配置可以解决问题,但最好为每个节点使用不同的数据目录 我感觉这只是临时的解决方案,不然节点会越来越多,
3.总结:
通过修改 elasticsearch.yml 中的 node.max_local_storage_nodes 配置项,可以允许多个节点使用相同的数据目录,从而解决启动时的 failed to obtain node locks 错误。然而,为了确保 Elasticsearch 的稳定性和性能,建议为每个节点配置不同的数据目录。