一、前言:Kafka 只是开始,消费才是关键
Kafka 提供了优雅的 Topic 管理与消息缓冲机制,但只有当 Flink 能稳定、有序、无数据丢失地消费并处理这些数据流,实时数仓系统才真正发挥作用。
本篇将围绕 Flink 如何"吃好" Kafka 数据展开,从 数据源配置、时间语义处理、并发与容错、消费策略优化 全面展开讲解。
二、Flink 消费 Kafka 的方式对比
Flink 支持多种 Kafka Source 组件,按版本与场景如下:
| Kafka Source 类型 | 支持版本 | 处理语义 | 备注 |
|---|---|---|---|
| FlinkKafkaConsumer (旧 API) | Flink ≤ 1.13 | 支持最多一次 / 精确一次 | 使用广泛,但已逐步淘汰 |
| KafkaSource (新 API) | Flink ≥ 1.13 | 默认 Exactly Once | 推荐使用,性能更优 |
| Connector Kafka Table API | Flink ≥ 1.11 | 用于 Flink SQL 作业 | 简洁配置,适合声明式处理 |
我们推荐使用 KafkaSource(DataStream API),功能丰富且支持最新特性。
三、KafkaSource 使用最佳实践(Java API)
✅ 示例代码(Flink 1.17+)
java
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setBootstrapServers("kafka-broker:9092")
.setTopics("order_main")
.setGroupId("realtime-order-group")
.setValueOnlyDeserializer(new SimpleStringSchema())
.setStartingOffsets(OffsetsInitializer.latest())
.setProperty("enable.auto.commit", "false")
.build();
DataStream<String> stream = env.fromSource(
kafkaSource,
WatermarkStrategy.forMonotonousTimestamps(),
"Kafka Source"
);四、Watermark 策略与事件时间管理
在实时处理中,事件时间(Event Time)才是真正的业务时间 ,而非 Kafka 到达时间。
Watermark 是 Flink 理解"什么时候可以处理一批数据"的核心机制。
✅ 常见 Watermark 策略
| 策略 | 适用场景 | 示例 |
|---|---|---|
forMonotonousTimestamps() |
时间严格递增,如 IoT 设备 | 单调时间流 |
forBoundedOutOfOrderness(Duration.ofSeconds(x)) |
有乱序容忍的业务日志 | 默认推荐 |
自定义 WatermarkStrategy |
多字段取最晚 | 高级用法 |
📌 示例:有乱序容忍的 Watermark
java
WatermarkStrategy<MyEvent> strategy = WatermarkStrategy
.<MyEvent>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner((event, timestamp) -> event.getEventTime());五、Exactly Once 消费语义配置
Kafka + Flink 想做到 Exactly Once 消费,你需要确保三件事:
-
Kafka Source 设置为 Exactly Once(默认即可)
-
启用 Flink 的状态一致性机制(Checkpoint)
-
Sink 端支持幂等性 / 事务性写入(例如 Kafka Sink、Doris Sink)
✅ 核心配置参数
java
env.enableCheckpointing(5000); // 每 5 秒一次
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);六、消费调优技巧
✅ 并行度配置
-
设置
KafkaSource与处理链路一致的setParallelism,避免反压。 -
Topic 分区数必须 ≥ 并行度,才能让任务并行消费。
✅ 动态 Topic 管理(如 topic.*)
Flink KafkaSource 支持按模式订阅 Topic,例如:
java
.setTopicPattern(Pattern.compile("order_.*"))适合电商、广告等多业务快速接入场景。
✅ 反压监控与缓冲优化
-
调整
env.setBufferTimeout()缓冲延迟 -
利用 Flink UI / Prometheus 监控
backpressure指标
七、典型消费拓扑图(配图)
📊 以下是 Kafka + Flink 消费处理拓扑的示意图:
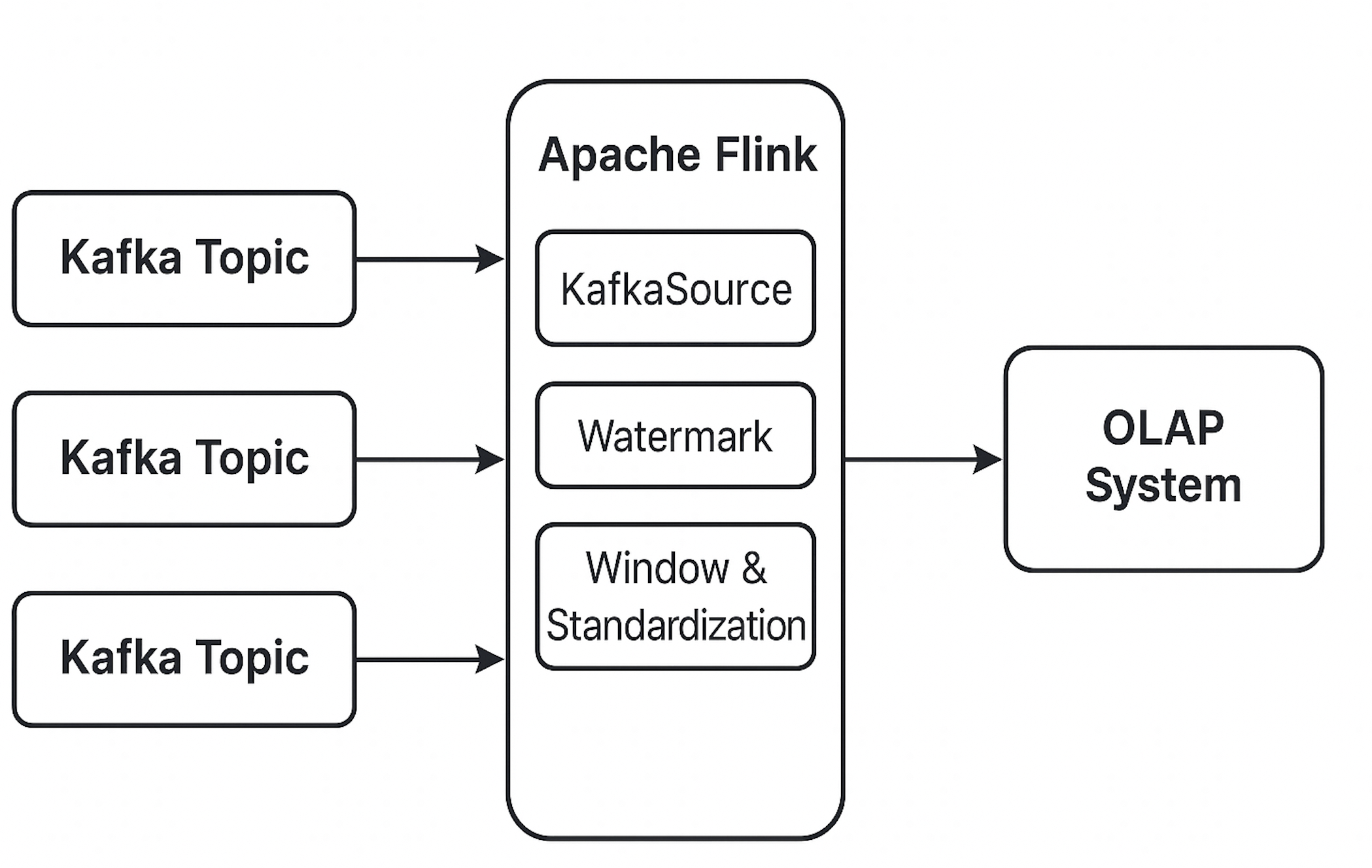
说明:
-
多个 Topic 接入后通过 KafkaSource 接入 Flink
-
Flink 中做 Watermark 分发、窗口计算、标准化处理
-
下游写入 Kafka / OLAP 系统(如 Doris)作为中间层
八、踩坑经验分享
| 问题 | 现象 | 解决方案 |
|---|---|---|
| 消费延迟飙升 | watermark 设置不当,堆积大量数据 | 优化 timestamp assigner |
| 消费堆积 | Source 分区 < 并行度 | 合理调整 Kafka topic 分区数 |
| 偶发丢数据 | Source 没启用 checkpoint | 开启 Flink 状态管理与 checkpoint |
| 多 topic 合并处理错乱 | 不统一时间语义 / schema | 建议多 topic 做统一清洗后处理 |
九、总结与建议
✅ Kafka 消费不是"连接一下"这么简单,它是实时链路的核心压舱石 ;
✅ 好的消费链路,应具备:时间语义清晰、吞吐稳定、可扩展处理逻辑 ;
✅ 建议配合使用 KafkaSource + 自定义 Watermark + 严格的 Checkpoint 配置 实现实时链路"精确处理"。
下一篇预告
📘 《第四篇:Flink 数据清洗与字段标准化最佳实践》
将重点讲解如何在 Flink 中进行数据的解析、标准化、字典对照处理,包括:
-
JSON 解析与字段提取
-
动态维度表广播 & 缓存机制
-
基于配置的标准化处理逻辑