一、概述
GBDT(Gradient Boosting Decision Tree,梯度提升决策树)是集成学习中提升(Boosting)方法的典型代表。它以决策树(通常是 CART 树,即分类回归树)作为弱学习器,通过迭代的方式,不断拟合残差(回归任务)或负梯度(分类任务),逐步构建一系列决策树,最终将这些树的预测结果进行累加,得到最终的预测值。
二、算法原理
1. 梯度下降思想
梯度下降是一种常用的优化算法,用于寻找函数的最小值。在 GBDT 中,它扮演着至关重要的角色。假设我们有一个损失函数\(L\left( y,\hat{y} \right)\),其中\(y\)是真实值,\(\hat y\)是预测值。梯度下降的目标就是通过不断调整模型参数,使得损失函数的值最小化。具体来说,每次迭代时,沿着损失函数关于参数的负梯度方向更新参数,以逐步接近最优解。在 GBDT 中,虽然没有显式地更新参数(通过构建多颗决策树来拟合目标),但拟合的目标是损失函数的负梯度,本质上也是利用了梯度下降的思想。
2. 决策树的构建
GBDT 使用决策树作为弱学习器。决策树是一种基于树结构的预测模型,它通过对数据特征的不断分裂,将数据划分成不同的子集,每个子集对应树的一个节点。在每个节点上,通过某种准则(如回归任务中的平方误差最小化,分类任务中的基尼指数最小化)选择最优的特征和分裂点,使得划分后的子集在目标变量上更加 "纯净" 或具有更好的区分度。通过递归地进行特征分裂,直到满足停止条件(如达到最大树深度、节点样本数小于阈值等),从而构建出一棵完整的决策树。
3. 迭代拟合的过程
(1) 初始化模型
首先,初始化一个简单的模型,通常是一个常数模型,记为\(f_0(X)\) ,其预测值为所有样本真实值的均值(回归任务)或多数类(分类任务),记为\(\hat y_0\)。此时,模型的预测结果与真实值之间存在误差。
(2) 计算残差或负梯度
在回归任务中,计算每个样本的残差,即真实值\(y_i\)与当前模型预测值\(\hat y_{i,t-1}\)的差值\(r_{i,t}=y_i-\hat y_{i,t-1}\),其中表示迭代的轮数。在分类任务中,计算损失函数关于当前模型预测值的负梯度g_{i,t}=-\\frac{\\vartheta L(y_i,\\hat y_{i,t-1})}{\\vartheta \\hat y_{i,t-1}}
(3) 拟合决策树
使用计算得到的残差(回归任务)或负梯度(分类任务)作为新的目标值,训练一棵新的决策树\(f_t(X)\)。这棵树旨在拟合当前模型的误差,从而弥补当前模型的不足。
(4) 更新模型
根据新训练的决策树,更新当前模型。更新公式为\(\hat y_{i,t}=\hat y_{i,t-1}+\alpha f_t(x_i)\),其中是学习率(也称为步长),用于控制每棵树对模型更新的贡献程度。学习率较小可以使模型训练更加稳定,但需要更多的迭代次数;学习率较大则可能导致模型收敛过快,甚至无法收敛。
(5) 重复迭代
重复步骤 (2)--(4)步,不断训练新的决策树并更新模型,直到达到预设的迭代次数、损失函数收敛到一定程度或满足其他停止条件为止。最终,GBDT 模型由多棵决策树组成,其预测结果是所有决策树预测结果的累加。
算法过程图示
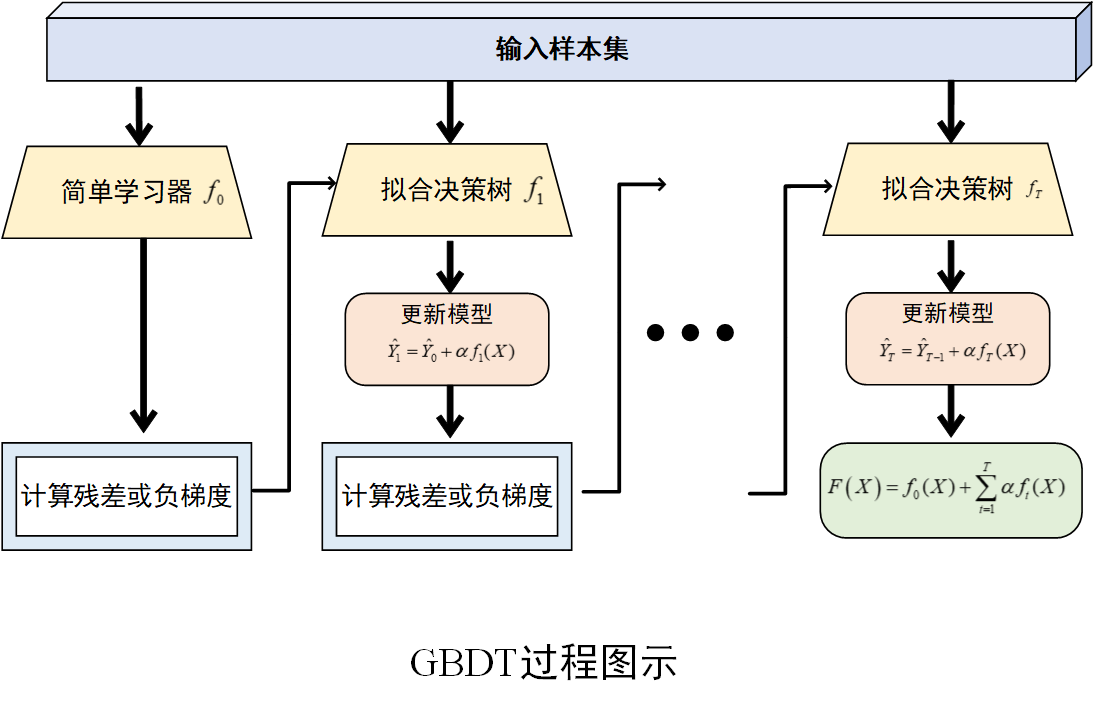
GBDT 算法将梯度下降思想与决策树相结合,通过迭代拟合残差或负梯度,逐步构建一个强大的集成模型。它在处理复杂数据和非线性关系时表现较为出色,在数据挖掘、机器学习等领域得到了广泛的应用。然而,GBDT 也存在一些缺点,如训练时间较长、对异常值较为敏感等,在实际应用中需要根据具体情况进行优化和调整 。
三、Python实现
(环境:Python 3.11,scikit-learn 1.5.1)
分类情形
python
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
from sklearn import metrics
# 生成样本数据
X, y = make_classification(n_samples=1000, n_features=50, n_informative=10, n_redundant=5, random_state=1)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# 创建GDBT分类模型
gbc = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1, random_state=1)
# 训练模型
gbc.fit(X_train, y_train)
# 进行预测
y_pred = gbc.predict(X_test)
# 计算准确率
accuracy = metrics.accuracy_score(y_test,y_pred)
print('准确率为:',accuracy)
回归情形
python
from sklearn.datasets import make_regression
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 生成样本数据
X, y = make_regression(n_samples=1000, n_features=10, n_informative=5, noise=0.1, random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建GDBT回归模型
model = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, random_state=42)
# 训练模型
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print(f"MSE: {mse}")
End.