损失函数
在深度学习中, 损失函数是用来衡量模型参数的质量的函数, 衡量的方式是比较网络输出和真实输出的差异
作用:指导模型的训练过程,通过反向传播算法计算梯度,从而更新网络的参数,最终使得模型的预测结果尽可能接近真实值。损失函数的选择对模型训练的收敛速度、效果和稳定性具有重要影响。
分类
-
回归问题
1.均方误差损失(Mean Square Error,MSE)
-
公式:
M S E = 1 N Σ i = 1 N ( y i − y ^ i ) 2 MSE = \frac{1}{N} Σ_{i=1}^N (y_{i} - ŷ_{i})^2 MSE=N1Σi=1N(yi−y^i)2 -
优点:
- 计算简单
- 对较大的误差惩罚较大,因此鼓励模型尽量减少较大的偏差。
-
缺点:
- 对离群点非常敏感,使得离群点的损失值会大大增加
2.平均绝对误差(Mean Absolute Error,MAE)
-
公式:
M S E = 1 N Σ i = 1 N ∣ y i − y ^ i ∣ MSE = \frac{1}{N} Σ_{i=1}^N |y_{i} - ŷ_{i}| MSE=N1Σi=1N∣yi−y^i∣ -
优点:
-
对离群点不那么敏感
-
缺点:
- 收敛速度慢
3.SmoothL1损失函数
SmoothL1 损失函数是一种结合了均方误差(MSE)和绝对误差(MAE)的损失函数。它在误差较小时表现得像 MSE,在误差较大时表现得像 MAE。
-
公式:
S m o o t h L 1 = { 0.5 ∗ x 2 , ∣ x ∣ < 1 ∣ x ∣ − 0.5 ∣ x ∣ ≥ 1 Smooth_{L1} = \begin {cases} 0.5*x^2 & {,|x| < 1} \\ |x| - 0.5 & {|x| \geq 1} \end{cases} SmoothL1={0.5∗x2∣x∣−0.5,∣x∣<1∣x∣≥1 -
优点:
- 解决了L2损失(MSE)的梯度爆炸的问题
- 解决L1损失的不光滑问题
-
-
分类问题
1.交叉熵损失(Cross-Entropy Loss)
-
二分类问题
- 公式:
L = 1 N Σ i = 1 N y i l o g ( y \^ i ) + ( 1 − y i ) l o g ( 1 − y \^ i ) L = \frac{1}{N} Σ_{i=1}^N y_{i}log(ŷ_{i}) +(1 - y_{i})log(1-ŷ_{i}) L=N1Σi=1Nyilog(y\^i)+(1−yi)log(1−y\^i)
-
多分类问题
- 公式:
L = − 1 N Σ i = 1 N y i l o g ( S o f t m a x ( f ɵ ( x i ) ) ) L = -\frac{1}{N} Σ_{i=1}^N y_ilog(Softmax(f_ɵ(x_i))) L=−N1Σi=1Nyilog(Softmax(fɵ(xi)))
y_i: 经过one-hot encoder后,属于x中某一类别的概率
f_ɵ(x_i):样本属于某一类的预测分数
-
梯度下降算法
梯度下降法 是一种寻找使损失函数最小化的方法 。从数学上的角度来看,梯度的方向是函数增长速度最快的方向,那么梯度的反方向就是函数减少最快的方向
通式
W i j = W i j ′ − l r ∗ ∂ E r r o r ∂ W i j W_{ij} = W^{'}{ij} - lr * \frac{∂Error}{∂W{ij}} Wij=Wij′−lr∗∂Wij∂Error
lr:学习率
反向传播算法(Back Propagation)
原理
利用损失函数Error,从后往前,结合梯度下降算法,依次对各个参数求偏导,并进行参数更新
反向传播算法举例
反向传播对神经网络中的各个节点的权重进行更新 。以一个简单的神经网络用来举例:激活函数为sigmoid
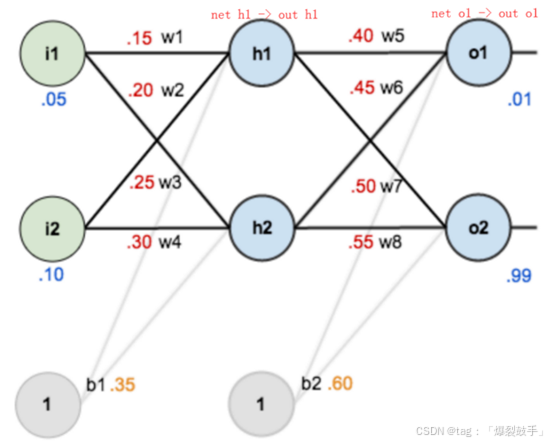
net xx: 神经元的输入值,net xx = w.T \* x +b
out xx:神经元的输出值,out xx = sigmoid(net xx)
Error:E = MSE
网络前向传播过程如下:

如何进行反向传播?
使用链式求导法则,以更新参数w5为例:
由
E t o t a l = E o 1 + E o 2 E_{total} = E_{o1} + E_{o2} Etotal=Eo1+Eo2
得
∂ E t o t a l ∂ o u t o 1 = − ( t a r g e t o 1 − o u t o 1 ) \frac{∂E_{total}}{∂out_{o1}}= -(target_{o1} - out_{o1}) ∂outo1∂Etotal=−(targeto1−outo1)
又
o u t o 1 = s i g m o i d ( n e t o 1 ) = s i g m o i d ( w 5 ∗ o u t h 1 + w 6 ∗ o u t h 2 ) out_{o1} = sigmoid(net_{o1})=sigmoid(w_5*out_{h1} + w_6*out_{h2}) outo1=sigmoid(neto1)=sigmoid(w5∗outh1+w6∗outh2)
则
∂ o u t o 1 ∂ w 5 = ∂ o u t o 1 ∂ n e t o 1 ∗ ∂ n e t o 1 ∂ w 5 = o u t o 1 ∗ ( 1 − o u t o 1 ) ∗ o u t h 1 \begin{aligned}\frac{∂out_{o1}}{∂w_5}&= \frac{∂out_{o1}}{∂net_{o1}}*\frac{∂net_{o1}}{∂w_5}\\&=out_{o1}*(1-out_{o1})*out_{h1}\end{aligned} ∂w5∂outo1=∂neto1∂outo1∗∂w5∂neto1=outo1∗(1−outo1)∗outh1
综上
∂ E t o t a l ∂ w 5 = ∂ E t o t a l ∂ o u t o 1 ∗ ∂ o u t o 1 ∂ n e t o 1 ∗ ∂ n e t o 1 ∂ w 5 \frac{∂E_{total}}{∂w_{5}}=\frac{∂E_{total}}{∂out_{o1}}*\frac{∂out_{o1}}{∂net_{o1}}*\frac{∂net_{o1}}{∂w_5} ∂w5∂Etotal=∂outo1∂Etotal∗∂neto1∂outo1∗∂w5∂neto1

pytorch中反向传播的过程
properties
1.optimizer.zero_grad()进行梯度清零
2.根据loss.backward()进行反向传播
3.使用optimizer.step()进行参数更新梯度下降的优化方法
梯度下降优化算法中,可能会碰到以下情况:
properties
1.碰到平缓区域,梯度值较小,参数优化变慢
2.碰到 "鞍点" ,梯度为 0,参数无法优化
3.碰到局部最小值,参数不是最优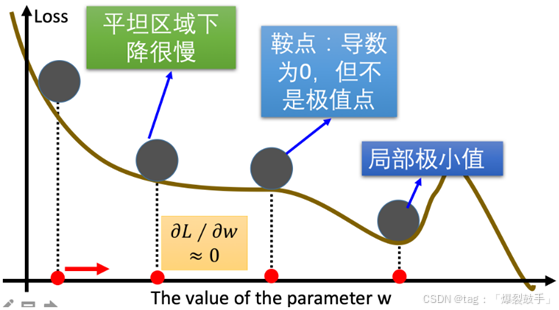
针对这些问题,出现了一些 通过优化权重系数w和学习率lr的两种主流思路 的算法
1.Momentum 动量法
思想:使用指数加权平均法优化权重w
梯度更新公式:
D t = β ∗ S t − 1 + ( 1 − β ) ∗ W t D_t = β*S_{t-1} + (1-β)*W_t Dt=β∗St−1+(1−β)∗Wt
1.Dt代表当前时刻的指数加权平均梯度值
2.St-1 表示历史梯度移动加权平均值
3.β为权重系数
4.Wt表示当前时刻的梯度值
2.AdaGrad
思想:根据历史梯度信息为每个参数动态调整学习率
AdaGrad 通过对不同的参数分量使用不同的学习率,AdaGrad 的学习率总体会逐渐减小。
其计算步骤如下:
1.初始化学习率 α、初始化参数 θ、小常数 σ = 1e-6
2.初始化梯度累积变量 s = 0
3.从训练集中采样 m 个样本的小批量,计算梯度 g
4.累积平方梯度 s = s + g ⊙ g,⊙ 表示各个分量相乘
学习率的计算公式如下:
α = α s + σ \alpha = \frac{\alpha}{\sqrt{s} + \sigma} α=s +σα
参数更新公式如下:
θ = θ − α s + σ ⋅ g \theta= \theta - \frac{\alpha}{\sqrt{s} + \sigma}\cdot{g} θ=θ−s +σα⋅g
3.RMSprop
思想:RMSProp 并不对所有历史梯度平方进行简单累加,而是采用了指数加权移动平均的方法
RMSProp优化算法是对AdaGrad的优化 . 最主要的不同是,其使用指数移动加权平均梯度替换历史梯度的平方和。其计算过程如下:
1.初始化学习率 α、初始化参数 θ、小常数 σ = 1e-6
2.初始化参数 θ
3.初始化梯度累计变量 s
4.从训练集中采样 m 个样本的小批量,计算梯度 g
5.使用指数移动平均累积历史梯度,公式如下:
s = β ⋅ s + ( 1 − β ) ⋅ g ⊙ g s = \beta \cdot s + (1-\beta)\cdot g ⊙ g s=β⋅s+(1−β)⋅g⊙g
学习率 α 的计算公式如下:
α = α s + σ \alpha = \frac{\alpha}{\sqrt{s} + \sigma} α=s +σα
参数更新公式如下:
θ = θ − α s + σ ⋅ g \theta= \theta - \frac{\alpha}{\sqrt{s} + \sigma}\cdot{g} θ=θ−s +σα⋅g
4.Adam
Adam(Adaptive Moment Estimation)算法 是一种广泛使用的自适应学习率优化算法,它结合了动量(Momentum)和 RMSProp 的思想,用于加速梯度下降过程,特别适用于深度学习等大规模参数优化问题。
核心思想
Adam 算法通过为每个参数维护两个估计量:
- 一阶矩估计(梯度的均值):捕捉梯度的方向信息,相当于动量机制。
- 二阶矩估计(梯度平方的均值):捕捉梯度的幅度信息,用于对学习率进行自适应调整。
这两个估计量帮助算法根据历史梯度的信息自动调整每个参数的更新步长,从而既能利用梯度的方向(动量)加速收敛,又能根据梯度的大小(自适应学习率)防止参数更新过大或过小。
算法步骤
设定目标函数为 J(θ) 需要优化的参数为 θ,在每次迭代中计算梯度 gt=∇θ*J(θt)
Adam 算法的具体更新步骤如下:
-
初始化
设置初始参数 θ,并初始化:
m 0 = 0 , v 0 = 0 , t = 0 m_0=0,v_0=0,t=0 m0=0,v0=0,t=0同时设定超参数:
- 学习率 η(通常如 0.001)
- 一阶矩衰减率 β1(常取值为 0.9)
- 二阶矩衰减率 β2(常取值为 0.999)
- 防止除零的小常数 ϵ(例如 10^−8)
-
梯度与矩估计更新
对于每一次迭代 t=1,2,...,进行以下更新:
-
更新一阶矩(梯度均值)的指数加权平均:
m t = β 1 ∗ m t − 1 + ( 1 − β 1 ) ∗ g t m_t = \beta_1*m_{t-1} + (1 - \beta_1)*g_t mt=β1∗mt−1+(1−β1)∗gt
-
更新二阶矩(梯度平方均值)的指数加权平均:
v t = β 2 ∗ v t − 1 + ( 1 − β 2 ) ∗ g t 2 v_t = \beta_2*v_{t-1} + (1 - \beta_2)*g_t^2 vt=β2∗vt−1+(1−β2)∗gt2
-
-
偏差修正
由于 m0 和 v0 初始化为零,在初期估计会存在偏差。为了校正这一偏差,进行以下计算:
m ^ t = m t 1 − β 1 t , v ^ t = v t 1 − β 2 t \hat{m}_t = \frac{m_t}{1 - \beta_1^t}, \quad \hat{v}_t = \frac{v_t}{1 - \beta_2^t} m^t=1−β1tmt,v^t=1−β2tvt -
参数更新
最后使用修正后的矩估计更新参数:
θ t + 1 = θ t − η m ^ t v ^ t + ϵ \theta_{t+1} = \theta_t - \eta \frac{\hat{m}_t}{\sqrt{\hat{v}_t} + \epsilon} θt+1=θt−ηv^t +ϵm^t
0,v_0=0,t=0
$$
同时设定超参数:
- 学习率 η(通常如 0.001)
- 一阶矩衰减率 β1(常取值为 0.9)
- 二阶矩衰减率 β2(常取值为 0.999)
- 防止除零的小常数 ϵ(例如 10^−8)
-
梯度与矩估计更新
对于每一次迭代 t=1,2,...,进行以下更新:
-
更新一阶矩(梯度均值)的指数加权平均:
m t = β 1 ∗ m t − 1 + ( 1 − β 1 ) ∗ g t m_t = \beta_1*m_{t-1} + (1 - \beta_1)*g_t mt=β1∗mt−1+(1−β1)∗gt
-
更新二阶矩(梯度平方均值)的指数加权平均:
v t = β 2 ∗ v t − 1 + ( 1 − β 2 ) ∗ g t 2 v_t = \beta_2*v_{t-1} + (1 - \beta_2)*g_t^2 vt=β2∗vt−1+(1−β2)∗gt2
-
-
偏差修正
由于 m0 和 v0 初始化为零,在初期估计会存在偏差。为了校正这一偏差,进行以下计算:
m ^ t = m t 1 − β 1 t , v ^ t = v t 1 − β 2 t \hat{m}_t = \frac{m_t}{1 - \beta_1^t}, \quad \hat{v}_t = \frac{v_t}{1 - \beta_2^t} m^t=1−β1tmt,v^t=1−β2tvt -
参数更新
最后使用修正后的矩估计更新参数:
θ t + 1 = θ t − η m ^ t v ^ t + ϵ \theta_{t+1} = \theta_t - \eta \frac{\hat{m}_t}{\sqrt{\hat{v}_t} + \epsilon} θt+1=θt−ηv^t +ϵm^t