基本概念
分布式调用链标准-openTracing
Span-节点组成跟踪树结构
有一些特定的变量,SpanName SpanId traceId spanParentId
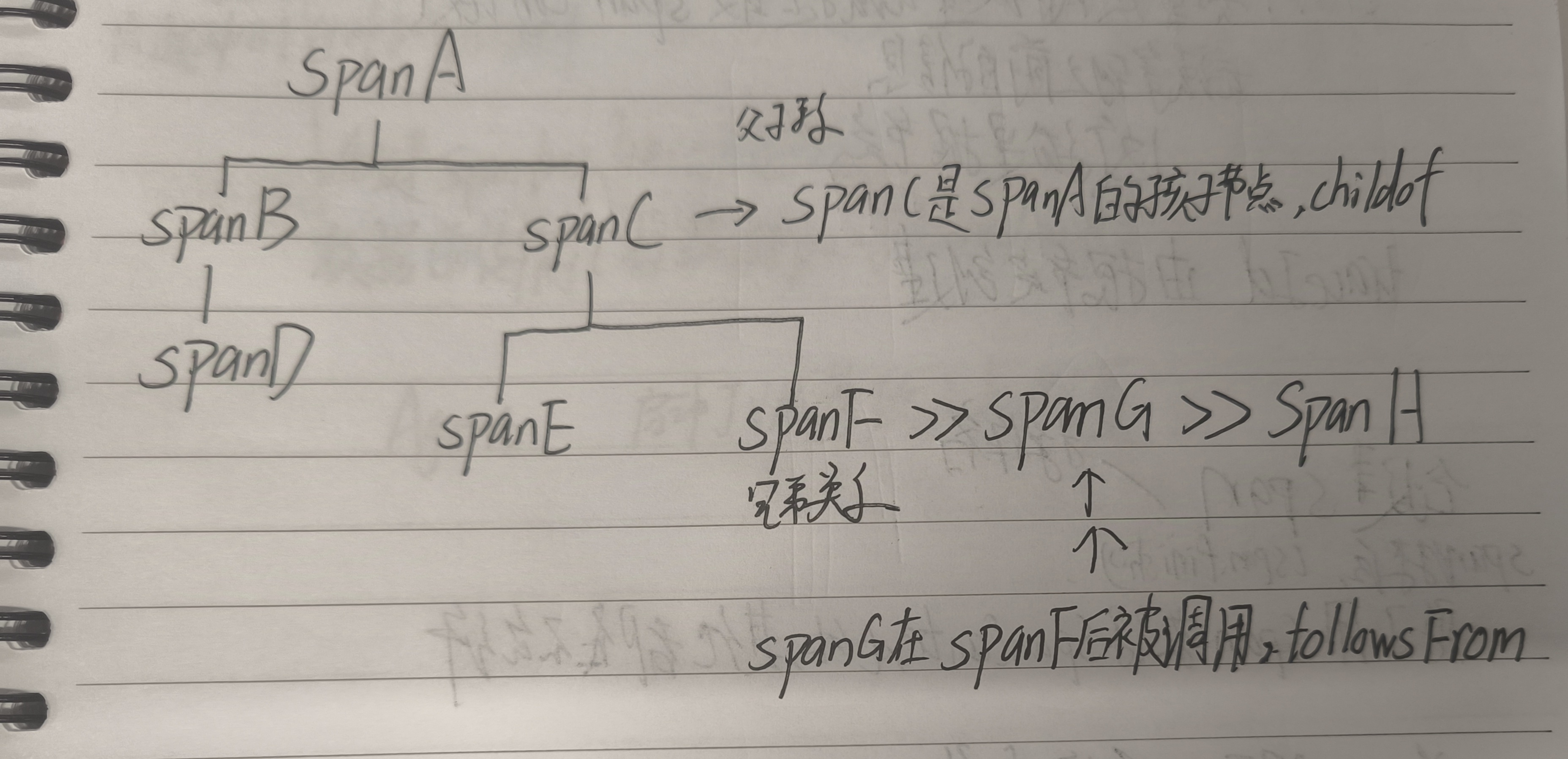
Trace(追踪) :代表一个完整的请求流程(如用户下单),由多个Span组成
Span(跨度) :请求经过的单个服务或操作(如订单服务调用支付服务)
包含:开始/结束时间、服务名、调用关系等
Context(上下文):传递Trace ID、Span ID等,确保链路连续
分布式链路追踪 = Trace ID串联全局 + Span记录局部 + 上下文传递
Span节点必须包含的内容
OperationName:操作名称
BeiginTime:开始时间
EndTime:结束时间
SpanTag:是一组键值对 构成的Span的标签集合(key必须是String类型,value可以是String,Boolean和数字类型),这个的目的是为Span添加更多的描述信息
SpanLog:一组Span的日志集合 ,是键值对,记录日志信息
SpanContext:是一个上下文对 象,会从上一个节点传递到下一个节点,里面包含了traceId ,SpanId ,Baggage (这是一个跨Span集合 ,上一个节点往Baggage加信息下一个节点可以拿到,不要放太多信息不然会导致占用空间大影响效率),我们通过上下文对象去进行 跨进程 传递
TraceSegment和TraceId原理
TraceSegment:
- 指的是一个进程中所有的Span的集合
- 如果多个线程协同产生同一个Trace(例如多个RPC调用不同的方法),它们只会共同创建一个TraceSegment
- 支持多入口,所以Skywalking去除了树节点RootSpan的概念,提出了三种Span模型
TraceId:
- TraceId应该是全局唯一的
- 我们的TraceId是根据时间错+算法生成的,所以会有时间回拨问题
- 我们有个变量lastTimeStamp保存上次TraceId生成的时间,然后在生成TraceId前进行比较,如果CuurentTimeMills比lastTimeStamp时间小,说明时间回拨了,我们就不生成Id,这样来保证TraceId全局唯一
概念简单总结
三个基本概念:Trace追踪,Span服务,Context上下文(用来传递信息)
分布式链路追踪 = Trace ID串联全局 + Span记录局部 + 上下文传递
Span中包含starTime,endTime,SpanContetx(上下文用来传递信息,包含TraceId,SpanId),
SpanTag(服务的标签),SpanLog(服务的日志信息)
TraceSegment(追踪段):一个进程中所有的Span的集合
TraceId:全局唯一,依赖时间戳,保存上次TraceId生成的时间,生成ID时时间戳进行对比,防止时间回拨问题
全链路追踪的工作流
阶段1:链路数据生成(埋点)
自动埋点:通过SDK或Agent自动在服务框架(如Spring Cloud、Dubbo)中注入追踪逻辑。
手动埋点:在业务代码中手动标记关键操作(如支付流程)。
示例:用户下单时,网关生成Trace ID=ABC,创建根Span(Span ID=1)
阶段2:链路数据采集与传输
采集方式 :通过Agent或Sidecar(如Envoy)实时收集Span数据。
传输协议:通过gRPC、HTTP等将数据发送到Collector(如Jaeger Collector)。
示例:订单服务(Span ID=2)和库存服务(Span ID=3)的Span通过Kafka发送到收集器。
阶段3:链路数据存储
存储后端:使用时序数据库(如InfluxDB)、列式存储(如Cassandra)或Elasticsearch。
数据模型:按Trace ID聚合Span,建立索引(如服务名、耗时、错误码)。
示例:Trace ID=ABC的所有Span被存储为一条完整链路。
阶段4:数据查询与分析
可视化 :通过UI工具(如Zipkin、SkyWalking)展示火焰图、调用拓扑。
分析能力:支持按服务名、耗时、错误码过滤,自动统计P99延迟、错误率。
示例:发现库存服务(Span ID=3)平均耗时500ms,触发告警
流程简单总结
- 链路数据生成:在进入Span服务前生成数据,一般来说再进入服务器会有自定义数据处理or服务启动前的Agent增强让服务有了多余的自定义逻辑
- 实时采集与传输链路数据:通过Http或者grpc采集和传输链路追踪的数据
- 链路数据存储:存储链路追踪的数据
- 数据查询与分析可视化:通过可视化页面展示详细的链路追踪流程和数据,显示服务细节,耗时,错误等