灵魂拷问: redis 为什么块?
- 纯内存访问
- 单线程避免上下文切换
- 渐进式ReHash , 缓存时间戳
Redis 的 key 和 value组织结构:
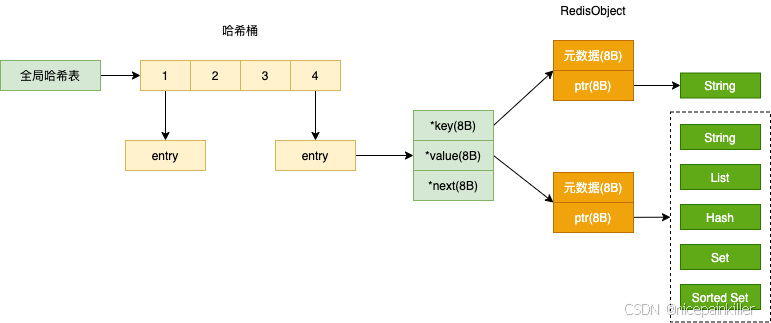
全局哈希表:
为了实现从键到值的快速访问。 redis 使用了一个哈希表 来保存所有键值对。一个哈希表 其实就是一个数组。数组的每个元素称为一个哈希桶。所以 我们常说 一个哈希表是有多个哈希桶组成。每个哈希桶中保存了键值对数据。
什么是 Redis 渐进式 ReHash
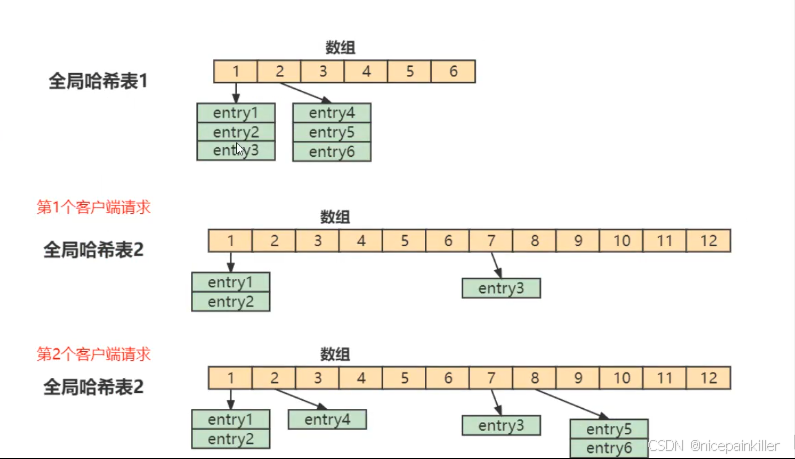
Redis 的 渐进式 ReHash(Progressive ReHashing)是 Redis 在处理哈希表(Hash Table)动态扩容或缩容时采用的一种优化机制。Redis 的哈希表用于存储键值对(如字典、哈希对象等),当哈希表的负载因子(load factor)过高或过低时,需要调整哈希表的大小(即扩容或缩容)。渐进式 ReHash 是一种分步、逐步迁移数据的方式,而不是一次性将所有数据从旧哈希表迁移到新哈希表。
核心机制:
- Redis 维护两个哈希表:
ht[0](旧表)和ht[1](新表)。- 当触发 ReHash 时,Redis 创建一个更大的(或更小的)新哈希表
ht[1],并将数据从ht[0]逐步迁移到ht[1]。- 迁移过程通过 渐进式操作 分摊到每次读写操作中,而不是一次性完成。
- Redis 使用一个
rehashidx指针记录当前迁移的桶(bucket)位置,逐步将ht[0]的桶迁移到ht[1]。- 迁移期间,Redis 会同时查询
ht[0]和ht[1],确保数据访问无中断。- 迁移完成后,
ht[1]成为新的主哈希表,ht[0]被清空并释放。触发条件:
- 扩容:当哈希表的负载因子(键数量/桶数量)超过阈值(默认 1.0,且无后台保存任务;或 5.0,若有后台保存任务)时触发。
- 缩容:当负载因子过低(如低于 0.1)时触发,以节省内存。
示例场景
假设 Redis 存储了一个包含 100 万键的哈希表:
- 一次性 ReHash:需要一次性将 100 万键重新计算哈希并迁移,可能导致数百毫秒甚至秒级的阻塞。
- 渐进式 ReHash:每次操作迁移 1-10 个键,100 万键分摊到多次操作中,可能只需几秒到几十秒完成,单次操作延迟仅增加微秒级。
注意事项
- ReHash 性能影响:虽然渐进式 ReHash 极大降低了阻塞风险,但在极端高并发场景下,频繁触发 ReHash 可能仍会带来轻微性能波动。
- 监控 ReHash :通过
INFO MEMORY命令查看rehashidx值,判断是否正在进行 ReHash(非 -1 表示进行中)。- 优化策略 :合理设置初始哈希表大小或负载因子阈值(通过
hash-max-ziplist-entries或activerehashing配置),减少不必要的 ReHash。
缓存时间戳
redis 为什么要缓存系统时间戳?
我们平时使用系统时间戳时,都是直接调用系统函数 直接获取时间戳。redis 不是这样的。因为 每一次获取系统时间戳都 一次系统调用。相对耗时。作为 高性能的 redis是承受不起的。所以它 采用定时任务来获取系统时间 每毫秒更新一次。 需要获取时间戳直接从缓存中拿。
Redis 处理缓存过期主要通过两种机制:
惰性删除:
惰性删除是指 Redis 只有在访问一个键(比如
GET、SET等操作)时,才会检查该键是否已过期。如果键已过期,Redis 会立即删除该键,并返回空(对客户端来说就像键不存在)
- 优点 :
- 节省 CPU 资源,只有在必要时才执行删除操作。
- 适合访问频率较高的场景,过期键能被及时清理。
- 缺点 :
- 如果某些键长期不被访问,过期键可能占用内存,直到被定期删除或其他机制清理。
定期删除:
Redis 会定期(后台)扫描数据库中的键,随机抽样检查部分键的过期状态,并删除已过期的键
- 优点 :
- 能清理不常访问的过期键,防止内存浪费。
- 扫描是分批进行的,不会一次性占用过多 CPU。
- 缺点 :
- 随机抽样可能漏掉一些过期键,导致内存清理不彻底。
- 高负载下,定期删除可能不够及时
redis 6.0 之前为什么一直不使用多线程
- 在使用redis 过程中 cpu 一直不是瓶颈。受制于 内存 和 网络
- 提高Redis, Pipeline(命令批量处理) 每秒 100万请求
- 单线程内部维护简便 高效
redis 6.0 之后为什么引入了多线程
中小型项目 单线程就够了,
大的项目中 为了更大的性能。IO 采用了多线程 。(内部执行指令 还是寺单线程)
redis 为什么没有采用 分布式架构 ---(不足)
1. 服务器数量多 增加维护成本 2. redis命令 不适用 数据分区 3. 数据分区 无法解决热点 读/写 的问题 4. 会出现数据倾斜的问题 重新分配 扩容 缩容开启 IO 多线程。同步 IO 读写中的负载
redis 6.0 有哪些高级功能
redis慢查询:
许多存储系统如 mysql 提供慢查询日志 帮助开发运维人员定位系统存在的慢操作。所谓慢查询日志就是 系统在命令执行前后计算每条命令的执行时间。当超过预设值时 就将这条命令相关信息(例如 发生事件 耗时 命令的详细信息) 记录下来 redis 也提供类似功能
redis 客户端执行一条命令 分为如下 4个 部分:
pipeline
Redis 的 Pipeline 和 事务 都是用于优化多个命令的执行方式,但它们的用途、机制和适用场景有显著差异。以下是详细对比:
- pipeline是客户端的行为,对于服务器来说是透明的,可以认为服务器无法区分客户端发送来的查询命令是以普通命令的形式还是以pipeline的形式发送到服务器的;
- Pipeline 是一种客户端与服务器的通信优化技术,允许客户端将多个命令打包成一个请求发送到服务器,服务器执行后一次性返回所有结果。
- 它主要减少客户端与服务器之间的网络往返(RTT,Round-Trip Time),提高吞吐量
- Pipeline 不保证原子性 (当),命令之间没有隔离性。当通过pipeline提交的查询命令数据较少,可以被内核缓冲区所容纳时,Redis可以保证这些命令执行的原子性。然而一旦数据呈过大,超过了内核缓冲区的接收大小,那么命令的执行将会被打断,原了性也就无法得到保证。因此pipeline只是一种提升服务器吞吐能力的机制,如果想要命令以事务的方式原了性的被执行,还是需要事务机制,或者使用更高级的脚本功能以及块功能。
事务
redis 事务 本身是一个弱事务功能。结合 lua 脚本可以 做事务
lua
Redis 支持通过 Lua 脚本执行复杂的服务器端逻辑,将多个操作封装为单个脚本运行。
优势:
原子性执行 Lua 脚本在 Redis 中以 原子性 方式执行
**减少网络开销,**Lua 脚本将多条 Redis 命令的逻辑集中在服务器端执行
强大的逻辑处理能力
高性能
劣势:
- 调试困难
- 性能开销虽然 Lua 脚本本身高效,但复杂的脚本(大量循环、计算或数据操作)可能显著增加 Redis 服务器的 CPU 负载
- **阻塞 Redis 实例,**Redis 是单线程的,Lua 脚本执行期间会独占线程,导致其他命令排队等待
redis 于 memcached 相对有那些优势
|--------|---------------------------------------------|------------------|
| | redis | memcached |
| 整体类型 | 1.内存数据库 2.非关系数据库 | 1.内存 2.key-value |
| 数据类型 | 1.string 2.hash 3.list 4.set 5.zset 6.等等 | 1.string 2.二进制 |
| 操作类型 | 1.单个操作 2.批量操作 3.事务 若事务结合lua 4.每种类型有不同的 curd | 1.curd 2.少量命令 |
| 附加功能 | 1.发布、订阅 2.主从 高可用 集群 3.序列化 4.支持lua | 1.多线程的支持 |
| 网络IO模型 | 1.执行命令 单线程 2.网络IO操作 多线程 | 1.多线程, 非阻塞IO模型 |
| 持久优化 | 1.RDB 2.AOF | 不支持 |
[redis 和 memcached差别]
redis的过期策略和内存淘汰机制
Redis 所有数据结构都会设置过期时间,redis会将每个设置了过期时间的 key 放到一个独立的字典中。以后会定时遍历这个字典来删除到期的key, 除了定时遍历以外。它还会使用 惰性策略来删除定期的 key, 所谓惰性策略就是在客户端访问这个 key 的时候, redis 对 key 的过期时间进行检查。如果过期立即删除。定时删除是集中处理的, 惰性删除是零散处理的。
定时扫描策略:
Redis 默认会每秒进行10次过期扫描,过期扫描不会遍历过期 字典中所有的 key, 而是采用一种贪心策略:
- 从过期字典中随机 20 key
- 删除这 20 个key 中已经过期的 key
- 如果过期的key 超过 1/4,则重复 步骤1
redis 会持续扫描过期字典,直到过期字典中的 key 变的稀疏,才会停止。这就会导致线上读写请求出现了明显卡顿现象, 导致这种卡顿的另一个原因就是 内存管理器 需要频繁回收。这样也会消耗 CPU. 这就要求开发人员一定要注意过期时间,如果有大批量key 同时过期。要给过期时间加上随机范围,从而避免在同一时间 大批量 key 失效
从库的过期策略:从库不会进行过期扫描。从库对过期的处理是被动的。主库在 key 到期,会在 AOF 文件中添加一条 del 指令, 同步到所有从库中 从库通过这条指令删除过期的key 。 应为指令是异步进行的,所以主库过期的key 的 del 指令 有可能 会没有同步到从库,这就会出现数据不一致的情况。主库不存在 而 从库 存在
惰性删除:
就是在客户端访问这个 key 的时候,redis 对这个 key的过期时间进行检查, 如果 过期了就立即删除。不会给你返回任何东西
总结:
定期删除可能会导致很多 过期的 key 已经到期了却没有被删除,所有就有了惰性删除,假如你的key 过期了却没有被删除,可以通过 惰性删除立即删除掉; 定期删除的是集中处理,惰性删除是 零散的处理
缓存淘汰算法:
当 redis 内存 超出 物理内存限制的时候, 内存的数据会开始和磁盘产生频繁的交互(swap)交互会让 redis 的性能急剧下降,对于访问频繁的 redis 来说 这样的速度是不能被接受的
Redis 的缓存淘汰算法由
maxmemory-policy配置项控制,当内存使用量达到maxmemory限制时,Redis 会根据指定的淘汰策略移除键
- noeviction(不淘汰)
- volatile-lru(对设置了过期时间的键使用 LRU)
- volatile-lfu(对设置了过期时间的键使用 LFU)
- volatile-random(对设置了过期时间的键随机淘汰)
- volatile-ttl(优先淘汰剩余存活时间短的键)
- allkeys-lru(对所有键使用 LRU)
- allkeys-lfu(对所有键使用 LFU)
- allkeys-random(对所有键随机淘汰)
算法对比:
算法 目标键范围 淘汰依据 适用场景 缺点 noeviction 无 不淘汰 数据持久化,内存充足 内存满后写入失败 volatile-lru 有过期时间的键 最近最少使用 混合持久化和缓存场景 需设置 TTL,近似 LRU 不够精确 volatile-lfu 有过期时间的键 最不经常使用 热点数据频繁访问 需设置 TTL,LFU 计数器有开销 volatile-random 有过期时间的键 随机 数据重要性均匀,性能敏感 随机性可能误删重要数据 volatile-ttl 有过期时间的键 剩余存活时间最短 临时缓存,明确生命周期 需设置 TTL,可能误删高频数据 allkeys-lru 所有键 最近最少使用 纯缓存场景 可能淘汰重要数据 allkeys-lfu 所有键 最不经常使用 热点数据优先保留 LFU 计数器开销,历史数据可能滞留 allkeys-random 所有键 随机 数据无明显模式,性能敏感 随机性可能误删高价值数据
是什么事缓存穿透?如何避免?
以数据库作为兜底方案的数据查询,当有大量请求没有走 redis,直接访问数据库的时候,会把 数据库CPU 打爆 。可以使用 布隆过滤器 判断 用户是否在存在, 若不存在 直接返回
什么是缓存雪崩?如何避免
通常用户通过 redis 作为缓存,数据库作为兜底方案的时候 缓存雪崩发生在一下情况
- redis 宕机失效 或者 cpu 跑满, 访问会直接请求到 数据库。数据库会奔溃。 引入集群 redis 高可用
- redis 中大量key 集中过期,这种情况下 也会有大量请求到数据库。设置过期时间加上随机值
redis 如何使用分布式锁
redis分布式锁的最简单的实现:
想要实现分布式锁, 必须要求 redis 有 互斥的能力,我么可以使用 setnx 命令,这个命令就是 set if not exists, 即 如果 key 不存在, 才会设置它的值 否则什么也做不了
- 防止死锁,加完锁 没有正常释放, 可以添加过期时间
- 过期时间不好评估,若执行逻辑期间 锁已经释放了。分布式锁就会失效。
- 分布式锁加入 看门(守护线程) ,如果锁要过期了 操作还未完成 那么就会对锁进行 续期,重新设置过期时间