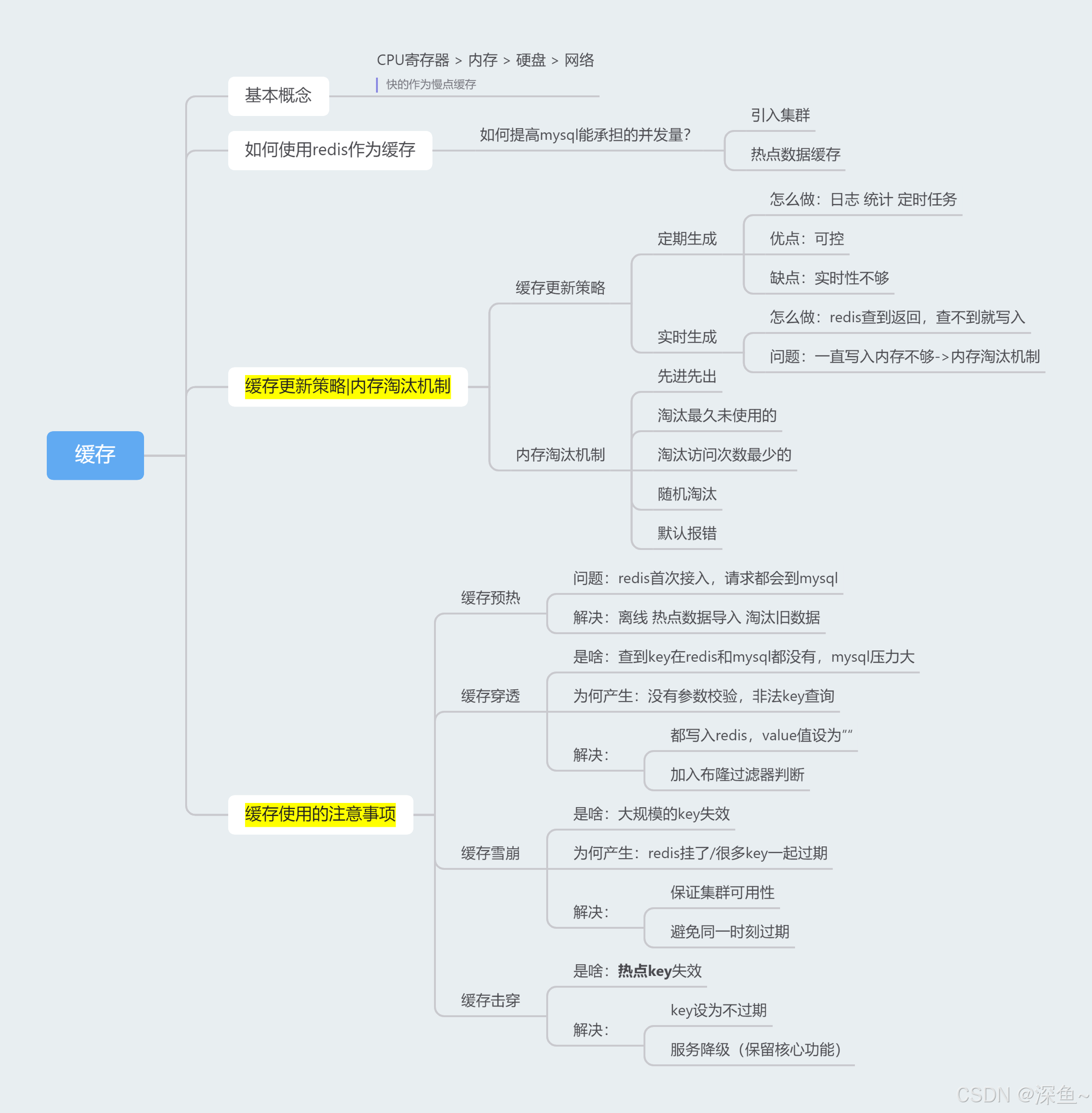
思维导图:
Redis最主要的用途,三个方面:
1.存储数据(内存数据库)
2.缓存(redis最常用的场景)
3.消息队列
一、什么是缓存
我们知道对于硬件的访问速度来说,通常情况下:
CPU寄存器 > 内存 > 硬盘 > 网络
速度快点设备,可以作为速度慢的设备的缓存
最常见的就是使用 内存 作为 硬盘 的缓存(redis定位)
同样硬盘也可作为网络的缓存,比如浏览器的缓存,浏览器通过http/https从服务器上(网络)获取到数据(html,css,图片,视频,音频...)并进行展示,像图片这种比较大,又不太改变的数据,就可以保存到浏览器本地(浏览器所在的主机硬盘上),后续打开这个页面,就不必重新从网络获取上述数据了
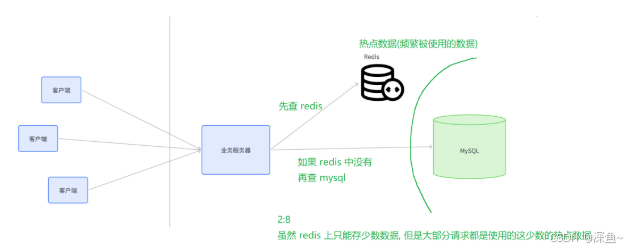
🍞二八定律
20%的数据,可以应对80%的请求
因此只需要把这少量的热点数据缓存起来,就可以应对⼤多数场景,从⽽在整体上有明显的性能提升
二、使用Redis作为缓存
通常是使用redis作为数据库的缓存(mysql),因为数据库是非常重要的组件,并且mysql的速度又比较慢,所以可以使用redis作为mysql的缓存
🍞为什么关系型数据库性能不高?
(1)数据存储在硬盘上,硬盘IO速度很慢,尤其是随机访问
(2)如果查询不能命中索引,就需要全表变量
(3)对SQL执行会做一系列的解析,校验,优化工作
(4)如果是复杂查询,需要进行笛卡尔积操作,效率更低
1和2属于硬件,3和4属于软件,因为mysql等数据库,效率比较低,所以承担的并发量有限,一旦请求多了,数据库压力就很大,甚至就容易宕机了(服务器每次处理应一个请求,一定都要消耗一些硬件资源CPU,内存,硬盘这些,任意一种资源的消耗超出了机器能提供的上限,机器就很容易出现故障
如何提高mysql能承担的并发量?
(1)开源:引入更多的机器,构成数据库集群
(2)节流:引入缓存,把一些频繁读取的热点数据,保存到缓存上,后续在查询数据的时候,如果缓存中已经存在,就不用访问mysql了
三、📚缓存的更新策略
**引入:**如何知道redis中应该存哪些数据呢/如何知道哪些数据是热点数据呢
📚缓存的更新策略:
1.定期生成
怎么做: 把访问的数据,以日志 的形式记录下来,此处的数据,就可以根据当前这里统计 的维度,来定期更新(比如按照天级别统计,就每天更新一次),写一套离线的流程(往往使用shell,python写脚本),可以通过定时任务来触发
eg:搜索引擎为例子
a)完成统计热词的过程
b)根据热词,找到搜索结果的数据(广告数据)
c)把得到的缓存数据同步到缓存服务器上
d)控制这些缓存服务器自动重启
优点:可控(缓存中有啥比较固定),方便排查问题
缺点:实时性不够,如果出现突发热点事件(比如:"春节晚会"这几天才会搜索),有一些本来不是热词的内容,变为了热词,新的热词就可能给后面的数据库带来较大的压力
2.实时生成
怎么做:
(1)如果在Redis查到了,就直接返回
(2)如果Redis中不存在,就数据库中查,把查到的结果同时也写入redis
存在的问题: 经过一段时间的动态平衡,redis中的key就逐渐都成了热点数据,这样不同的写redis,就会使redis的内存占用越来越多,逐渐达到内存上限(这个上限可以配置的maxmemory参数设定),此时如果继续往里面插入数据,就会触发问题
解决:
📚内存淘汰策略
(1)FIFO(First In First Out)先进先出:把缓存中存在时间最久的(也就是先来的数据)淘汰掉
(2)LRU(Least Recently Used)淘汰最久未使用的:记录每个key都最近访问时间,把最近访问时间最老的key淘汰掉
(3)LFU(Least Frequently Used)淘汰访问次数最少的:记录每个key最近一段时间的访问次数,把访问次数最少的淘汰掉
(4)Random 随机淘汰:从所有的 key 中抽取幸运⼉被随机淘汰掉
redis中有个配置,就可以设置redis采取上述哪种策略淘汰内存数据,具体采用哪种,结合实际场景来具体问题具体分析
其实还可以细分 :针对设置了过期时间的key (设置了过期时间都算,包括过期时间还没到的)淘汰/在所有key中淘汰【FIFO没有针对所有key,因为可能对于一些没有设置过期时间的key,是没有保存设置时间的】

四、缓存预热、缓存穿透、缓存雪崩和缓存击穿
1.缓存预热(Cache preheating)
问题: 缓存中的数据,是定期生成/实时生成的,对于定期生成这种情况是不涉及"预热"的,而对于实时生成,redis服务器首次接入之后,服务器里面是没有数据的。此时所有的请求都会打到mysql上
解决: 缓存预热就是来解决上述问题的,把定期生成 和 实时生成结合一下,先通过离线 的方式,通过一些统计的途径,先把热点数据找到一批,导入到redis 中,此时导入的这批热点数据,就能帮助mysql承担很大的压力了,随着时间的推移,逐渐就使用新的热点数据淘汰旧的数据
2.📚缓存穿透(Cache penetration)
是啥:
查询的某个key,在redis中没有,mysql也没有,这次查询没有,下次查也没有,如果这样的数据,存在很多,并且还反复查询,一样也会给mysql带来很大的压力
为何产生:
(1)业务设计不合理,比如缺少必要的参数校验环节,导致非法的key也被查询了【典型】
(2)开发/运维误操作,不小心把部分数据从数据库上误删了
(3)黑客恶意攻击
解决:
(1)如果发现这个key,在redis和mysql都不存在,仍然写入redis,value值设为非法值(比如"")
(2)引入布隆过滤器,每次查询redis/mysql之前都先判定一下key是否在布隆过滤器存在(把所有的key都插入到布隆过滤器中)
(3)通过改进业务/加强监控报警
3.📚缓存雪崩(Cache avalanche)
是啥:
由于在短时间内,redis上大规模的key失效,导致缓存命中陡然下降,并且mysql的压力迅速上升,甚至直接宕机
为何产生:
(1)redis直接挂了(redis宕机/redis集群环境下大量节点宕机)
(2)redis好着,但是可能之前短时间内设置了很多key 给redis,并且设置的过期时间是相同的
解决:
(1)加强监控报警,加强redis集群可用性的保证
(2)不给key设置过期时间/设置过期时间的时候添加随机的因子(避免同一时刻过期)
4.📚缓存击穿(Cache breakdown)
是啥: 相当于缓存血崩的特殊情况,针对热点key,突然过期了,导致大量的请求直接访问到数据库上,甚至引起数据库宕机【热点key访问频率高,影响更大】
解决:
(1)基于统计的方式发现热点key,并设置永不过期
(2)服务降级(适当关闭一些不重要的功能,只保留核心功能),比如访问数据库的时候使⽤分布式锁,限制数据库的访问频率