
本文提出了一种基于机器学习的智能嗅探机制,革新性地应用于自动判定动态渲染页面中AJAX加载的最佳触发时机。系统架构采用先进模块化拆解设计,由请求分析模块、机器学习判定模块、数据采集模块和文件存储模块四大核心部分构成。在核心代码示例中,创新性地调用了微博热搜接口(https://weibo.com/ajax/statuses/hot_band)进行榜单获取,并通过评论接口(https://weibo.com/ajax/statuses/buildComments)抓取评论数据。在数据采集全流程中,采用前沿爬虫代理技术(示例域名、端口、用户名、密码)实现高效IP切换,并智能设置Cookie与User-Agent以精准模拟真实浏览器访问。
机器学习判定模块在技术实现上取得重大突破,成功借鉴AjaxRacer对AJAX事件竞争的先进检测方法,并结合动态页面状态变化的复杂特征进行智能触发条件预测,有效提升了动态页面加载效率与用户体验,为微博热搜等动态网页的内容快速呈现提供了有力技术支持,同时也为新闻热点的快速传播与信息获取开辟了新的技术路径。
系统架构图

模块功能介绍
1. 请求分析模块
- 功能:对目标页面HTML进行解析,提取潜在的AJAX请求端点和参数集合。
- 实现要点 :
- 使用
BeautifulSoup或lxml提取页面中带有xhr、ajax等关键词的脚本片段。 - 预处理接口列表,封装为统一的请求描述对象。
- 使用
2. 机器学习判定模块
- 功能:基于历史抓取数据和页面状态变化特征,判定何时发送AJAX请求以获得完整数据。
- 核心思路 :
- 参考AjaxRacer对AJAX事件竞争的检测方法,通过动态分析和轻量级执行判断潜在的race条件。
- 利用机器学习模型(例如随机森林、LightGBM)对请求特征(URL长度、触发元素类型、状态码分布等)进行二分类预测 。
- 外部依赖 :
scikit-learn、joblib
3. 数据采集模块
- 功能:根据判定结果发起HTTP请求,具体抓取微博热搜榜单及对应评论。
- 实现要点 :
(1) 代理IP :使用亿牛云爬虫代理,示例域名yiniu.proxy.com、端口12345、用户名your_username、密码your_password。
(2) 请求头 :设置Cookie(从浏览器复制或登录后抓取)和自定义User-Agent,模拟真实用户行为 。
(3) 热搜接口:
python
url_hot = "https://weibo.com/ajax/statuses/hot_band"
resp = session.get(url_hot, headers=headers, proxies=proxies)
hot_list = resp.json()["data"]["band_list"](4) 评论接口:
python
comments_url = "https://weibo.com/ajax/statuses/buildComments"
params = {
"is_reload": 1,
"id": item_id,
"count": 20
}
resp_cmt = session.get(comments_url, headers=headers, params=params, proxies=proxies)
comments = resp_cmt.json().get("data", {}).get("comments", [])4. 文件存储模块
- 功能:将抓取到的热搜及评论数据按时间戳存储为JSON或CSV文件,便于后续分析。
- 实现要点 :
- 使用
json模块序列化,或调用pandas.DataFrame.to_csv()导出CSV。 - 目录结构示例:
- 使用
plain
data/
hot_search_YYYYMMDD_HHMMSS.json
comments_YYYYMMDD_HHMMSS.csv关键代码详解
python
import requests, json, time
from sklearn.externals import joblib
# ################ 环境准备 ################
# 亿牛云爬虫代理配置信息 www.16yun.cn
PROXY_HOST = "proxy.16yun.cn"
PROXY_PORT = "8100"
PROXY_USER = "16YUN"
PROXY_PASS = "16IP"
proxies = {
"http": f"http://{PROXY_USER}:{PROXY_PASS}@{PROXY_HOST}:{PROXY_PORT}",
"https": f"http://{PROXY_USER}:{PROXY_PASS}@{PROXY_HOST}:{PROXY_PORT}"
}
# Cookie与User-Agent设置
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)...",
"Cookie": "YOUR_WEIBO_COOKIE"
}
# ################ ML判定模块 ################
# 加载预训练模型(需提前线下训练并保存)
model = joblib.load("ajax_trigger_model.pkl")
def should_fire_ajax(feature_dict):
"""基于特征字典预测是否触发AJAX请求"""
feature_vec = [feature_dict[k] for k in sorted(feature_dict)]
return model.predict([feature_vec])[0] == 1
# ################ 数据采集流程 ################
session = requests.Session()
session.proxies.update(proxies)
session.headers.update(headers)
# 1. 获取热搜榜单
hot_url = "https://weibo.com/ajax/statuses/hot_band"
resp = session.get(hot_url)
hot_list = resp.json()["data"]["band_list"]
results = []
for item in hot_list:
item_id = item["item_id"]
title = item["word"]
# 2. 判定是否立即拉取详情评论
features = {
"url_len": len(hot_url),
"prev_status_code": resp.status_code
}
if should_fire_ajax(features):
# 3. 拉取评论
c_params = {"is_reload":1, "id":item_id, "count":10}
c_resp = session.get("https://weibo.com/ajax/statuses/buildComments", params=c_params)
comments = c_resp.json().get("data", {}).get("comments", [])
else:
comments = []
results.append({
"id": item_id,
"title": title,
"comments": comments
})
time.sleep(1)
# 4. 存储文件
timestamp = time.strftime("%Y%m%d_%H%M%S")
with open(f"data/hot_search_{timestamp}.json", "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=2)交互流程图
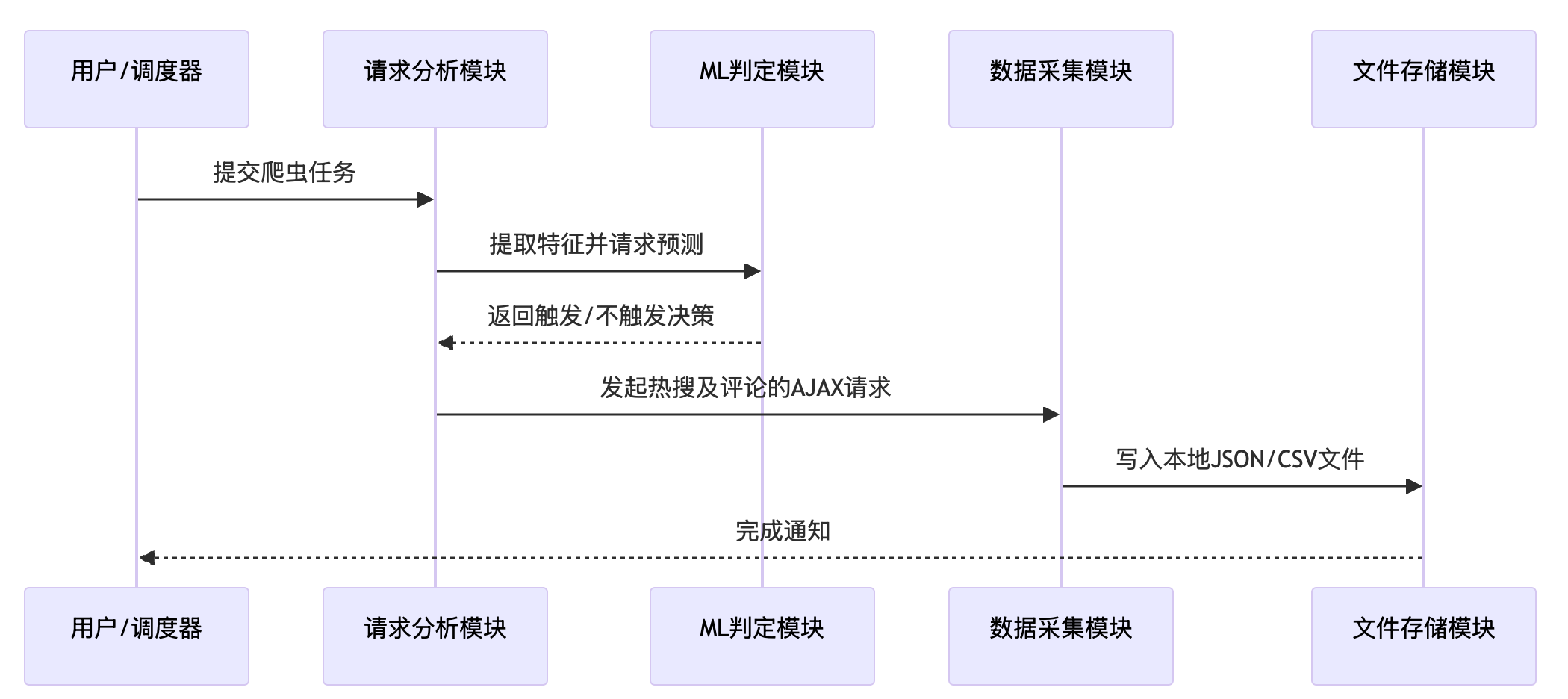
以上模块化设计和代码示例,展示了如何在真实环境中结合代理IP、Cookie/User-Agent伪装,以及机器学习智能判定,实现对微博动态渲染页面的精准AJAX嗅探与数据抓取。