**文章标题:**Foundation Models in Autonomous Driving: A Survey on Scenario Generation and Scenario Analysis
(翻译)自动驾驶中的基础模型:场景生成与场景分析综述
文章发表于预印本:Foundation Models in Autonomous Driving: A Survey on Scenario Generation and Scenario Analysis
续:文献阅读篇#10:自动驾驶中的基础模型:场景生成与场景分析综述(1)-CSDN博客 & 文献阅读篇#11:自动驾驶中的基础模型:场景生成与场景分析综述(2)-CSDN博客 & 文献阅读篇#12:自动驾驶中的基础模型:场景生成与场景分析综述(3)-CSDN博客 & 文献阅读篇#13:自动驾驶中的基础模型:场景生成与场景分析综述(4)-CSDN博客
五、扩散模型(DMs)
本节概述了扩散模型(DMs),解释了其基础的生成过程并追溯了其概念演变。由于其生成特性,扩散模型在合成新的场景方面表现出色,而非分析现有场景。因此,我们回顾了它们在自动驾驶(AD)场景生成中的应用,包括交通流合成、道路布局设计、图像生成和视频生成。++(DMs部分的概况)++
A. DMs的发展
扩散模型(DMs)是受到非平衡热力学启发的生成模型 200,模拟了墨水在水中扩散等自然过程。本质上,它们遵循一个简单而强大的理念:通过迭代地向数据中添加噪声来系统性且渐进地破坏数据结构,并学习以逐步方式逆转这一过程。虽然该方法由 Sohl-Dickstein 等人提出 200,但通过 Ho 等人的 DDPM 30 获得了广泛应用。如图 7 所示,扩散模型(DMs)的框架包括两个关键阶段:前向过程和反向过程。++(扩散模型的提出和应用)++

图 7. 展示了扩散模型如何通过前向过程将干净图像转化为噪声,然后在反向过程中将其重建的示意图。
(1) 正向过程:正向过程是指通过在 T 步中逐步向原始数据 x0 添加高斯噪声,从而逐渐破坏原始数据,得到一系列带噪声的样本 x1, x2, ..., xT。在最后一步 xT 时,样本无法与纯噪声区分开。 (2) 反向过程:为了从纯高斯噪声生成逼真的样本,扩散模型必须学习逆转其正向破坏过程。这是通过迭代去噪过程实现的,在该过程中,模型逐步精炼带噪输入以恢复底层数据分布。在每一步中,模型估计并去除正向过程添加的噪声,逐步重建目标样本。去噪过程通常由神经网络参数化,例如 U-Net 30,其训练目标是在每次迭代中预测噪声成分。++(详细说明了扩散模型正向和反向的两个过程)++
在这一范式建立之后,研究主要沿两个关键方向推进:
可控性: 与原始的 DDPM 30 不同,原模型是无条件训练的,对生成样本的控制非常有限,后续研究开发了引导扩散过程生成期望输出的方法。通过对网络施加辅助信号条件,如类别标签、文本嵌入、布局图或其他模态,可以实现引导生成过程的结构约束。分类器引导 201 使用来自独立分类器的梯度,将采样引导到期望输出。无分类器引导 202 通过联合训练有条件和无条件信号的模型,避免了对独立分类器的需求,从而在推理阶段实现可调控的控制。ControlNet 203 进一步扩展了可控性,通过引入边缘、深度或姿态等空间条件,实现精细化的用户控制。++(提高可控性的几种方法和几个案例)++
效率: DDPM 的高计算成本源于在全分辨率下的多次迭代步骤。LDMs 32 通过在压缩的潜在空间中操作来解决这一问题,在降低复杂性的同时保持质量。扩散变换器(DiT)204 在此基础上通过将 U-Net 替换为变换器主干,提高了可扩展性和全局上下文建模能力。++(降低计算成本提高效率的方法与案例)++
这些先前的创新使得在广泛的领域中使用DM成为可能。AD是一个特别有影响力的领域,DM被用来高效且可控地生成逼真的场景。
B. 情景生成
本节概述了用于自动驾驶场景生成的生成模型(DMs),按输出类型组织:动态交通流、静态交通元素、图像和视频。
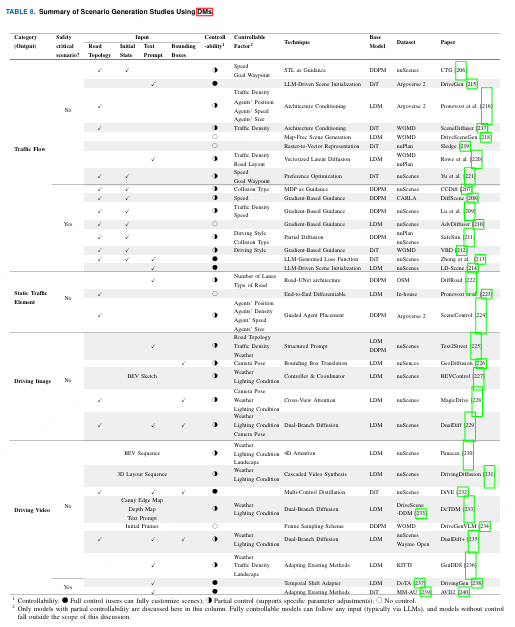
1 可控性:实心圆,完全可控(用户可以完全自定义场景);半圆,部分可控(支持特定参数调整);空心圆,不可控。2 本列仅讨论具有部分可控性的模型。完全可控的模型可以遵循任何输入(通常通过大语言模型),而不可控的模型不在本讨论范围内。
交通流生成: 传统的仿真器 51, 52, 93, 205 通常依赖于重放驾驶日志或使用启发式控制器,这些方法往往无法准确捕捉真实人类行为的复杂性和适应性。最近生成模型的进展提供了一个机会,可以直接创建虚拟智能体的现实且多样化的交通行为。这些模型可以生成多个智能体随时间变化的行为(轨迹)。为了作为可靠的仿真工具,这类模型必须同时实现现实性和可控性,在遵循可自定义规则的同时反映类似人类的驾驶行为。为了增强现实性,这些模型通常在大规模真实驾驶数据集上进行训练,以学习交通行为的潜在动力学和多样性。下面,我们将回顾实现可控性的不同技术。++(直接创建虚拟智能体的现实且多样化的交通行为)++
(I) DMs 中基于梯度的引导是通过使用控制目标的梯度在每个去噪步骤修改预测均值来工作的。这使生成过程朝向更好地满足目标的样本,同时仍遵循底层扩散过程。根据目标的定义方式,这种引导可以强化安全约束,或者反过来,也可能导致对抗性和安全关键的情境。CTG 206 使用信号时序逻辑(STL)来编码交通规则,利用 STL 的鲁棒性评分作为规则遵守程度的衡量标准,并利用其梯度指导轨迹采样。CCDiff 207 利用受约束的马尔可夫决策过程(MDP)的梯度来引导多智能体的轨迹生成,其中 MDP 编码了特定的控制目标,如引发碰撞。在应用引导之前,因果推理器会根据智能体间的影响对其进行排序,并将引导限制在最具影响力的子集上,以提高效率和效果。DiffScene 208 定义了三个可微分目标:安全关键(最大化碰撞风险)、功能性(阻碍自我任务完成)和基于约束(执行现实规则)。Lu 等 209 通过鼓励对抗性智能体表现侵略性机动(通过加速度/偏航率变化)并操控自车周围的交通密度来扩展 DiffScene。AdvDiffuser 210 训练一个模型来预测某个情境导致给定规划器失败的可能性,并利用该信号引导采样过程。SafeSim 211 和 VBD 212 生成潜在轨迹并识别可能导致碰撞的轨迹,然后使用引导扩散进行去噪。Zhong 等人 213 和 LD-Scene 214 提出了另一种方法,他们都利用大型语言模型将自然语言指令(如"激进变道")翻译成可微导引函数,连接高层意图与低层控制。++(控制目标的梯度在每个去噪步骤修改预测均值)++
(II) 架构条件化将控制信号直接嵌入网络结构中,使约束在每次迭代中被强制执行,而非事后作为外部修正注入。DM通过接受额外的条件输入来实现这一点,比如携带代理属性、场景统计、语言描述或空间掩码的标记。这些额外输入由专用层处理,例如交叉注意力块或修复模块,并在每次去噪迭代时与潜景表示融合。Pronovost 等人 216 将代理属性(速度、航向)和全局场景属性(代理密度)编码为交叉注意力层处理的代币。SceneDiffuser 217 将轨迹生成框架为对形状 A×T×D 的三维张量上的内嵌任务,每个张量代表代理、时间步和特征。场景编辑和代理注入可以通过调整场景张量和相关的补漆遮罩实现。DriveGen 215 使用自然语言描述生成道路布局并通过大型语言模型(LLM)放置车辆。随后应用VLM分析BEV,以确定潜在的未来目标。最后,DM生成从每辆车辆初始状态到预测目标的真实轨迹。DriveSceneGen 218 解决了两个关键问题:场景初始化和展开。它首先用DM合成道路布局和代理位置的BEV图像,然后用运动变换器(MTR)对输出进行矢量化以预测轨迹。SLEDGE 219 和 ScenarioDreamer 220 处理相同的任务,但优化了生成流程。具体来说,SLEDGE 引入了光栅转矢量自编码器,将场景压缩为潜在映射以进一步扩散,而 ScenarioDreamer 则进一步推进,直接在矢量空间中作 DM。这些方法共同反映了从像素级(DriveSceneGen)到压缩光栅(SLEDGE)再到完全矢量化(ScenarioDreamer)生成的过程。++(使约束在每次迭代中被强制执行)++
(III) 偏好优化(PO)不依赖梯度指导和架构条件。Yu 等人 221 直接使用 PO 对 DM 进行微调,而不是使用显式控制信号或手工设计的损失函数。模型为每个场景生成两个候选轨迹,通过基于规则的启发式方法对它们进行评分,并自我更新以偏向更好的轨迹,从而隐式地学习控制偏好。++(偏好优化)++
尽管最近取得了进展,但基于扩散的交通流生成器仍然依赖人工设计的控制输入。梯度引导的模型需要精心调节的目标权重,而架构条件模型则依赖预定义的标记或掩码方案来编码规则。将这些方法适应新的约束通常需要昂贵的重新训练或大量的微调。++(存在的一些问题)++
**静态交通元素:**DMs 还被开发用于生成除车辆轨迹之外的各种自动驾驶组件。
DiffRoad 222 可以根据结构化文本输入(例如,"两个三岔路口")合成 3D 道路布局,并根据平滑度和是否存在重叠路段等标准评估输出结果。Pronovost 等人 223 和 SceneControl 224 专注于为下游交通模拟生成初始代理布局。Pronovost 等人提出了一种场景自编码器,将光栅化的代理布局压缩为潜在嵌入。然后,一个以道路地图为条件的 DM 在这些嵌入上进行训练,解码器重建代理的定向边界框。SceneControl 通过引导采样提供了额外的灵活性,使用户能够在生成过程中进行精细控制(例如执行速度约束)并保证现实性(例如避免碰撞和遵守车道)。为了评估生成的场景与真实数据的匹配程度,两种方法都比较了真实和合成数据集之间的统计分布。++(DMs生成静态交通元素的几个案例)++
这些静态场景生成器仍然存在明显的不足。当使用扩散模型生成道路布局时,交通标志、信号灯和车道标线等细粒度元素往往会被忽略。因此,生成的地图缺乏进行高逼真驾驶模拟所需的精确度。此外,初始场景生成器也高度依赖具体地图:它们会吸收训练语料的空间先验,并在应用于未见过的道路几何或具有不同驾驶习惯的区域时不现实地放置交通参与者。++(存在的明显的不足)++
**图像生成:**可靠的自动驾驶感知依赖于大规模标注数据集。扩散模型(DMs)通过生成真实的街景图像,提供了一种高效的替代方案。
Text2Street 225 将结构化提示分解为三个不同部分,例如"一个阳光明媚的日子里有一条路口、4条车道、3辆车、2个人和2辆卡车的街景图像",分为三个不同的组成部分:道路拓扑、物体布局和天气状况。每个组成部分都由专属的DM负责。第一个模型处理道路拓扑以生成纯电动车(BEV)道路布局。第二个模型将该纯电动车布局纳入物体布局,生成包含车辆、行人及其他前景元素的地图。第三个模型将BEV的表现转化为逼真的摄像机视角街景。为了更有效地处理几何条件,GeoDiffusion 226 将边界框转换为文本提示,引导预训练的文本转图像DM。这包括将连续的边界框位置转换为离散的标记,并在图像生成过程中平衡前景物体的视觉突出度与通常占主导的背景区域。Baresi 等人241 使用三种基于扩散的策略生成罕见的 OOD 驾驶场景(如雪地、沙漠),分别是指令编辑、修补和细化修补。与此同时,其他作品则专注于生成多视图图像。BEVControl 227 通过使用可编辑的 BEV 草图作为输入,解决了编辑密集分割映射的复杂性。它引入了"控制器和协调器"机制,以确保生成的对象与草图精确匹配,并在多个视角之间保持一致性。MagicDrive 228 将道路布局、边界框、相机姿态,以及天气和时间等文本描述作为输入。它引入了一个跨视图注意力模块,使每个相机视图可以访问其相邻视图的信息,从而确保所有生成视图的视觉一致性和连贯性。DualDiff 229 采用了双分支架构,分别生成前景和背景。它将 3D 占用数据投影到相机平面上形成密集特征图,并将其与 3D 边界框和道路地图融合,然后结合分支输出合成最终图像。++(使用DMs生成街景图像的几个案例)++
尽管近期取得了一些进展,诸如交通标志、杆式信号灯和车道标线等细节仍经常被简化或省略,这导致生成的图像无法覆盖许多真实感知系统必须处理的视觉角落情况。光度真实感也有限:简化的光照模型以及缺乏相机伪影(如滚动快门失真、镜头眩光和传感器噪声)在使用这些合成帧训练或评估现实世界检测器时会产生明显的领域差异。++(仍然存在的一些问题)++
**视频生成:**近期的研究也推进了基于扩散模型的驾驶视频生成,提升了时间一致性、可控性和多样性。
多项研究提出了创新的架构,以确保生成视频的多视角和时间一致性。Panacea 230 通过首先从 BEV 输入合成图像,然后沿时间维度扩展这些图像,生成多视角视频序列。该方法引入了一种 4D 注意力机制,考虑了视角内(每个摄像机内)、跨视角(相邻摄像机之间)和跨帧(时间片段之间)的关系。DrivingDiffusion 231 也采用了多阶段方法:它首先从布局生成所有摄像机视角的一致初始帧,然后使用时间模型生成短期视角特定序列,最后通过滑动窗口后处理模块优化长期一致性。DiVE 232 专注于高效的多视角驾驶场景生成。它引入了多控制辅助分支蒸馏(MAD)以简化多条件无分类器引导,从而显著减少推理时间。DiVE 还提出了视角扩展注意力,这是一种轻量机制,在不增加参数的情况下强制跨视角一致性。++(一些确保生成视频的多视角和时间一致性的架构)++
视频生成的另一种策略是通过时间扩展来改编图像扩散模型。DrivingGen 238 通过引入时间偏移适配器扩展了文本到图像的扩散模型,该适配器使用修改后的二维卷积高效地在帧之间传播信息,而无需昂贵的三维操作。类似地,DcTDM 233 将基于图像的扩散扩展到时间域,但引入了稠密深度图和 Canny 边缘图的双重条件,以在帧间保持几何和结构一致性。DriveGenVLM 234 通过条件和采样策略(如逐帧生成和关键帧插值的 VOLUME)增强了长期视频生成能力,在质量和速度之间提供了权衡。++(通过时间扩展来改编图像扩散模型)++
相比之下,DualDiff 235 通过一种双分支架构生成视频,该架构将前景和背景建模解耦。该模型首先将三维占用网格投影到二维空间,然后将这些特征与语义输入融合,包括三维边界框(前景)和地图(背景)。++(双分支架构生成视频)++
另一条研究路线通过结合和调整现有模型推进视频生成。GenDDS 236 使用 LoRA 65 对 Stable Diffusion XL 242 进行微调,以生成驱动图像,然后通过 Hotshot-XL 243 中的时间变换器将这些图像扩展成视频。AVD2 240 在 MM-AU 239 数据集上对 Open-Sora 1.2 模型 244 进行微调,以生成带有事故原因和规避策略注释的视频。++(通过结合和调整现有模型推进视频生成)++
尽管最近取得了一些进展,用于生成视频的扩散式生成器仍面临重大挑战。它们往往难以保持一致的时间和多视角连贯性,尤其是在较长的视频片段中。此外,它们对物理世界动力学的理解仍然有限:例如,车辆可能以违反惯性或遮挡逻辑的方式运动。++(视频生成上仍然存在的问题)++
C. 局限性与未来方向
尽管最近的扩散模型支持通过布局掩码、语言标记或基于注意力的输入进行条件控制,但这些机制往往仍然比较僵硬且专业化程度高。它们通常依赖手动调优、预定义的条件模式或特定任务的再训练,从而限制了其灵活性和可扩展性。为了解决这一问题,未来的研究应致力于开发更具通用性的条件框架,能够无缝整合多样或新颖的输入,而无需进行大规模的架构修改或再训练。++(僵硬且专业化程度高)++
与此同时,虽然扩散模型(DMs)在统计真实性指标上通常表现出色,但生成的轨迹和场景往往缺乏细致的物理合理性。常见问题包括不合理的惯性动力学、不自然的智能体反应,以及对遮挡或因果依赖关系建模不足。未来研究的一个有前景的方向是引入物理驱动模型,这可以提高对真实物理规律的遵循性,并增强生成结果的整体真实感。++(生成的轨迹和场景往往缺乏细致的物理合理性)++
此外,尽管大语言模型(LLMs)越来越多地被用来将自然语言输入转换为扩散模型(DMs)的指导信号,但它们的潜力仍未被充分利用。LLMs 不应仅仅作为输入翻译器,而可以作为嵌入式知识源,编码关于物理动力学、语义场景结构和规范驾驶行为的丰富先验知识。利用这些能力可能会显著提升扩散生成场景的可控性、真实感和可解释性,尤其是在复杂或模糊的环境中。++(大语言模型的作用未充分利用)++
七、世界模型(WMs)
WMs 是生成型神经网络模型,它们能够学习环境的压缩空间和时间表示 34。它们使智能体能够建立世界的内部模型,从而预测周围环境的未来状态,包括动态代理和静态物体。在本节中,我们重点讨论它们生成驾驶场景的能力,并将近期的工作分类为视觉生成、三维占用生成和多模态生成。此外,我们还讨论了相关的架构创新和基准测试。++(世界模型是什么,总结本节内容)++
A. 世界模型的发展
与认知科学的关系: 工作记忆(WM)的发展侧重于学习对物理世界动态的紧凑、可预测的表示。这一概念的灵感来自人类大脑模拟和预测现实世界物理规律的能力245。认知科学提出了预测性大脑模型,以预测现实世界场景的演变,例如Downing(2009)的程序性和陈述性模型246。Svensson等人(2013)247 将类似大脑的"梦境"应用于离线模拟感知-动作序列,用于简单的机器人系统。他们将心理意象定义为大脑生成和操作世界内部表示的能力,这一过程类似梦境,不需要与环境直接交互。同样,如下一节所述,工作记忆可以通过生成想象场景(图8)来"做梦",无需与物理世界交互,并使用其学习到的表示预测环境的未来演变。++(预测现实世界场景的演变)++
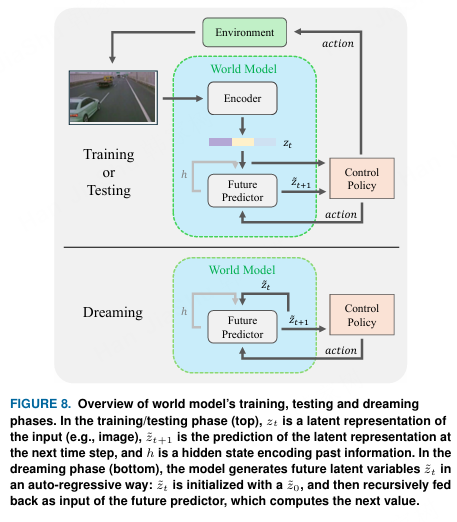
图8.++世界模型训练、测试和梦境阶段概览。++在训练/测试阶段(上方),zt 是输入(例如图像)的潜在表示,˜zt+1 是下一个时间步潜在表示的预测,h 是编码过去信息的隐藏状态。在梦境阶段(下方),模型以自回归方式生成未来潜在变量 ˜zt:先以 ˜z0 初始化 ˜zt,然后递归地将其反馈作为未来预测器的输入,该预测器计算下一个值。
在相关背景下,Plebe 等人 248,249 提出了视觉自编码器,模仿大脑的神经收敛-发散模式 250,以视频的形式输出驾驶场景的长期预测。他们建议将自由能最小化作为训练损失函数,这一做法受到 Friston 关于大脑运作理论的启发 251。LeCun 245 也提出了类似的最小自由能原则用于工作记忆的训练。关于自动驾驶中生物启发认知代理的更广泛综述,读者可以参考 252。++(视频的形式输出驾驶场景的长期预测)++
我们认为,这种认知理论将激励下一代工作记忆(WMs),这些工作记忆需要从有限的数据中学习可概括的现实世界动态模型。
世界模型的架构与演化: 世界模型(WMs)的架构通常基于编码器-解码器范式 34, 244, 245, 287, 288。如图8所示,编码器(也称为视觉模型 34)用于将多模态输入(图像、点云、三维占据体素等)编码为潜在向量 zt。然后,未来预测器(解码器或记忆模型 34)基于 zt 和由给定控制策略提供的动作预测未来的潜在表示 ˜zt+1。当世界模型的预训练完成后,未来预测器既可用于动作预测,也可用于"梦境"生成(即生成训练期间未曾见过的新场景)。在这方面,世界模型可以生成超出训练数据分布的数据:这在自动驾驶(AD)中尤为重要,因为稀有但关键的场景可能在现有数据集中表现不足,但在验证阶段至关重要。++(基于编码器-解码器范式)++
除了单独设计之外,WM 现在越来越多地借鉴来自 LLM、VLM 和 MLLM 的灵感,这些模型在语义理解方面表现出了良好的潜力。更具体地说,WM 正在强调利用这种语义理解进行内容生成 289。此外,DM 在大多数现代 WM 中作为生成主干发挥着重要作用,为图像和视频提供稳定且高保真度的生成。GAIA-2 255、DriveDreamer 288 和 MagicDrive3D 263 是这一趋势的例子,它们采用潜在扩散或视频扩散来提高生成场景的时间一致性和真实性。总体来看,这些例子表明,WM 正在发展为一种混合架构,将 VLM 的多模态推理能力与 DM 的生成精度结合起来,从而创造出连贯、可控且语义扎实的驾驶模拟。++(强调利用这种语义理解进行内容生成)++
如图8所示,在早期的例子34中,视觉模型(编码器)被实现为变分自编码器(VAE),并将高维观测压缩为紧凑的潜在表示。这种降维为预测和生成创建了一个可管理的状态空间。未来预测器(记忆模型)被实现为循环网络(例如长短期记忆网络(LSTM)或门控循环单元(GRU))。记忆模型捕捉顺序观测中的时间依赖性和动态特性,从而实现对未来状态的预测。用于自动驾驶(AD)的现代记忆模型改进了这一基本架构,将先进技术融入未来预测器。例如,GAIA-1 253 使用了 Transformer,而更新的 GAIA-2 255 则采用潜在扩散模型(LDM)32 进行未来预测和生成。最近,扩散 Transformer(DiTs)204、稳定视频扩散(SVD)256 模型以及视频 LDM 261 已作为记忆模型的核心架构获得了广泛关注。++(未来预测器的发展案例)++
如图9所示,WM通常可在AD中用于两个目的:未来动作预测290和场景生成253,255。在本节中,我们主要关注WM在场景生成中的应用。所回顾的论文、相应的数据集及其代码的可用性总结如表9所示。
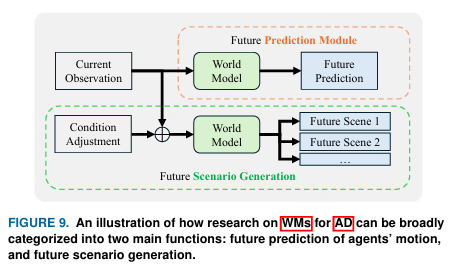
图9. 说明了针对AD的工作记忆研究如何可以大致分为两大功能:对智能体运动的未来预测,以及未来场景生成。
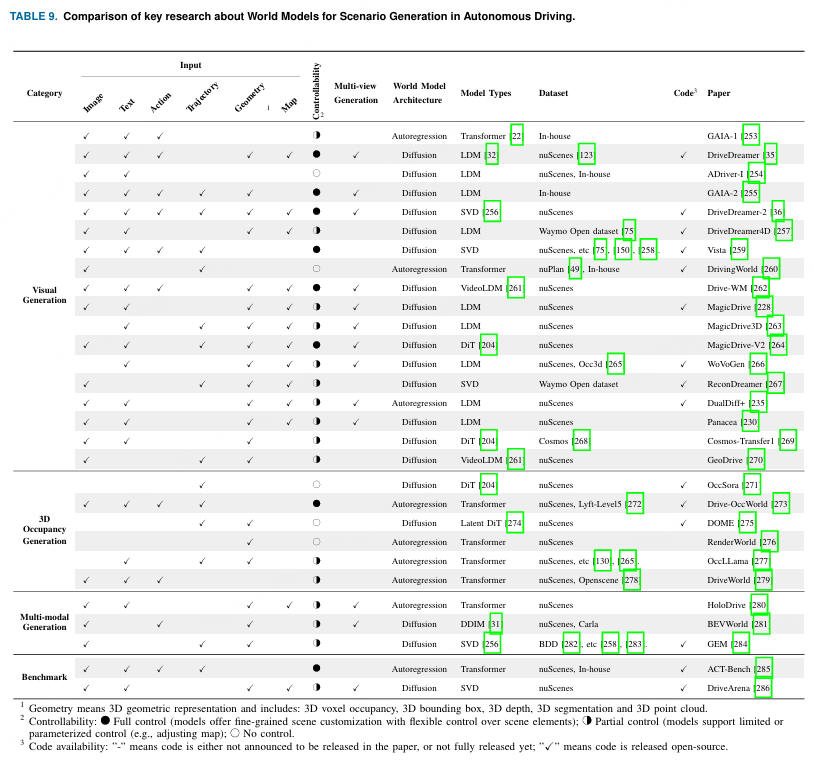
1 几何表示指3D几何表示,包括:3D体素占用、3D边界框、3D深度、3D分割和3D点云。 2 满圆可控性:完全控制(模型提供精细场景定制,并对场景元素具有灵活控制);半圆部分控制(模型支持有限或参数化控制,例如调整地图);不可控制。 3 代码可用性:"-"表示代码在论文中未宣布发布或尚未完全发布;"✓"表示代码已开源发布。
B. 使用世界模型梦境进行情景生成
WMdreaming 34 是指利用经过训练的 WM,通过从其学到的潜在空间中进行采样来生成新场景,而无需额外的现实世界输入。一旦 WM 捕捉到环境的基本动态,它就可以"梦想"出遵循训练数据中类似物理和逻辑模式的新场景,但组合的元素和条件可能在训练中未曾出现。如表 9 所示,近期关于用于 AD 的 WM 研究可以分为以下四类。++(WMdreaming是什么)++
视觉生成: 这种方法侧重于通过生成图像和视频来创造逼真的驾驶场景。它们代表了自动驾驶中世界模型(WM)应用最成熟的类别。GAIA-1 253 首创了在自动驾驶中使用生成型世界模型的方法,展示了生成包含多个相互作用主体的多样化交通场景的能力。GAIA-1 将世界建模视为一个无监督的序列建模问题,将多模态输入(视频、文本和动作)映射为离散代币,并预测后续代币。这种方法可以对自车行为和场景特征进行精细控制,展现出情境感知和三维几何理解等新兴特性。GAIA-2 255 通过基于潜在扩散的世界模型,在 GAIA-1 的基础上实现了重大进展,该模型支持在结构化输入(如自车动态和主体配置)条件下可控的视频生成。GAIA-2 能在多样化的驾驶环境和国家(英国、美国、德国)中生成高分辨率、时空一致的多摄像头视频,使其成为复杂场景模拟的有用工具,同时保证良好的多视角一致性。++(通过生成图像和视频来创造逼真的驾驶场景)++
为了解决先前WMs的局限性,DriveDreamer 35 引入了一个完全基于真实驾驶场景的模型。通过其 AD 扩散模型(Auto-DMs)和两阶段训练流程,DriveDreamer 首先学习交通结构约束,然后通过视频预测来预见未来状态。这种方法在生成可控驾驶视频和预测驾驶策略方面表现出色,从而提升了如3D检测等感知任务的能力。DriveDreamer-2 36 在 DriveDreamer 框架 35 的基础上进行了扩展,加入了大型语言模型(LLM)以生成用户定义的驾驶视频。DriveDreamer-2 将用户查询转换为智能体轨迹,并采用统一的多视角模型以确保时间和空间的一致性。它还可以生成不常见的场景,例如突然的车辆切入。DriveDreamer4D 257 将 DriveDreamer 框架扩展至 4D(时空)场景表示。通过整合地图、布局和文本条件,它增强了生成数据的真实感。++(解决局限性的几个尝试)++
与传统的模块化设计不同,ADriver-I 254 引入了一个统一的工作记忆(WM),使用交错的视觉-动作对来标准化视觉特征和控制信号。通过利用多模态大模型(MLLMs)和扩散方法,它以自回归方式预测控制信号并预测未来帧,形成连续的仿真循环。同样采用自回归风格,30 DrivingWorld 260 为自动驾驶引入了类似 GPT 的工作记忆,具有时空融合机制。它使用下一状态和下一标记预测策略来建模时间连贯性和空间信息,并通过实现掩码和重新加权策略来减轻长期漂移问题,同时提升三维检测和运动预测能力。++(几种新的设计)++
作为一个具有多样化3D几何控制的街景生成框架,MagicDrive 228 包含相机位置、道路地图和3D边界框,以及文本描述。它解决了传统扩散模型(DM)在3D控制方面的挑战,提供具有细腻3D几何和多摄像机一致性的高保真视频生成。MagicDrive3D 263 提出了一种可控的3D街景生成流程,支持多条件控制,包括鸟瞰图(BEV)地图、3D物体和文本描述。与在训练前重建场景的方法不同,它首先训练视频生成模型,然后从生成的数据中重建3D场景,从而实现任意视角渲染的高质量场景重建。++(多样化3D几何控制的街景生成框架)++
WoVoGen 266 引入了一种世界体积感知的生成模型(DM),用于生成可控的多摄像头驾驶场景。它通过预测显式的三维世界体积来引导视频生成,确保多摄像头视角与底层场景几何准确对齐,并保持高空间和传感器间的一致性。而 ReconDreamer 267 不仅专注于为驾驶场景重建构建世界模型(WM),还关注在线恢复。它强调用于实时应用的在线学习,使世界模型在获取新数据时能够持续更新,这对于适应自动驾驶中不断变化的环境至关重要。++(两个案例)++
DualDiff 235 通过采用用于高保真视频生成的双分支扩散模型,引入了占用射线采样以实现语义丰富的三维表示,并使用语义融合注意力将多模态数据整合到前景感知的掩码损失中,从而提高小对象的生成效果。GeoDrive 270 将三维几何条件融入驾驶动作建模(WM)中。它通过三维视频渲染以及动态编辑和控制,实现时空一致性的空间理解和动作可控性,从而在最少训练数据的情况下提升视频质量。++(两个案例)++
3D 占用生成: 3D 占用生成预测并生成驾驶环境的体积表示,捕捉场景的空间结构和时间动态。通过将 4D 占用场景演变视为视频预测任务,OccSora 271 提出了一种新型的 4D 场景标记器,以获得紧凑的时空表示。然后,它训练一个扩散变换器来生成基于轨迹提示的 4D 占用,实现对各种驾驶场景的轨迹感知模拟。为了在复杂的城市环境中同时考虑静态和动态元素,Drive-OccWorld 273 将规划器与动态 WM 结合,从多视角图像预测 3D 占用和流场。更具体地,它使用具备运动感知的 BEV 序列作为中间表示,将多视角视频数据与运动线索整合,以实现稳健预测。同样旨在提高静态和动态物体的预测精度,RenderWorld 276 进一步尝试在粒度和计算效率之间取得平衡。它通过一种新颖的标记策略专注于细粒度占用预测,该策略能够捕捉空间关系。++(生成驾驶环境的体积表示,捕捉场景的空间结构和时间动态)++
使用类似连续变分自编码器的分词器,DOME 275 进行 3D 占用预测,以保留复杂的空间信息。与离散分词方法不同,DOME 的连续方法在保持计算效率的同时捕捉微妙的几何细节,并使用概率建模增强对传感器噪声和遮挡的鲁棒性。OccLLama 277 尝试将多模态大语言模型 (LLM) 作为占用预测的核心组件。与传统仅依赖几何或视觉数据的模型不同,OccLLama 利用 LLM 的推理能力处理多模态输入,理解复杂场景语义和物体交互,从而提高预测精度。而 DriveWorld 279 则侧重于从多视角视频进行 4D 场景理解。这种方法将静态空间上下文与动态时间变化分离,以实现精确的占用预测。该模型依靠自监督学习来减少对标注数据的依赖,从而增强可扩展性。++(DOME 的连续方法捕捉细节)++
**多模态生成:**多模态生成方法整合多种传感器模态和数据类型作为输入,并输出可以包括相机图像、激光雷达点云和深度估计的多模态数据。
为了应对单一模态方法的局限性,HoloDrive 280 提出了一个用于联合 2D-3D 场景生成的统一框架。它采用 BEV-to-Camera 和 Camera-to-BEV 转换模块来连接异构生成模型。因此,它在使用相机图像和 LiDAR 点云生成一致的街景场景时,确保了 2D 和 3D 表示的一致性。此外,GEM 284 提出了一个通过整合多模态传感器数据(包括相机图像和深度估计)生成逼真环境的框架。它采用基于时空变换器的生成模型,能够预测动态场景的演变,包括视觉生成和深度估计。BEVWorld 281 通过一个统一的 BEV 潜空间执行世界建模,同时整合多模态传感器输入。该框架包括一个多模态分词器和一个潜在 BEV 序列 DM,用于将多模态数据编码到统一的 BEV 潜空间中。该方法旨在以自监督方式将视觉语义与几何信息对齐。++(异构生成模型)++
基准测试: 当前的基准测试框架提供了标准化的方法来评估生成场景的质量、可控性和实用性,确保WM满足自动驾驶应用的要求。现有的评估框架主要关注视觉真实感以及下游任务(感知、规划等)的性能。ACT-Bench 285 引入了一个标准化框架来量化动作可控性,衡量生成的场景在多大程度上遵循指定的驾驶指令。该基准测试框架评估WM生成场景中动作执行的真实性。DriveArena 286 是一个闭环生成仿真平台,可在动态且逼真的环境中评估自动驾驶系统。通过模拟自车与环境的持续交互,它弥合了合成训练与现实部署之间的差距,支持驾驶策略的迭代优化。++(注视觉真实感以及下游任务)++
C. 局限性与未来方向
关于使用WM进行3D占用生成的最新研究显示了在体积形式下预测驾驶环境演变的有前景的能力。然而,大多数模型仍然计算量大:未来的工作应致力于开发轻量级架构并探索更精细的占用体素表示。最近的商业系统,例如特斯拉的FSD8基础模型,既凸显了大规模WM的潜力,也显示了仍然存在的挑战。++(计算量大问题,特斯拉案例)++
此外,当前的实现方法在模拟复杂多智能体交互和真实世界物理时面临困难,包括车辆动力学和运动学规律、轮胎与路面的摩擦、碰撞力以及天气影响。生成的场景有时包含物理上不合理的元素,例如物体突然出现或消失。因此,所调研的世界模型(WMs)++能够生成多样化的驾驶场景,但无法准确遵循物理定律,这可能导致误导性的测试结果和不可行的场景。++