总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
User Inference Attacks on Large Language Models
https://arxiv.org/pdf/2310.09266
https://www.doubao.com/chat/4034601691207170
速览
这篇论文主要研究了大语言模型(LLMs)在使用用户数据进行微调时的隐私问题,提出了用户推理攻击概念,并探讨了相应的缓解策略。
- 研究背景:在实际应用中,大语言模型(LLMs)常常通过在特定领域数据上进行微调,以更好地解决现实问题。然而,使用用户数据微调LLMs可能带来隐私风险。现有的针对LLMs的隐私攻击主要有成员推理和提取攻击,但这些攻击无法评估特定用户的隐私风险。本文提出了用户推理这种新的威胁模型。
- 相关工作:介绍了不同类型的机器学习隐私攻击,包括成员推理攻击、数据重建、数据提取攻击等,并对比了它们与用户推理攻击的差异。
- 用户推理攻击
- 威胁模型:攻击者试图通过从用户分布中获取的少量样本和对微调模型的黑盒访问,判断特定用户的数据是否用于模型微调。
- 攻击策略:将攻击者的任务转化为统计假设检验,通过构建基于似然比的检验统计量来判断用户是否参与了微调。
- 攻击效果分析:在理论上分析了攻击统计量,指出攻击者更容易推断出贡献数据多或数据独特的用户是否参与了微调。
- 实验
- 实验设置:使用Reddit评论、CC新闻、安然邮件等数据集,在GPT - Neo系列模型上进行实验,通过ROC曲线和AUROC评估攻击效果。
- 实验结果:发现用户推理攻击在不同数据集上均有一定效果,用户数据量、攻击者知识、模型过拟合等因素会影响攻击性能。
- 最坏情况分析:通过合成"金丝雀"用户,发现共享子串会增加攻击成功率,且难以通过梯度过滤来防范。
- 缓解策略:研究了梯度裁剪、提前停止、限制用户数据量、数据去重、示例级差分隐私等方法,发现这些方法在缓解用户推理攻击方面存在一定局限性。
- 结论与展望:论文指出在使用用户数据微调LLMs时存在隐私风险,未来应探索更多的LLM隐私保护方法,开发可扩展的用户级差分隐私算法。
论文阅读
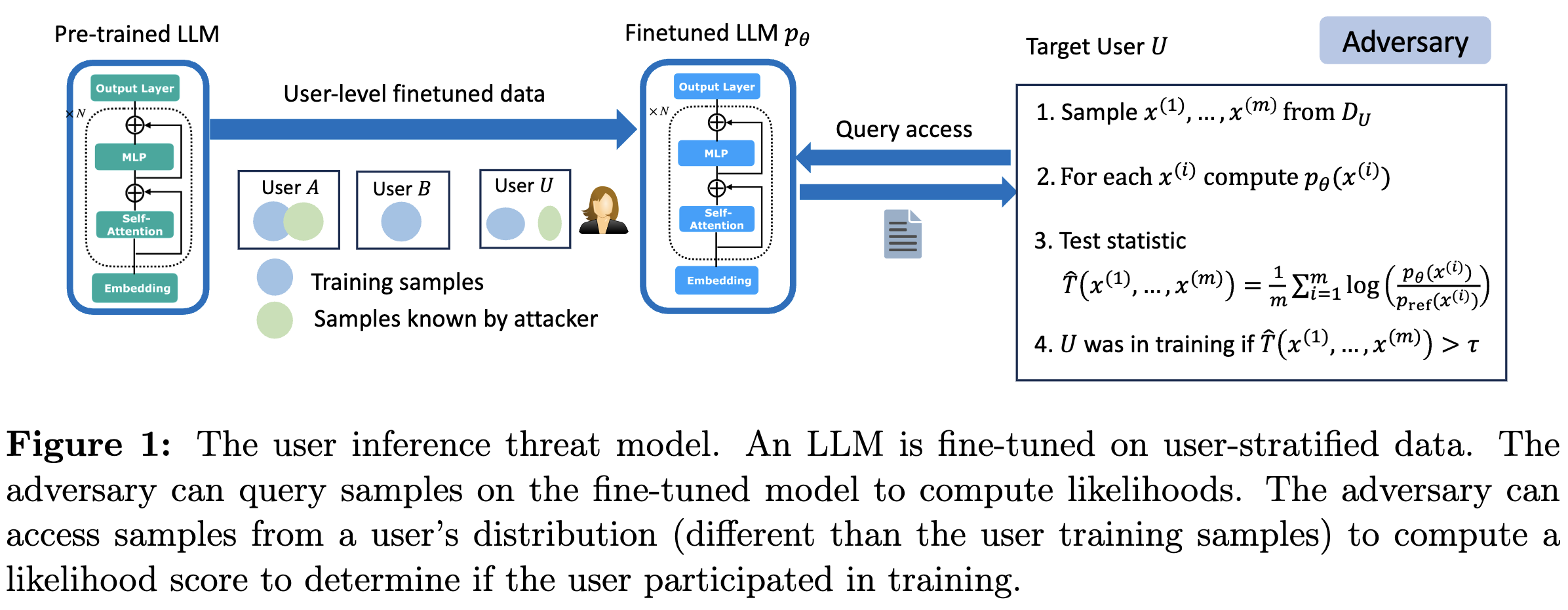
图1展示的是用户推理(user inference)威胁模型的流程,在大语言模型(LLM)基于用户数据进行微调的场景下,攻击者试图判断某个用户的数据是否被用于模型微调,具体步骤如下:
- 样本选取 :存在一个经过预训练的大语言模型,在用户分层的数据上进行微调。攻击者从目标用户(Target User)的分布中选取一些样本 x ( 1 ) , ... , x ( m ) x^{(1)}, ..., x^{(m)} x(1),...,x(m) ,这些样本不需要是模型微调时使用过的样本。比如,若模型基于用户的邮件数据微调,攻击者可能获取到该用户的部分邮件,但不一定是模型微调所用的那些。
- 计算似然值 :攻击者利用对微调后模型的查询权限,将选取的样本输入微调后的模型 p θ p_{\theta} pθ ,计算每个样本 x ( i ) x^{(i)} x(i)在该模型下的似然值 p θ ( x ( i ) ) p_{\theta}(x^{(i)}) pθ(x(i)) 。
- 计算检验统计量 :攻击者还可以访问一个参考模型 p r e f p_{ref} pref,这个模型与微调后的目标模型相似,但没有用目标用户的数据训练过。攻击者通过公式 T ( x ( 1 ) , ... , x ( m ) ) : = l o g ( p θ ( x ( 1 ) , ... , x ( m ) ) p r e f ( x ( 1 ) , ... , x ( m ) ) ) = ∑ i = 1 m l o g ( p θ ( x ( i ) ) p r e f ( x ( i ) ) ) T(x^{(1)}, ..., x^{(m)}) := log(\frac{p_{\theta}(x^{(1)}, ..., x^{(m)})}{p_{ref}(x^{(1)}, ..., x^{(m)})})=\sum_{i = 1}^{m}log(\frac{p_{\theta}(x^{(i)})}{p_{ref}(x^{(i)})}) T(x(1),...,x(m)):=log(pref(x(1),...,x(m))pθ(x(1),...,x(m)))=∑i=1mlog(pref(x(i))pθ(x(i)))计算检验统计量。直观来讲,如果目标用户的数据参与了模型微调,那么微调后的模型对该用户样本的似然值,相对参考模型会更高,计算出的统计量也会更大。
- 判断用户是否参与微调 :设定一个阈值 τ \tau τ,如果计算得到的统计量 T ( x ( 1 ) , ... , x ( m ) ) > τ T(x^{(1)}, ..., x^{(m)})>\tau T(x(1),...,x(m))>τ ,攻击者就会判定目标用户的数据参与了模型的微调训练;反之,则认为目标用户未参与。
这个威胁模型的关键在于,攻击者仅通过少量来自用户的样本和对模型的黑盒访问(只能查询模型的似然值,不知道模型内部结构和参数),就能尝试推断用户数据是否用于模型微调,揭示了大语言模型在使用用户数据微调时存在的隐私风险。