1、前言
首先要解决的问题就是:多个视觉摄像头,分别提取特征之后如何聚合?
现在流行的趋势是:多模态融合 + 多传感器融合
举例特斯拉的全景视频融合,中间的是鸟瞰图
怎么做到的呢?就是局部特征的一个整合 ,局部特征的聚合投影映射到高维特征空间的表示。

2、BEV(Bird's Eye View)要解决一件什么事(上帝视角光环)
✏️ 跟驾驶相关的视觉任务基本都是多传感器融合,如何融合呢?
✏️ 后融合(结果);前融合(数据);特征级融合(这个是咱们的主题)
后融合,就是多个视角的检测的结果作为汇总,前融合就是先把图像拼接,然后再提取特征图。
特征级融合:最近流行的!每个视角都是有特征的,我们通过卷积等方式提特征,然后做融合!
✏️ 将多传感器特征汇总在3D空间上,在这上面做预测,分析,决策
✏️ 而且BEV空间特征可以更容易拓展到下游任务(3D检测,高精度地图等)
✅ 3D VS 4D
✏️ BEV空间的特征我们可以当作是3D(多个2D视角的信息变成3D)的,但是能不能再拓展一步呢?
✏️ 如果再考虑到时间维度,那就是一个4D特征空间了,包括了时序信息
✏️ 时序特征更适合预测速度,轨迹,检测等任务而且还可以进行'猜想'(在某些场景下,比如模糊,遮挡等场景下)

、特征融合过程中可能遇到的问题
✏️ 自身运动补偿:车在运动,不同时刻之间的特征要对齐
不同时刻采集的数据的所处的空间位置发生了变化,导致特征点发生了错位,因此需要做特征对齐 ,也就是车上的特征和车上的特征做对齐,具体做法就是将历史时刻特征通过运动变化矩阵(如刚体变换),投影到当前时刻的坐标系下面。还有一种做法就是通过神经网络,让他去学习视频中的每一个物体,他自身的运动的状态是什么样子,然后再推理预测。
✏️ 时间差异:不同传感器的采样频率不同、处理延迟不同、触发机制不同,导致它们的数据到达时间不一致,要对齐这部分信息。
✏️ 空间差异:最后肯定都要映射到同一坐标系,空间位置特征也要对齐
✏️ 谁去对齐呢?肯定不是手动完成的,这些都交给模型去学习就好了
✅ BEV最终得到了什么
✏️ 相当于我们在上帝视角下重构了一个特征空间,空间的大小我们自己定义。(这个特征空间可以同时适配多个下游任务,可以做检测,分割等任务)
✏️ 特征空间相当于一个网格(一般的大小是200*200),网格的间隔也可以自己定义,对应精度也会有差异
✏️ 在特征空间中,我们可以以全局的视角来进行预测,特征都给你了,咋用你来定
✏️ 难点:既想做的细致,还想节约计算成本,怎么办?BevFormer它来了
bev这个特征空间不是越大越好,越大意味着计算复杂度会上升。
bev形成的2d空间中,每个点其实是一个高维度向量(形成一个特征空间)。
4、BEVFormer
✅ 比较出名,提供了一个基本框架
✏️ 一个核心:纯视觉解决方案(多个视角摄像头进行特征融合)
BEVFormer 是 2022年 CVPR 的一篇重要论文,提出了一种全新的、端到端的纯视觉 BEV 感知方法。它不是第一个做 BEV 的模型,但它 首次系统地构建了一个通用且高效的框架,被广泛引用和复现。成为后续很多工作的"基础模板"(如 BEVDepth、Occupancy Networks、BEVFormer-v2 等)。
✏️ 两个策略:将Attention应用于时间与空间维度(其实就是对齐特征)
✏️ 三个节约:Attention计算简化,特征映射简化,粗粒度特征空间
✏️ 基本奠定了框架结构:时间 + 空间 + Deformable Attention
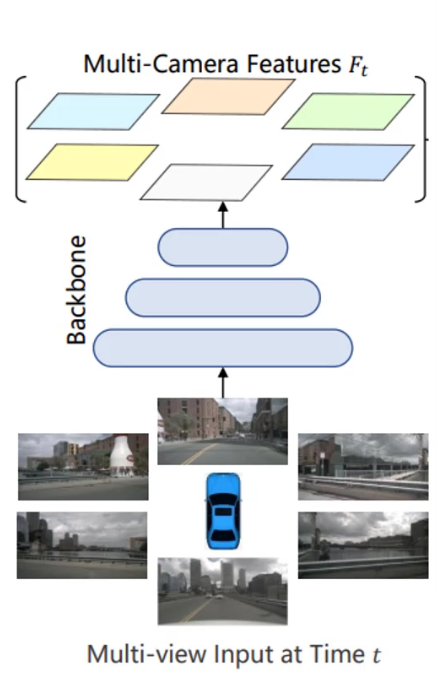
✅ 输入数据格式
✏️ 输入张量 (bs, queue, cam, C, H, W)
|-------|------------------|-----------------------------|
| 维度 | 含义 | 示例值 |
| bs | 批次大小(batch size) | 2 或 4(训练时常用小批量) |
| queue | 时间序列长度(连续帧数) | 2~5 帧(如当前帧 + 前1~4帧) |
| cam | 摄像头数量(每个时刻的视角数) | 6(nuScenes 中为前/后/左/右/左上/右上) |
| C | 图像通道数 | 3(RGB) |
| H | 图像高度 | 256 或 512(取决于预处理) |
| W | 图像宽度 | 512 或 1024 |
✏️ queue 表示连续帧的个数,主要解决遮挡问题。
"queue" 是一个时间队列,表示模型会同时接收 过去若干帧的图像。实现跨帧跟踪 (遮挡)和 运动预测。
✏️ cam 表示每帧中包含的图像数量,nuScenes数据集中有6个。
✏️ C, H, W 分别表示图片的通道数,图片的高度,图片的宽度
输入的6个视觉的CAM数据:
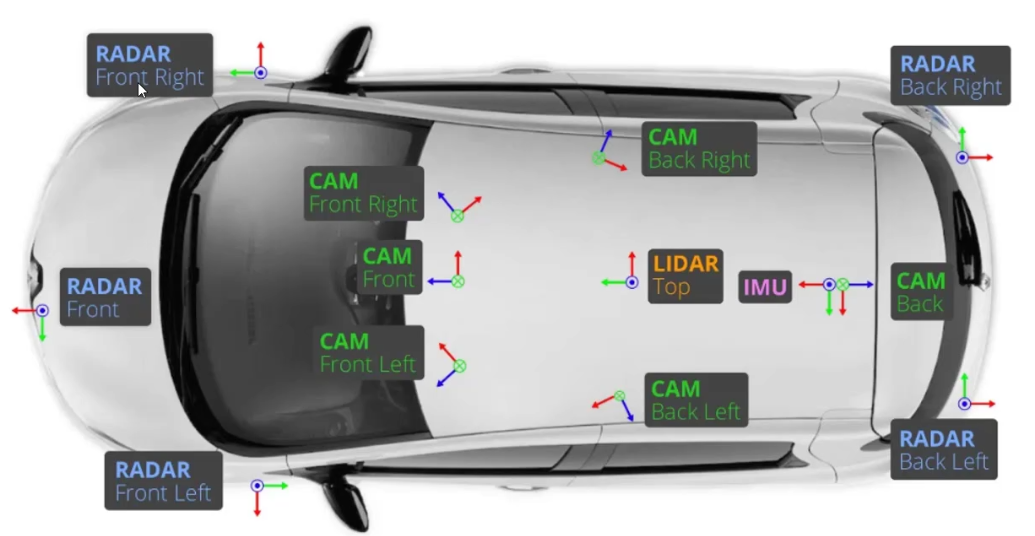
✅ Backbone
✏️ 这步没啥特别的,就是分别提特征就好了
✏️ 基本上啥Backbone都可以,但是最好速度快一些
✏️ 分别得到6个视角下的特征图,给后续空间注意力用
✏️ BEV特征空间中每一个点都要在这些特征中采样
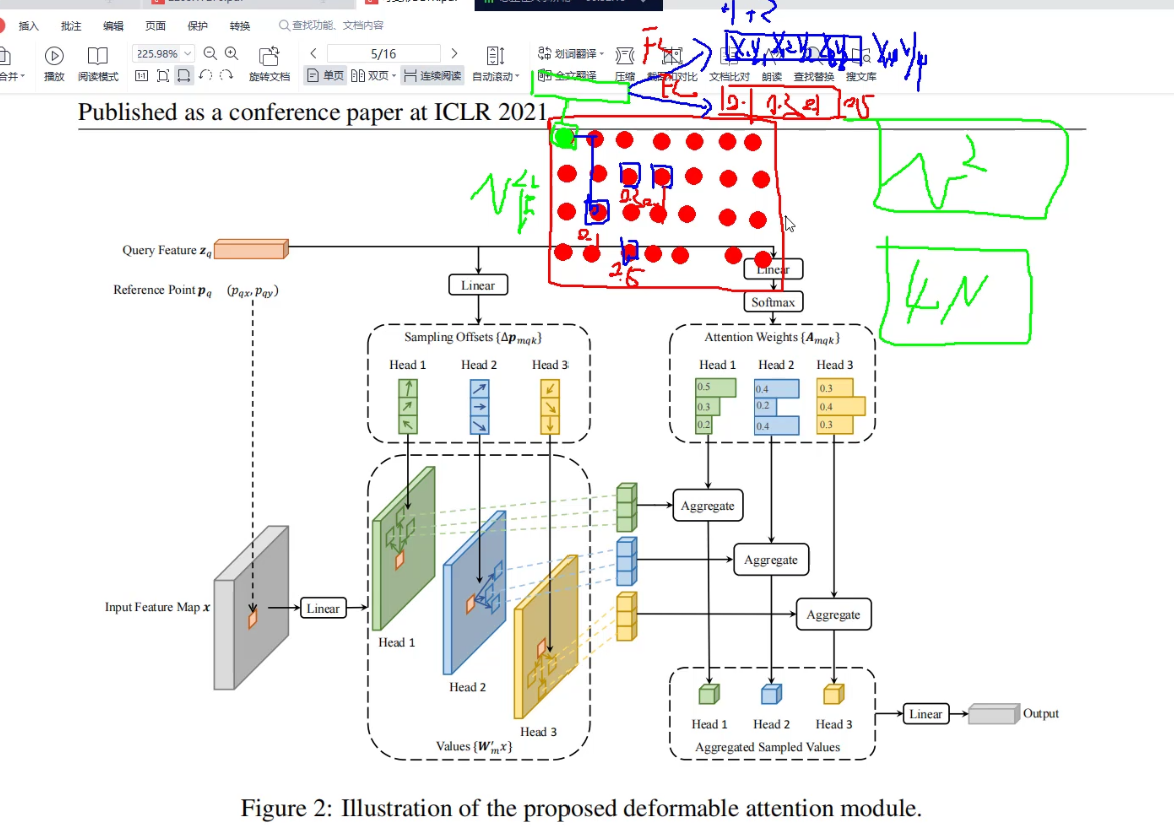
✅ 时间注意力模块
✏️ 类似RNN的方式来利用前面一些时刻的特征
✏️ 在时间上,不同帧中的车和周围物体都会有偏移,如何从历史中选需要的呢?
✏️ 其实依旧是DeformableAttention,这东西现在已经是硬流通货币了

可变形的 注意力机制(可关注之前的DETR,Mask2Former实例分割)
主要计算一个是偏移量(关注当前向量要和谁做注意力机制),另外一个是注意力权重(关注的其他向量和自身计算的注意力权重 )
下图中计算偏移量使用了多头注意力机制,原来论文中标注,不是头数越多越好,4个头反而效果好。
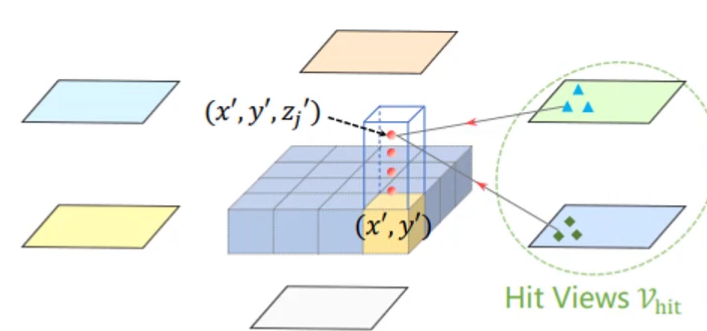
✅ 空间注意力模块
✏️ 要融合多个视角的特征相当于 query 会遍历所有视角找有用的信息
✏️ 3D空间的点要投影到2D空间,但是由于遮挡或者相机内外参不准
✏️ 那么投影点就是一个参考而已,在这个基础上附近再进行特征采样
✏️ 其实依旧是 DeformableAttention 的思想 (Local > point > global)
下图中不同的红色的点代表不同的query,就是一个向量去学习空间上面的知识
✅ 空间注意力模块,计算效率优化
✏️ 如果特征空间是200*200那么就有4W的query
✏️ 4W个query和6个视角特征算Attention,这个有点慢了
✏️ 通过映射已经能得到投影关系,针对每一个视角只选择其中一部分query
✏️ 这样就相当于能把4W个的计算量大约降低成类似6000个(原作者说的)
✅ 后续拓展升级
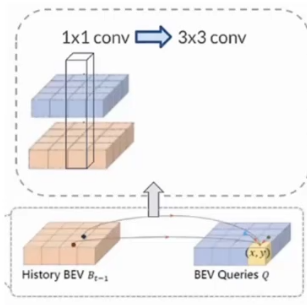
✏️ 偏移量的预测可以用更大的卷积核 1 -> 3
✏️ 多种检测器都可以用,然后做集成

PS:Anchor-based" 和 "Anchor-free" 是目标检测(Object Detection)领域中两种主流的检测范式,它们的核心区别在于 是否依赖预定义的锚框(anchors)来生成候选检测框。
✅ Anchor-Based(基于锚框)
-
定义:在图像上预设大量不同尺度和长宽比的固定框(称为 anchors),作为"先验",然后让网络预测这些 anchor 是否包含目标,并对其位置和尺寸进行微调。
-
流程:
-
在特征图每个位置放置多个预定义 anchor(如 3 scales × 3 ratios = 9 anchors/point)
-
网络输出:每个 anchor 的分类得分 + 偏移量(Δx, Δy, Δw, Δh)
-
通过 NMS(非极大值抑制)筛选最终检测框
-
典型模型:Faster R-CNN、SSD、YOLOv2/v3
✅ Anchor-Free(无锚框)
-
定义:不使用预定义 anchor,而是直接从图像或特征图中预测目标的位置和类别。
-
常见思路:
-
关键点检测:预测物体中心点(如 CenterNet),再回归宽高
-
逐像素预测:每个像素直接预测是否是目标及边界(如 FCOS)
-
端到端集合预测:如 DETR,将检测视为集合预测问题
-
典型模型:CenterNet、FCOS、DETR、YOLOX(部分 anchor-free)
|---------------|--------------------|----------------|
| 维度 | Anchor-Based | Anchor-Free |
| 是否需要预设 anchor | ✅ 需要(大量超参) | ❌ 不需要 |
| 设计复杂度 | 高(需调 anchor 尺寸/比例) | 低(结构更简洁) |
| 计算开销 | 大(成千上万个候选框) | 小(只关注正样本区域) |
| 对小目标敏感度 | 依赖 anchor 密度,可能漏检 | 更灵活,可精准定位中心 |
| 训练效率 | 正负样本极度不平衡(99% 负样本) | 正样本定义清晰,训练更稳定 |
| 推理速度 | 较慢(需 NMS 后处理) | 更快(部分方法无需 NMS) |
| 可解释性 | 强(anchor 有明确物理意义) | 弱(端到端黑盒) |
当前共识:Anchor-free 更适合轻量化、端到端、 BEV 等新兴场景(如自动驾驶中的 BEVFormer 常搭配 FCOS 或 CenterNe
✅ 时间与空间顺序
✏️ 先时间再空间,因为前面时刻BEV有很多信息
✏️ 相当于要充分利用先验知识,在此基础上再
✏️ 继续融合当前帧的特征,从而构建当前BEV
✏️ 重复多次(6次)得到最后的BEV空间特征
5、论文
✅ Abstract
BEVFormer 是一种面向自动驾驶的新型纯视觉感知框架,通过时空 Transformer 学习统一的鸟瞰图(BEV)表示,以支持3D目标检测、地图分割等多种任务。该方法利用预定义的网格状 BEV 查询,在空间和时间维度上分别通过空间交叉注意力和时间自注意力机制进行特征交互:前者使每个 BEV 查询从多摄像头视图的感兴趣区域中提取并融合空间特征,后者则递归地融合历史 BEV 信息以建模时序动态。在 nuScenes 测试集上,BEVFormer 以 56.9% 的 NDS 指标刷新了纯视觉方法的性能纪录,较此前最佳结果提升 9.0 个百分点,达到与激光雷达基线相当的水平;同时在低能见度条件下显著提升了物体速度估计精度和召回率。相关代码已开源(https://github.com/zhiqi-li/BEVFormer)。
✅ BEVformer
将多摄像头图像特征转换为鸟瞰图(BEV)特征,可以为多种自动驾驶感知任务提供统一的周围环境表示。本文提出了一种基于 Transformer 的新框架,用于生成 BEV 特征,该框架能够有效利用注意力机制,从多视角摄像头和历史 BEV 特征中聚合时空信息,从而实现对车辆周围环境的统一建模与理解。
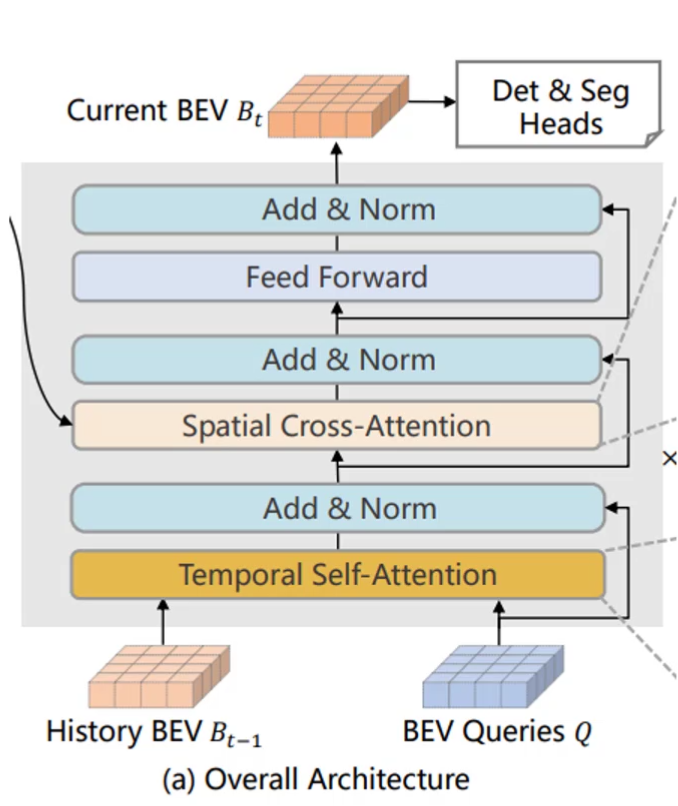
✅ Overall Architecture
BEVFormer 包含 6 个编码器层,每层基于标准 Transformer 结构,但引入了三项关键设计:网格状可学习的 BEV 查询(BEV queries)、空间交叉注意力(spatial cross-attention)和时间自注意力(temporal self-attention)。在推理时,当前时刻 t 的多摄像头图像首先通过骨干网络(如 ResNet-101)提取各视角特征 Ft ,同时保留上一时刻 t −1 的 BEV 特征 Bt −1;每个编码器层先利用 BEV 查询通过时间自注意力从历史 BEV 中获取时序信息 ,再通过空间交叉注意力从当前多视角特征中聚合空间信息 ,经前馈网络后输出优化的 BEV 特征并传递至下一层;经过 6 层堆叠后,最终生成当前时刻统一的 BEV 表示 Bt,并以此作为共享输入,由 3D 检测头和地图分割头分别预测 3D 边界框和语义地图等感知结果。
其他略