概率论是人工智能中处理不确定性的核心工具,它为机器学习、数据科学和统计分析提供了理论基础。本文将深入浅出地介绍概率论的重要概念,并结合 Python 实例,帮助读者更好地理解和应用这些知识。资源绑定附上完整资源供读者参考学习!
5.1 概述
5.1.1 概率论的发展简史
概率论起源于 17 世纪对赌博问题的研究,帕斯卡和费马的通信奠定了其基础。随后,贝叶斯、高斯等科学家的贡献推动了概率论的发展,使其在现代科学中广泛应用。
5.1.2 概率论的主要内容
概率论主要研究随机现象的规律性,包括随机事件、随机变量、概率分布、期望、方差以及大数定理和中心极限定理等。
5.2 随机事件及其概率
5.2.1 随机事件的运算
随机事件的运算包括事件的并、交、差和补集等。这些运算遵循集合运算的规则,用于构建复杂的事件。
5.2.2 随机事件的概率
概率是衡量随机事件发生可能性大小的数值。它满足非负性、规范性和可加性三个基本性质。
5.2.3 条件概率
条件概率是指在事件 B 发生的条件下,事件 A 发生的概率,记为 P(A|B)。其计算公式为 P(A|B) = P(AB)/P(B),其中 P(B) ≠ 0。
综合案例及应用:抛掷骰子事件
案例描述 :计算抛掷两个骰子时,点数之和大于 8 的概率。
python
import itertools
# 生成所有可能的骰子点数组合
dice_rolls = list(itertools.product(range(1, 7), repeat=2))
# 计算有利事件数目
favorable_outcomes = [roll for roll in dice_rolls if sum(roll) > 8]
# 计算概率
probability = len(favorable_outcomes) / len(dice_rolls)
print("抛掷两个骰子点数之和大于 8 的概率为:", probability)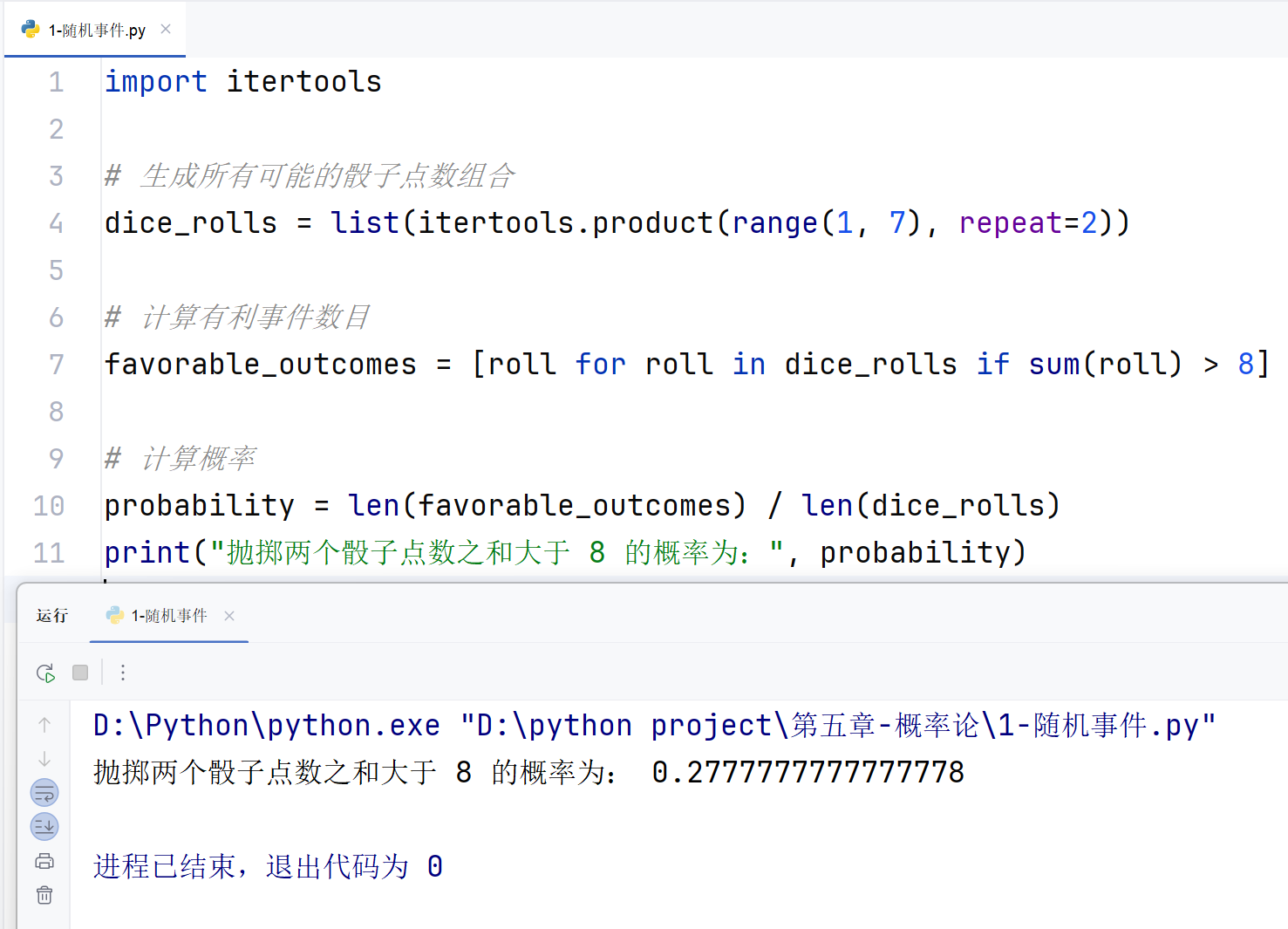
5.3 随机变量
5.3.1 随机变量的概率分布
随机变量的概率分布描述了随机变量取各个可能值的概率规律。常见的分布包括离散型(如二项分布、泊松分布)和连续型(如正态分布、指数分布)。
5.3.2 随机变量的数字特征
数字特征包括期望(均值)、方差和标准差,用于描述随机变量的集中趋势和离散程度。
5.3.3 常见的概率分布
-
二项分布 :描述 n 次独立伯努利试验中成功的次数。
-
泊松分布 :描述单位时间(或空间)内随机事件发生的次数。
-
正态分布 :自然界中最常见的分布之一,具有钟形曲线。
-
指数分布 :描述泊松过程中的事件发生间隔时间。
综合案例及应用:正态分布的概率计算
案例描述 :计算某地成年人身高服从均值为 170cm,标准差为 10cm 的正态分布,求身高在 160cm 到 180cm 之间的概率。
python
import numpy as np
import scipy.stats as stats
# 正态分布参数
mu = 170 # 均值
sigma = 10 # 标准差
# 计算概率
prob = stats.norm(mu, sigma).cdf(180) - stats.norm(mu, sigma).cdf(160)
print("身高在 160cm 到 180cm 之间的概率为:", prob)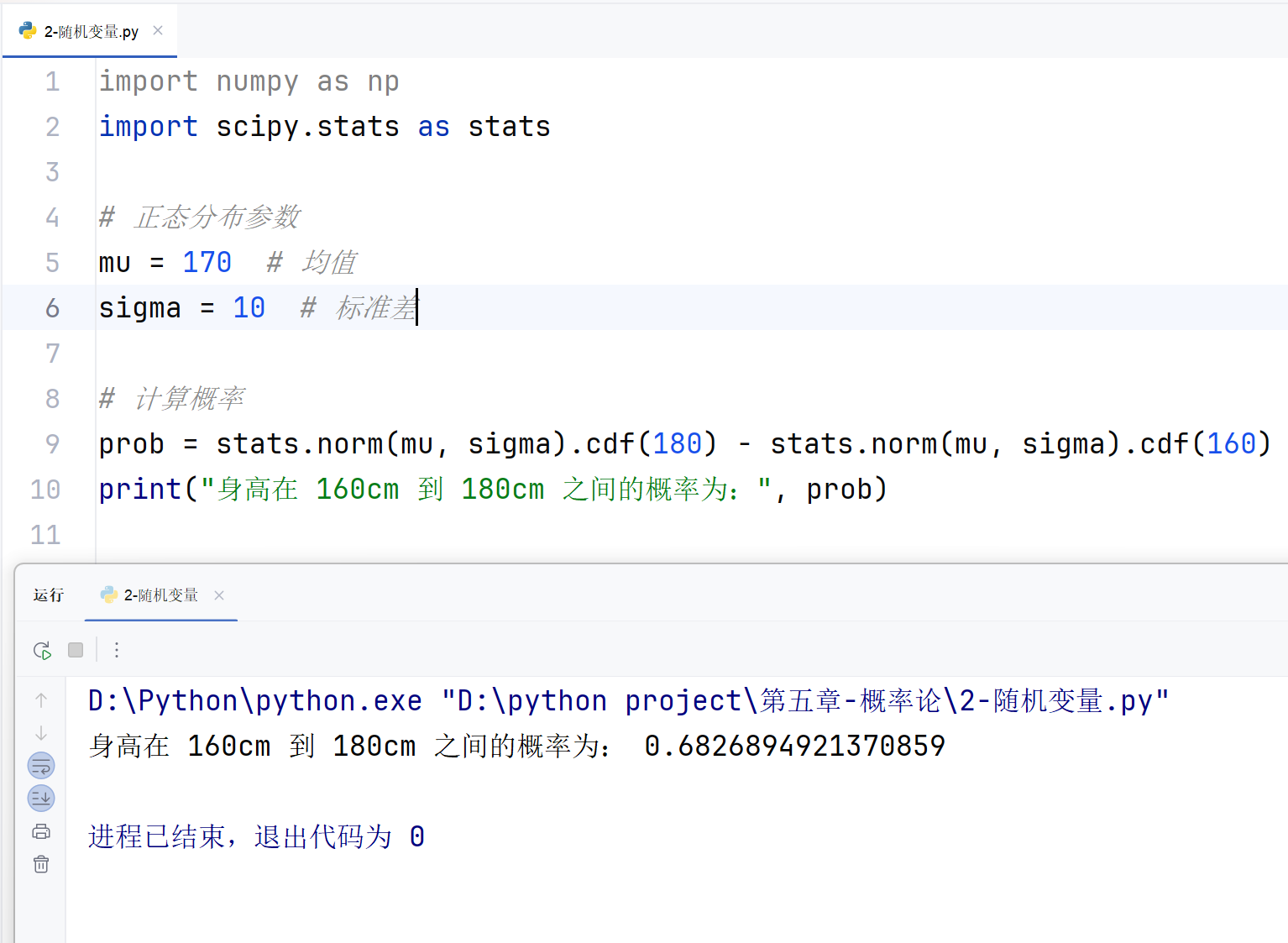
5.4 贝叶斯理论
5.4.1 贝叶斯公式的推导
贝叶斯公式是基于条件概率的逆概率计算公式,用于更新事件发生的概率。公式为 P(A|B) = P(B|A)P(A) / P(B)。
5.4.2 贝叶斯公式的应用举例
在医学诊断、垃圾邮件过滤等领域,贝叶斯公式可用于更新事件发生的概率。例如,计算患者患病的概率。
5.4.3 贝叶斯理论的前景
贝叶斯理论在机器学习中具有重要地位,如贝叶斯分类器、贝叶斯网络等。它为模型的不确定性和概率推理提供了有力工具。
综合案例及应用:疾病诊断
案例描述 :某疾病的发病率为 0.1%,检测该疾病的实验准确率为 99%(即患者检测为阳性的概率为 99%,非患者检测为阴性的概率为 99%)。求某人检测为阳性时患病的概率。
python
# 疾病发病率
p_disease = 0.001
# 检测准确率
p_positive_given_disease = 0.99 # 患者检测为阳性的概率
p_negative_given_healthy = 0.99 # 非患者检测为阴性的概率
# 计算贝叶斯公式中的各项
p_positive = p_disease * p_positive_given_disease + (1 - p_disease) * (1 - p_negative_given_healthy)
# 计算患病概率
p_disease_given_positive = (p_positive_given_disease * p_disease) / p_positive
print("检测为阳性时患病的概率为:", p_disease_given_positive)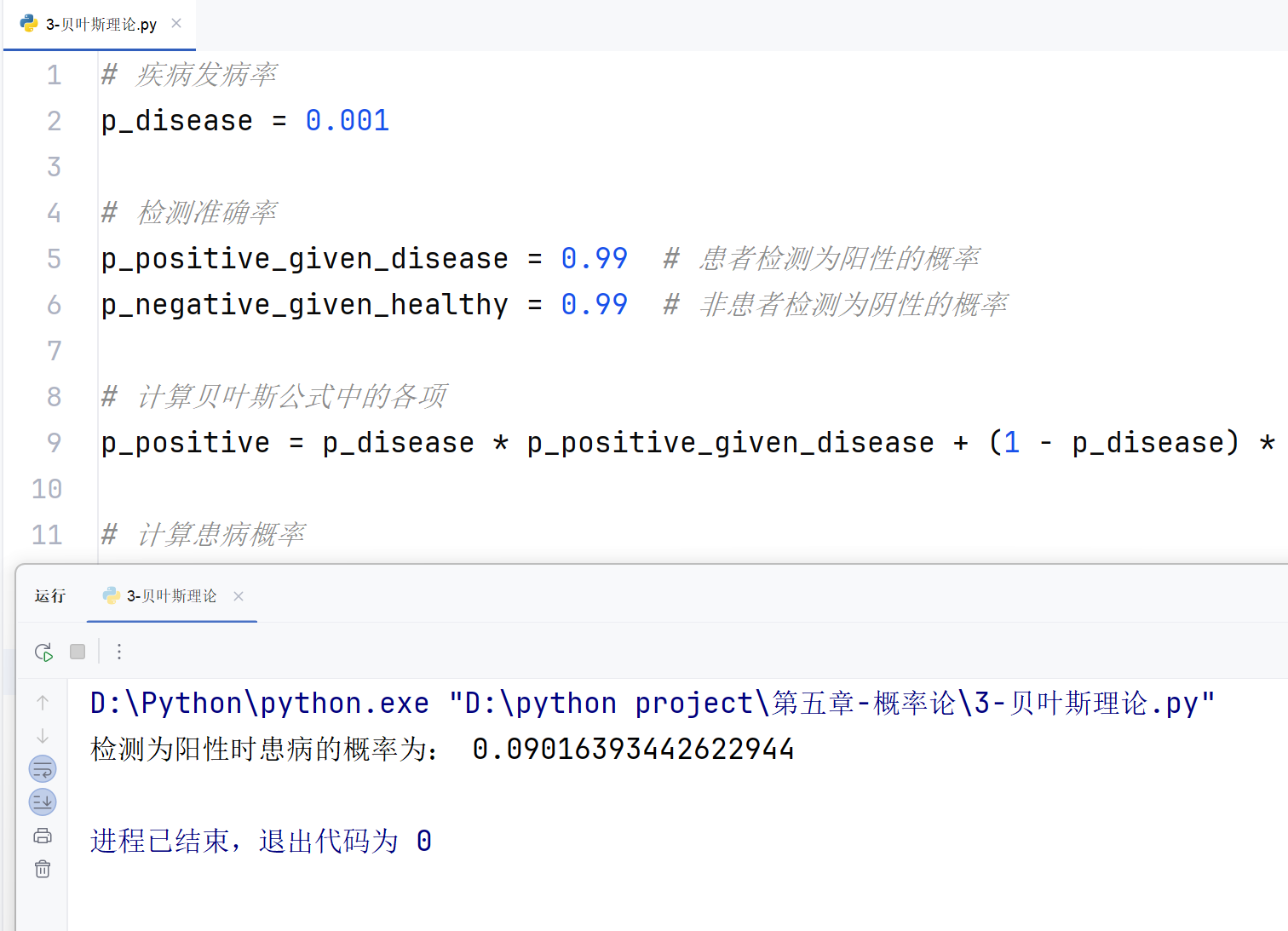
5.5 极限理论
5.5.1 收敛
收敛是指随机变量序列逐渐趋近于某个值或分布的过程。包括几乎必然收敛、依概率收敛和依分布收敛等。
5.5.2 大数定理
大数定理说明,随着试验次数增加,事件发生的频率逐渐稳定于其概率。例如,伯努利大数定理表明,事件发生的频率依概率收敛于其概率。
5.5.3 中心极限定理
中心极限定理指出,大量独立同分布的随机变量之和近似服从正态分布。这解释了正态分布在自然现象中的普遍性。
综合案例及应用:中心极限定理仿真实验
案例描述 :从均匀分布中抽取大量样本,计算样本均值,并验证中心极限定理。
python
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 抽取样本并计算均值
sample_means = []
for _ in range(10000):
sample = np.random.uniform(0, 1, 100)
sample_means.append(np.mean(sample))
# 绘制直方图
plt.figure(figsize=(8, 6))
plt.hist(sample_means, bins=30, density=True, alpha=0.6, color='g')
plt.xlabel('样本均值')
plt.ylabel('频率')
plt.title('中心极限定理仿真实验')
plt.grid(True)
plt.show()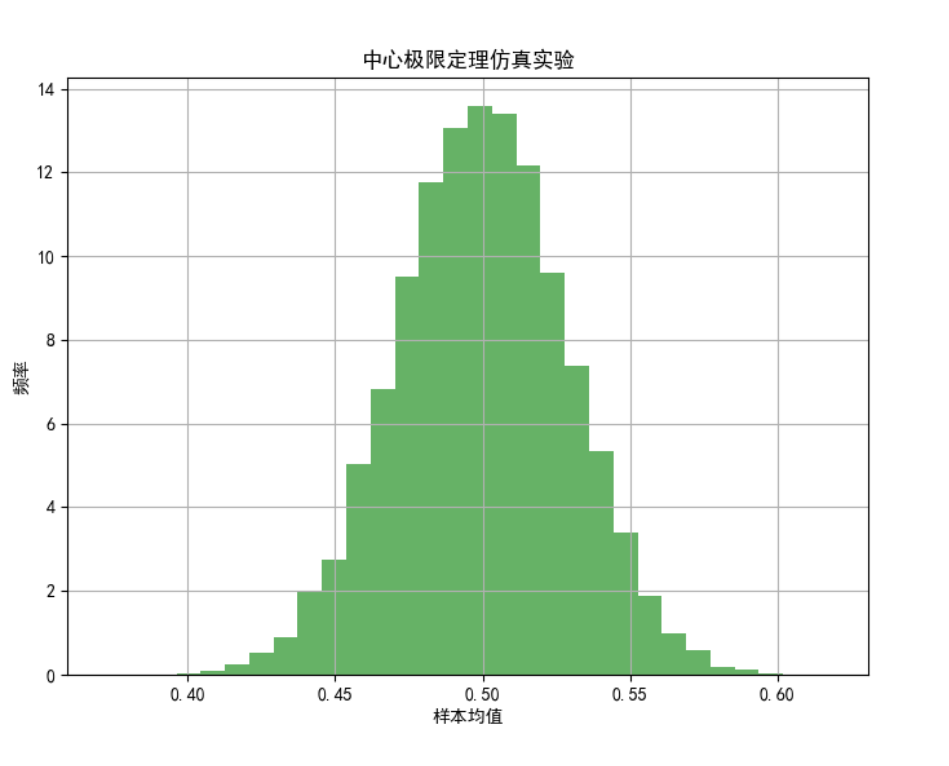
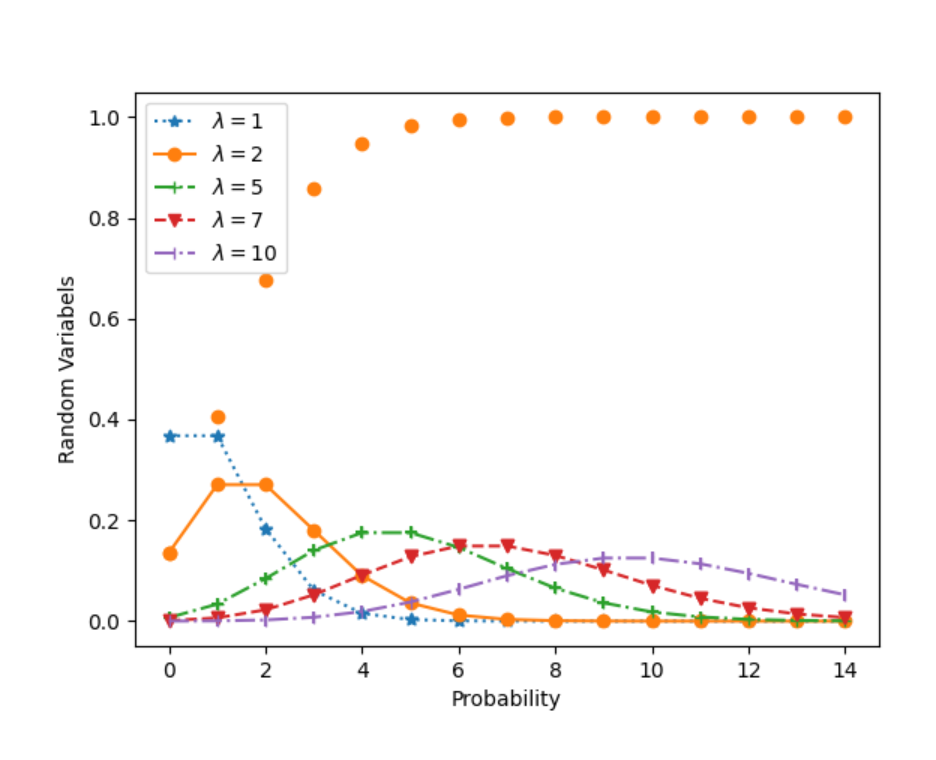
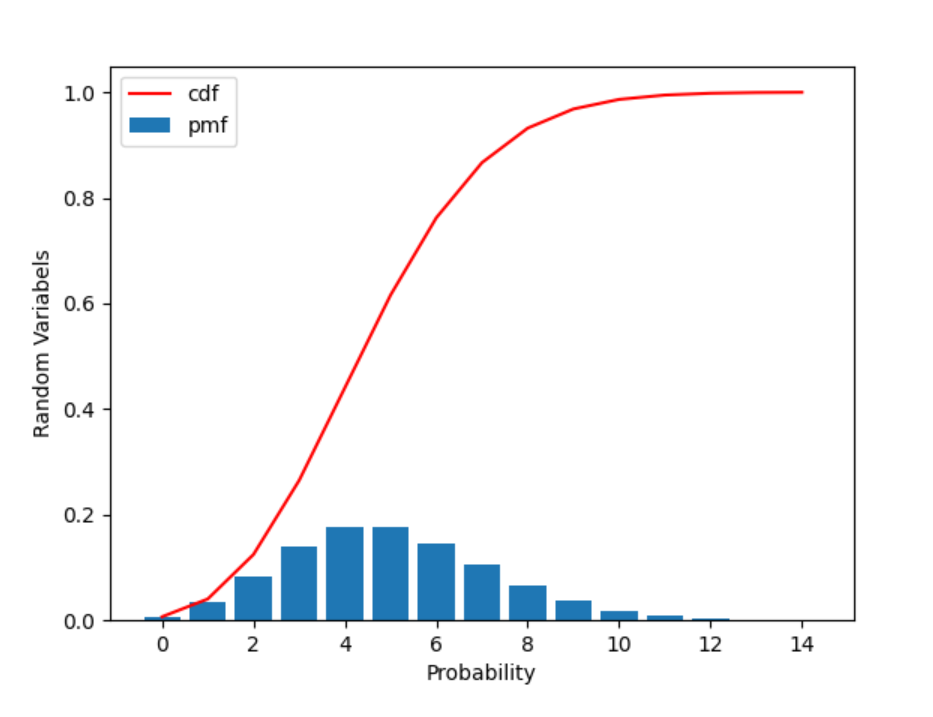
5.6 实验:基于 Python 的泊松分布仿真实验
5.6.1 实验目的
理解泊松分布的特点,并掌握使用 Python 进行泊松分布模拟的方法。
5.6.2 实验要求
生成泊松分布的随机样本,绘制其概率质量函数,并计算其期望和方差。
5.6.3 实验原理
泊松分布用于描述单位时间(或空间)内随机事件发生的次数,其概率质量函数为 P(X=k) = λ^k e^{-λ} / k!,其中 λ 是平均发生率。
5.6.4 实验步骤
-
导入必要的 Python 库(NumPy 和 Matplotlib)。
-
设置泊松分布的参数 λ。
-
生成泊松分布的随机样本。
-
计算样本的均值和方差。
-
绘制泊松分布的概率质量函数。
5.6.5 实验结果
python
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置参数
lam = 2 # 泊松分布的平均发生率
num_samples = 10000 # 生成的样本数量
# 生成泊松分布的随机样本
samples = np.random.poisson(lam, num_samples)
# 计算样本均值和方差
sample_mean = np.mean(samples)
sample_variance = np.var(samples)
print("样本均值:", sample_mean)
print("样本方差:", sample_variance)
# 绘制概率质量函数
k = np.arange(0, 10)
pmf = stats.poisson.pmf(k, lam)
plt.figure(figsize=(8, 6))
plt.bar(k, pmf, align='center', alpha=0.6)
plt.xlabel('随机变量取值')
plt.ylabel('概率')
plt.title('泊松分布概率质量函数')
plt.grid(True)
plt.show()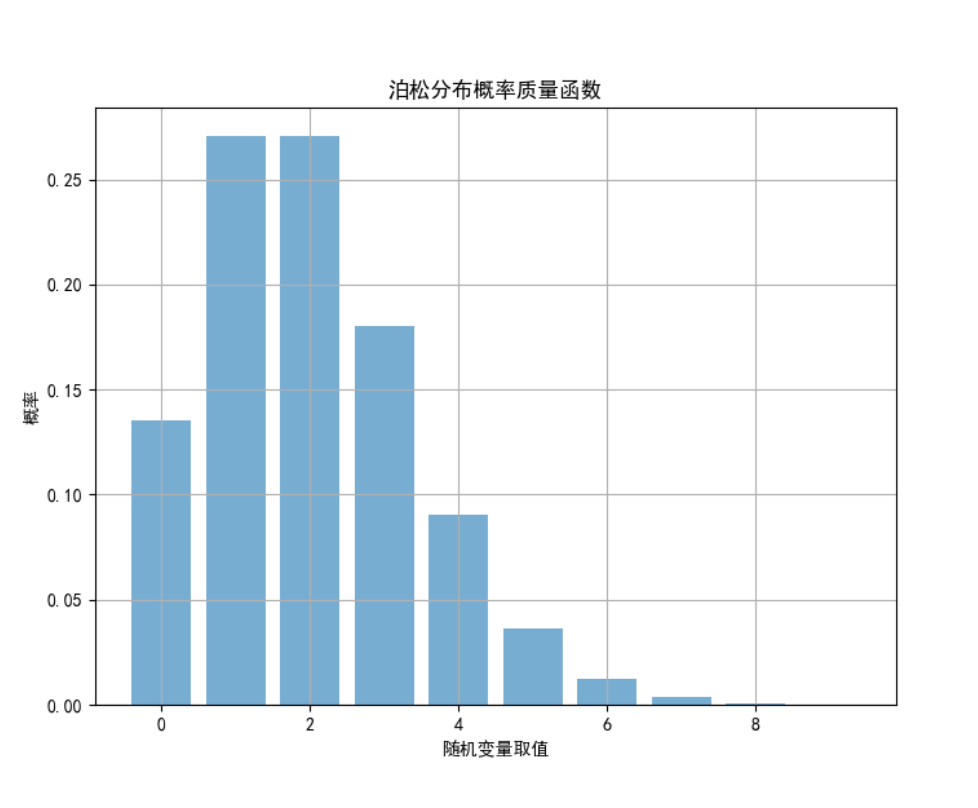
5.7 概率论知识点表格总结
| 概念 | 定义与说明 | 常见应用 |
|---|---|---|
| 随机事件 | 在随机试验中可能出现的结果 | 事件的并、交、差、补集 |
| 随机变量 | 将随机事件映射为数值的变量 | 离散型和连续型随机变量,概率分布,期望,方差 |
| 贝叶斯公式 | 基于条件概率的逆概率计算公式 | 垃圾邮件过滤,疾病诊断 |
| 极限理论 | 研究随机变量序列的收敛性和大样本性质 | 大数定理,中心极限定理 |
通过本文的学习,希望大家对概率论在人工智能中的应用有了更深入的理解。在实际操作中,多进行代码练习,可以更好地掌握这些数学工具,为人工智能的学习和实践打下坚实的基础。资源绑定附上完整资源供读者参考学习!