运行游戏,查看当前调试层级的状态。
我们正在直播中开发一个完整的游戏,目前正进行调试代码的整理和清理工作。现在我们直接进入正题,虽然还不完全确定今天要完成哪些具体内容,但有几个明确的目标:
首先,我们打算完善调试目标(Debug Target)的设置方式,这是我们之前已经开始做但还没有完成的部分。同时,我们也希望开始整理性能分析视图(Profile View)的逻辑,让其运行得更加清晰和整洁。
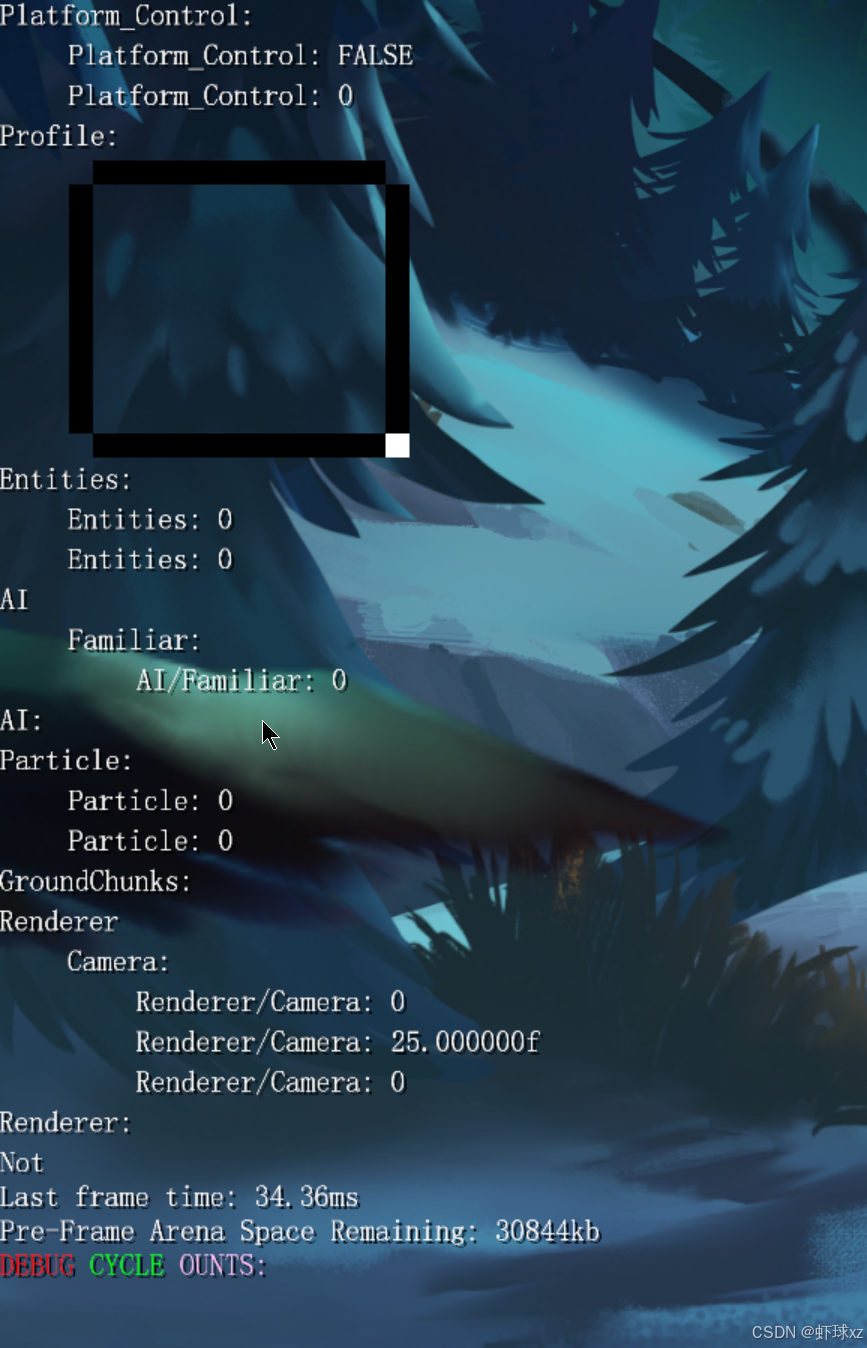
从目前调试层级结构的状态来看,已经完成了大部分框架,并且已经有一个用于展示性能数据的空间。但现在这个区域还没有实际内容,所以这是后续需要补充的部分。
当前我们聚焦的,是完成调试界面中各项数据的读取与编辑功能。现在虽然路径读取已经正常,但调试项的名称显示仍不正确;此外,尚未启用对这些项的编辑功能,这也是我们今天希望完成的内容。
编辑功能可能涉及较多的代码实现,处理起来需要花费一定时间,因此这是我们今天的主要目标。
如果进展顺利、时间充裕,可能会提前开始性能分析功能的实现。但更可能的是,今天先完成调试项的编辑系统,下周再集中处理性能分析数据的可视化部分。
总之,当前的开发重点是完成调试信息结构的显示与编辑,为下一阶段的性能分析系统打好基础。
打开 game_debug.cpp,查看当前调试层级是如何构建的。
我们正在继续调试系统的开发,这一部分主要处理调试事件在层级结构中的显示问题,特别是它们的命名格式。目前的问题在于事件的名称打印出来不是我们期望的形式。
首先我们查看了一下调试事件是如何被放入层级结构中的。事件被插入时,我们会尝试从完整路径中提取名称------通过查找路径中最后一个斜杠后面的部分来作为最终显示名称。但是现在显示的内容并不正确,所以我们需要仔细梳理层级构建的逻辑,并确保路径的处理逻辑完全正确,最终呈现出我们希望看到的标签格式。
在现有实现中,调试块会作为层级结构中的节点存在,每个调试块内部包含的调试事件会在之后动态输出。我们找到了具体的渲染调试块的函数,并注意到当前做法是将整个数据块作为一个节点来输出,并不是将其中的事件直接作为层级结构的一部分。
这种处理方式的好处是可以支持多个相同类型的数据块独立显示,但它也带来了层级结构中无法准确显示具体事件的问题。我们考虑是否应该改变策略,让每次遇到调试事件时都直接将其插入到层级结构中,而不是延后到输出阶段才渲染。
这样做可以简化处理逻辑,不过也可能会牺牲对重复数据块的管理能力,因此需要权衡是否要进行结构性的调整。
我们在打印事件名称的过程中,注意到事件是通过一个叫做 StoreEvent 的过程被加入的。在这个过程中,会调用一个生成名称的函数 GetName,这个函数返回的是完整路径名,包括路径中的斜杠,因此现在我们看到的渲染结果中包含了像 Render/Slice/Camera 这样的名称。
这本身是合理的,但令人困惑的是,路径最后一部分的名字似乎并没有正确显示出来。我们预期看到的是最后一级名称,比如 "Camera",但实际显示可能缺失了这一部分。为了解释这一点,我们需要回溯查看当初是如何构建用于打印的 DebugValue 数据的,分析是否在构造调试项时就丢失了这部分信息。
总的来说,当前的目标是:
- 确保事件名称正确显示,尤其是路径中最后一级;
- 决定是否改变层级结构的构建方式,让调试事件直接插入层级结构;
- 清理并统一调试输出逻辑,保证名称处理的一致性与正确性;
- 为后续性能分析等系统打好稳定的数据展示基础。
这些任务是我们今天要优先解决的问题。
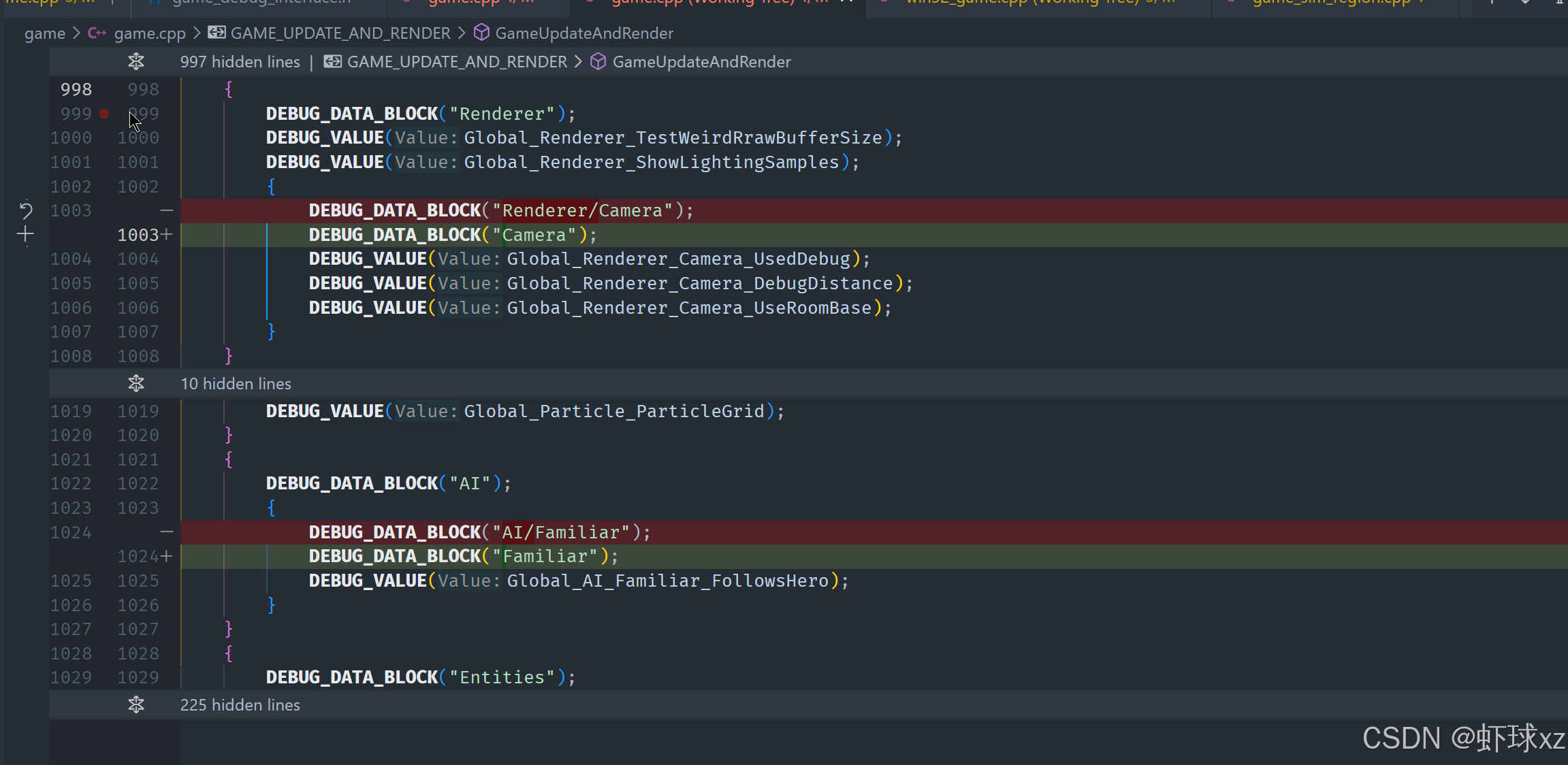
现在问题来了为什么Camera 没有在Renderer下面
之前没改完
修改一下变量
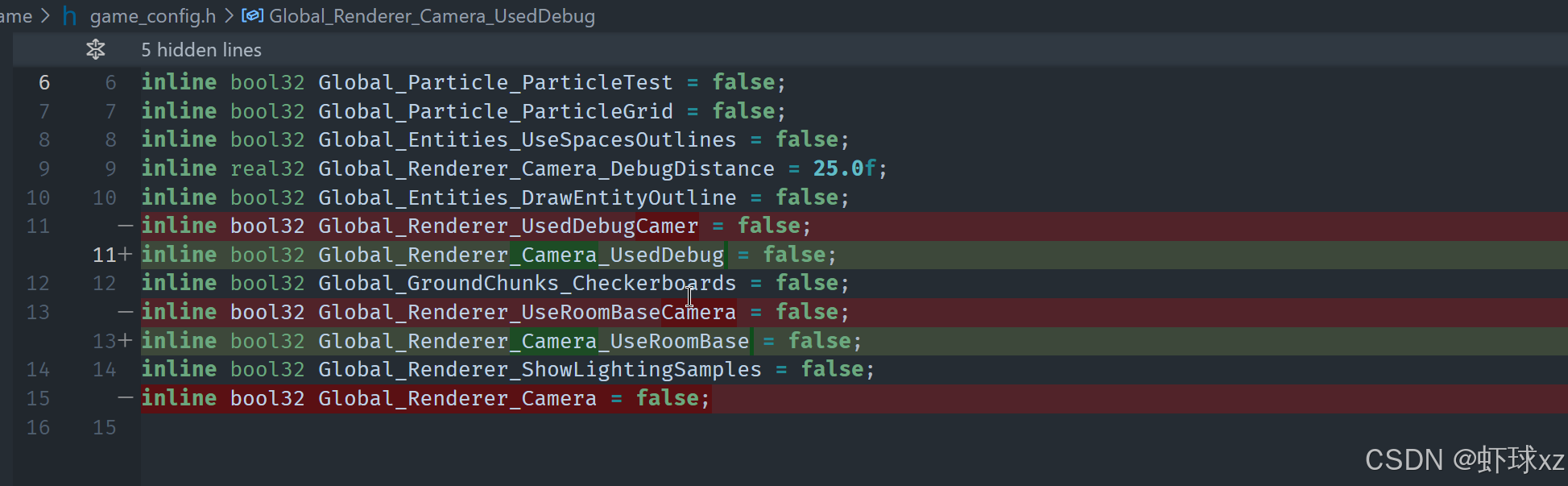

打开 game.cpp,指出 DEBUG_VALUE 本应出现在调试视图中。
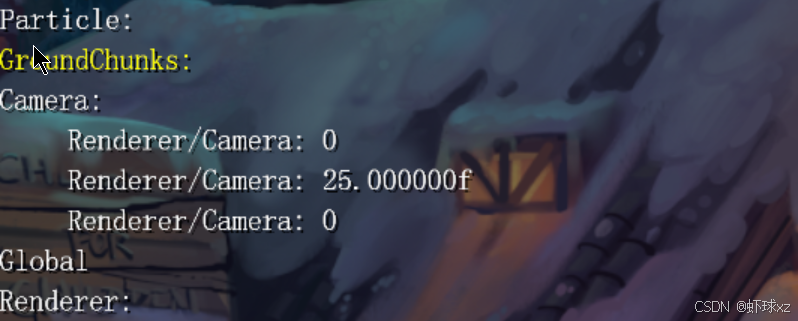
目前我们在调试视图中看到一个名为 Render/Camera 的数据块,按照预期,这个数据块内部应该包含多个调试值,而这些调试值的命名本应是非常具体的、完整路径的名称,例如 Global/Render/Camera/UseDebug 之类的内容。
然而现实中看到的并非如此。实际渲染出来的内容并没有体现出这些调试值应有的完整名称,看起来像是调试值只继承了所属调试块的名称,而没有保留它们自身的独立命名信息。
这不是我们想要的效果,我们希望每一个调试值都带有其完整的路径和具体名称,而不是只是简单的挂靠在其所属的调试块名下。也就是说,在调试层级中,不应仅显示调试块的名字,而是每个调试值应各自具名,并反映其在代码逻辑中的真实路径。
我们怀疑问题可能出在调试值写入或记录的过程中。当前很可能是调试值的名称在处理时被错误地替换成了调试块的名字,或者调试块在插入到层级结构时没有正确附带下属调试值各自的路径信息。
接下来,我们需要快速确认一下调试值在写入时是否正确传递了它们自己的名称信息。如果名称在创建过程中就被错误地设置了,那就会直接导致后续的显示异常。从行为上来看,这种"名称错位"的情况与我们观察到的问题表现是高度一致的。
因此,接下来的工作重点包括:
- 确认调试值在生成时是否带有自己的完整路径名;
- 检查调试块在输出调试值时是否错误地覆盖或忽略了这些名称;
- 修改层级构建逻辑,确保调试值能以正确的路径名独立显示在调试视图中;
- 保证调试信息在层级结构中有清晰准确的来源识别,以方便调试和性能分析。
这个问题虽然看起来是显示异常,实则关系到整个调试系统的信息准确性,需要尽快修正。
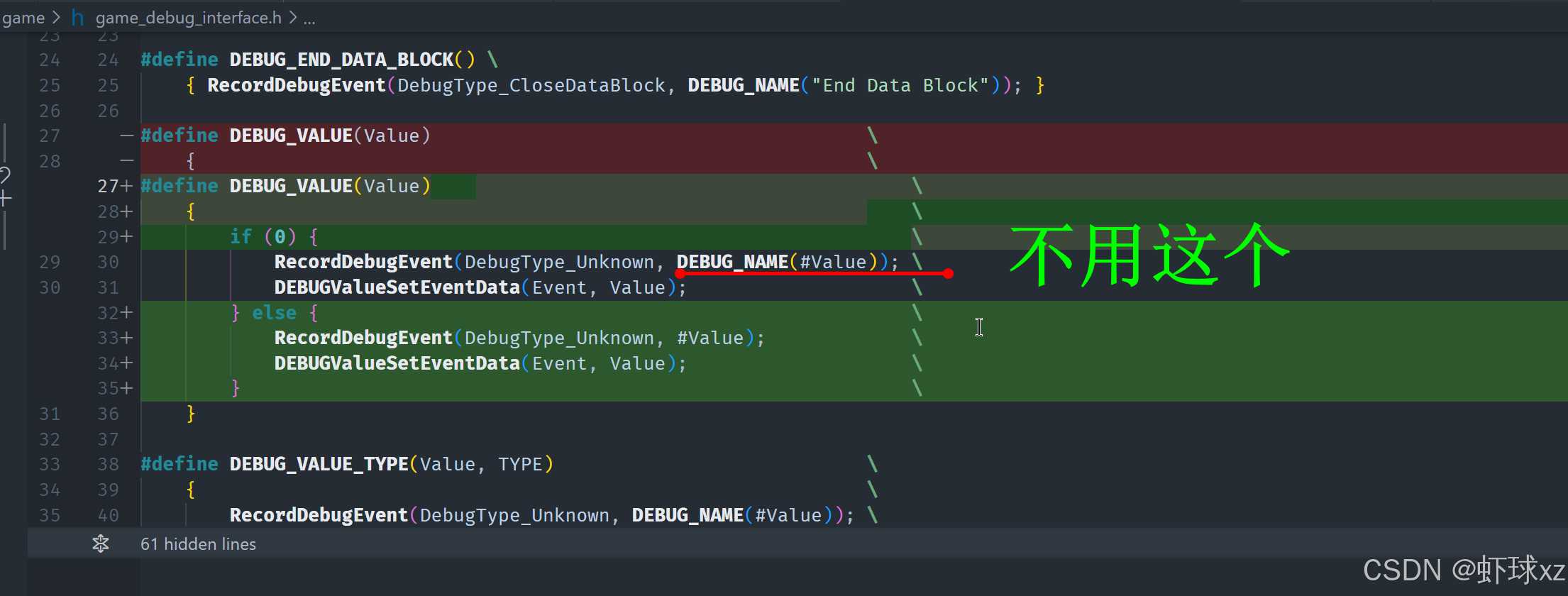
查看 game_debug_interface.h,确认 DEBUG_VALUE 的设置是否正确。
当前我们在调试系统中发现一个明显的问题:虽然我们在记录调试事件时,确实传入了带有完整路径的调试名称(例如 Global/Render/Camera/UseDebug),但实际在调试视图中却未能正确显示出这个名称,显示的名称更像是仅来自上层调试块的名字(例如只是 Render/Camera),这显然不符合预期。
具体分析如下:
- 我们可以确认,在调用
RecordDebugEvent时,已经传入了一个完整的调试名称,这个名称是通过某种方式组合的字符串(例如通过SetEvent传入),内容应当包括整个调试值的路径。 - 调试值在创建的时候通过
SetEvent接收了这个名称,并与数值(如某个开关变量)一起存储,因此按理说调试系统应已拥有了正确的名称。 - 但我们回到调试界面(例如 game debug 系统)时,实际显示的名称却并不包含完整路径,而是落回到了某个上层或父级节点的名称,说明中间某个环节发生了覆盖、截断或替换。
目前的怀疑点包括:
- 调试值名称在传递过程中被错误覆盖或截断:可能在进入调试系统内部进行层级构建时,错误地用调试块的名字取代了调试值原有的完整路径。
- 层级构建逻辑未使用调试值自身携带的名称:可能当前是通过父节点(调试块)来构造子项路径,而不是完全依赖调试值本身携带的路径信息,导致结构错误。
- 调试视图渲染部分获取了错误的名称来源:可能 UI 层或调试值抽取逻辑中,取用了不应使用的字段(如只取了 block name 而不是 value name)。
接下来的工作步骤应包括:
- 回溯
GameDebug.cpp中相关调试值插入逻辑,确认调试值的名称是否原封不动地传入了调试结构。 - 核查调试事件被存入调试树结构时,是否使用了正确的名称源字段。
- 修正调试视图渲染中名称获取逻辑,确保调试值节点显示的是自身携带的完整路径名,而非其所在调试块的名称。
总之,虽然调试事件的生成阶段是正确的,但在调试视图中名称却显示错误,这很可能是后续存储或展示过程中的名称使用错误,需要逐步排查并修复。目标是确保调试树结构能够完整、准确地展示每一个调试值的实际路径,便于分析和维护。
回到 game_debug.cpp,调查为什么 DEBUG_VALUE 没有按预期出现。
当前在调试系统中,我们已经深入到绘制调试界面的核心路径,并试图厘清调试值显示名称不正确的根本原因。我们已经定位到调试值的绘制是通过 DebugDrawEvent 函数完成的,并确认正常情况下每个元素绘制都会走这条路径。
具体分析如下:
1. 正常绘制流程回顾:
我们已经知道:
- 每当需要绘制一个调试元素时,程序会调用
DebugDrawEvent。 - 在
DebugDrawEvent内部,会从之前保存的事件数据结构中取出一个StoredEvent。 - 该
StoredEvent中包含我们记录时存入的调试信息,比如事件类型、值以及最关键的------事件名称。
2. 名称的提取与显示:
- 当调用
DebugDrawEvent后,会进一步调用DebugEventToText。 - 在
DebugEventToText中,会调用AddName()方法,将事件的名称字符串从存储结构中提取出来加入最终绘制文本中。 - 名称的具体来源,是事件中的
GUIDIndex对应的字符串数据,这一点我们之前已经确认过。
按理说,这样整个流程是没有问题的,事件名称也确实应该是我们在记录事件时传入的完整路径(例如 Global/Render/Camera/UseDebug)。
3. 当前问题表现:
但实际我们在调试窗口中看到的却是不完整或错误的名称 ,更像是某个调试块的名称(比如 Render/Camera)而不是完整的调试值路径。
4. 当前怀疑与分析:
我们推测现在出现的情况可能是以下几种原因之一:
- 绘制路径走错 :虽然我们假设走了
DebugDrawEvent,但可能某些情况下绘制路径发生变化,比如另有特殊分支未走我们检查的代码,导致显示信息异常。 - 事件绑定错位 :可能
StoredEvent中绑定的调试值与原始名称不匹配,被错误地替换为其它数据。 - 事件名称未正确保存在结构中 :也可能是
SetEvent时没有正确传入全名(或者后续被替换掉了),虽然看似代码上是传入了完整名称。 - 事件输出时处理逻辑错误:在最终显示事件时,可能在某个环节中未使用或覆盖了原本事件携带的名称。
5. 接下来行动方向:
- 验证事件是否正确进入
DebugDrawEvent路径:加入临时断点或日志,确保每个绘制调用确实进入我们检查的函数。 - 检查
StoredEvent的名称字段实际内容 :在调试阶段输出StoredEvent->Event.Name,确认其是否是预期的完整路径。 - 复查事件创建过程是否有中间改写名称的可能 :尤其是
SetEvent前后,或PushDebugEvent时是否存在路径截断、合并、替换的操作。 - 定位是否还有其他事件绘制路径 :确保没有某些调试值是通过其他函数(非
DebugDrawEvent)绘制的。
总结:
我们现在几乎确定所有逻辑在流程上是正确的,绘制路径是统一的,名称字段也应该来源正确,但最终却仍出现了错误的名称显示,这表明问题可能出在某个不明显的细节,比如:
- 字符串处理中的截断、
- 缓冲区替换、
- 或者值的复用错误。
下一步应着重验证调试值实际传递过程中是否完整保留了原始路径名,并进一步查明是否在 StoredEvent 中被替换、覆盖或遗漏。只要能准确定位到值的来源与当前显示的不一致,就能彻底解决这个问题。
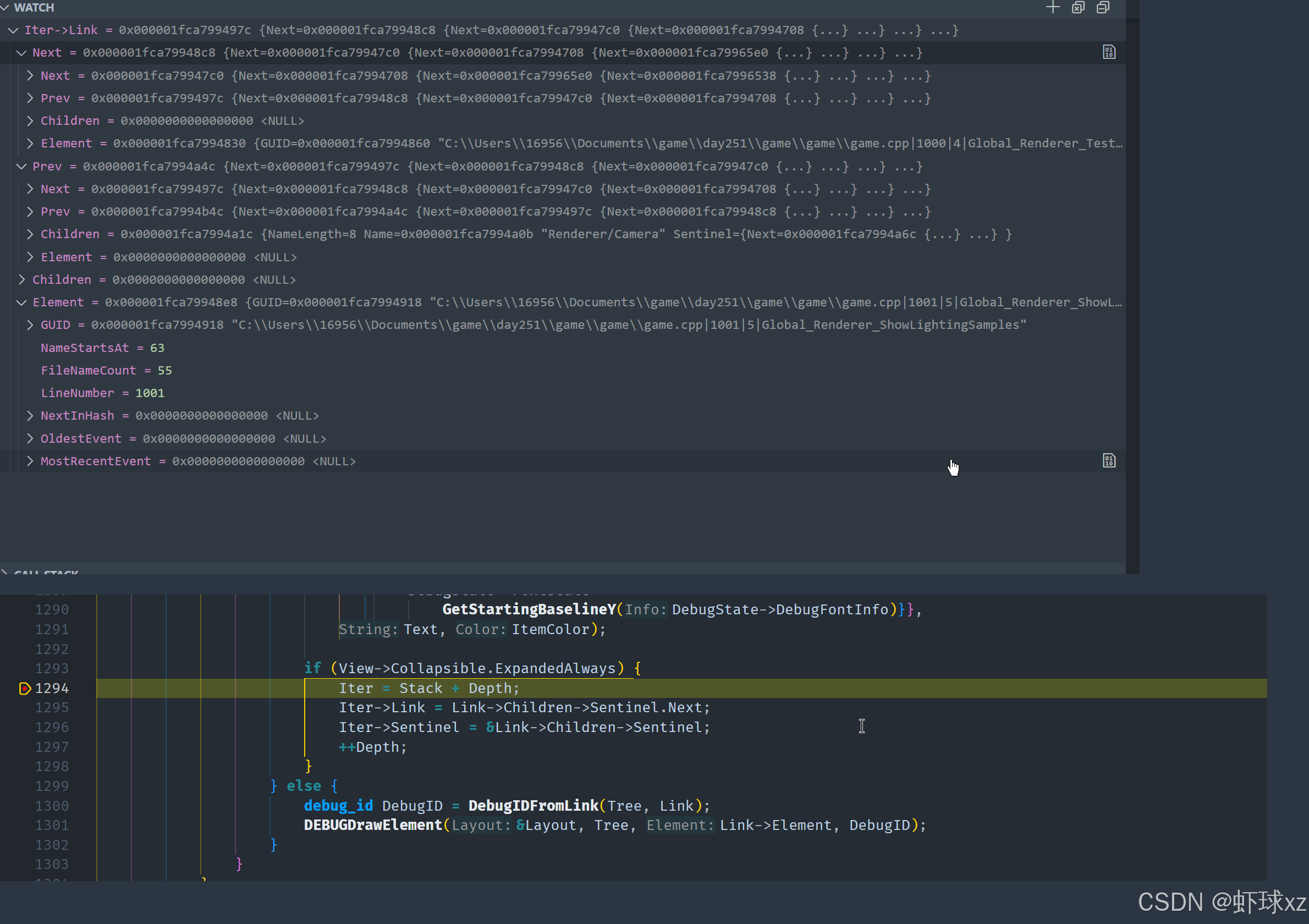
使用调试器:单步进入 DEBUGDrawEvent 并检查事件数据。
我们接下来检查了遍历期望的数据块时的具体情况,目的是观察这些调试事件的实际结构,确认其中的信息是否如预期那样被正确保存和传递。
分析过程与意图:
- 当前我们进入了一个数据块遍历的逻辑中。
- 意图是查看其中包含的调试事件列表,明确这些事件在被记录时是否保留了应有的信息。
- 主要关注的是事件的结构中是否含有完整的调试路径名称、值、类型等关键数据。
初步观察结果:
- 当前查看到的某个事件结构显示得还算清晰,看上去是一个调试事件被正常生成并记录。
- 事件中包含的字段看上去齐全,没有明显的丢失。
- 这也可能意味着,在事件生成时数据是正常的,问题出在后续使用或显示阶段。
推测:
目前没有完全深入每个事件的所有细节字段,但从初步观察看,事件在遍历时至少基本结构是完整的,并未出现明显的缺失或错误。接下来还需要继续深入分析每一个字段(尤其是名称字段)的内容是否准确,才能进一步排除或确认问题源头。
接下来的方向:
- 仔细检查事件的名称字段内容,确认是否是预期的调试路径全名。
- 确保调试事件没有在后续处理流程中被截断或替换名称。
- 检查遍历顺序和事件种类,确认是否有异常结构混入。
目前整体判断倾向于:事件在记录阶段是正常的,问题可能发生在展示层面,例如绘制名称时使用了错误的字段,或某个中间变量被错误地复用或替换。继续验证即可逐步缩小问题范围。
问题的根源出在更上游的逻辑中。因为在当前阶段我们已经错误地得到了类似 "renderer/camera" 这样的名字,而这种名称本不应该在这个阶段出现,意味着问题并不是发生在显示阶段,而是在调试事件存储时就已经出现了错误。
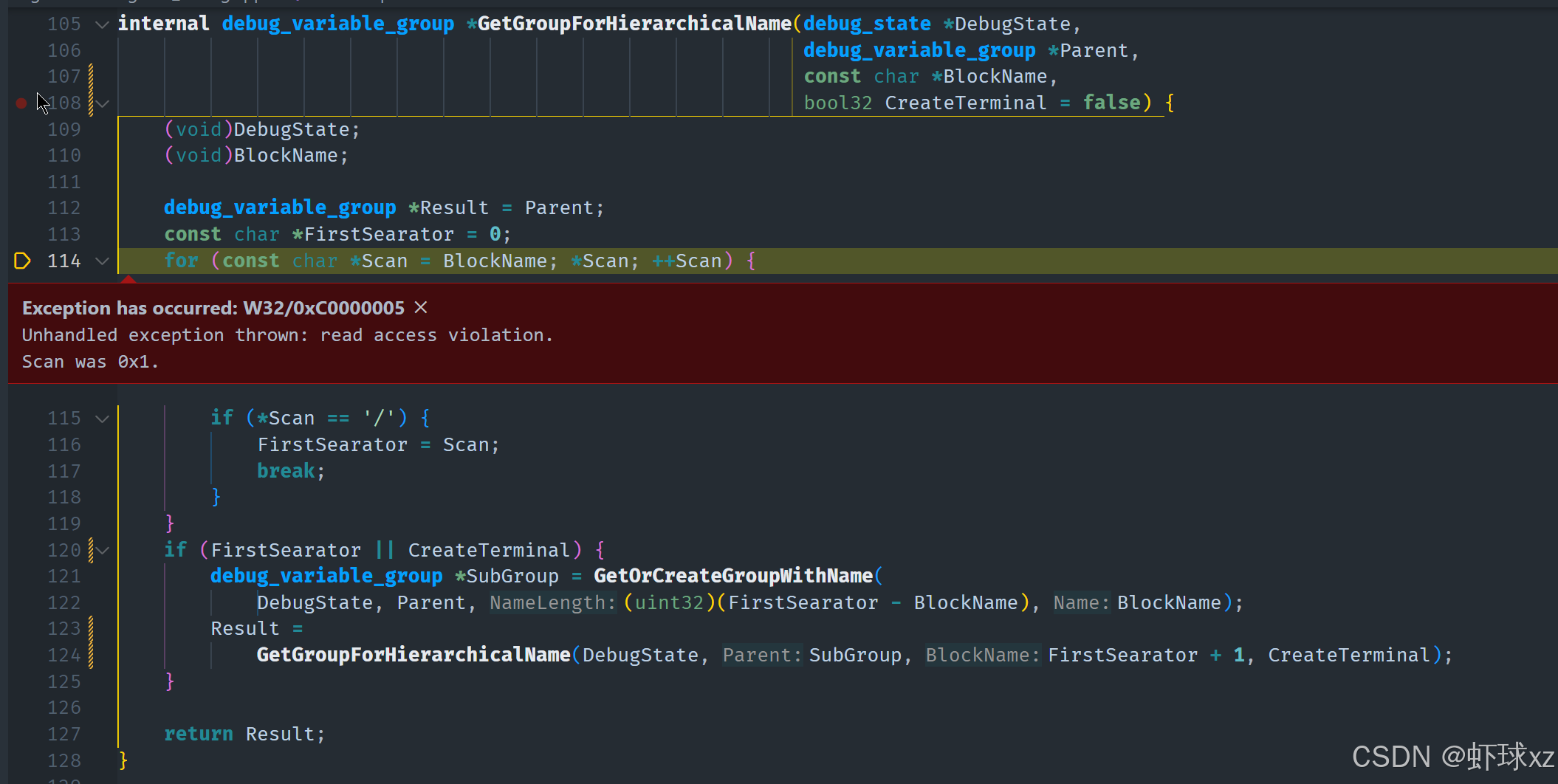
当前的判断依据:
- 当前数据中本应显示的是完整的调试路径名,例如
global/renderer/camera/use_debug,但实际显示的是不完整的中间路径,说明从一开始记录数据时就有问题。 - 所以现在重点要排查的是调试事件被"存储"时到底发生了什么。
- 必须确认是谁在处理这些事件时引入了错误 ------ 某段逻辑在记录事件名时搞错了。
后续检查计划:
- 回到调试事件的存储函数,查看事件在被创建、命名并传入系统时,使用的名称是否正确。
- 检查字符串传递和拼接的逻辑,是否在某个阶段只传递了路径的一部分(例如只传了
"renderer/camera"而不是整个调试路径)。 - 确认事件结构体中的
Name字段是否在初始化后被错误地替换或覆盖。
初步结论:
问题已经不是显示层的问题,而是在调试事件写入系统的过程中,名称被错误地设置成了路径中间某一层,而非目标数据项的完整路径。这种问题会导致最终呈现完全错误的调试层级,进而影响调试效率和正确性。
下一步:
深入调试事件写入逻辑,追踪调试值(debug value)被创建和命名的全过程,从根源修正路径名设置错误的问题,以确保后续处理逻辑使用的是正确、完整的调试名称。
使用调试器:尝试进入 StoreEvent,意识到事件早已被解析过。
我们首先挑选了一个合理的事件进行观察,比如 global/render/test/RearBufferSize,这类名称是完全符合预期的。它来自于 game.cpp 中的调试记录,因此我们希望它在调试系统中也能正确地显示出完整路径的名称。
接着追踪了该调试事件的处理流程,发现其并没有在 store_event 里被直接查看,因为事件在之前就已经被解析过了。事件是通过 get_element_from_event 函数处理的,这可能就是问题的根源。
当前逻辑分析:
-
事件解析阶段
- 调试事件通过
get_element_from_event被处理。 - 在这一步中,事件会被赋予一个当前的
GUID名称,这个GUID是通过一套路径解析逻辑得到的。
- 调试事件通过
-
名称解析的漏洞
- 由于这些事件不是"实际"存储在层级结构中,它们却仍然走了统一的处理路径。
- 这导致了事件名称不是通过事件自身提供的完整路径名称来确定的,而是通过当前活动的
data block结构中的路径解析得出。 - 这就出现了错误的路径继承,事件最终只继承到了某个上层路径,而不是自己的完整路径。
-
结构混乱的根本原因
- 当前的调试事件处理逻辑并未对 "不应该参与分层解析的事件" 进行特殊处理。
- 所有事件都被统一地通过
add_element_to_group加入分层系统,即使它们本不应该被那样处理。
初步结论:
当前调试事件层级系统的处理逻辑混杂,导致所有事件都被当作结构性层级节点对待,哪怕它们只是单个值。这种错误的统一处理方式,破坏了路径的准确性。我们原本希望事件名称基于其原始定义,而不是从所属块继承来的路径。
后续计划:
-
分离解析逻辑
- 将真正属于分层结构的调试块(如
BeginDataBlock/EndDataBlock)与单纯的调试值事件区分开。 - 不应让所有事件都通过
get_element_from_event和add_element_to_group的路径走一遍。
- 将真正属于分层结构的调试块(如
-
更好调试入口
- 把相关处理逻辑抽出来,便于独立调试和查看事件被赋予的路径来源。
- 提前对这些事件进行路径完整性验证,避免名称丢失或继承错误。
-
系统结构优化
- 重新考虑事件在进入层级系统前的分类逻辑:哪些是结构性信息,哪些是纯粹数据值。
- 合理设计调试事件的命名来源,优先使用事件自身携带的名称数据。
通过这些修正,调试系统才能准确还原事件原始定义中的路径结构,防止出现层级错误和名称丢失问题。
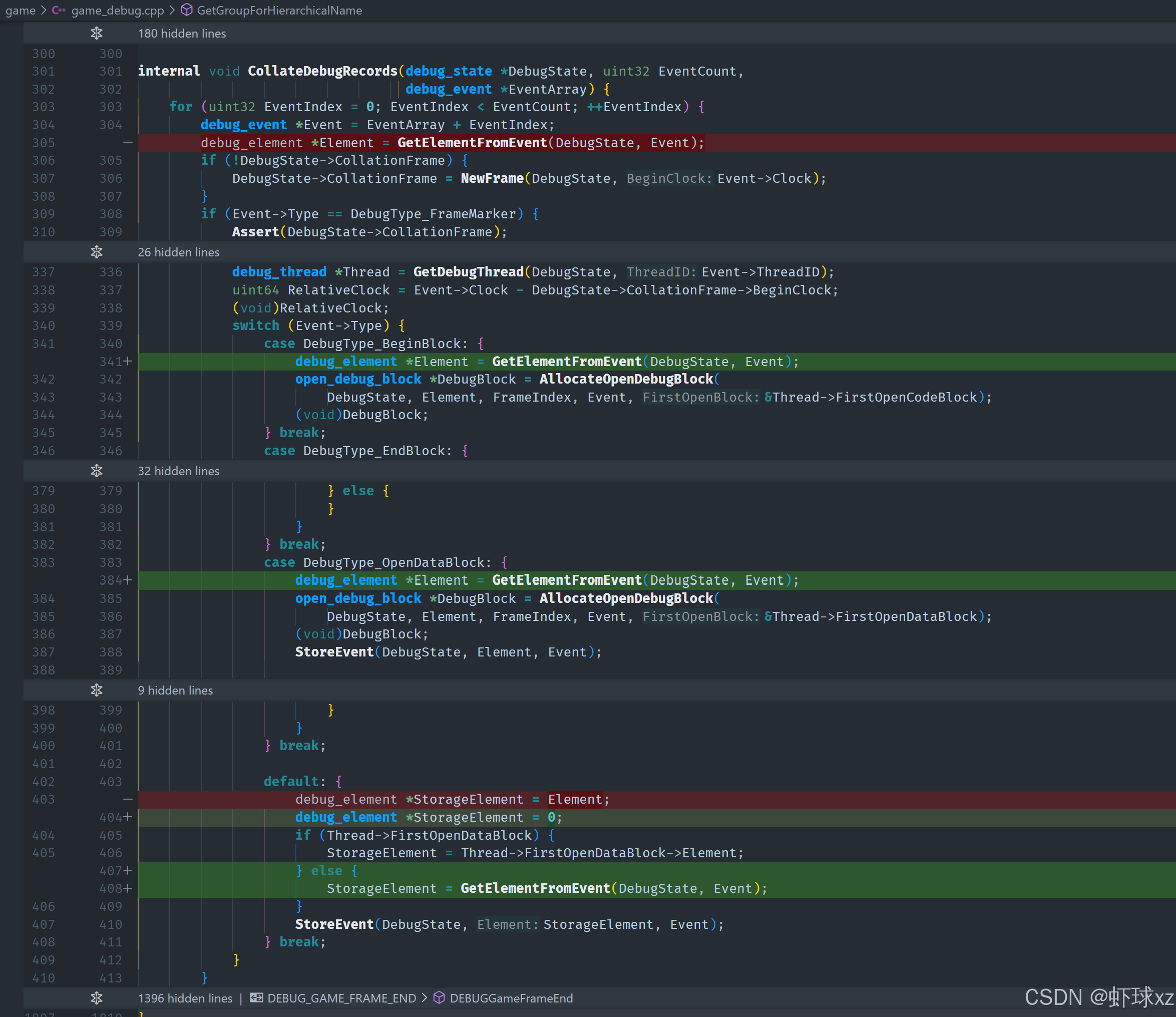
在 game_debug.cpp 中,将 GetElementFromEvent 从 CollateDebugRecords 中删除,并按需调用。
首先决定从事件处理中移除 get_element_from_event,然后重新编译代码。接下来会查看这个功能在其他地方的使用情况,并根据实际需求重新调整它的触发方式。
在修改过程中,决定将事件的存储过程改为按需触发,而不是在原本的位置一次性处理。这样,在存储一个事件时,可以动态地解析它,而不需要一开始就对它进行完整的解析。
这种方法可以更灵活地处理事件,并且通过这种方式修改后,代码的行为应该更加合理。当事件存储时,我们会直接使用存储的元素,而不会提前对它的名称进行解析。因此,问题的根本原因也就显现出来了:由于事件在存储时没有进行适当的名称解析,它最终并未按预期显示正确的名称。
接下来,依然需要通过一定的操作来对事件名称进行处理。尤其是需要处理名称中的部分内容,比如在名称中找到最后一个斜杠的位置,然后从该位置开始解析名称,剥离不必要的部分。
最终目标是能够让事件在存储和解析过程中更加灵活地处理名称,确保名称的解析能够准确地显示正确的调试信息。
为了验证这一思路,计划先进行一个简单的修改,并暂时进行手动的调试,后续会对这一部分代码进行进一步优化。
提议将所有元素都放入层级结构中,避免总是要判断是否该放进 DataBlock 的麻烦。
我觉得接下来要做的事情是简化现有的代码结构。我倾向于把所有内容都放进统一的层级结构中,这样就不会再有数据块和其他内容分开的问题。现在的做法是把某些内容放进数据块,而另一些则不放,这种方式让我觉得很复杂。
如果不需要某种特定的功能,那么为什么要继续为它留出空间呢?如果最终我们根本不使用这种功能,那么每次调试时,它就成了我们自己给自己制造麻烦的源头。我们希望简化调试过程,避免每次调试时都遇到这种繁琐的情况。
虽然这只是调试代码,并且我们不需要担心它影响最终用户,但还是不想给自己留下过多的负担,特别是未来如果我们需要调整或扩展调试功能时,不希望它变成一个不可管理的混乱。所以,这是我为什么想要简化这个过程的原因。
在 game_debug.cpp 中,修正 GUID 的设置逻辑。
如果我们要进行这个修改,首先需要确保事件在存储时能够跳过管道部分。具体来说,可以通过检查事件中的"管道"符号并将其移除,从而确保事件的名字可以正确地存储。为了实现这一点,可以编写一段逻辑,检查事件的GUID内容,并根据需要处理事件名称。这样,我们就能确保事件在存储时只包含正确的名称,而不会包含不必要的部分。
当我们在存储事件时,事件的名字应该已经正确提取出来,这样可以避免之前出现的名称错误问题。这是第一步,通过这种方式可以保证事件被正确存储并且符合预期。这是解决当前问题的一个好的起点。
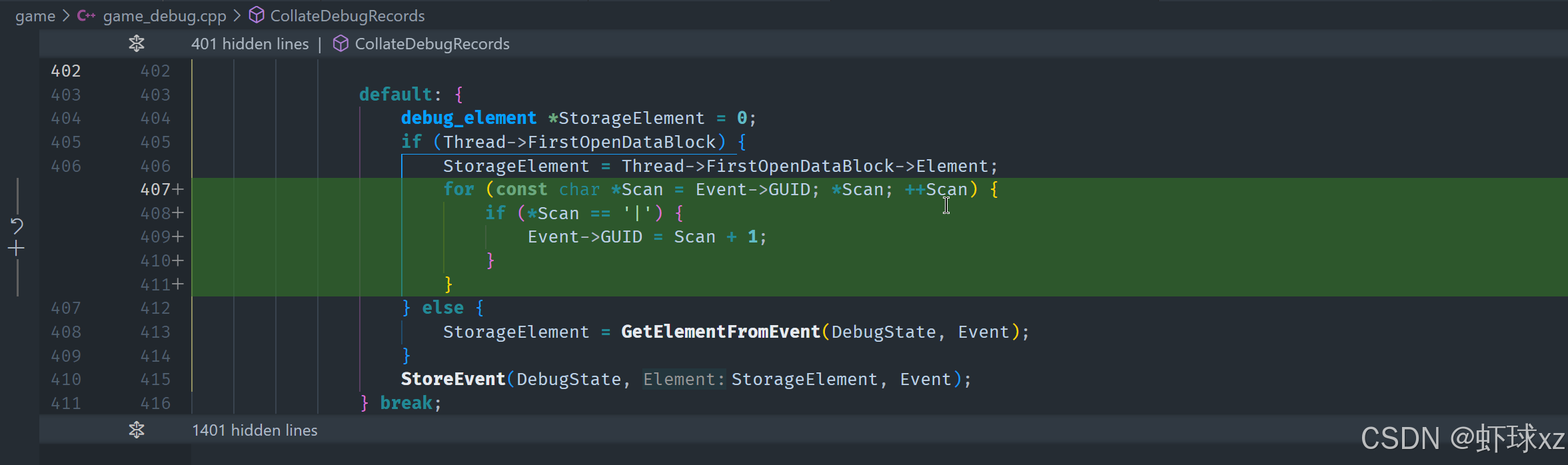
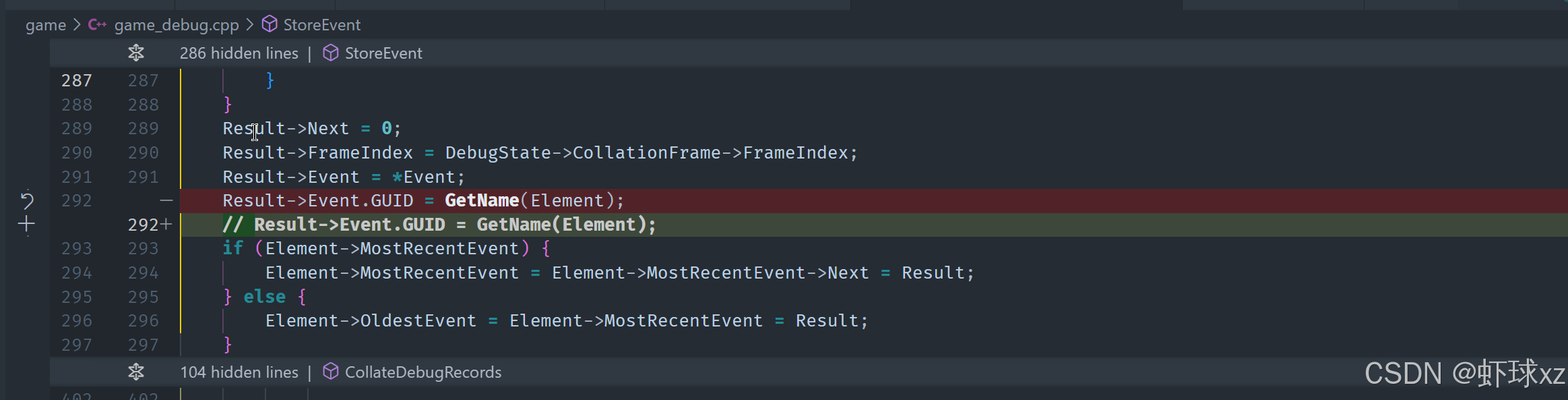
在 game_debug.cpp 中,注释掉 StoreEvent 中设置 GUID 的部分。
现在的问题是在提取事件时,似乎并没有从正确的位置获取数据。问题出在我们循环遍历开放的数据块时,无法正确提取事件。具体来说,store event是导致问题的根本原因。通过查看事件数据,可以发现它正在覆盖正确的元素名称,实际上是将错误的名称存储在了错误的位置。这种覆盖是我们不希望发生的。
尽管这样解决了部分问题,但仍然存在另一个问题,那就是树形结构中的其他元素依然不正确。因此,解决了部分问题,但整体结构依然不完美。
考虑到这一点,可能需要进一步简化和优化代码。我认为不应该继续使用"开放数据块"这种方式,而应该直接通过"开放数据块"的流来处理,不再需要存储它们。这样做能够让代码更加简洁和清晰,同时避免重复和错误的存储操作。
在 game_debug.cpp 中,重构调试组的设置逻辑。
为了简化代码并解决当前的问题,计划采取以下步骤:
-
存储事件方式不变:继续按照当前方式存储事件,但确保每个事件都有一个关联的元素,并确保元素被正确地存储在合适的层级结构中,避免之前的错误。
-
每个事件都需要一个元素:每个事件将被分配到一个元素,并确保这个元素可以正确地进入其在层级中的位置。这样,避免了原来由于没有正确层级结构而导致的问题。
-
使用初始父元素:在处理事件时,需要保留对父元素的引用,确保事件在正确的层级中。具体来说,当进入开放数据块时,事件的父元素应该是当前数据块的元素,但如果不是第一个开放数据块,父元素应为零。
-
修改事件存储逻辑 :在存储事件时,我们要调用
get element from event,并将父元素作为参数传递下去。通过这种方式,能够确保每个事件都按照其层级结构正确存储,并且不会错误地将事件插入到不该插入的位置。 -
使用父元素的组 :当插入事件时,应该使用之前父元素的组,而不是直接依赖于某个默认值。为了实现这一点,需要从
get element from event中提取相关信息,确保事件按层级关系存储到正确的组中。 -
获取正确的组信息:需要在处理数据块时,获取和使用正确的组信息,而不仅仅是存储元素本身。这可以通过从每个开放数据块中提取出它的组信息来实现。这样,事件存储的过程就能更加精确,避免之前的存储错误。
通过这些步骤,可以确保事件存储的过程更加简洁和清晰,同时避免了原来的混乱和错误。
运行游戏,发现调试系统完全不起作用。
看起来目前的逻辑仍然存在问题。虽然代码结构似乎已经调整得更合理,但当前的实现依旧没有按预期工作。分析后发现,根本原因可能是我们在某处并没有对相关变量进行更新。
我们判断最可能出问题的地方,是在处理某个状态或数据结构时,少了一步更新操作。也就是说,在逻辑上虽然已经设置好了层级结构、传入了正确的父元素或组信息,但是程序并没有在正确的时间点将这些信息同步或写回到对应的数据结构中。
因此,我们需要在事件处理或调试元素创建的关键位置,把相关状态显式地更新进去。这应该就可以修复当前逻辑不生效的问题。
结论如下:
- 当前功能未按预期执行。
- 初步判断是某个值或状态未被更新。
- 应该在特定逻辑点增加一次更新动作。
- 修改后再次测试,可以验证问题是否解决。
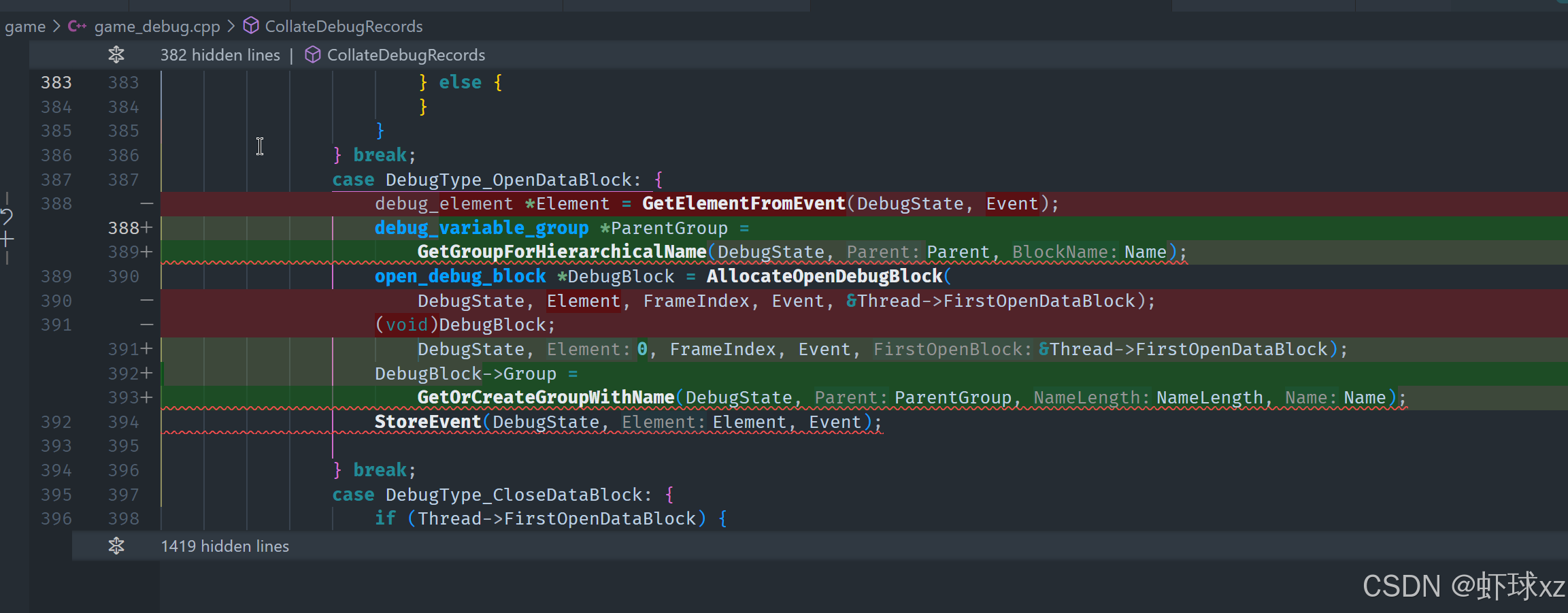
在 game_debug.cpp 中,为 OpenDebugBlock 创建时将 Element 初始化为 0。
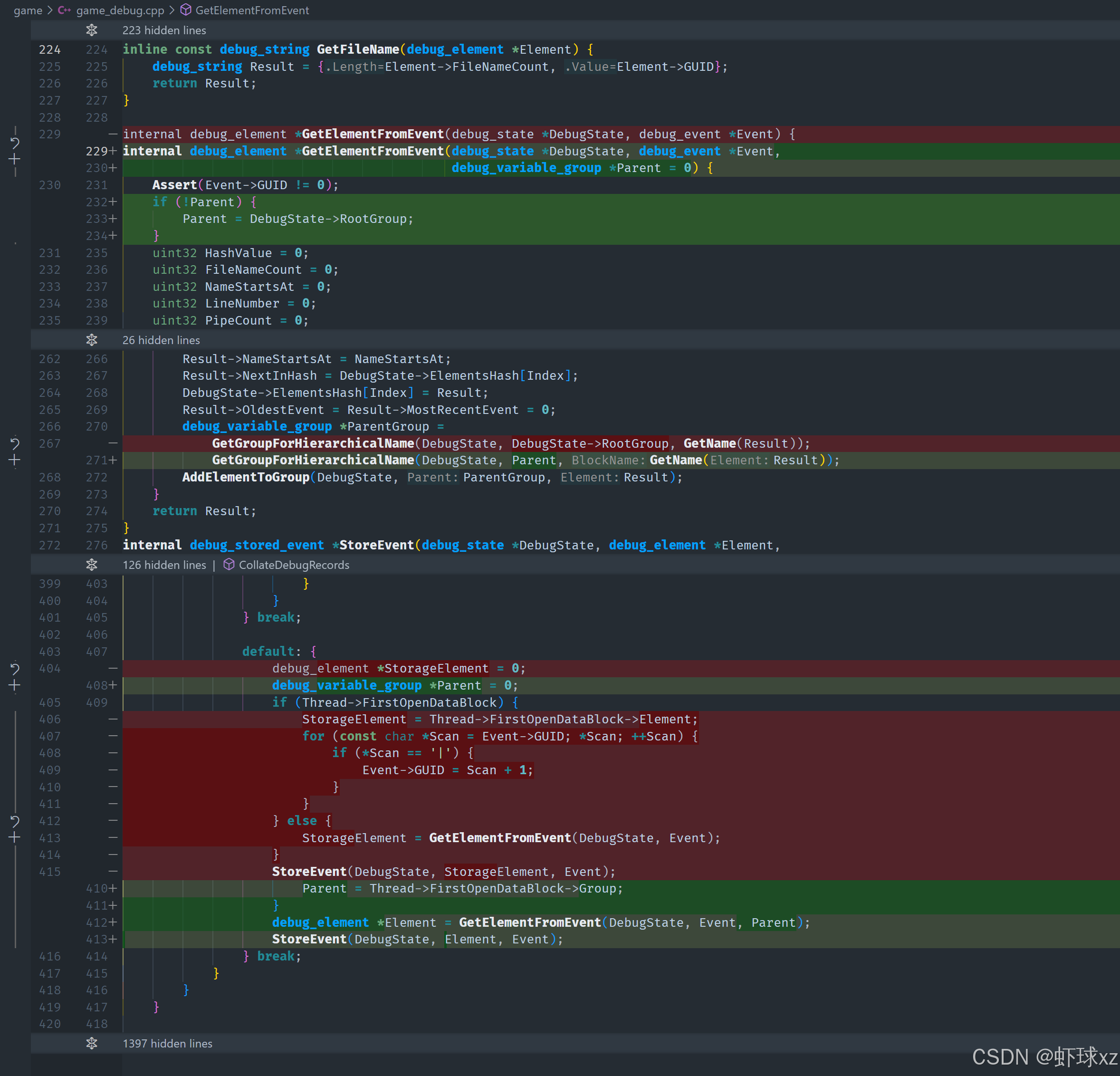
目前的调试逻辑中,发现存在一个关键问题:在处理调试块(debug block)分配时,没有正确记录和设置其所属的分组(group)。我们虽然通过 getElementFromEvent 函数获取到了对应的元素,但并没有保留该元素所属的分组信息,从而导致后续逻辑无法正确使用该分组。
具体分析如下:
- 在进行调试块分配时,
openDebugBlock没有设置所属的 group; - 实际上,在
getElementFromEvent中已经通过getHierarchicalGroupFromName获取到了对应的 group,但我们没有把这个 group 信息存下来; - 当前的问题是我们"丢失"了 group 这一关键状态;
- 另一方面,调试块本身并不需要作为一个元素添加到层级结构中,因此我们也不需要调用
addElementToGroup添加它,而应直接记录 group 的引用; - 也就是说,调试块只是一个逻辑容器,不应当作为"普通元素"存在于结构树中;
- 因此,处理逻辑应当调整为:在
openDebugBlock时仅提取和记录 group,不添加任何元素; - 为了实现这一点,需要将原本嵌套在
getElementFromEvent中的名称解析逻辑(即提取 group 名称与 element 名称)抽取成一个独立函数,供openDebugBlock调用; - 调用流程为:解析名称 → 取 group → 存储该 group 作为当前调试块的父 group;
- 此外,为确保一致性,应使用
getOrCreateGroupWithName函数来获取对应的 group; - 最终,调试块中需要插入的其他元素也将自动归入该 group 下,达到了结构逻辑清晰统一的目的。
总结重点:
- 问题出在调试块没有正确设置所属 group;
- 需要抽取并复用名称解析逻辑;
- 调试块不应作为元素插入,仅需记录 group;
- 通过
getOrCreateGroupWithName获取 group; - 修改后可以保证元素都按照正确的结构归类,并避免后续结构混乱。
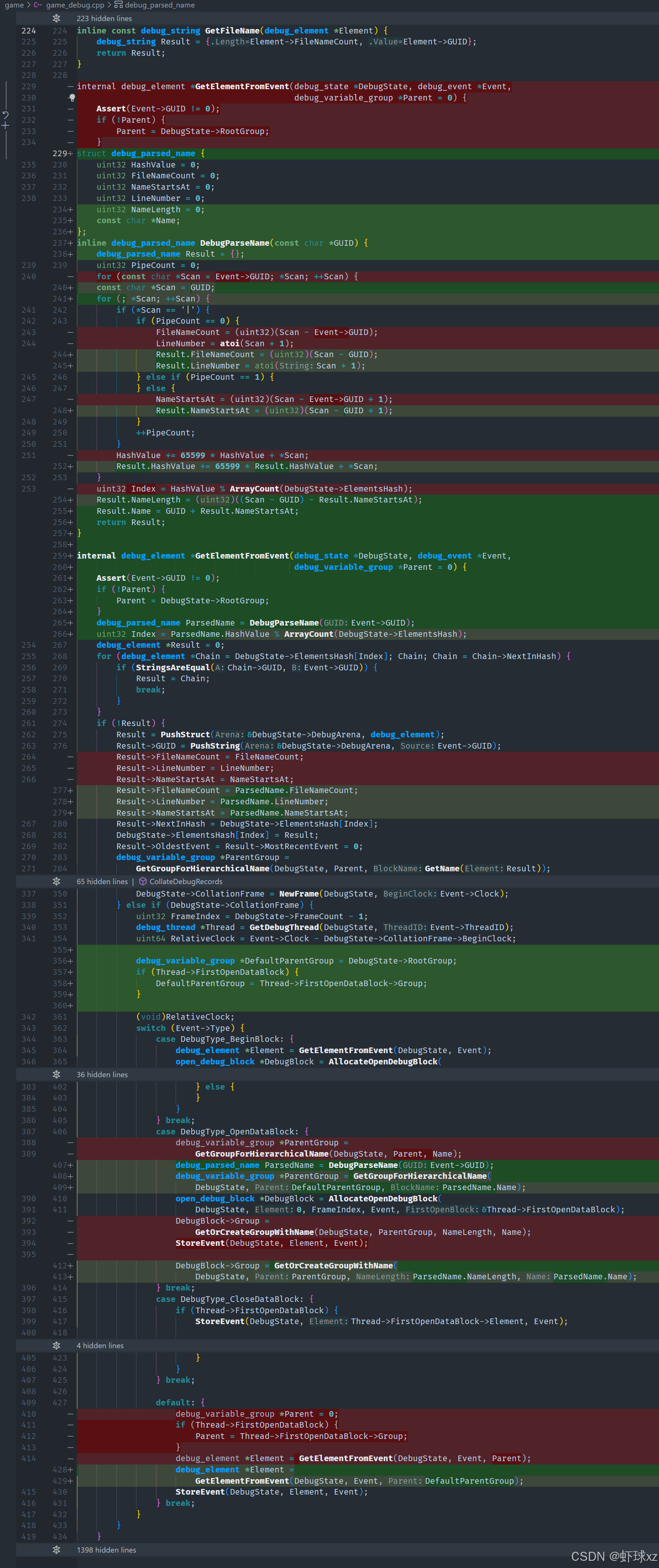
在 game_debug.cpp 中,引入 debug_parsed_name 和 DebugParseName。
当前的优化目标是进一步完善事件名称解析的流程,使调试逻辑更加清晰、统一并具备可扩展性。核心思想是将事件名称的解析过程提取成一个独立的函数模块,这样可以在多个场景中复用,并将结构信息(如 group 和 hash 值)完整保留下来。
具体操作与思路如下:
- 将原本用于从事件名中提取分组信息、名称主体等的解析代码提取为一个新的函数,比如叫
parseEventName; - 这个函数接受一个事件名称作为参数,返回一个结构体或结果对象,包含以下信息:
- 完整名称
- 提取后的 group 名称
- 解析后的元素名称
- 可选的 hash 值(既然已经计算,不妨一并保存,未来或许可用于加速索引);
- 接着,在主流程中对事件名进行解析时,不再手动逐项提取信息,而是统一调用
parseEventName并直接使用其返回结果; - 例如,在遍历事件进行处理(scan)的时候,调用
parseEventName获取解析结果,然后将其写入结果结构体中; - 由于 store 变量仅在这个解析环节中临时使用,因此可以删除不再需要的中间变量,减少冗余;
- 最终,这样的结构使得事件名称相关的逻辑清晰集中,后续维护或扩展(比如新增格式、支持多级结构)都会变得更简单。
总结优化重点如下:
- 把事件名称解析逻辑单独封装成函数
parseEventName; - 返回结构包括 group 名、元素名、hash 等有用信息;
- 主逻辑调用时只需传入事件名,接收解析结果即可;
- 删除多余变量,使流程更简洁;
- 提升复用性和可维护性,为后续功能拓展打下基础。
在 game_debug.cpp 中调用 DebugParseName 并继续重构。
当前的工作主要集中在事件名称解析与调试信息结构化方面,通过一系列优化与封装,使得整体数据处理逻辑更清晰、代码更易维护,具体包括以下几个核心思路与操作步骤:
事件名称解析统一封装
将原本分散在代码各处的事件名称解析逻辑封装为统一的解析器函数(如 parseFirstName):
- 该函数接收事件的类名或完整名称字符串;
- 返回的结构体中包含:
- 解析后的名称指针;
- 名称长度;
- 哈希值;
- 可能还包括名称起始位置等中间信息;
- 所有需要处理事件名称的地方都改为调用此函数,从结构中提取信息,避免重复解析逻辑。
哈希值和名称信息集中管理
通过结构体封装后的名称解析结果:
- 可以直接在所有需要的位置调用,比如事件调试系统、分组系统等;
- 所需的信息统一保存在结构中,调用者不再需要重复计算或重新扫描;
- 哈希值的计算一次完成,复用性能更优。
调试事件默认分组逻辑修复与调整
重新审视了调试事件的分组插入方式,发现以下问题并进行了修复:
- 原问题:未正确记录调试块所属于的 group,导致后续结构混乱;
- 修复方法:明确将调试事件插入到一个默认的父分组中;
- 引入变量
defaultParentGroup,将所有无显式父组的元素归于该组下; - 同时确保调试事件之间可以嵌套,因此不能始终插入到 root group,而是根据前一个调试块确定父分组。
禁止错误存储逻辑
强调部分元素 不应作为真正的结构元素被存储:
- 比如调试用的 "Open Debug Block" 元素,仅作为逻辑指针存在,不应被加入正式元素树中;
- 明确指令:不要存储,通过代码注释和逻辑控制加以保证;
- 从而防止污染元素层次结构,保证调试信息的独立性和可控性。
结构设计的逻辑完整性与可扩展性
最终的优化不仅完成了解析和组织流程的正确性,还具有良好的扩展能力:
- 新的结构只需修改
parseFirstName即可适配; - 调试块、事件块、普通数据块等可以统一处理逻辑;
- 所有名称信息解析后都封装在统一结构中,调用方式一致,接口清晰。
小结
此次调整围绕事件处理流程中的"名称解析、分组归属、存储行为"三大关键点展开,通过封装、默认逻辑与明确限制,有效提升了调试系统的健壮性与可维护性。整套逻辑现在更加统一、清晰,并为后续进一步增强打下基础。
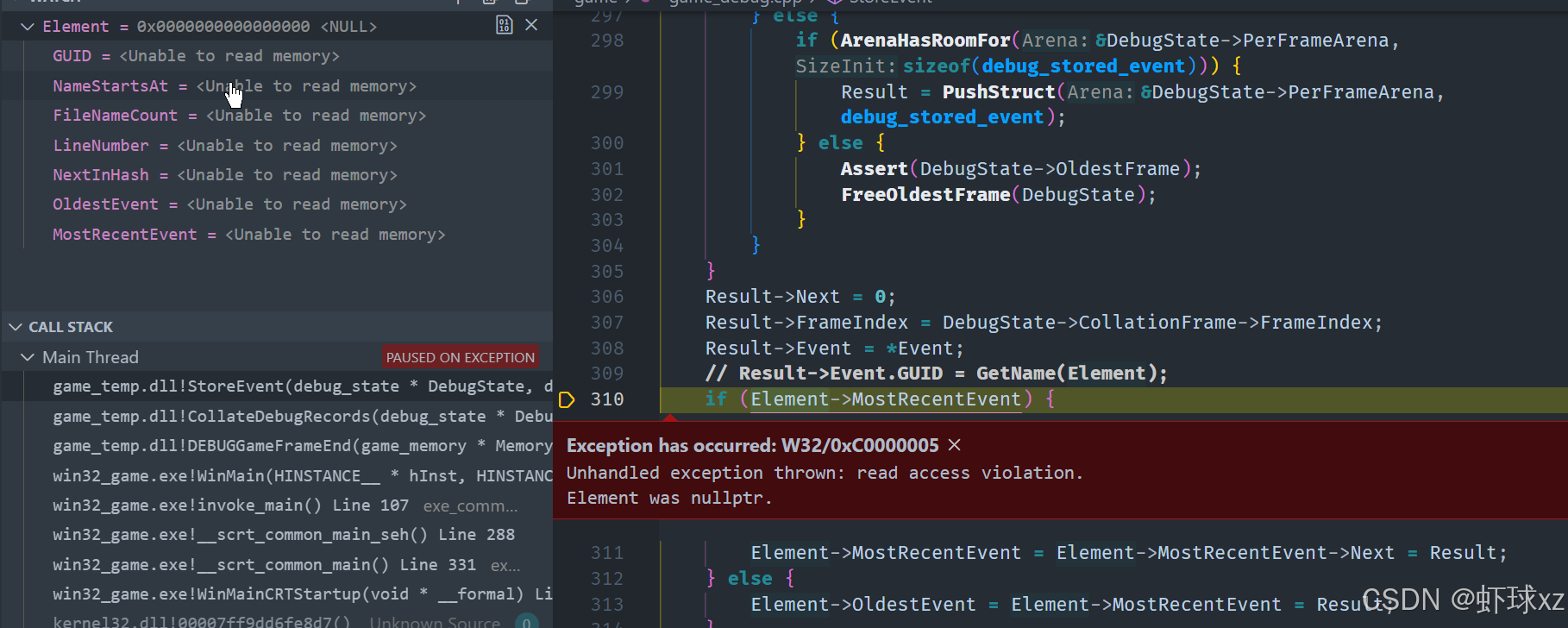
使用调试器:编译并遇到异常。
当前的重点在于调试数据块在关闭时结构层级未正确建立,进而导致调试结构异常或程序行为异常。我们逐步发现问题、定位根因并提出修正方向,整个过程如下:
现象:调试数据块结构错误
目前虽然理论上所有数据已经正确被嵌套在层级结构中,但实际运行中仍存在异常行为,例如:
- 在**关闭调试数据块(close data block)**时程序出现了问题;
- 系统试图"存储"一个关闭的数据块,而这种行为是不应该发生的;
- 这意味着:在某些流程中调用了不应调用的逻辑,特别是在关闭调试块时,不应该再执行类似元素存储的动作。
初步排查:错误调用路径
我们检查了调用堆栈,发现系统在处理"关闭数据块"时,不小心执行了本不该调用的逻辑:
store逻辑被调用,而关闭调试块时本不应再有任何新结构或子元素插入;- 该行为引发后续
elements为null的错误,说明试图访问未初始化或未构建的结构; - 问题源头在于关闭数据块时对"调试块"的状态理解有误。
深层根因:未保存首个调试块引用
通过调试继续深入:
firstOpenDataBlock是调试结构构建过程中非常关键的引用,它用于确定当前结构的嵌套父级;- 但程序在打开调试块时并未将该引用保存下来,导致关闭时无法从原始结构回溯;
- 关闭逻辑依赖
firstOpenDataBlock,但它是null,因此流程错误、结构断裂。
解决思路:显式记录首个调试块
明确以下修复操作:
- 在打开调试块的过程中,必须显式保存
firstOpenDataBlock的引用; - 在后续处理关闭调试块等逻辑时,依据这个引用恢复结构上下文;
- 禁止在关闭数据块过程中再次触发结构插入逻辑,如
store,以避免异常操作。
状态控制建议
为了防止类似误操作重复发生:
- 应增加状态控制标记,明确当前是否处于"调试结构构建"阶段;
- 在处理关闭时对非法行为主动报错或屏蔽处理;
- 所有层级结构应来源于明确解析,而非由模糊触发流程自动生成。
小结
当前问题根源是调试块在关闭时结构状态不一致,具体是未存储必要的 firstOpenDataBlock 引用,导致后续流程操作失效或错误调用。修复的关键是:
- 明确结构入口与状态;
- 禁止非法操作;
- 补充引用保存逻辑。
修复这些后,调试层级系统会更健壮,关闭流程也将如预期正确运行。
在 game_debug.cpp 中,移除 CloseDataBlock 的 StoreEvent 调用。
我们已经将那部分内容移除掉了,彻底删除,没有保留。
当前处理结果:
- 某段与当前功能或逻辑无关的代码,已经被移除;
- 这段代码在之前可能有一定作用,但在当前结构或新逻辑下已经不再需要;
- 删除后不再担心其可能带来的副作用或干扰;
- 清理后的逻辑更加简洁明确,也更容易维护。
删除的影响与态度:
- 删除是明确、彻底的,不再考虑保留或兼容旧路径;
- 未来的流程完全不会依赖于这段旧逻辑;
- 即使这段逻辑再次被触发,也不会产生任何作用;
- 明确表示"这部分不重要,不再关心",可以放心忽略。
总结:
通过移除这段冗余逻辑,流程更加清晰简洁,避免了无用的复杂性,也减少了潜在的错误触发点。当前结构更加聚焦于实际需要处理的内容,后续工作也将更为稳定高效。
使用调试器:重新编译并运行,发现几乎可以工作,可能仅剩一个数据问题。
我们已经逐步推进到了比较接近完成的阶段,整体流程基本跑通。但现在注意到有一个奇怪的现象,表现不太正常,看起来像是哪里出错了。进一步分析后,我们怀疑这个问题并不是逻辑或渲染流程中的错误,而是源自数据本身的问题。
当前发现的异常情况:
- 整个系统在某处状态表现异常;
- 不是直接来自渲染管线或逻辑处理部分;
- 现象有一定的不合理性,和预期行为不符;
- 通过排查其他部分,基本可以排除代码层面的致命错误。
初步判断:
- 可能是数据结构、输入数据或者某些初始化状态本身存在问题;
- 当前的逻辑对这些数据是"信任"的,默认它们是合法和规范的;
- 但实际运行时传入的数据可能就已经带有问题了,才导致现象异常;
- 看上去像是"bug",但很有可能根源是"输入问题"。
后续方向:
- 考虑引入数据验证流程,对数据源或关键字段增加合法性判断;
- 在数据进入渲染/处理逻辑前进行基础校验;
- 如有必要,可回溯数据来源或对数据产生方式进行进一步排查。
总结:
当前的问题极有可能不是处理逻辑的失误,而是数据本身存在潜在错误。后续重点应放在数据源的校验与修复上,避免错误数据干扰正常逻辑流程。这样可以从根本上解决这一"看似代码问题"的异常行为。
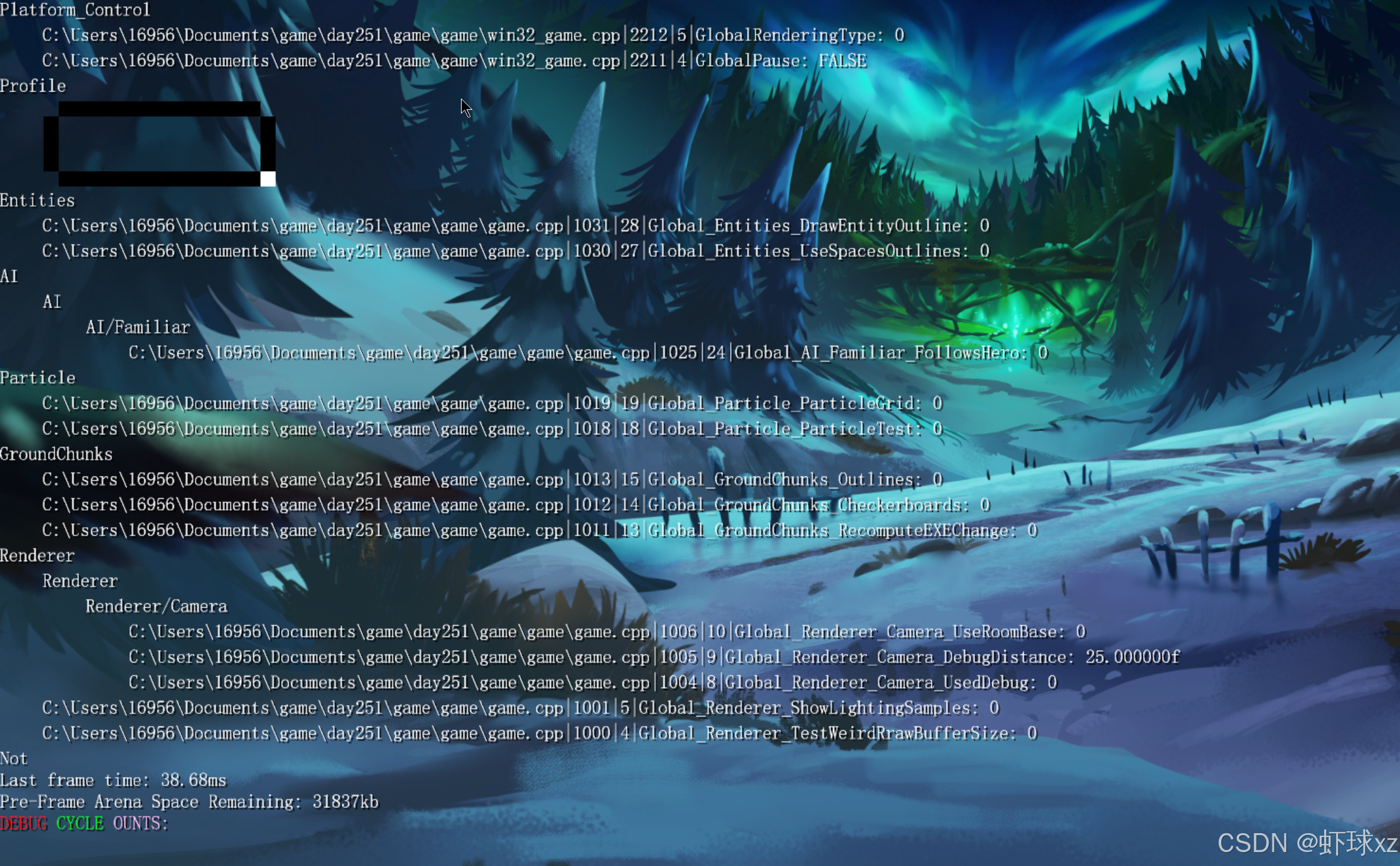
在 game.cpp 和 win32_game.cpp 中,修正 DEBUG_DATA_BLOCK 的名称。
现在的问题可能是我们自己在实现上犯了一个低级错误。某处逻辑在处理数据或判断状态时并不正确,这其实就是导致现象异常的根本原因。具体来说:
问题分析:
- 某个模块(如渲染相关)中存在错误处理或判断;
- 具体出错的地方是"社区"相关的逻辑,这一部分写得不对;
- 正是因为这个错误,才引发了之前观察到的不正常表现;
- 此外,还有其他部分也存在类似的问题,比如平台相关逻辑;
- 比如在
win_pretty_two中,平台处理存在问题; - 表单控件来自某些科学内容部分,但这部分逻辑应当是能正常工作的;
- 可以确认这是一个代码错误,不应继续保留,应尽快修复。
状态确认:
- 渲染摄像头部分目前是正确的;
- 问题并不出现在它身上,逻辑流程是符合预期的;
- 因此可以将注意力重新拉回到之前的问题点,集中修复。
后续处理:
- 需要定位并修复"社区"部分的错误逻辑;
- 同时排查平台适配和表单控件来源部分;
- 确保每个子模块都能正确响应调用和数据传入;
- 一旦修复,相关渲染或交互问题应当能够消除。
总结:
目前已经定位到是我们自身在某部分逻辑上写错了,尤其是在与"社区"和"平台"处理相关的地方,这些错误引发了之前所有的连锁反应。修复这些明确的问题后,系统将会重新恢复正常运行。接下来应将精力集中于这些具体代码点的修改和验证上。
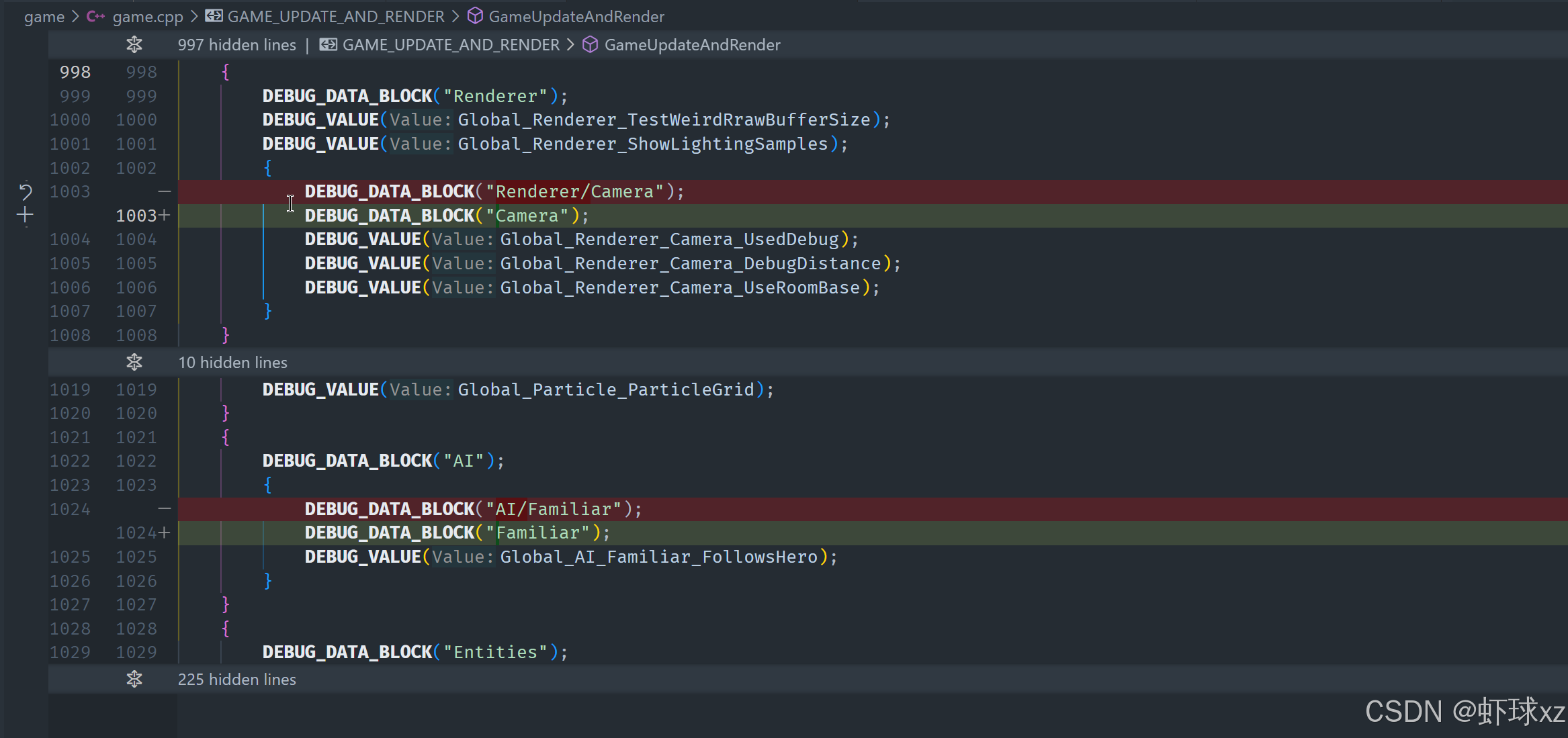
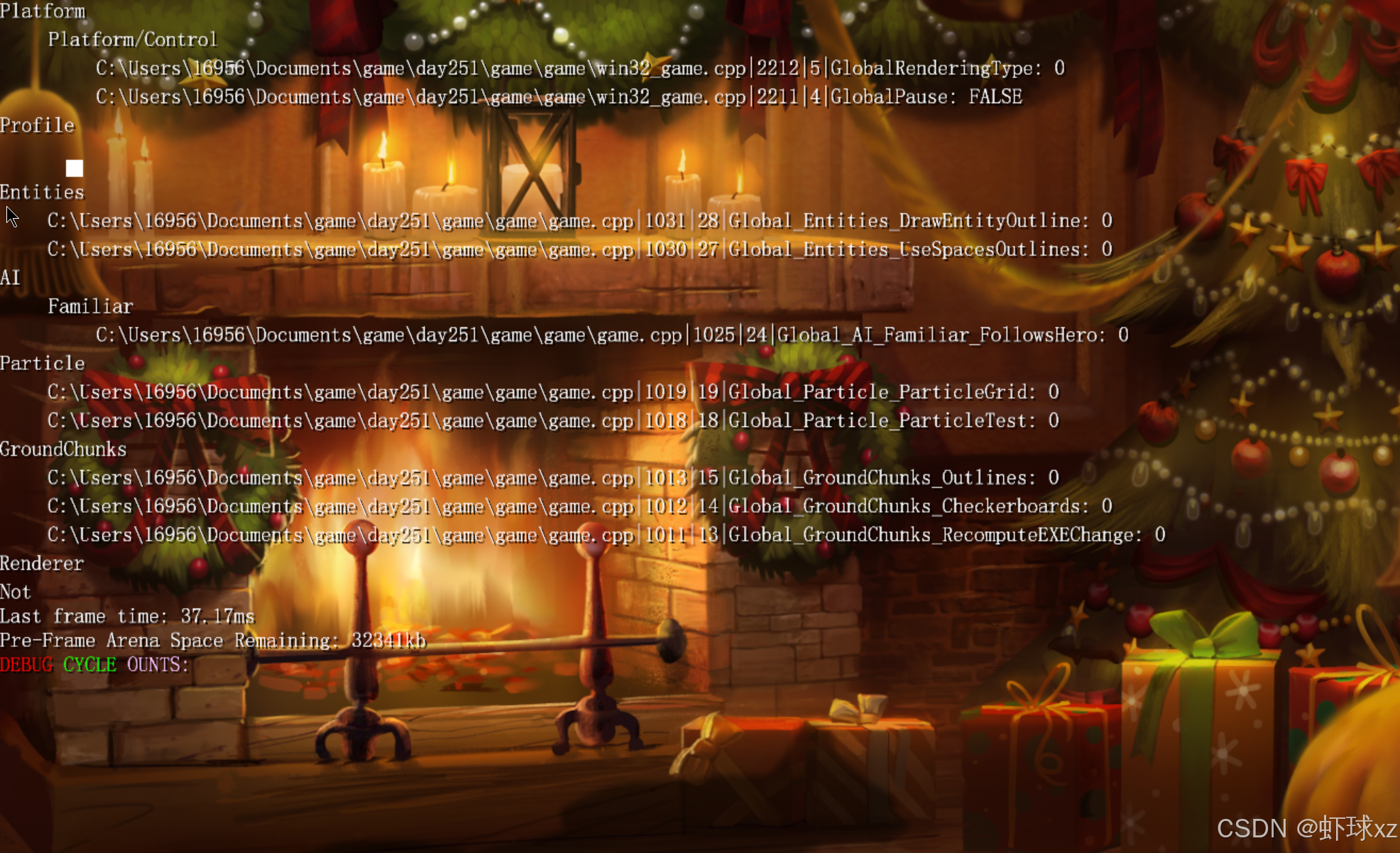
Platform/Control 有问题呢
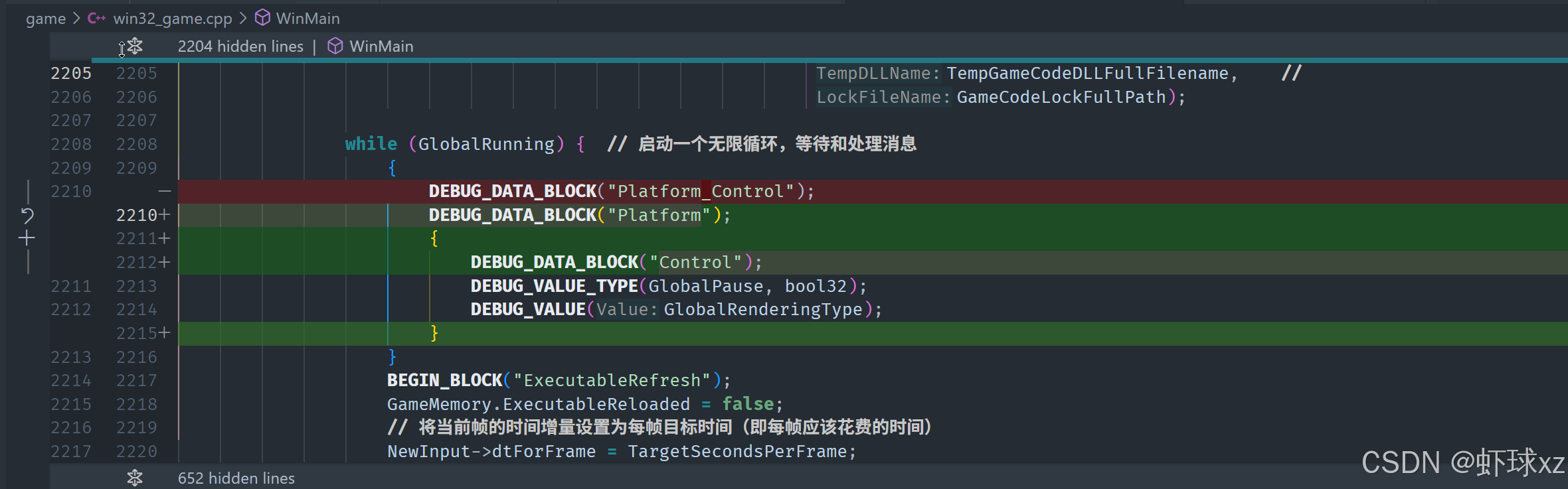

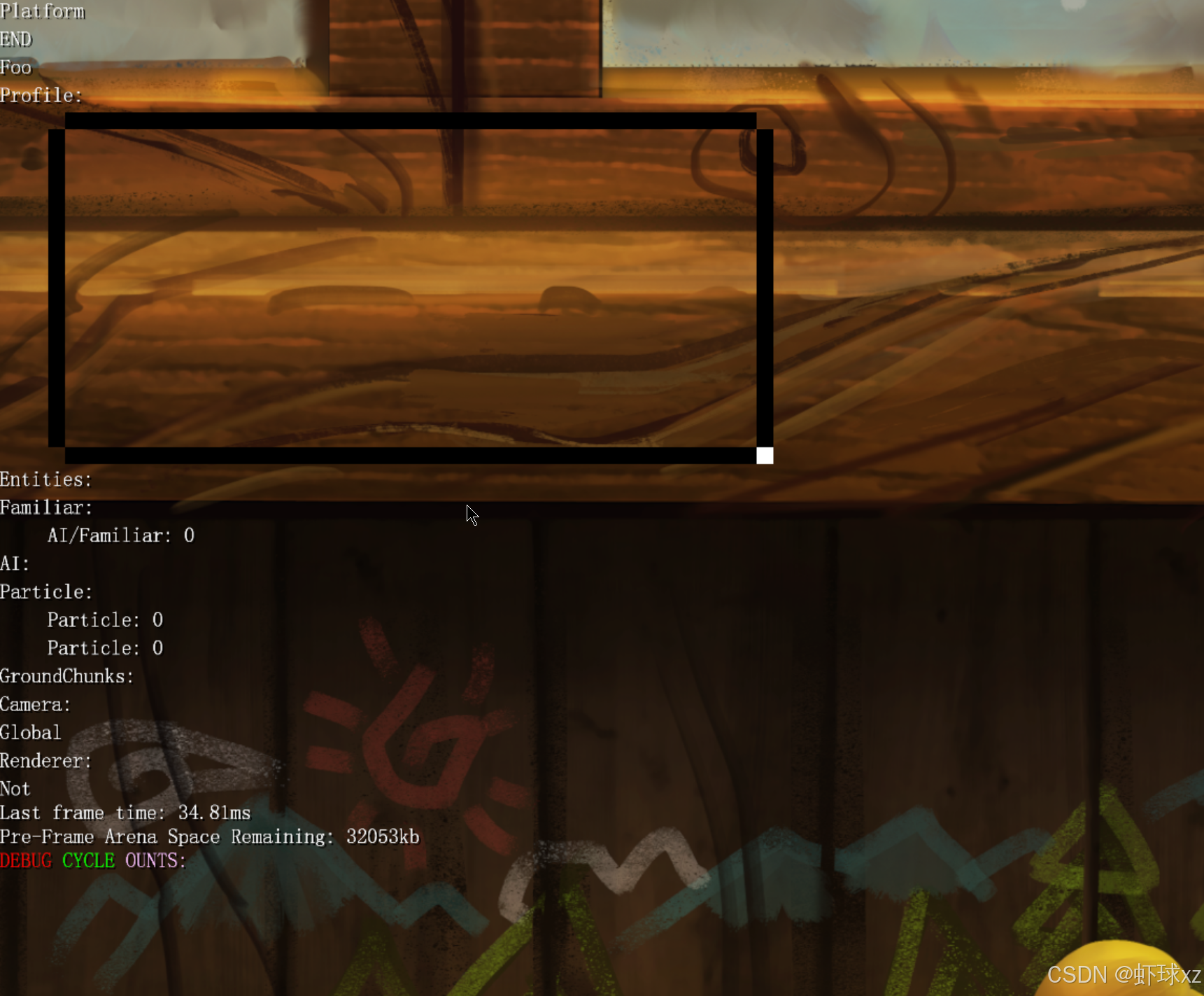
运行游戏,欣赏当前的调试信息。
目前已经进入调试阶段,重点集中在那些未能正确展开的数据或结构上。进行了一些交叉检查,确认当前系统中某些部分的功能是正常工作的,尤其是模拟实体的可视化部分。
当前系统状态:
- 正常显示了模拟实体信息;
- 例如实体的速度(velocity)、x轴值、y轴值、朝向(facing direction)等信息都可以被调试面板读取并查看;
- 也能看到跳跃状态,例如是否正在跳跃、总跳跃次数等;
- 注意到一个问题:虽然理论上游戏当前不应允许跳跃,但跳跃功能仍然开启了,这是一个不符合预期的行为;
- 后续需要将这一部分逻辑修复,使游戏状态符合设计规范。
工具可视化部分表现良好:
- 调试面板可以展示关键物理属性;
- 这些信息对后续调试非常有帮助;
- 虽然还有些问题尚未解决(例如为什么某些位图无法显示),但整体调试体验较为顺畅;
- 可视化反馈有助于观察模拟实体当前状态的变化,尤其是物理行为和控制输入反馈。
接下来要做的:
- 很快就要进入正式的游戏逻辑编码阶段;
- 在此之前,需要先清理和重构之前的部分代码;
- 特别是对跳跃逻辑、物理控制以及状态检测模块要进行重新整理;
- 同时也要修复仍未展开的数据节点问题,保证系统结构完整性;
- 在整理过程中,将持续清除临时调试代码,替换为更正式和高效的实现。
总结:
已经成功进入调试并观测实体状态,当前主要问题集中在数据结构未正确展开以及部分逻辑(如跳跃)未按预期限制。虽然还有部分功能未完善,但整体流程已接近转入正式编码阶段。当前重心是收尾调试、修复逻辑漏洞,并为即将到来的核心功能开发打下干净基础。

前面很长的一串
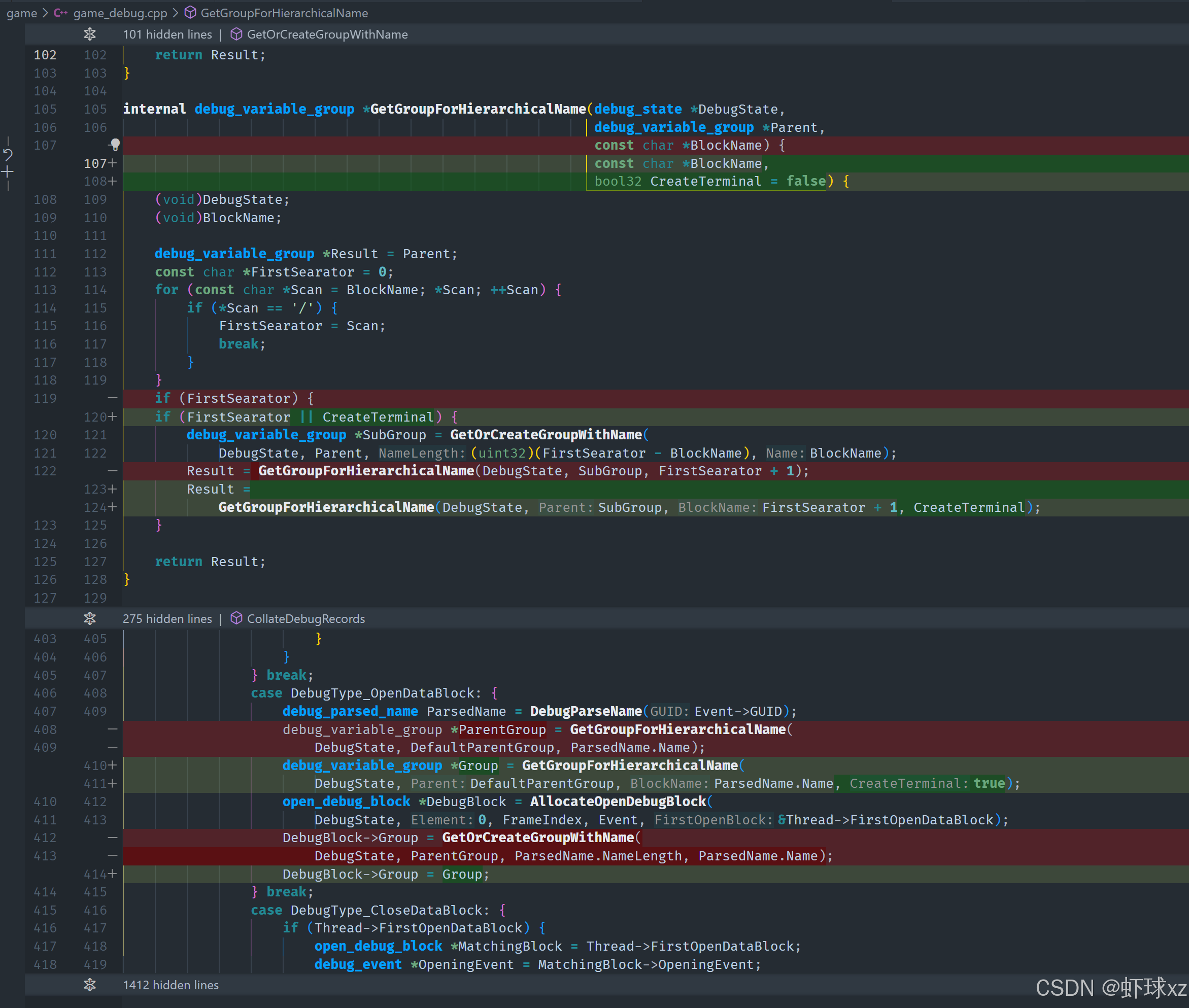
在 game_debug.cpp 中,修改 GetGroupForHierarchicalName 的逻辑,以支持层级正确展开。
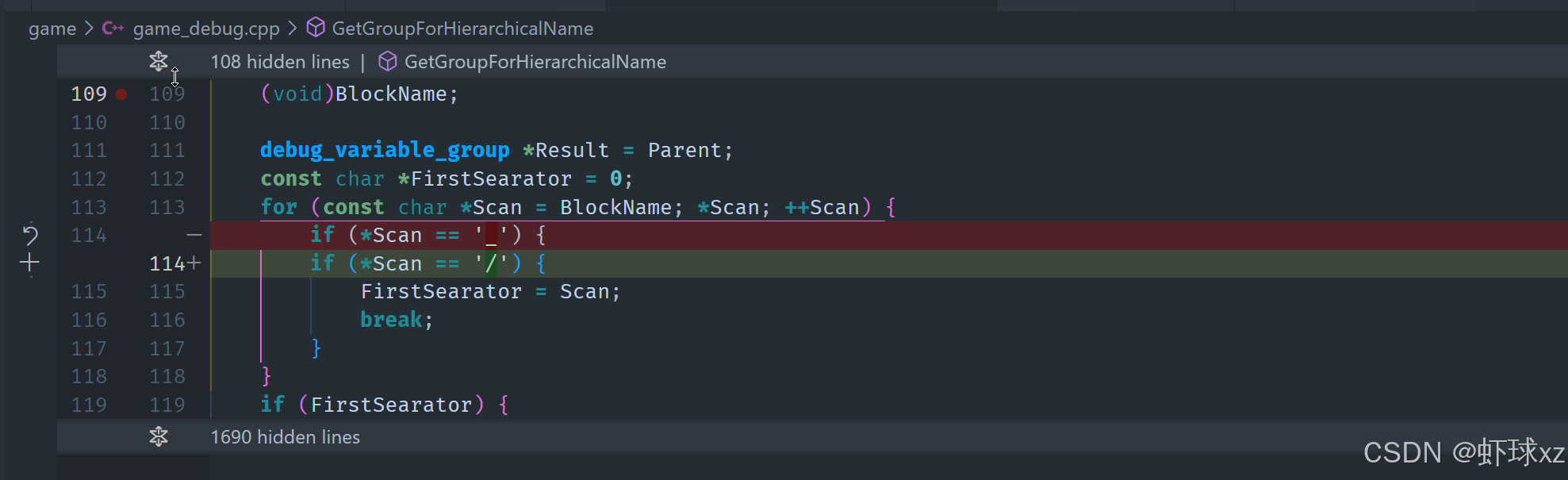
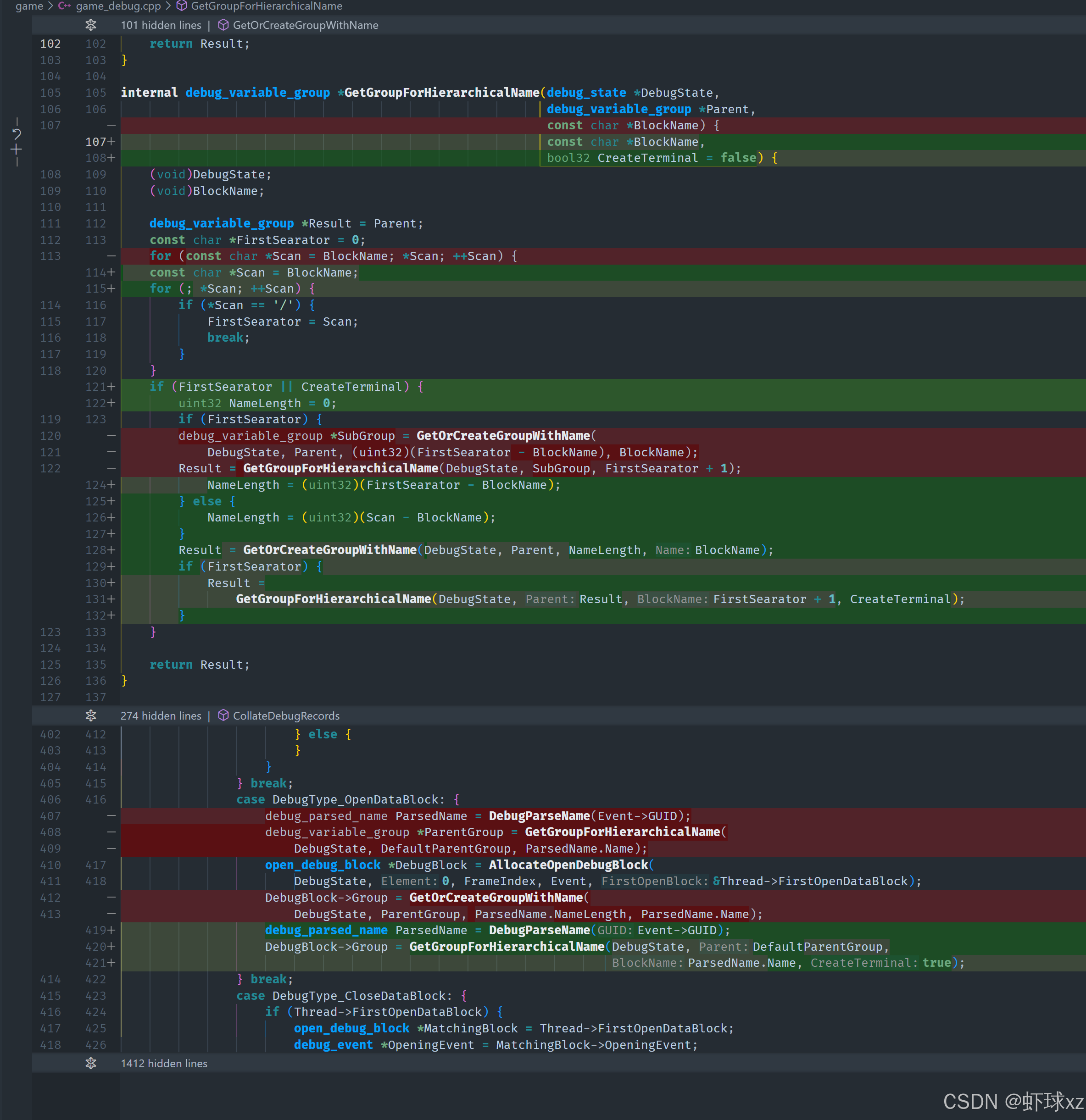
目前针对层级名称的解析逻辑继续进行了深入调整和修复,目标是确保名称路径中所有的层级都能正确创建,避免路径解析失败或错误归类的情况。
问题表现:
- 在解析层级结构名称时,没有按预期展开所有路径,导致只生成了部分节点或结构扁平;
- 使用
GetGroupForHierarchicalName函数时未能正确处理多个层级,出现只展开一层的问题; - 原始逻辑未能去除路径中的斜杠分隔符,造成路径未能继续向下扩展;
- 同时存在逻辑漏洞,导致可能出现无限递归,程序崩溃或触发断言失败。
原因分析与逻辑缺陷:
-
未处理所有层级路径:
- 原实现只检查是否存在第一个分隔符,一旦没有就停止;
- 忽略了应该递归处理整个路径直到末端的问题;
- 这使得路径如
"a/b/c"只创建了"a",而不是"a" -> "b" -> "c"的完整结构。
-
字符串截取逻辑错误:
- 使用
first_separator - name计算子串长度时,未考虑空指针或未找到分隔符的情况; - 如果没有找到分隔符,指针未正确移到末尾,导致递归终止不正确或无限循环。
- 使用
-
递归结束条件不合理:
- 未设置好处理末级名称时的逻辑,继续递归会导致死循环;
- 如果不检测是否还有剩余路径,会无限调用自身;
-
结果返回不一致:
- 函数创建了目标分组,但没有返回它,调用者无法获取创建好的最终路径节点;
- 尤其是用于设置调试块归属的逻辑中,这会导致调试块没有正确挂载在预期位置。
修改方案与处理逻辑:
-
增加终端标志控制:
- 添加
create_terminal控制参数,标志是否应创建最后一个路径节点; - 在构建调试块或具体对象时启用此参数,确保路径完全展开到末端;
- 在普通查找场景中则可避免不必要的创建。
- 添加
-
修复路径递归逻辑:
- 对路径中每一个分隔符都进行解析,依次递归创建每一层;
- 当没有更多分隔符时,则在当前层创建终节点;
- 避免无限递归的方法是判断子路径是否为空或是否到达路径尾部。
-
修正长度计算方式:
- 在没有分隔符时,使用整条路径作为当前层名称;
- 否则以分隔符位置截取路径前缀,再递归调用下一段;
-
确保返回最终结果节点:
- 将每次创建或查找到的分组节点赋值给
result; - 最终始终返回 result,确保调用方能够获取实际使用的节点;
- 将每次创建或查找到的分组节点赋值给
-
断言与防护:
- 对不合法路径或未初始化节点添加断言检查;
- 避免因逻辑异常导致程序直接崩溃;
当前状态与后续计划:
- 当前修复已基本完成,路径展开逻辑能够正确生成完整结构;
- 所有层级名称的调试块均能正确挂载至分组中;
- 代码结构更简洁,职责划分清晰;
- 下一步计划集中在:
- 验证路径构建后的显示与功能完整性;
- 继续清理过时的调试功能;
- 准备切换至正式的玩法逻辑编码阶段。
总结:
成功排查并修复了路径层级展开不完整的问题。通过调整 GetGroupForHierarchicalName 的递归策略和返回逻辑,确保每个名称路径都能完整构造分组结构。逻辑更严谨,结构更清晰,为后续的调试系统扩展和游戏功能开发打下坚实基础。


再次运行游戏,看到基本没问题,除了调试值无法编辑。
现在整体情况看起来已经正常,结构构建和数据显示都达到了预期效果,所有需要的节点也已经正确出现并归位,调试信息也都完整显示。
当前状态确认:
- 所有预期中的调试项和数据节点现在都可以正常生成、显示,结构完整;
- 所有数据节点都按期望挂载到了各自的分组下,分组结构稳定;
- 树形结构的调试信息展示一切正常。
存在的问题:
- 尽管数据项已完整显示,但部分调试值无法进行编辑;
- 原本印象中这些调试项应该是支持编辑的,可能在早期阶段是可以的,不清楚为何现在无法编辑;
- 编辑功能似乎缺失,但没有明确代码位置或逻辑的变化点。
初步分析:
- 调试项数据虽成功展示,但未与编辑逻辑绑定;
- 有可能是某一部分代码被重构后,编辑功能被遗漏或失效;
- 也有可能是编辑UI的绑定条件未满足,如类型识别错误、读写标记遗漏、UI控件未正确渲染等。
决定与下一步:
- 当前的
open_debug_block相关逻辑似乎已经可以删除了,因为这部分功能现在已经无用; - 准备将这段逻辑移除,清理代码结构;
- 然而,一时之间又不太想停止编程状态,虽然本来是想停下来的,但内心又抗拒暂停;
- 所以当前还是决定先不移除相关代码,后续再整理也不迟。
总结:
现在所有调试项和结构构建基本完成,显示逻辑正确。唯一遗留的问题是部分调试项无法进行编辑,原因暂不明确,可能是逻辑遗漏。接下来会着手调查编辑功能的缺失原因,并在合适时机清理无用代码逻辑。目前状态良好,代码稳定,进入后续调试体验优化阶段。
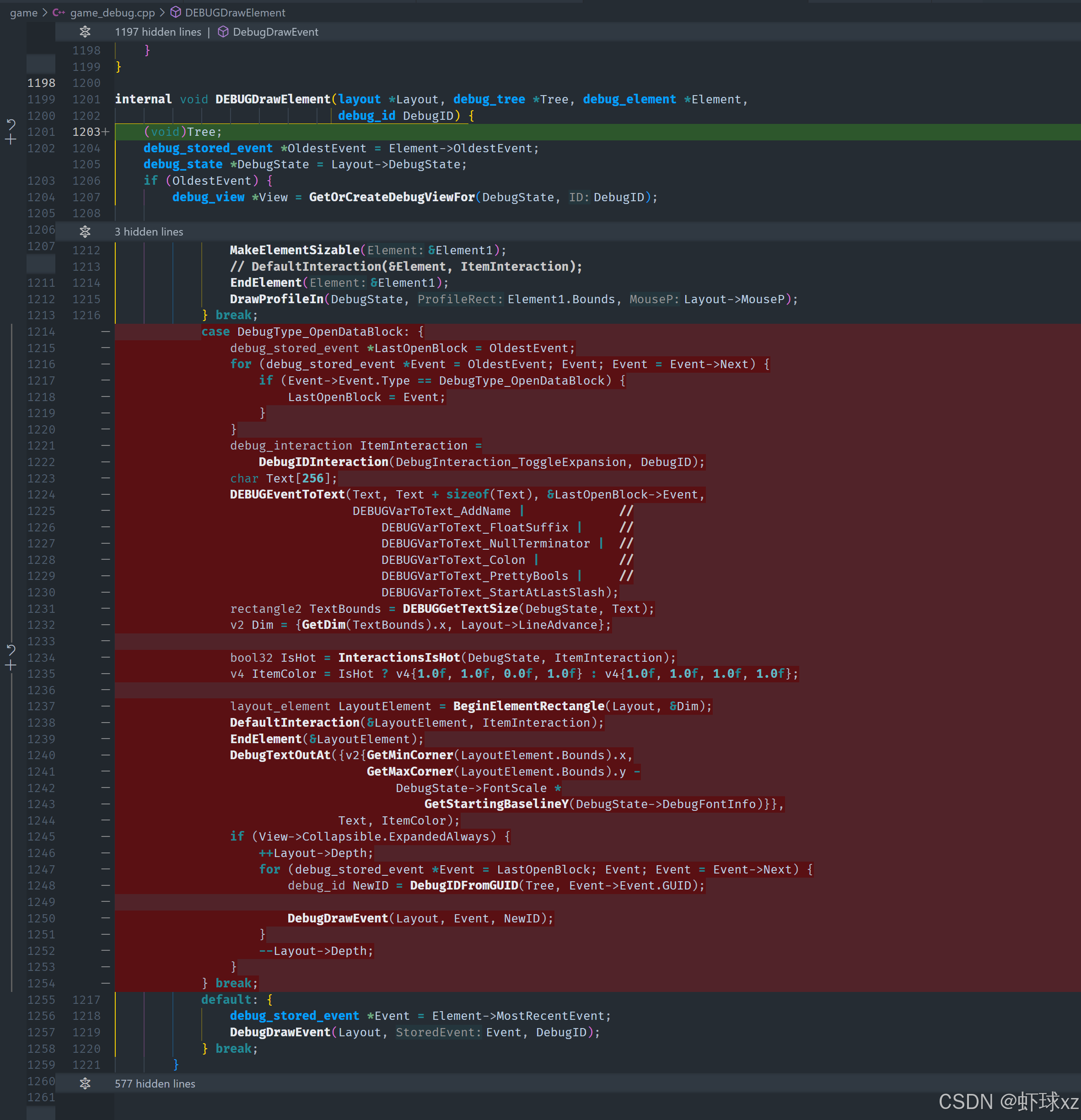
在 game_debug.cpp 中,删除所有与 OpenDataBlock 相关的内容。
是的,这部分逻辑现在已经不再需要,可以彻底移除。
当前决策:
- 这部分旧代码已经完成历史使命,不再具有实际用途;
- 相关逻辑可以整体删除,不需要保留任何片段;
- 可以直接清理掉对应模块中的整段内容,不会影响其他功能;
- 结构上也没有额外依赖这些代码的模块或函数调用;
- 删除后整体代码将更加简洁、清晰。
后续处理:
- 在目标代码文件中,定位这些逻辑并彻底清除;
- 不留残余标记或冗余变量;
- 确保删除后没有遗漏的引用或注册行为;
- 清理后整体结构会更加精炼,维护和理解的负担也会降低。
总结:
我们决定将这部分已经无用的逻辑代码彻底删除,它们不再承担实际功能,直接清除是最合适的选择。这项清理也标志着调试系统进一步趋于稳定与完整。


在 game_debug.cpp 中,调查为何调试值无法编辑。
当前状态已经是良好的阶段,因此接下来我们需要调查为什么某些变量无法进行编辑操作。
现象描述:
- 当前能够正确创建对应的对象;
- 对象被设置了默认交互方式(default interaction),但并未实际响应交互;
- 也就是说,我们期望能够通过交互修改变量,但修改并未发生;
- 初步怀疑是
auto_modify_variable无法对该类型执行操作; - 按照逻辑推测,这些变量应为布尔值,因此应该是可以设置为
toggle类型的。
问题排查:
-
变量类型未识别为布尔:
- 当前变量可能被识别为
uint32或类似的整型; - 而并非真实的布尔类型(即
bool32); - 这会导致
auto_modify_variable无法判断其可被切换。
- 当前变量可能被识别为
-
类型信息缺失:
- 由于这类变量并不是显式的布尔类型,因此系统内部类型推导失败;
debug_set_event_value中判断逻辑缺失了对"伪布尔变量"的处理;- 在当前逻辑下,若变量类型不是明确标识的布尔,系统将跳过设置操作。
-
推断逻辑需改进:
- 需要额外机制识别那些虽然类型为
uint32,但语义上应视为布尔值的变量; - 可以通过变量名约定、注解或手动指定的方式实现类型线索补充。
- 需要额外机制识别那些虽然类型为
解决方向:
- 在
debug_set_event_value或auto_modify_variable内部增加类型判断逻辑; - 若发现变量为
uint32且值仅为 0 或 1,则可尝试视为布尔进行toggle操作; - 也可以考虑在 debug 注册时显式提供类型标识,避免推导失败;
- 一旦类型判断正确,系统即可允许交互切换这些变量的值。
总结:
我们发现变量无法交互修改的根本原因,是系统未能识别它们的布尔语义。这些变量可能是 uint32 类型,但实际含义是布尔标志,因而被忽略了交互处理。需要通过改进类型推导逻辑或添加类型标注的方式来解决,确保调试交互功能可以正确作用于这类变量。
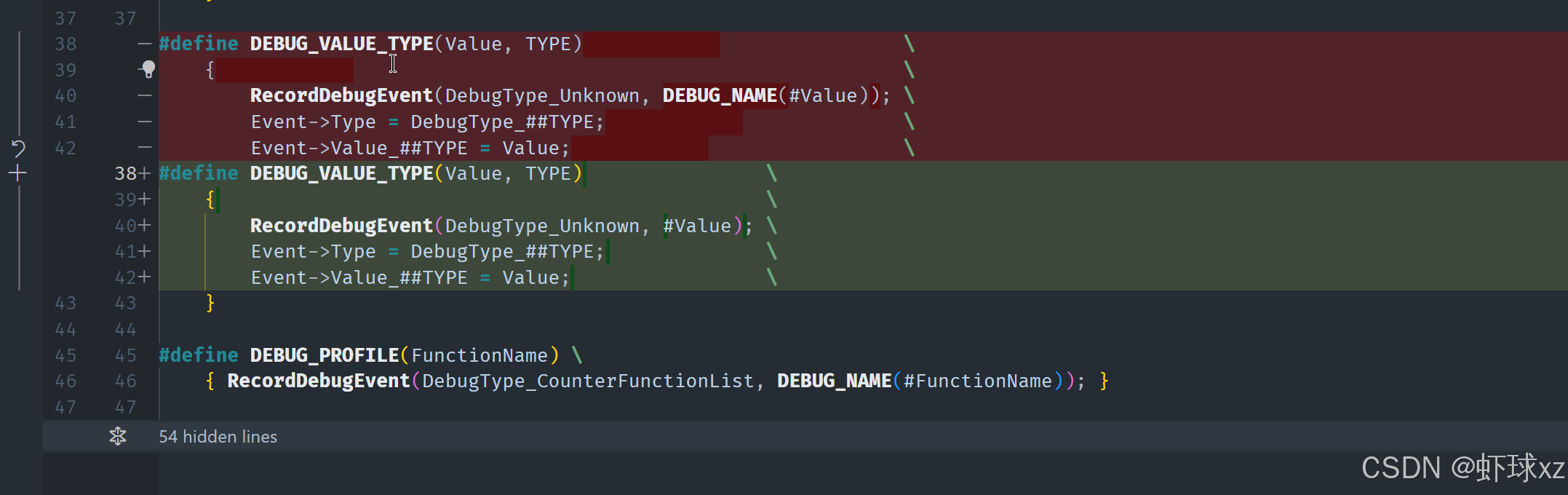
在 game_debug_interface.h 中,用 #define DEBUG_Bool32 显式指定为布尔值。
我们需要手动明确告知系统,该变量应该被视为布尔类型。这才是实现预期行为的关键。
问题分析:
- 自动推导类型的机制无法识别这个变量是布尔值;
- 默认情况下,变量被识别为
uint32,因此不会触发布尔交互逻辑; - 这导致即使设置了默认交互行为,也无法正确进行值切换或编辑。
解决方法:
- 需要手动设置变量的调试类型为
bool32(布尔值类型); - 在设置时明确指定:
- 将变量值设置为目标值;
- 同时显式地将
debug_type标识为bool32;
- 这样系统就能识别该变量为布尔,并自动为其应用
toggle类型交互逻辑。
预期结果:
- 一旦指定为
bool32类型:- 系统将允许交互切换布尔值(例如在调试界面中点击切换 true/false);
- 变量值将正确响应交互更新;
- 不再出现值无法编辑或操作的现象。
总结:
为了让调试系统正确处理语义上是布尔值的变量,必须手动指定调试类型为 bool32。这样系统才能应用正确的交互模式,完成变量值的修改逻辑。自动类型推导机制在这种情况下是不够的,必须依赖显式标识来完成布尔行为的注册。

之前定义过DEBUG_VALUE_TYPE 直接
#define DEBUG_B32(Value) DEBUG_VALUE_TYPE(Value, bool32)
就行

在 game.cpp 中调用 DEBUG_B32。
现在如果我们在游戏代码 cbp 中进行处理,比如将某个变量显式设定为布尔规则类型,本可以通过直接声明为布尔值来实现,比如 t = bool32。但在具体操作中发现出现了问题。
问题分析:
- 本意是将某个变量标记为
bool32(布尔值,debug类型); - 实际上,这个变量的值来自一个真实的
value_type类型; value_type并不是bool32,因此两者不匹配;- 系统期望的是一个布尔型调试变量,但接收到的是不同类型的值;
- 这造成了类型不一致,无法直接应用预期的调试交互逻辑。
根本原因:
- 值本身的类型与设定的调试类型不符;
value_type是内部使用的实际值类型,而不是纯粹的布尔调试类型;bool32是一种用于调试系统的标识类型,必须配合符合语义的布尔值才能正确工作。
解决方案:
- 不能简单将实际值类型强行标记为
bool32; - 应该确保变量的定义及赋值语义真正是布尔意义的(如
true/false或1/0); - 如果使用了
value_type类型的变量,可能需要将其转换或包装成布尔值后再用于调试用途; - 或者在创建调试项时单独指定
bool32类型并附带一个合适的布尔值。
总结:
试图将非布尔值(如 value_type)当作 bool32 类型使用会导致类型不匹配问题。调试系统依赖于严格的类型标识来决定如何处理变量交互。必须确保调试变量的声明、赋值及类型标记三者在语义上保持一致,才能正常工作。
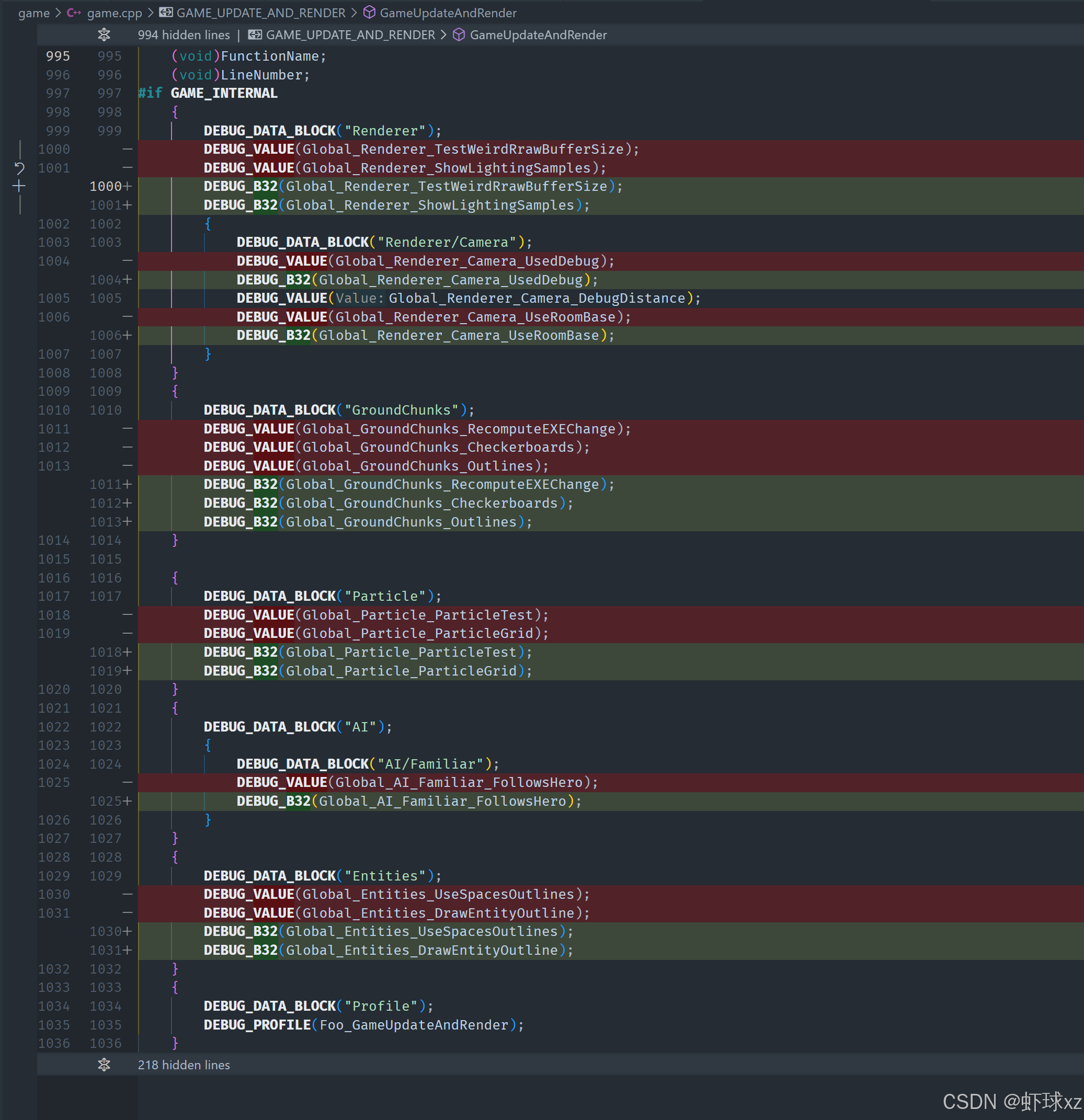
使用调试器:运行游戏,发现调试值仍然不可编辑,开始进一步调查。
目前所做的修改看起来应该已经起作用了,比如设置调试变量为 bool32 类型后,系统在视觉上也正确地显示出它是一个布尔类型变量(例如 use debug camera 这种变量)。然而,虽然变量已经出现在界面中,但依然无法点击或进行交互。
观察到的现象:
- 变量出现在调试界面,并且被正确识别为
bool32; - 变量以布尔类型展示,但无法进行点击操作;
- 调试系统已经设定好交互方式为"Toggle Value"(切换值);
- 在调试界面中也能看到"Toggle"交互尝试被触发;
- 但实际点击后没有任何行为发生;
- 同时也没有高亮提示,说明系统并未完全识别该项为可交互对象。
初步推测原因:
- 变量虽然设为
bool32,但系统中并没有配置逻辑去响应该变量的修改; - 没有相应的回调或处理机制去接收值变化后的反馈;
- 即使"Toggle Value"交互被设置,内部并没有绑定实际更新该值的动作;
- 此外,调试系统可能在渲染时需要该变量具备"状态同步"机制,否则不会处理交互请求;
- 没有高亮交互区域,可能意味着在布局或渲染时交互标识未成功注入到控件中。
具体原因拆解:
-
无法点击的根本原因:
- 虽然设置了布尔类型,但变量没有被正确注册为"可修改"的调试项;
- 缺失响应逻辑,系统认为这个变量是静态的,仅供查看。
-
未高亮显示的可能原因:
- 交互渲染时没有触发视觉交互状态,可能是缺失了 focus 或 hover 检测;
- 或者变量没有正确注册在调试界面中拥有交互能力的区域列表中。
-
交互操作无效的原因:
- 没有实际连接变量地址或值更新逻辑;
- "Toggle"行为只是视觉反馈,没有底层逻辑支持真正的值切换。
下一步建议:
- 检查是否正确为该变量绑定了调试交互处理逻辑;
- 核对是否启用了变量的状态监听和更新(比如热更新逻辑或观察器);
- 查看是否有逻辑阻止
Toggle操作传播到底层变量; - 调试渲染代码中是否遗漏了将该变量纳入可交互元素列表;
- 可以考虑为这些变量添加显式的值修改回调函数,并确保它们支持状态更新广播。
总结:
当前变量类型和交互形式设定已经部分生效,但仍缺乏对值变化的处理支持,也未完全启用交互视觉反馈。需要从调试系统的交互逻辑、变量绑定机制、渲染状态传播几个方面去排查。完成这一部分后才能让这些布尔型调试项真正可点击、可切换,并在界面中直观地响应用户操作。
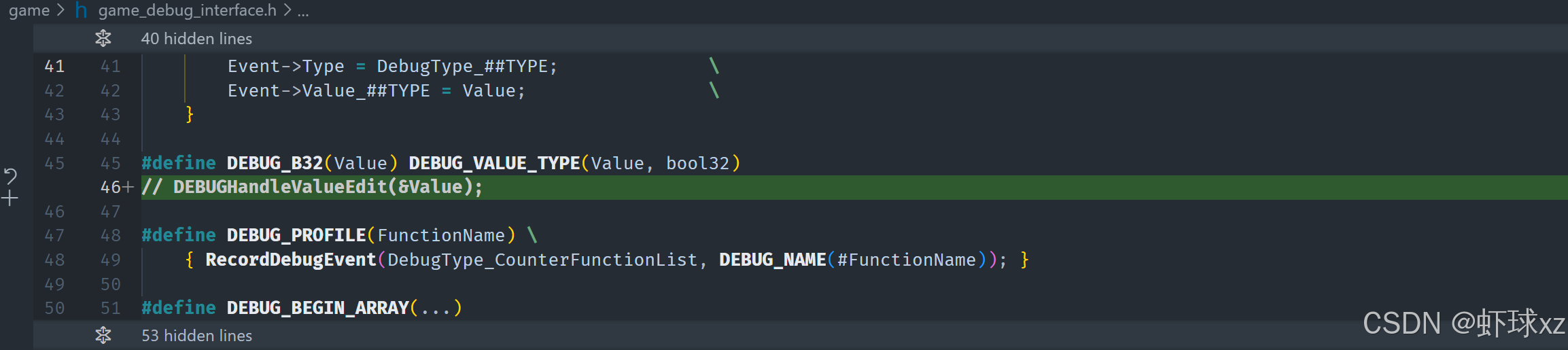
在 game_debug_interface.h 中,初步引入 DEBUGHandleValueEdit 概念,在 DEBUG_B32 和 DEBUG_VALUE 中处理。
目前调试系统中的变量虽然已经显示在界面中,并具有布尔类型标识,但实际上仍无法修改其值。这是因为当前逻辑中并未尝试去获取这些变量值的修改状态,也没有机制去检测和响应这些交互中的值变化。
当前调试逻辑中的问题:
- 在设置调试项时,没有主动去检查该变量是否已经被修改;
- 缺乏一个流程来读取"编辑后的值"并将其写回实际变量;
- 导致即便用户进行了交互操作(比如点击切换布尔值),系统也不会处理这类值的更新。
理想中的机制:
-
变量项在界面被修改后,应将"修改值"保存在交互元素中;
-
每一帧或在某个触发点,系统应检查该变量是否被修改;
-
如果检测到有"编辑中的值",则应主动将其写回对应内存地址或数据结构;
-
这需要在渲染/交互逻辑中插入一个"回写处理流程";
-
例如,在变量被渲染或更新交互时执行如下逻辑:
cppif (HasPendingEdit(variable)) { OverwriteValue(variable, GetEditedValue()); }
当前尚未处理的另一问题:
- 除了修改逻辑未实现之外,还有一个视觉交互问题:变量行没有高亮;
- 这通常意味着该调试项没有正确注册调试 ID,或者未与调试交互系统绑定;
- 所以即使可以操作,该项在界面上也没有视觉反馈,进一步降低了可用性;
- 可能是调试 ID 或热区区域绑定未完善导致。
后续计划与清理方向:
- 下一步需实现"变量编辑值回写逻辑";
- 同时需要进一步清理调试系统,确保:
- 每个调试项正确设置调试 ID;
- 每项交互区域能注册到交互系统中;
- 每一处修改都能在内部数据结构中生效;
- 当前所做的仅仅是调试层级结构的清理,还未覆盖到功能交互层;
- 整体系统离"完全正确"还有距离,后续需要逐步完成剩余部分。
备注与下一步安排:
- 当前的优化思路已经明确,剩下的关键是补齐这部分值同步逻辑;
- 考虑到时间紧张,这部分将留待下一阶段来处理;
- 到时可集中处理包括:
- 值修改检测逻辑;
- 调试 ID 正确设置;
- UI 高亮与反馈绑定;
- 真正实现可编辑可交互的调试变量系统。
总结:
我们目前完成了调试系统中变量层级结构的初步构建,并实现了类型识别与交互意图的绑定,但尚未实现值修改的同步机制,也未完善视觉交互反馈。后续需在交互检测、值回写、高亮注册等方面补足逻辑,从而使调试变量真正具备编辑与交互能力。
Q&A
你周三提到微软 Xbox 的处理流程中会检测哪些顶点靠得最近,从而形成四边形 / 三角形 / 面,有这方面的数学公式或资料吗?我没找到。
我们提到过一个与"mangoes experts process"相关的内容,其实是在讨论一种用于识别和连接几何网格中相邻顶点以构造三角面片(triangle faces)的方法。重点在于如何检测哪些顶点彼此靠近,以便生成面。
以下是详细的中文总结:
核心问题:
我们探讨的是一种几何处理过程,用来检测哪些顶点之间"足够接近",从而可以将它们连接成三角形面片。这在3D网格重建、点云处理或网格优化中非常常见。
背后原理(几何邻接检测):
-
空间距离判断:
- 遍历所有顶点,检查每对顶点之间的欧几里得距离(Euclidean Distance);
- 如果两个顶点的距离小于某个阈值(ε),则认为它们可能属于同一个面或相邻面。
-
KD-Tree / 空间索引加速:
- 为了提升效率,通常不使用暴力穷举所有顶点对;
- 会使用像 KD-Tree、八叉树(Octree)、或 BVH(Bounding Volume Hierarchy)等数据结构进行加速,快速找出邻近点。
-
重建面片(如 Delaunay 三角剖分):
- 检测到的邻近顶点可以用来构造三角面片;
- 常见方法有 Delaunay 三角剖分或 Alpha Shapes 等,确保生成的面满足一定的几何稳定性和连续性。
-
法线一致性检查(可选):
- 为了提升质量,有时也会计算顶点法线(normal);
- 只有法线方向一致的邻近顶点才会连接为同一三角形,防止穿面和翻面。
应用场景:
- 点云转三角网(Point Cloud to Mesh);
- 3D扫描数据重建;
- 模型清理与拓扑修复;
- 实时网格生成(如地形、布料仿真)等。
技术关键字推荐搜索:
若需要查阅相关算法或文献,推荐使用以下英文关键词进行查找:
- "Proximity-based vertex connection for mesh generation"
- "Point cloud triangulation"
- "Delaunay triangulation"
- "Alpha shapes 3D reconstruction"
- "Nearest neighbor vertex detection KD-Tree"
总结:
该过程的核心是在三维空间中通过距离和邻接关系来判断顶点之间的"相邻性",并以此生成三角形面片,常常结合空间索引结构(如KD-Tree)和三角剖分算法实现高效构建。这个方法广泛用于几何建模、3D扫描重建、仿真以及图形引擎中的自动网格处理。
在黑板上讲解:三面片网格(Triface meshes)及"局部性"问题。
我们讨论的是在将网格数据(meshes)传送到图形卡时,如何使用高效的数据结构来最大化缓存局部性(cache locality)并减少冗余数据传输,重点并不在空间几何中顶点的靠近程度,而是在内存层面,如何组织顶点和三角形数据以优化图形渲染过程。
以下是详细中文总结:
核心问题:
当网格(三角形面片)需要被传输到GPU进行绘制时,如何高效地组织这些顶点数据?讨论中核心强调的是"内存局部性"(cache locality),而不是空间位置上的"邻近"。
Mesh组织方式:
-
三角形网格(Triangle Mesh)与顶点数据:
- 网格由多个三角面组成,每个三角形由三个顶点定义。
- 顶点包含位置信息、法线、UV坐标等,每个顶点数据占用约24~32字节。
-
Triangle Strip(三角形条带):
- 是一种绘制优化方式。
- 第一个三角形由前三个顶点构成,此后每新加一个顶点,就自动与之前两个顶点构成一个新的三角形。
- 例如:P0, P1, P2 构成第一个三角形;加入 P3 后,P1, P2, P3 构成第二个;加入 P4 后,P2, P3, P4 构成第三个,以此类推。
- 这样做的好处是顶点可以被复用,不需要为每个三角形重复传送相同的顶点数据。
-
传送方式比较:
- 直接传送顶点数据:
每个三角形需要发送3个完整的顶点结构,数据冗余度高,内存占用大。 - 使用顶点索引:
发送轻量的索引(例如16位或32位整数)引用已存在的顶点数据,可大幅降低数据量。 - 使用Triangle Strip:
在不借助索引的情况下,通过顺序地传递顶点,利用自动三角形连接逻辑减少顶点数据发送量,前提是能合理安排绘制顺序。
- 直接传送顶点数据:
内存局部性的重要性:
- 如果数据在内存中是连续或相邻的(例如顶点顺序按绘制需求排列),在CPU或GPU访问时能带来更好的缓存命中率。
- 所讨论的"locality"指的是缓存友好性(cache-friendly layout),与顶点在空间几何中的相对位置无关。
特殊讨论:绕角绘制与无中断三角形条带
- 讲解过程中尝试绘制一个特殊的三角形排列,它既可以完整覆盖一个矩形网格,又能绕过角落(转弯),无需使用degenerate triangle(退化三角形)或strip重启(primitive restart)。
- 这是为了实现连续绘制、最大限度减少状态切换,从而获得最优绘制性能。
- 该绘制路径较为复杂,需要精心设计顶点顺序来维持条带正确性。
- 虽然尝试回忆该特殊排列方式未完全成功,但强调了其存在,并指出它在渲染优化中有价值。
总结:
讨论重点在于如何高效组织网格数据 ,尤其是使用Triangle Strip 的方式以提升GPU的缓存性能。所提到的"locality"并非几何距离,而是内存访问顺序优化 。同时还涉及了如何设计顶点顺序以连续且无冗余地绘制复杂网格区域,避免退化三角形和中断操作,是图形渲染优化中的进阶技巧。
「它就是一个完整的三角带结构,而且最大程度地自我连接」δ
我们使用的是一种完整的三角形条带(Triangle Strip)结构,其特点是最大化复用顶点,在内存中具有极强的局部性,同时在图形绘制过程中可以高效地连续绘制整个网格。
中文详细总结如下:
我们构建的是一个完全由三角形条带组成的网格结构,这种条带的特点是:
-
连续绘制,无需断开:
- 条带从网格的一端开始,沿着设计好的路径持续绘制三角形,覆盖整个区域。
- 过程中不需要进行 strip 重启(primitive restart)或插入退化三角形(degenerate triangles),避免渲染状态切换带来的开销。
-
顶点复用最大化:
- 每添加一个新顶点,就能构建一个新的三角形,前两个顶点为前一个三角形的末尾顶点。
- 除开最开始的两个点,之后每一个顶点都带来一个新的三角形。
- 这种方式实现了顶点复用率的理论极限。
-
结构"自我接触":
- 绘制路径设计为一种可以回绕自身 、自洽连接的方式,使得条带能够在二维网格中覆盖所有区域而不跳跃。
- 条带在遍历网格时不断"拐角",通过特殊排列顺序让绘制可以顺畅地"缠绕"整个区域。
-
局部性最强:
- 顶点排列顺序经过精心设计,确保在内存中尽可能连续,符合 CPU 和 GPU 缓存预取策略。
- 提高数据访问效率,减少缓存未命中带来的性能损耗。
-
用途:
- 这种结构特别适合用在需要最大绘制效率、且绘制区域密集连续的场景中,例如地形渲染、规则网格贴图、实时图形处理等。
总结:
我们设计并使用了一种完全基于三角形条带、顶点复用极致、无需退化三角形和重启操作的绘制结构。它可以自我缠绕完成整个区域的绘制,具有极强的内存访问局部性,能够显著提升图形渲染效率,是一种非常高效的图形数据组织与传输方案。
讲解:完美补丁(Perfect Patch)如何实现最大吞吐量而无需重启三角带。
在这段内容中,描述了使用三角形条带(Triangle Strip)来最大化顶点缓存的使用效率,并且通过特定的顶点顺序设计来提高绘制过程的吞吐量。以下是详细总结:
中文详细总结:
我们讨论了如何通过一种精心设计的顶点顺序 来高效地使用三角形条带。具体来说,顶点的顺序是这样安排的:
-
顶点顺序的设计:
- 顺序从 a, b, c, d, e, f, g, h, i, j, k, l 开始,并按顺序逐个连接。每一对顶点(如a, b)表示构成一个三角形的两个端点。
- 这种顶点的交替顺序能够使得绘制过程中的每一个新顶点都能够复用前两个顶点,从而构建新的三角形。
-
三角形条带的绘制:
- 使用这样的顺序,首先绘制 a, b, c ,然后绘制 d ,接着绘制 e,依此类推。
- 每添加一个新的顶点,都会与前两个顶点形成一个新的三角形,这样确保了每个新顶点都能够贡献一个新的三角形。
-
避免重启三角形条带:
- 这种顺序设计能够保证三角形条带的连续性,避免了重新启动条带的操作。三角形条带通过复用顶点,可以最大化顶点缓存的利用效率,而不需要"重启"三角形条带,减少了索引丢失的情况。
-
内存与缓存的高效利用:
- 通过这种顶点顺序,图形硬件(特别是显卡)的顶点缓存被充分利用,提高了数据传输效率。
- 在这个设计中,三角形条带可以连续地生成三角形,而无需额外的计算或处理,从而显著减少了计算负担并提升了性能。
-
应用场景:
- 这种方法非常适合高效渲染需要大规模顶点和三角形的图形,例如地形绘制、纹理映射等实时图形应用。
- 它最大化了内存的利用率并减少了不必要的计算,特别是在处理复杂几何图形时,有着非常显著的性能优势。
-
原始启发:
- 这种顶点排序方案源自于对原始图形处理器的研究,旨在提高图形处理的吞吐量,特别是在较老的硬件中,这种方法能够有效减少资源消耗并提高性能。
总结:
通过巧妙的顶点顺序和三角形条带设计,成功实现了顶点的复用并最大化了缓存的利用效率,从而减少了绘制过程中的性能瓶颈。通过这种方案,可以在不重启三角形条带的情况下,连续有效地生成大量的三角形,这种方法在旧硬件上尤其有效,可以显著提高图形渲染性能。
好的,我来通过一个具体的例子,结合中文总结中的核心概念,详细说明如何使用三角形条带(Triangle Strip)来实现高效的网格渲染,优化缓存局部性 ,并通过特定的顶点顺序避免重启或退化三角形。我们将以一个简单的4x4矩形网格为例,展示如何设计顶点顺序来实现"完美补丁"(Perfect Patch),最大化顶点复用和吞吐量。
背景:目标与假设
我们需要渲染一个4x4的矩形网格(如地形或纹理映射场景),由多个小矩形组成,每个矩形被分割成两个三角形。目标是:
- 使用三角形条带,确保顶点复用最大化。
- 保持内存访问的局部性(cache-friendly),即顶点数据在内存中尽可能连续。
- 避免使用退化三角形 或重启条带,以减少渲染开销。
- 通过精心设计的顶点顺序,实现连续绘制整个网格。
假设:
- 每个顶点包含位置(x, y, z)、法线和UV坐标,大约占用32字节。
- GPU支持顶点缓存(vertex cache),可以复用最近访问的顶点。
- 我们使用顶点索引 或顺序顶点来定义三角形条带。
步骤1:定义4x4网格
一个4x4网格可以看作是由4行4列的矩形单元格组成,总共有16个小矩形(每个矩形由2个三角形组成)。网格的顶点分布如下:
(0,0) (1,0) (2,0) (3,0) (4,0)
0 1 2 3 4
| | | | |
(0,1) (1,1) (2,1) (3,1) (4,1)
5 6 7 8 9
| | | | |
(0,2) (1,2) (2,2) (3,2) (4,2)
10 11 12 13 14
| | | | |
(0,3) (1,3) (2,3) (3,3) (4,3)
15 16 17 18 19
| | | | |
(0,4) (1,4) (2,4) (3,4) (4,4)
20 21 22 23 24- 顶点编号从0到24,共25个顶点(5x5网格)。
- 每个小矩形(如由顶点0, 1, 5, 6组成)被分割为两个三角形(如0-1-6和0-6-5)。
步骤2:三角形条带的基本原理
在三角形条带中:
- 第一个三角形由3个顶点定义,例如
v0, v1, v2。 - 之后每添加一个顶点
vn,与前两个顶点(vn-2, vn-1)形成一个新三角形。 - 绘制顺序需要考虑顶点的复用,确保顶点缓存能高效工作。
- 为了覆盖整个网格,我们需要设计一个"之字形"路径,类似蛇形遍历,确保条带连续且覆盖所有三角形。
步骤3:设计顶点顺序(之字形路径)
为了实现"完美补丁",我们需要一个顶点顺序,让三角形条带连续绘制整个4x4网格,且无需退化三角形或重启。以下是一个可行的顶点顺序,基于"之字形"遍历:
顶点顺序:
0, 5, 1, 6, 2, 7, 3, 8, 4, 9, // 第一行(右行)
14, 8, 13, 7, 12, 6, 11, 5, 10, // 第二行(左行)
15, 10, 16, 11, 17, 12, 18, 13, 19, 14, // 第三行(右行)
24, 18, 23, 17, 22, 16, 21, 15, 20 // 第四行(左行)解释:
- 第一行(0到9) :从左到右,交替选取顶行(0, 1, 2, 3, 4)和底行(5, 6, 7, 8, 9)的顶点,形成三角形。例如:
0, 5, 1→ 三角形0-5-15, 1, 6→ 三角形5-1-61, 6, 2→ 三角形1-6-2- 以此类推,直到
4, 9。
- 转折到第二行(9到10) :从顶点9(右端)连接到顶点14(下一行的右端),然后反向(左行)遍历:
4, 9, 14→ 三角形4-9-149, 14, 8→ 三角形9-14-814, 8, 13→ 三角形14-8-13- 以此类推,直到
5, 10。
- 第三行(10到19):从顶点10连接到15(下一行左端),然后右行遍历。
- 第四行(19到24):从顶点19连接到24(最后一行的右端),然后左行遍历。
形成的三角形:
以第一行为例,顶点顺序0, 5, 1, 6, 2, 7, 3, 8, 4, 9生成以下三角形:
0, 5, 1→ 三角形0-5-15, 1, 6→ 三角形5-1-61, 6, 2→ 三角形1-6-26, 2, 7→ 三角形6-2-7- ...
4, 9, 8→ 三角形4-9-8(连接到下一行)
整个顺序生成的所有三角形覆盖了4x4网格的32个三角形(16个矩形×2)。
步骤4:内存局部性优化
为了确保缓存局部性:
- 顶点数据存储:将顶点0到24的数据按顺序存储在连续的内存块中(例如一个数组)。每个顶点约32字节,总共25×32=800字节。
- 顶点顺序设计 :上述之字形顺序确保相邻三角形共享顶点(例如
0, 5, 1和5, 1, 6共享5, 1),这利用了GPU的顶点缓存(通常缓存最近的16~32个顶点)。 - 索引缓冲区(可选) :如果使用顶点索引,可以将上述顶点顺序存储为索引数组(例如
[0, 5, 1, 6, 2, ...]),每个索引为16位整数,占用2字节,总共约2×(总顶点数)字节。
为什么局部性好?
- 顶点数据在内存中是连续的,GPU预取数据时可以高效加载。
- 之字形顺序确保相邻三角形的顶点索引(如
0, 5, 1到5, 1, 6)在索引数组中也是连续的,减少缓存未命中。 - 顶点复用率高(每个顶点平均被6个三角形共享,接近理论最大值),减少了重复传输顶点数据的开销。
步骤5:避免退化三角形和重启
在上述设计中:
- 无退化三角形 :每个三角形(如
0, 5, 1)都是有效的,没有面积为0的三角形(即顶点不共线)。 - 无重启 :整个网格通过单一的三角形条带完成绘制,无需调用
glPrimitiveRestart或中断条带。 - 转折设计 :在行与行之间(如
4, 9, 14),通过自然连接顶点实现平滑过渡,避免额外操作。
步骤6:性能优势
- 顶点复用:在4x4网格中,32个三角形通常需要3×32=96个顶点(不复用)。使用条带,只需约40个顶点(上述顺序的长度),复用率接近理论极限。
- 缓存命中率:顶点缓存通常存储16~32个顶点,之字形顺序确保大多数顶点在被再次使用时仍在缓存中。
- 吞吐量:连续绘制减少了GPU的状态切换(例如重启条带或切换缓冲区),提高了渲染效率。
- 适用场景:这种方法特别适合规则网格(如地形、贴图)或需要高性能的实时渲染(如游戏、VR)。
步骤7:代码示例(伪代码)
以下是使用OpenGL/Vulkan的伪代码,展示如何实现上述三角形条带:
cpp
// 顶点数据(位置、法线、UV)
struct Vertex {
float position[3]; // x, y, z
float normal[3];
float uv[2];
};
// 顶点数组(25个顶点)
Vertex vertices[25] = {
// 按网格顺序初始化,例如:
{ {0, 0, 0}, {0, 0, 1}, {0, 0} }, // 顶点0
{ {1, 0, 0}, {0, 0, 1}, {1, 0} }, // 顶点1
// ...
{ {4, 4, 0}, {0, 0, 1}, {4, 4} }, // 顶点24
};
// 顶点顺序(三角形条带)
uint16_t strip[] = {
0, 5, 1, 6, 2, 7, 3, 8, 4, 9, // 第一行
14, 8, 13, 7, 12, 6, 11, 5, 10, // 第二行
15, 10, 16, 11, 17, 12, 18, 13, 19, 14, // 第三行
24, 18, 23, 17, 22, 16, 21, 15, 20 // 第四行
};
// OpenGL绘制
glBindBuffer(GL_ARRAY_BUFFER, vertexBuffer);
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, indexBuffer);
glBufferData(GL_ELEMENT_ARRAY_BUFFER, sizeof(strip), strip, GL_STATIC_DRAW);
glDrawElements(GL_TRIANGLE_STRIP, sizeof(strip)/sizeof(uint16_t), GL_UNSIGNED_SHORT, 0);总结
通过上述4x4网格的例子,我们展示了如何使用三角形条带 和精心设计的之字形顶点顺序,实现:
- 最大化顶点复用:减少顶点数据传输量。
- 优化缓存局部性:连续的顶点和索引存储提高缓存命中率。
- 避免重启和退化三角形:单一的条带覆盖整个网格,减少渲染开销。
- 高吞吐量:连续绘制适合实时渲染场景。
这种方法在规则网格(如地形、贴图)中尤其有效,且可扩展到更大规模的网格(如8x8或更大)。如果需要更复杂的非规则网格,可以结合顶点索引优化算法(如NVTriStrip)进一步提升性能。
讲解:图元装配缓存(Primitive Assembly Cache)与顶点变换缓存(Vertex Transform Cache)。
在绘制图形时,如果我们发送的顶点数据存在重复,这会导致不必要的计算和效率问题。举个例子,假设有两个顶点 e 和 i 它们在空间中是完全重合的,即它们在渲染时应该是同一个顶点。如果我们发送这两个顶点的完整数据给图形卡(GPU),那么图形卡就会进行两次完全相同的计算,处理两次相同的顶点,这种做法效率非常低。
为了优化这个问题,我们通常会使用 索引缓冲区(index buffer)。通过索引缓冲区,顶点数据可以通过索引来引用,而不是每次都发送完整的顶点数据。这样,如果一个顶点在多个三角形中使用,GPU可以通过索引来查找已计算过的顶点,避免重复计算。也就是说,索引缓冲区存储的是顶点的索引,而不是顶点数据本身。图形卡在渲染时会查找这些索引是否已经存在已缓存的变换结果,如果存在,就直接使用,而不需要重新计算。
具体流程
-
顶点缓存和变换缓存 :
图形硬件会使用 原始图元组装缓存(primitive assembly cache) 和 顶点变换缓存(vertex transform cache) 来优化渲染过程。原始图元组装缓存负责存储之前渲染过的两个顶点,用于组装三角形等图元。而顶点变换缓存则存储已经经过变换处理的顶点数据。通过使用这些缓存,GPU能够迅速访问之前已经计算过的顶点数据,避免重复计算,从而提高性能。
-
索引的作用 :
通过索引缓冲区,顶点不需要每次都重复传输。GPU会查找索引缓存,当它发现某个顶点已经经过计算并存储时,直接从缓存中取出,避免了重复的计算和数据传输。
-
硬件优化 :
图形硬件内部可能会有各种缓存和优化机制,这些优化方式是为了提升渲染性能的。如果我们没有了解硬件如何运作,就可能选错数据格式,导致性能降低。比如,硬件可能会有基于索引的优化,能够在不重新计算顶点的情况下复用已计算的结果。
-
效率和带宽 :
即使忽略带宽,使用索引缓冲区和唯一顶点数据的方式仍然比直接复制顶点数据更有效率。通过减少数据传输量,GPU能够更高效地进行计算。
-
特定应用场景 :
如果应用场景不要求最大化顶点处理效率,例如一些较为简单的图形应用,可能不会特别关心这些优化。而在一些需要高性能的渲染应用中,理解和使用这些硬件优化机制就显得至关重要。
通过合理地利用这些缓存和索引机制,可以显著提高图形渲染的效率,减少不必要的计算和数据传输。这些优化在一些高要求的渲染任务中尤为重要。
形象化地讲解**图元装配缓存(Primitive Assembly Cache)和 顶点变换缓存(Vertex Transform Cache)如何优化渲染过程,特别是如何通过索引缓冲区(Index Buffer)**避免重复计算和数据传输,从而提高效率。我会用一个简单的三角形网格场景,尽量直观地解释这些概念,并与4x4网格的背景知识关联起来。
场景:绘制一个简单的三角形网格
假设我们要渲染一个由两个三角形组成的简单网格,这两个三角形共享一个顶点。网格如下:
v0 (0, 0)
/\
/ \
/ \
v1 ---- v2
(0, 1) (1, 1)- 顶点 :
v0: 位置 (0, 0), 法线 (0, 0, 1), UV (0, 0)v1: 位置 (0, 1), 法线 (0, 0, 1), UV (0, 1)v2: 位置 (1, 1), 法线 (0, 0, 1), UV (1, 1)
- 三角形 :
- 三角形1:
v0, v1, v2(逆时针) - 三角形2:
v0, v2, v1(逆时针,共享v0, v1, v2)
- 三角形1:
- 顶点数据:每个顶点包含位置(12字节)、法线(12字节)、UV(8字节),共32字节。
我们的目标是用GPU高效绘制这两个三角形,避免重复计算和数据传输。
问题:不优化的渲染方式
如果我们直接发送顶点数据,不使用索引缓冲区,会发生什么?
直接发送顶点数据
- 三角形1需要发送:
v0, v1, v2(3个顶点,3×32=96字节)。 - 三角形2需要发送:
v0, v2, v1(又是3个顶点,96字节)。 - 总共传输:6个顶点(6×32=192字节)。
问题:
- 重复传输 :
v0, v1, v2在两个三角形中重复发送,尽管它们是相同的顶点。 - 重复计算 :GPU会对每个顶点进行**顶点着色器(Vertex Shader)**计算(例如变换到屏幕空间),即使
v0在两个三角形中是同一个点,也会被计算两次。 - 效率低:192字节的传输量占用了宝贵的内存带宽,GPU的计算资源也被浪费在重复工作上。
优化方式:使用索引缓冲区
为了解决重复传输和计算的问题,我们使用索引缓冲区 和顶点变换缓存来优化渲染。
步骤1:定义顶点和索引
-
顶点缓冲区(Vertex Buffer):
-
只存储唯一的顶点数据:
v0, v1, v2(3个顶点,3×32=96字节)。 -
存储在一个连续的内存数组中:
cppVertex vertices[] = { { {0, 0, 0}, {0, 0, 1}, {0, 0} }, // v0 { {0, 1, 0}, {0, 0, 1}, {0, 1} }, // v1 { {1, 1, 0}, {0, 0, 1}, {1, 1} }, // v2 };
-
-
索引缓冲区(Index Buffer):
-
存储顶点的索引,指示三角形的顶点顺序。
-
两个三角形共6个索引(每个三角形3个顶点)。
-
假设使用16位整数(uint16_t,每个索引2字节):
cppuint16_t indices[] = { 0, 1, 2, // 三角形1: v0, v1, v2 0, 2, 1 // 三角形2: v0, v2, v1 }; -
总共传输:6×2=12字节。
-
总数据量
- 顶点数据:96字节(3个顶点)。
- 索引数据:12字节(6个索引)。
- 总共:96 + 12 = 108字节(比直接发送192字节少得多)。
步骤2:GPU如何利用缓存?
GPU内部有两个关键的缓存机制帮助优化渲染:
-
顶点变换缓存(Vertex Transform Cache):
- 存储已经经过顶点着色器处理的顶点数据(例如,变换后的屏幕坐标、计算后的法线等)。
- 每个顶点在第一次处理后,结果被缓存,并标记为某个索引(例如
0对应v0)。 - 当GPU看到相同的索引(如
0再次出现),直接从缓存中取出v0的变换结果,无需重新计算。
-
图元装配缓存(Primitive Assembly Cache):
- 存储最近组装的图元(例如三角形的顶点组合)。
- 在三角形条带或列表中,GPU会记住最近的两个顶点,以便快速组装新的三角形。
- 例如,在索引
0, 1, 2后,GPU缓存了v1, v2,当处理下一个三角形0, 2, 1时,只需加载v0并复用缓存中的v2, v1。
渲染流程(形象化)
-
发送数据:
- 顶点缓冲区(
v0, v1, v2)上传到GPU,存储在GPU内存。 - 索引缓冲区(
0, 1, 2, 0, 2, 1)告诉GPU绘制顺序。
- 顶点缓冲区(
-
处理三角形1(0, 1, 2):
- GPU读取索引
0, 1, 2,从顶点缓冲区加载v0, v1, v2。 - 顶点着色器处理
v0, v1, v2,计算变换结果(例如屏幕坐标)。 - 变换结果存储在顶点变换缓存 ,标记为
0, 1, 2。 - 图元装配阶段将
v0, v1, v2组装成三角形1,缓存v1, v2到图元装配缓存。
- GPU读取索引
-
处理三角形2(0, 2, 1):
- GPU读取索引
0, 2, 1。 - 检查顶点变换缓存:
- 索引
0(v0):已在缓存中,直接复用变换结果。 - 索引
2(v2):已在缓存中,直接复用。 - 索引
1(v1):已在缓存中,直接复用。
- 索引
- 图元装配阶段从缓存中取出
v0, v2, v1,组装三角形2,无需重新计算任何顶点。 - 结果:三角形2的处理几乎没有额外计算开销!
- GPU读取索引
-
输出:
- 两个三角形被高效绘制,GPU只执行3次顶点变换(
v0, v1, v2),而不是6次。
- 两个三角形被高效绘制,GPU只执行3次顶点变换(
效率提升在哪里?
-
减少数据传输:
- 不优化:192字节(6个顶点)。
- 优化后:108字节(3个顶点+6个索引),节省了约44%的带宽。
-
减少计算:
- 不优化:GPU对
v0, v1, v2各计算两次(共6次顶点着色器调用)。 - 优化后:每个顶点只计算一次(共3次),节省50%的计算量。
- 不优化:GPU对
-
缓存命中:
- 顶点变换缓存确保
v0, v1, v2的变换结果被复用。 - 图元装配缓存减少了组装三角形时的内存访问。
- 顶点变换缓存确保
-
内存局部性:
- 顶点缓冲区(
v0, v1, v2)是连续存储的,GPU一次加载即可。 - 索引缓冲区(
0, 1, 2, 0, 2, 1)也是连续的,访问效率高。
- 顶点缓冲区(
连接到4x4网格
在之前的4x4网格例子中,我们使用了三角形条带 (如0, 5, 1, 6, 2, ...),这也利用了类似的缓存机制:
- 顶点复用 :顶点
6在多个三角形中重复出现(如5-1-6,1-6-2),通过索引或条带顺序,GPU只变换一次6,然后复用缓存结果。 - 图元装配 :条带中连续的顶点(如
1, 6, 2到6, 2, 7)共享6, 2,图元装配缓存直接复用这两个顶点,只需加载新顶点7。 - 局部性 :之字形顺序(
0, 5, 1, 6, ...)确保顶点索引在内存中连续,GPU的缓存命中率高。
如果4x4网格不用索引,而是直接发送每个三角形的3个顶点:
- 32个三角形×3顶点×32字节=3072字节。
- GPU需要变换32×3=96次顶点。
使用索引和条带: - 顶点数据:25顶点×32字节=800字节。
- 索引数据:约40索引×2字节=80字节。
- 总共880字节,变换约25次顶点,效率大幅提升。
更形象的比喻
想象GPU是一个"厨师",顶点是"食材",顶点着色器是"烹饪":
- 不优化 :每次做菜(三角形),都重新拿相同的食材(
v0, v1, v2),重新烹饪,浪费时间和材料。 - 优化 :先把食材(
v0, v1, v2)准备好,烹饪一次后放进"冰箱"(顶点变换缓存)。下次做菜时,用"菜单"(索引0, 1, 2)直接从冰箱拿成品,省时省力。 - 图元装配缓存就像厨师的"工作台",记住最近用的两块食材(
v1, v2),新菜只需加一块新食材(v3),组装更快。
代码示例(OpenGL伪代码)
cpp
struct Vertex {
float position[3];
float normal[3];
float uv[2];
};
// 顶点缓冲区
Vertex vertices[] = {
{ {0, 0, 0}, {0, 0, 1}, {0, 0} }, // v0
{ {0, 1, 0}, {0, 0, 1}, {0, 1} }, // v1
{ {1, 1, 0}, {0, 0, 1}, {1, 1} }, // v2
};
// 索引缓冲区
uint16_t indices[] = { 0, 1, 2, 0, 2, 1 };
// 上传到GPU
glBindBuffer(GL_ARRAY_BUFFER, vertexBuffer);
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, indexBuffer);
glBufferData(GL_ELEMENT_ARRAY_BUFFER, sizeof(indices), indices, GL_STATIC_DRAW);
// 绘制
glDrawElements(GL_TRIANGLES, 6, GL_UNSIGNED_SHORT, 0);总结
通过这个简单例子,我们看到:
- 索引缓冲区 让相同的顶点(如
v0)只传输和计算一次,节省带宽和计算。 - 顶点变换缓存存储变换后的顶点结果,GPU直接复用,避免重复着色。
- 图元装配缓存记住最近的顶点,加速三角形组装。
- 在4x4网格中,类似的优化(条带+索引)让32个三角形只需约25次顶点变换,而非96次。
如果你还想更深入某个部分(例如缓存大小、条带与索引的对比),或需要更复杂的例子(例如4x4网格的具体缓存命中分析),请告诉我!
观众提问:我现在才明白我的问题是,当你不断添加顶点时,它是如何"知道"该用哪个顶点构建三角形的?例如,你在网格中心添加一个点,它为什么不会连接到左上角的点?
在图形渲染过程中,如何确定哪些三角形需要绘制是一个非常重要的问题。这个问题涉及到 图元组装(Primitive Assembly)这一概念。图元指的是渲染的基本单元,比如三角形、四边形、点等,而图元组装则是如何将顶点数据拼接成这些基本单元的过程。
图元组装(Primitive Assembly)
-
图元类型的选择 :
在渲染之前,我们需要告诉图形系统我们想要绘制的图元类型。例如,如果我们想绘制三角形,我们就需要指定渲染的图元是三角形。类似地,也可以指定其他类型的图元,如四边形或点等。
-
如何选择三角形进行绘制 :
在图元组装过程中,图形系统会根据指定的图元类型(比如三角形)来决定如何组合和组织顶点数据。具体而言,如果是三角形,就会将顶点按照三角形的方式进行组合,并生成相应的三角形进行渲染。这个过程会涉及到如何从顶点数据中提取出有效的三角形数据,并将其交给后续的渲染管线。
-
图元组装的工作方式 :
在图元组装阶段,GPU会根据输入的顶点数据,将这些顶点组织成一个个基本的图元(如三角形)。这些图元随后会进入光栅化阶段,最终被渲染到屏幕上。
-
与"Handmade Hero"中的实现相关 :
在一些图形应用中,本游戏可能会指定不同类型的图元进行渲染。本游戏选择了三角形作为图元类型,并且在实现过程中设置了图元类型为"几何三角形"(geo triangles)。这意味着渲染管线会将输入的顶点数据按三角形的方式进行处理和渲染。
总结来说,图元组装的过程就是将一系列顶点数据按照一定规则组织起来,形成一个个基本的渲染单元(如三角形、四边形等),并为后续的光栅化和渲染做好准备。这个过程的关键在于如何将顶点数据正确地组合为符合图元类型要求的几何形状。
黑板:图元装配中三种基本方式:三角形(Triangles)、三角带(Tristrips)、三角扇(Trifans)。
图元组装(Primitive Assembly)是指在渲染管线中如何根据顶点流来确定绘制的图元类型(如三角形、四边形等)。不同类型的图元会根据特定规则来解释输入的顶点数据,从而确定输出的图元形式。
图元类型与规则
-
三角形(Triangles)
对于三角形图元类型,规则非常简单:每三个连续的顶点将被用来组成一个三角形。因此,如果我们发送一系列顶点数据,系统会每三个顶点构成一个三角形进行渲染。
例如,假设我们发送以下顶点流:
- 顶点 0,顶点 1,顶点 2
- 顶点 3,顶点 4,顶点 5
这会被解释为两个三角形: - 第一个三角形由顶点 0、1、2 构成
- 第二个三角形由顶点 3、4、5 构成
-
三角带(Triangle Strip)
三角带是一种优化绘制方式,其中每添加一个新顶点,都能利用之前的两个顶点来组成一个新的三角形。换句话说,第一个三角形使用顶点 0、1、2,第二个三角形使用顶点 1、2、3,以此类推。这样可以减少需要发送的顶点数量,因为每个新三角形只需要一个新顶点即可。
-
三角扇(Triangle Fan)
三角扇则是另一种形式的图元,在这种情况下,第一个顶点是中心顶点,后续的顶点将与中心顶点一起形成多个三角形。比如,第一个三角形由中心顶点与前两个顶点组成,第二个三角形由中心顶点与下两个顶点组成,以此类推。
图元组装的作用
图元组装的目的是将输入的顶点数据转换成适合光栅化阶段处理的基本图元形式(如三角形)。具体来说:
- 对于 三角形 类型的图元,每三个顶点构成一个三角形。
- 对于 三角带 和 三角扇,则利用已知的顶点模式来减少顶点数据的传输量,从而提高渲染效率。
总结来说,图元组装是决定如何将顶点数据组合成几何图元的过程。不同的图元类型(如三角形、三角带、三角扇)提供了不同的顶点组合方式,用来优化渲染效率。
黑板:三角形绘制方式。
假设我们发送以下顶点数据:
1, 2, 3, 4, 5, 6
如果将图元组装方式设置为 三角形(Triangles),那么系统会按每三个顶点一组来绘制三角形。具体来说,顶点会按照以下方式组合成三角形:
- 第一组三个顶点(1, 2, 3)会形成第一个三角形。
- 第二组三个顶点(4, 5, 6)会形成第二个三角形。
输出的结果将是两个三角形,分别由以下顶点构成:
- 第一个三角形由顶点 1, 2, 3 构成
- 第二个三角形由顶点 4, 5, 6 构成
这里没有复杂的推理或魔法,系统只是按照我们指定的规则(设置为三角形)来处理顶点数据。每次它会取三个顶点,组合成一个三角形,这个过程完全依赖于我们设置的图元类型。
黑板:三角带绘制方式。
**三角带(Triangle Strip)**的工作方式与三角形有所不同,它通过不断滑动"窗口"来复用之前的顶点。具体过程如下:
- 初始化:首先选择前两个顶点(例如顶点 1 和顶点 2)。
- 生成第一个三角形:然后加入第三个顶点(例如顶点 3),这三个顶点就形成了第一个三角形。就像传统的三角形一样,系统将它们连接成一个三角形。
- 滑动窗口:接下来,每添加一个新顶点,系统会滑动窗口,丢弃最早的一个顶点,只保留新的两个顶点以及最新加入的一个顶点。通过这种方式,顶点的组合不断变化,但每次都只使用三个顶点来绘制三角形。
举例来说:
- 首先,使用顶点 1, 2, 3 绘制一个三角形。
- 接着,滑动窗口,使用顶点 2, 3, 4 绘制下一个三角形。
- 然后,再滑动窗口,使用顶点 3, 4, 5 绘制下一个三角形。
- 依此类推,系统会持续地将窗口向前滑动,每次使用新的顶点来形成新的三角形。
三角带的特点在于,每次绘制三角形时,都会复用前两个顶点,这样做的好处是减少了顶点的冗余,并且可以提高图形绘制的效率。系统不需要每次都使用全新的顶点,而是通过滑动窗口复用顶点数据,形成连续的三角形。
黑板:三角扇绘制方式。
**三角扇(Triangle Fan)**与三角带有些相似,但其工作方式稍有不同。它的原理如下:
- 固定一个顶点:三角扇以第一个顶点作为中心点,这个顶点在整个过程中始终保持不变。
- 使用滑动窗口:然后,使用滑动窗口的方式,窗口只包含另外两个顶点,每次滑动时只向后移动一个顶点。这样,每次新的三角形都会使用固定的第一个顶点,并与滑动窗口中的两个顶点一起绘制。
举个例子,假设我们有一组顶点:
- 第一次绘制时,使用顶点 1、2、3 来绘制三角形。
- 接着,使用顶点 1、3、4 绘制下一个三角形。
- 然后,使用顶点 1、4、5 来绘制新的三角形。
- 每次都使用第一个顶点 1,与滑动窗口中的两个顶点组合成新的三角形。
通过这种方式,可以在顶点列表的每个位置生成多个三角形,所有的三角形都会从相同的中心点(顶点 1)开始。这种方法非常适合用于绘制类似圆形的形状,因为可以通过不断绘制不同的三角形,围绕中心点逐渐形成一个完整的形状。
例如,如果要绘制一个圆形,可以通过传递一组顶点数据:1, 2, 3, 4, 5, 6, 7, 8, 9等,然后系统会依次生成三角形:1-2-3,1-3-4,1-4-5,依此类推。
这种方式的特点是固定一个顶点,而其他顶点会通过滑动窗口不断变化。这种结构类似扇形,因此得名"三角扇"。
然而,三角扇并不常用,它的使用频率低于三角带(Triangle Strip),但它在某些特定情况下,比如绘制圆形或其他围绕中心点辐射的形状时非常有效。
以下是对图元装配中三种基本方式(三角形 、三角带 、三角扇 )的总结,并针对顶点数据 1, 2, 3, 4, 5, 6 提供具体的绘制示例。同时,我会用简单的字符图(ASCII艺术)来直观表示每种方式的顶点连接方式,并给出实际应用的例子。回答将保持简洁、清晰,并满足你的要求。
1. 三角形(Triangles)
规则 :每三个连续顶点组成一个独立三角形,无顶点复用。
输入顶点 :1, 2, 3, 4, 5, 6
绘制结果:
- 三角形 1:顶点
1, 2, 3 - 三角形 2:顶点
4, 5, 6
输出:2 个独立三角形。
字符图(表示两个独立的三角形):
1 4
/ \ / \
2---3 5---6应用示例 :绘制不连续的几何体,如多个独立的平面或物体(如两个不相关的三角形面)。
特点:简单但顶点冗余,适合非连续几何。
2. 三角带(Triangle Strip)
规则 :第一个三角形用顶点 1, 2, 3,之后每新增一个顶点,与前两个顶点组成新三角形,滑动窗口复用顶点。
输入顶点 :1, 2, 3, 4, 5, 6
绘制结果:
- 三角形 1:顶点
1, 2, 3 - 三角形 2:顶点
2, 3, 4 - 三角形 3:顶点
3, 4, 5 - 三角形 4:顶点
4, 5, 6
输出:4 个三角形。
字符图 (表示连续的三角带,顶点顺序为 1->2->3->4->5->6):
1
/ \
2---3
/ \
4---5
/ \
6说明:每个新顶点与前两个顶点形成三角形,构成连续的带状结构。
应用示例 :绘制连续表面,如地形网格、3D模型的曲面(如布料、管道)。
特点 :顶点复用减少数据量,效率高,适合连续网格。
注意:需确保顶点顺序一致以避免绕序问题(顺时针/逆时针)。
3. 三角扇(Triangle Fan)
规则 :第一个顶点 1 固定为中心点,每新增一个顶点,与中心点和前一个顶点组成新三角形。
输入顶点 :1, 2, 3, 4, 5, 6
绘制结果:
- 三角形 1:顶点
1, 2, 3 - 三角形 2:顶点
1, 3, 4 - 三角形 3:顶点
1, 4, 5 - 三角形 4:顶点
1, 5, 6
输出:4 个三角形。
字符图 (表示三角扇,顶点 1 为中心,连接 2, 3, 4, 5, 6):
2
/ \
/ \
3 1
|\ /|
| \ / |
4--5--6说明 :顶点 1 为中心,连接到 2, 3, 4, 5, 6,形成扇形三角形序列。
应用示例:绘制围绕中心的形状,如圆形、多边形(如五边形)、扇形图案或锥体顶端。
- 具体例子 :绘制一个近似圆形,顶点
1为圆心,2, 3, 4, 5, 6为圆周上的点,依次形成三角形1-2-3,1-3-4,1-4-5,1-5-6,逼近圆形的一部分。
特点:适合辐射状几何,顶点复用效率高,但应用场景较窄。
总结与对比
- 效率 :
- 三角形:顶点数 = 3 × 三角形数,冗余最多。
- 三角带:顶点数 = 三角形数 + 2,适合连续表面。
- 三角扇:顶点数 = 三角形数 + 2,适合辐射状几何。
- 应用场景 :
- 三角形:非连续几何,如独立的多边形。
- 三角带:连续网格,如3D模型曲面。
- 三角扇:中心辐射形状,如圆形或扇形。
- 注意事项:在渲染管线(如OpenGL/DirectX)中,需确保顶点顺序一致(通常逆时针为正面)以避免背面剔除问题。
提问:你提到启动变慢了,因为 OpenGL 的原因。有办法加快启动吗?难道不应该先加载贴图再展示画面吗?
关于优化纹理加载和OpenGL上下文创建的讨论:
-
纹理加载不是瓶颈:虽然纹理需要加载,但是纹理加载是按需进行的,并不是导致性能慢的主要原因。
-
问题出在OpenGL上下文的创建:实际的性能瓶颈是创建OpenGL上下文的过程,这个初始化步骤非常缓慢。系统当前创建了多个上下文,其中有两个用于纹理下载,另外一个是常规的上下文。
-
减少上下文的数量以提高速度:目前的多上下文方式并没有带来显著的性能提升,反而可能会造成不必要的开销。因此,决定减少为两个纹理下载用的上下文,只保留一个上下文来进行所有操作。这一改动预计能够使系统速度提高大约三倍。
-
OpenGL上下文的创建时间过长:虽然在进行这些调整后,性能应该得到大幅提升,但由于OpenGL上下文的创建本身就需要很长时间,性能提升可能仍然不会立刻达到理想状态。这种情况在不同显卡的驱动程序中表现不同,NVIDIA的驱动程序启动较快,而某些其他厂商的驱动程序启动则非常缓慢。
提问:在 3D 建模中(例如 Blender),使用非四边形的拓扑结构会导致渲染伪影,这是因为游戏中渲染时都会被分解成三角形吗?
关于使用四边形拓扑与渲染问题的讨论:
-
渲染与拓扑的关系:问题的核心不在于渲染本身,而是在于拓扑(即网格的几何结构)。即使最终渲染时所有网格都被拆分为三角形,渲染卡能够处理任何三角形形式的网格,但四边形拓扑的重要性不在于渲染,而是在于几何建模和后续处理。
-
拓扑与数学上的问题:当网格使用四边形时,它能够更好地适应平滑曲线(如细分曲面)和纹理映射等操作。没有四边形时,网格可能会产生不可避免的数学奇点和渲染伪影,这些是无法避免的数学问题。这些问题可能会影响细分曲面或纹理映射的效果,导致不平整或不准确的结果。
-
局部平坦性和不塌缩性:在高级建模和渲染操作中,要求网格局部平坦且不发生塌缩。如果网格的拓扑不满足这一要求,可能会影响后续的渲染效果和其他操作。
-
渲染卡的处理方式:尽管渲染卡能够将任何网格拆分成三角形并渲染出来,但当涉及到更复杂的几何操作时,四边形的拓扑提供了更好的结构,能够避免很多数学上的问题。因此,四边形拓扑对于细节的处理和渲染质量至关重要。
-
与当前项目的关系:虽然这些问题在高级建模和纹理映射中非常重要,但对于当前的项目而言,这些细节并不完全相关,因此无需过于深入探讨。
提问:OpenGL 创建上下文时,哪个环节最慢?是 SetPixelFormat 吗?VS2013 里很慢,在 VS2015 里就没这么慢。
关于OpenGL上下文创建和Visual Studio的性能问题:
-
问题的根源:在OpenGL上下文的创建过程中,性能问题主要出现在内存分配和上下文初始化上。特别是在使用Visual Studio 2013时,内存分配和上下文创建的过程可能非常缓慢,导致程序启动变慢。
-
内存分配的跟踪:Visual Studio在内存分配过程中会进行内存跟踪,这会影响程序的性能。在程序的初始化阶段,Visual Studio会跟踪内存的分配和管理,而这可能导致上下文创建过程变慢。
-
未禁用的堆管理:在此情况下,程序并没有禁用Visual Studio的内存堆跟踪功能。由于没有关闭这一功能,内存分配的管理可能对程序性能产生了不必要的影响,导致OpenGL上下文的创建变得更加缓慢。
-
可能的优化:如果禁用了堆管理功能,可能会减少上下文创建过程中不必要的性能损耗,从而加速初始化过程。禁用该功能后,可以测试程序是否会变得更快,特别是在上下文创建和内存分配方面。
-
性能瓶颈的定位:在测试过程中,可以看到,性能瓶颈主要出现在OpenGL上下文创建时,具体来说是在上下文初始化(尤其是设置像素格式时)过程中。因此,可能需要优化这些部分,以提高程序的启动速度。
解释 Debug Heap 的作用。
调试器性能优化过程:
-
Visual Studio的调试功能影响性能 :在使用Visual Studio进行调试时,启用了调试时的内存跟踪功能,这会显著影响程序的性能。具体来说,C++代码往往会频繁调用内存分配(如
malloc),这在调试模式下可能导致程序运行变得非常缓慢。 -
关闭调试功能:尝试关闭Visual Studio中与调试相关的内存跟踪功能,旨在提升运行速度。尽管做了这个优化,程序的运行速度仍然没有明显改善,仍然相对较慢。
-
额外调试上下文的创建影响:开发者认为,导致程序运行速度较慢的原因之一是创建了过多的调试上下文(debug contexts)。这些上下文并没有实际提供性能上的帮助,反而拖慢了速度。开发者计划尝试移除这些不必要的上下文,以进一步提升性能。
-
优化目标:虽然通过调整调试功能有所改进,但目前的速度仍未达到预期。开发者希望能够回到之前的性能水平,在调整上下文创建后,能够恢复到更高效的状态。
总的来说,性能问题的根源在于调试功能带来的开销,尤其是频繁的内存分配和不必要的调试上下文。通过去除这些不必要的操作,有望进一步提高程序的启动速度和运行效率。