目录
[1 Hive事务概述](#1 Hive事务概述)
[2 ACID特性详解](#2 ACID特性详解)
[3 Hive事务表的配置与启用](#3 Hive事务表的配置与启用)
[3.1 启用Hive事务支持](#3.1 启用Hive事务支持)
[3.2 创建事务表](#3.2 创建事务表)
[4 Hive事务操作流程](#4 Hive事务操作流程)
[5 并发控制与隔离级别](#5 并发控制与隔离级别)
[5.1 Hive的锁机制](#5.1 Hive的锁机制)
[5.2 隔离级别](#5.2 隔离级别)
[6 Hive事务的限制与优化](#6 Hive事务的限制与优化)
[6.1 主要限制](#6.1 主要限制)
[6.2 性能优化建议](#6.2 性能优化建议)
[7 事务表操作示例](#7 事务表操作示例)
[7.1 基本事务操作](#7.1 基本事务操作)
[7.2 合并(MERGE)操作示例](#7.2 合并(MERGE)操作示例)
[8 事务监控与管理](#8 事务监控与管理)
[8.1 查看当前事务](#8.1 查看当前事务)
[8.2 查看锁信息](#8.2 查看锁信息)
[8.3 压缩管理](#8.3 压缩管理)
[9 总结](#9 总结)
1 Hive事务概述
Hive作为传统的数据仓库工具,最初设计主要用于批处理ETL操作,并不支持事务处理。但随着业务需求的发展,Hive从0.13版本开始引入了有限的事务支持,并在后续版本中不断完善。
事务在数据库系统中是指一组不可分割的操作序列,这些操作要么全部执行成功,要么全部不执行。Hive事务的实现使得Hive能够支持更新(UPDATE)、删除(DELETE)和合并(MERGE)等操作,同时保证数据的ACID特性。
2 ACID特性详解
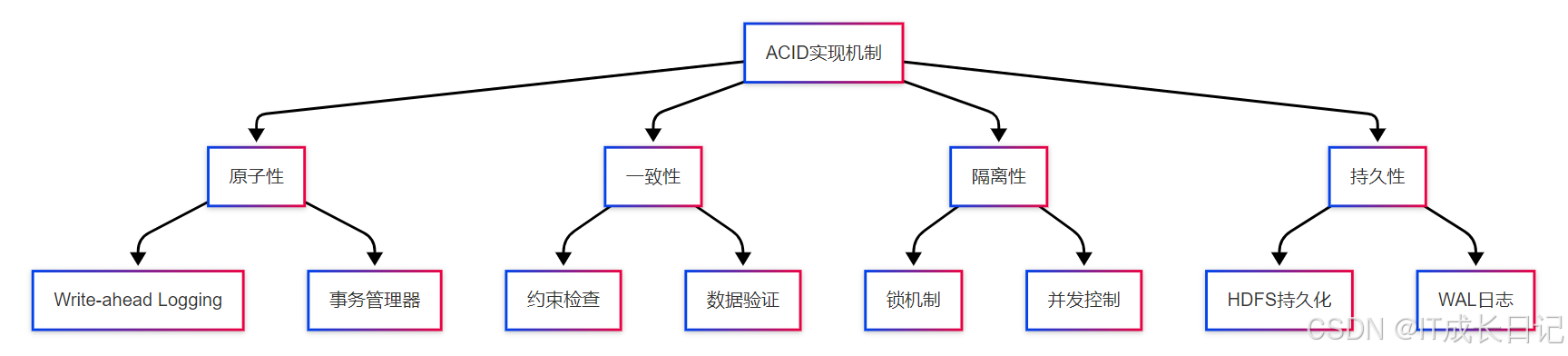
ACID是数据库事务正确执行的四个基本要素的缩写:
- 原子性(Atomicity):事务是一个不可分割的工作单位,事务中的操作要么全部完成,要么全部不完成
- 一致性(Consistency):事务执行前后,数据库从一个一致性状态变到另一个一致性状态
- 隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行
- 持久性(Durability):一旦事务提交,其所做的修改会永久保存在数据库中
3 Hive事务表的配置与启用
3.1 启用Hive事务支持
要使用Hive的事务功能,需要在hive-site.xml中配置以下参数:
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
<property>
<name>hive.enforce.bucketing</name>
<value>true</value>
</property>
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
<property>
<name>hive.compactor.initiator.on</name>
<value>true</value>
</property>
<property>
<name>hive.compactor.worker.threads</name>
<value>1</value>
</property>3.2 创建事务表
Hive中的事务表必须是分桶表(Bucketed Table),并且存储格式为ORC。
-
创建语法:
CREATE TABLE transactional_table (
id int,
name string,
dept string
)
CLUSTERED BY (id) INTO 4 BUCKETS
STORED AS ORC
TBLPROPERTIES ('transactional'='true');
4 Hive事务操作流程
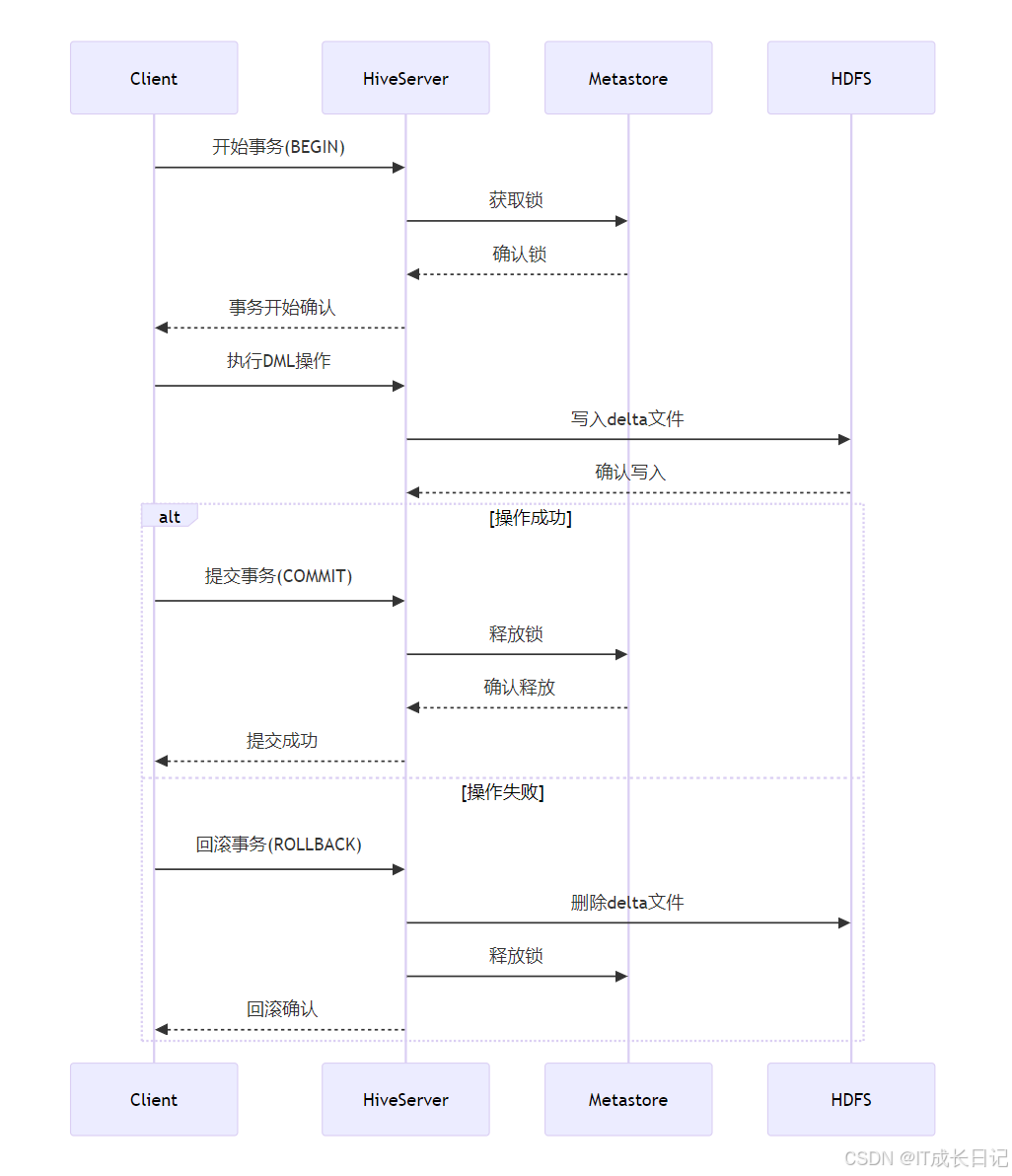
- 事务开始:客户端发送BEGIN命令,HiveServer向Metastore申请锁
- 执行操作:所有DML操作会生成delta文件而非直接修改原文件
- 事务提交:提交时合并delta文件到基文件,释放锁
- 事务回滚:回滚时删除delta文件,释放锁
5 并发控制与隔离级别
5.1 Hive的锁机制
|---------------|--------------------|
| 锁类型 | 描述 |
| 共享锁(S) | 多个事务可以同时持有,用于读操作 |
| 排他锁(X) | 只有一个事务可以持有,用于写操作 |
| 意向共享锁(IS) | 表示事务意图在表的某些行上设置共享锁 |
| 意向排他锁(IX) | 表示事务意图在表的某些行上设置排他锁 |

5.2 隔离级别
Hive支持以下隔离级别:
- 读未提交(Read Uncommitted):最低级别,可能读取到未提交的数据
- 读已提交(Read Committed):只能读取已提交的数据
- 可重复读(Repeatable Read):同一事务中多次读取结果一致
- 串行化(Serializable):最高级别,完全隔离
Hive默认使用读已提交隔离级别,可以通过以下设置调整:
SET hive.txn.isolation=serializable;6 Hive事务的限制与优化
6.1 主要限制
- 只支持ORC文件格式的事务表
- 表必须是分桶表
- 不支持BEGIN、COMMIT、ROLLBACK语句的嵌套
- 不支持Savepoint功能
- 压缩(Compaction)操作可能影响性能
6.2 性能优化建议
- 合理设置桶数:根据数据量和集群规模设置适当的分桶数
- 控制事务大小:避免在单个事务中进行大量数据修改
- 调整压缩参数:根据负载情况调整压缩线程数和触发条件
- 监控锁等待:及时发现和解决锁争用问题
7 事务表操作示例
7.1 基本事务操作
-- 开始事务
BEGIN;
-- 插入数据
INSERT INTO transactional_table VALUES (1, 'Alice', 'HR');
-- 更新数据
UPDATE transactional_table SET dept = 'Finance' WHERE id = 1;
-- 删除数据
DELETE FROM transactional_table WHERE id = 1;
-- 提交事务
COMMIT;
-- 如果出现错误可以回滚
-- ROLLBACK;7.2 合并(MERGE)操作示例
MERGE INTO transactional_table AS target
USING source_table AS source
ON target.id = source.id
WHEN MATCHED AND target.dept != 'HR' THEN
UPDATE SET dept = source.dept
WHEN MATCHED THEN
DELETE
WHEN NOT MATCHED THEN
INSERT VALUES (source.id, source.name, source.dept);8 事务监控与管理
8.1 查看当前事务
SHOW TRANSACTIONS;8.2 查看锁信息
SHOW LOCKS;
SHOW LOCKS transactional_table EXTENDED;8.3 压缩管理
-- 手动触发压缩
ALTER TABLE transactional_table COMPACT 'minor';
ALTER TABLE transactional_table COMPACT 'major';
-- 查看压缩历史
SHOW COMPACTIONS;9 总结
Hive的事务支持为数据仓库提供了更强大的数据处理能力,使得Hive能够应对更多实时性要求较高的场景。虽然相比传统关系型数据库,Hive的事务功能还存在一些限制,但对于大数据环境下的数据仓库需求已经提供了很好的解决方案。
合理使用Hive事务特性,可以在保证数据一致性的同时,实现数据的灵活更新和管理。在实际应用中,需要根据业务需求和数据规模,权衡事务的使用范围和性能影响,以达到最佳的使用效果。