引言
在大数据时代,如何高效处理海量数据成为技术核心挑战之一。Hadoop生态中的MapReduce框架应运而生,以其"分而治之"的思想解决了大规模数据的并行计算问题。本文将从原理、核心组件到实战案例,带你全面理解这一经典计算模型。
一、MapReduce概述
MapReduce是一种分布式计算框架,核心思想是将任务拆分为两个阶段:
-
Map阶段:将输入数据分割成独立块,并行处理生成中间键值对。
-
Reduce阶段:对中间结果聚合,生成最终输出。
其优势在于:
-
横向扩展性:通过增加节点轻松应对数据量增长。
-
容错机制:自动重试失败任务,保障任务可靠性。
-
数据本地化:优先在存储数据的节点执行计算,减少网络传输。
二、MapReduce工作原理
1. 数据流与核心流程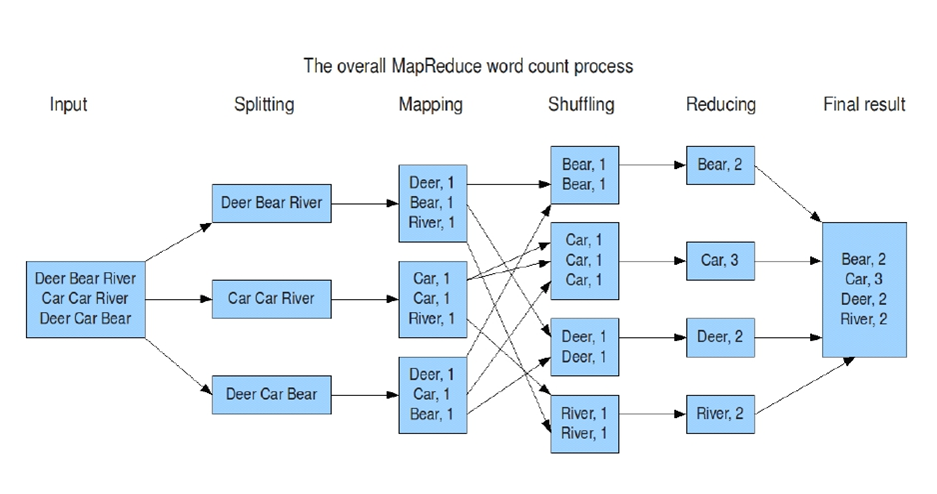
-
Input Split:输入数据被划分为多个分片(Split),每个分片启动一个Map任务。
-
Map阶段 :处理分片数据,输出**
<key, value>**对。 -
Shuffle & Sort:将相同Key的数据分发到同一Reducer,并按Key排序。
-
Reduce阶段:聚合中间结果,输出最终结果。
2. 关键角色
1.Mapper:处理原始数据,生成中间结果。
Mapper类是一个泛型类,包含四个泛型参数,定义了输入输出的键值类型:
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
// 核心方法
} | 参数 | 描述 | 示例(WordCount) |
|---|---|---|
KEYIN |
Map任务的输入键类型 | LongWritable(文件偏移量) |
VALUEIN |
Map任务的输入值类型 | Text(一行文本) |
KEYOUT |
Map任务的输出键类型(Reducer输入键) | Text(单词) |
VALUEOUT |
Map任务的输出值类型(Reducer输入值) | IntWritable(出现次数1) |
2.Reducer:聚合中间结果,输出最终结果。
public class Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
// 核心方法
} | 参数 | 描述 | 示例(WordCount) |
|---|---|---|
KEYIN |
Reducer 的输入键类型(Mapper 输出键) | Text(单词) |
VALUEIN |
Reducer 的输入值类型(Mapper 输出值) | IntWritable(出现次数1) |
KEYOUT |
Reducer 的输出键类型 | Text(单词) |
VALUEOUT |
Reducer 的输出值类型 | IntWritable(总次数) |
Reducer 的输入并非直接来自 Mapper,而是经过以下处理:
-
Shuffle:框架将 Mapper 输出的中间数据按 Key 分组,并跨节点传输到对应的 Reducer。
-
Sort:数据按 Key 排序(默认升序),确保相同 Key 的值连续排列。
-
Group :将同一 Key 的所有 Value 合并为
Iterable<VALUEIN>供reduce()处理。
3.Combiner(可选):在Map端本地聚合,减少数据传输量。
4. Partitioner:控制中间结果的分区策略,决定数据流向哪个Reducer。
1. 自定义 Partitioner
public class GenderPartitioner extends Partitioner<Text, IntWritable> {
@Override
public int getPartition(Text key, IntWritable value, int numPartitions) {
// 按性别分区,男→0,女→1
return key.toString().equals("男") ? 0 : 1;
}
} 2. 配置作业
job.setPartitionerClass(GenderPartitioner.class);
job.setNumReduceTasks(2); // 需与分区数匹配 三、核心组件详解
1. Mapper的生命周期
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
protected void setup(Context context) { /* 初始化操作 */ }
protected void map(KEYIN key, VALUEIN value, Context context) { /* 核心逻辑 */ }
protected void cleanup(Context context) { /* 收尾操作 */ }
} -
setup() :在Map任务启动时执行一次,用于初始化资源(如连接数据库、加载配置文件)。调用时机 :在所有
map()方法调用之前。protected void setup(Context context) { // 初始化计数器或全局变量 Configuration conf = context.getConfiguration(); String param = conf.get("custom.param"); } -
map() :处理每条输入记录,生成中间键值对。每条数据调用一次。
protected void map(KEYIN key, VALUEIN value, Context context) { // 示例:WordCount的切分单词逻辑 String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); context.write(word, one); // 输出<单词, 1> } } -
cleanup() :在Map任务结束时执行一次,用于释放资源(如关闭文件句柄、清理缓存)。调用时机 :在所有
map()方法调用之后。protected void cleanup(Context context) { // 关闭数据库连接或写入日志 }
Mappper的生命周期牵涉到三个方法: setup() 、 map() 、cleanup(),生命周期的方法的执行顺序是:先运行 setup() ,然后运行 map() ,最后运行cleanup()。
2. Reducer的输入输出
Reducer接收Mapper输出的<key, list<value>>,通过迭代计算生成最终结果。
public class Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
protected void reduce(KEYIN key, Iterable<VALUEIN> values, Context context) {
// 例如:计算单词总频次
int sum = 0;
for (VALUEIN value : values) sum += value.get();
context.write(key, new IntWritable(sum));
}
} 3. Combiner优化
Combiner本质是"本地Reducer",在Map端预聚合数据。
job.setCombinerClass(IntSumReducer.class); // 直接复用Reducer逻辑 注意事项:
-
Combiner 的输入输出类型必须与 Mapper 的输出类型一致。
-
仅适用于可结合(Associative)和可交换(Commutative)的操作(如求和、最大值)。
适用场景:求和、最大值等可交换与结合的操作。
4. Partitioner自定义分发
默认分区策略是哈希取模,但可通过实现Partitioner接口自定义:
1. 自定义 Partitioner
public class GenderPartitioner extends Partitioner<Text, IntWritable> {
@Override
public int getPartition(Text key, IntWritable value, int numPartitions) {
// 按性别分区,男→0,女→1
return key.toString().equals("男") ? 0 : 1;
}
} 2. 配置作业
job.setPartitionerClass(GenderPartitioner.class);
job.setNumReduceTasks(2); // 需与分区数匹配 5.Job 类:作业控制中心
Job 类是 MapReduce 作业的入口,负责定义作业配置、设置任务链并提交到集群执行。
1. 核心方法
// 创建作业实例
Job job = Job.getInstance(Configuration conf, String jobName);
// 设置作业的主类(包含main方法)
job.setJarByClass(Class<?> cls);
// 配置Mapper和Reducer
job.setMapperClass(Class<? extends Mapper> cls);
job.setReducerClass(Class<? extends Reducer> cls);
// 设置输入输出路径
FileInputFormat.addInputPath(Job job, Path path);
FileOutputFormat.setOutputPath(Job job, Path path);
// 指定键值类型
job.setMapOutputKeyClass(Class<?> cls);
job.setMapOutputValueClass(Class<?> cls);
job.setOutputKeyClass(Class<?> cls);
job.setOutputValueClass(Class<?> cls);
// 设置Combiner和Partitioner
job.setCombinerClass(Class<? extends Reducer> cls);
job.setPartitionerClass(Class<? extends Partitioner> cls);
// 提交作业并等待完成
boolean success = job.waitForCompletion(boolean verbose); 2. 示例:WordCount 作业配置
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "WordCount");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
} 6.InputFormat 与 OutputFormat
1. InputFormat
定义如何读取输入数据(如文件分片、记录解析)。常用实现类:
-
TextInputFormat:默认格式,按行读取文本文件,键为偏移量,值为行内容。
-
KeyValueTextInputFormat:按分隔符(如Tab)解析键值对。
-
SequenceFileInputFormat:读取Hadoop序列化文件。
自定义示例:
// 设置输入格式为KeyValueTextInputFormat
job.setInputFormatClass(KeyValueTextInputFormat.class); 2. OutputFormat
定义如何写入输出数据。常用实现类:
-
TextOutputFormat :将键值对写入文本文件,格式为
key \t value。 -
SequenceFileOutputFormat:输出为Hadoop序列化文件。
自定义示例:
// 设置输出格式为SequenceFileOutputFormat
job.setOutputFormatClass(SequenceFileOutputFormat.class); 7.Counter:任务级统计
通过 Counter 可收集作业运行时的统计信息(如无效记录数)。
// 在Mapper或Reducer中定义计数器
public class WordCountMapper extends Mapper<...> {
enum Counter { INVALID_RECORDS }
protected void map(...) {
if (line == null) {
context.getCounter(Counter.INVALID_RECORDS).increment(1);
return;
}
// 正常处理
}
} 8.Context 对象:任务上下文
Context 对象贯穿 Mapper 和 Reducer 的生命周期,提供以下功能:
-
数据写入 :
context.write(key, value) -
配置访问 :
Configuration conf = context.getConfiguration() -
进度报告 :
context.progress()(防止任务超时)
四、数据类型与序列化
MapReduce要求键值类型实现**Writable或WritableComparable**接口,确保跨节点序列化。
public interface WritableComparable<T> extends Writable, Comparable<T> {}1. 常用内置类型
| 序号 | Writable类 | 对应的Java类/类型 | 描述 |
|---|---|---|---|
| 1 | BooleanWritable | Boolean | 布尔值变量的封装 |
| 2 | ByteWritable | Byte | Byte的封装 |
| 3 | ShortWritable | Short | Short的封装 |
| 4 | IntWritable | Integer | 整数的封装 |
| 5 | LongWritable | Long | 长整型的封装 |
| 6 | FloatWritable | Float | 单精度浮点数的封装 |
| 7 | DoubleWritable | Double | 双精度浮点数的封装 |
| 8 | Text | String | UTF-8格式字符串的封装 |
| 9 | NullWritable | Null | 无键值的占位符(空类型) |
2. 自定义数据类型
1.设计自定义类型的类。
2. 这个类实现要实现 WritableComparable 接口。
3. 分别实现接口里面的 readFields() 、 read() 方法。
以学生信息为例,需实现WritableComparable接口:
public class Student implements WritableComparable<Student> {
private int id;
private String name;
// 实现序列化与反序列化
public void write(DataOutput out) { /* 序列化字段 */ }
public void readFields(DataInput in) { /* 反序列化字段 */ }
// 定义排序规则
public int compareTo(Student o) { /* 按ID或性别排序 */ }
} 五、实战案例:WordCount
1. Mapper实现
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
protected void map(LongWritable key, Text value, Context context) {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
} 2. Reducer实现
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
protected void reduce(Text key, Iterable<IntWritable> values, Context context) {
int sum = 0;
for (IntWritable val : values) sum += val.get();
result.set(sum);
context.write(key, result);
}
} 3. 提交作业
Job job = Job.getInstance(conf, "WordCount");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1); 六、优化与挑战
1. 性能瓶颈
-
Shuffle开销:跨节点数据传输可能成为瓶颈,可通过Combiner和压缩中间数据缓解。
-
小文件问题:过多小文件导致Map任务激增,需合并输入或使用SequenceFile。
2. 适用场景
-
批处理任务:ETL、日志分析等。
-
非实时计算:适合对延迟不敏感的场景。
3. 与Spark对比
| 特性 | MapReduce | Spark |
|---|---|---|
| 计算模型 | 批处理 | 批处理+流处理 |
| 内存使用 | 磁盘优先 | 内存优先 |
| 延迟 | 高 | 低 |
七、总结
MapReduce作为大数据处理的基石,其"分而治之"的思想深刻影响了后续计算框架(如Spark、Flink)。尽管在实时性上存在局限,但其高可靠性和成熟生态仍使其在离线计算领域占据重要地位。理解MapReduce不仅是掌握Hadoop的关键,更是构建分布式系统思维的重要一步。