点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-30-新发布【1T 万亿】参数量大模型!Kimi‑K2开源大模型解读与实践,持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年07月28日更新到: Java-83 深入浅出 MySQL 连接、线程、查询缓存与优化器详解 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
章节内容
上节我们完成了如下的内容:
- Java添加POM依赖
- Java操作Kafka的API、SpringBoot
- 实现对Kafka消息发送和消息消费

基本流程
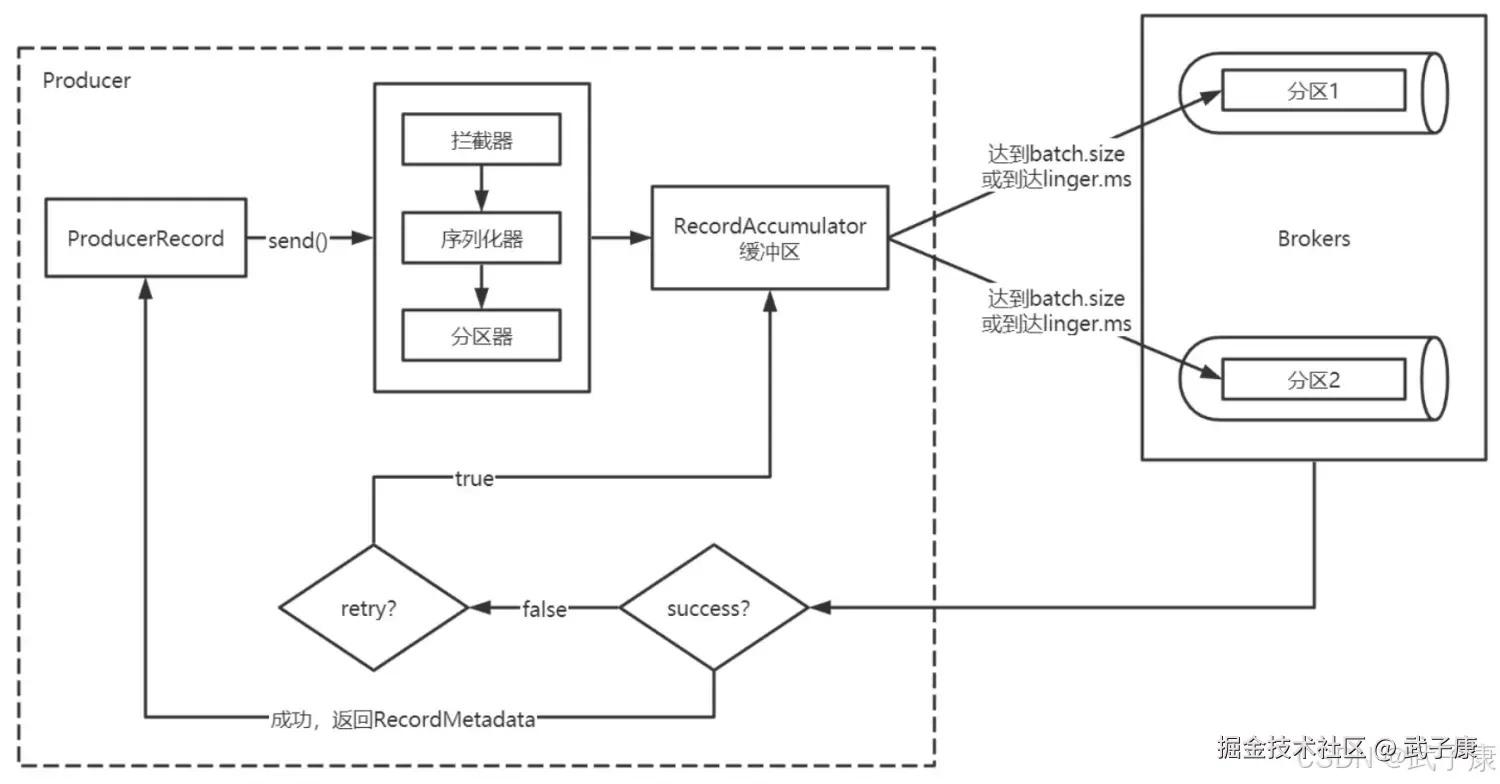
Kafka Producer 消息发送流程详解
Producer初始化阶段
- 在创建KafkaProducer实例时,会同步初始化以下核心组件:
- 创建并启动Sender线程,该线程负责实际的消息发送,被设置为守护线程(daemon thread)
- 初始化RecordAccumulator消息缓冲区,默认大小32MB
- 加载配置的拦截器链(Interceptor)、序列化器(Serializer)和分区器(Partitioner)
消息发送流程
-
当调用send()方法时,实际是异步处理流程: a. 拦截处理 :消息首先通过配置的ProducerInterceptor链进行处理(可用于添加消息头、监控等) 示例:可添加traceId等分布式追踪信息
b. 序列化阶段:分别对消息key和value进行序列化
- 默认使用ByteArraySerializer,也可配置为StringSerializer等
c. 分区路由:通过Partitioner确定目标分区
- 默认使用RoundRobin或Key哈希策略
- 自定义分区器需实现Partitioner接口
消息缓冲与批次发送
- 消息会被暂存到RecordAccumulator缓冲区
- 触发批次发送的条件(满足任一即触发):
- 批次大小达到batch.size(默认16KB)
- 等待时间达到linger.ms(默认0ms,表示立即发送) 应用场景:高吞吐场景可适当调大linger.ms(如50ms)以提升批量效果
- 每个分区对应独立的批次队列
网络传输与Broker处理
- Sender线程将批次消息通过网络发送到目标分区Leader副本
- Broker端处理流程:
- 写入Leader副本的PageCache
- 同步到ISR副本集
- 根据acks配置等待副本同步确认
异常处理机制
- 重试条件:
- retries参数>0(默认Integer.MAX_VALUE)
- 错误类型可重试(如网络异常、NOT_LEADER等)
- 重试策略:
- 具备backoff退避机制(通过retry.backoff.ms配置)
- 避免无效重试(如消息过大等不可恢复错误)
响应处理
- 同步模式:通过Future.get()阻塞等待响应
- 异步模式:通过Callback接口处理响应
- 响应元数据包含:
- 主题、分区信息
- 消息offset
- 时间戳等信息
关键配置参数
| 参数 | 默认值 | 说明 |
|---|---|---|
| batch.size | 16384 | 批次大小(字节) |
| linger.ms | 0 | 批次等待时间 |
| buffer.memory | 33554432 | 缓冲区总大小 |
| max.block.ms | 60000 | 缓冲区满时阻塞时间 |
| retries | 2147483647 | 最大重试次数 |
| acks | 1 | 消息确认机制 |
Broker配置
这里是Broker的常见配置: 
bootstrap.servers
生产者客户端与broker集群建立初始链接需要Broker的地址列表,由该初始连接发现Kafka集群中其他的所有Broker,该地址列表不需要写全部的Kafka集群地址,但也不要只写一个防止宕机不可用。
key.serializer
实现了 org.apache.kafka.common.serialization.Serializer 的key序列化类
value.serializer
实现了 org.apache.kafka.common.serialization.Serializer的value序列化类
acks
该项控制着已发消息的持久性。
- acks=0,生产者不等待Broker的任何消息确认。
- acks=1,Leader将记录写到它本地的地址,就相应客户端的消息,而不等待Follower的副本的确认。
- acks=all,Leader等待所有有同步副本消息的确认,保证了只要有一个同步副本存在,消息就不会丢失。
- acks=-1,等价于 acks=all
默认值为1
compression.type
生产者生成数据的压缩格式,默认是none(无压缩)。 可选:
- none
- gzip
- snappy
- lz4
默认是none
Broker配置补充
额外的配置还有下图的这些内容: 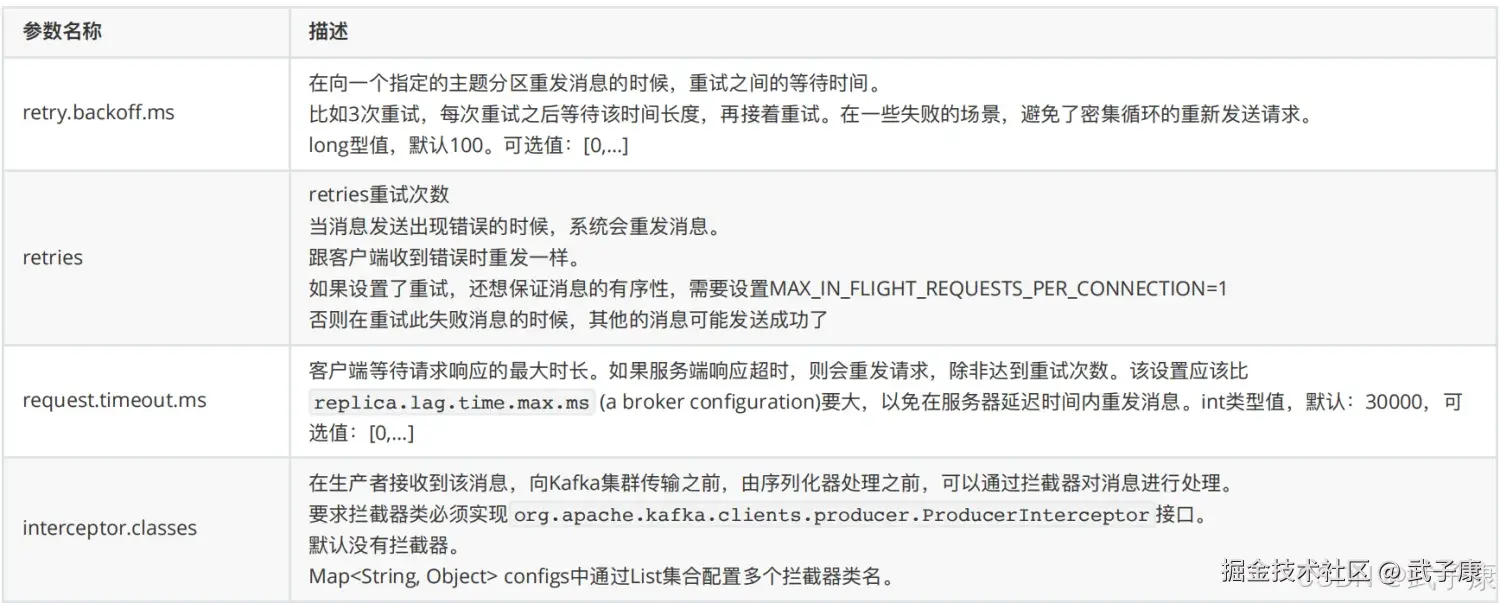


retry.backoff.ms
在向一个指定的主题分区重发消息的时候,控制重试之间的等待时间间隔。这个参数非常重要,它可以避免在遇到临时性故障时过于频繁地重试,从而减轻系统负担。
- 参数作用:当生产者发送消息失败时,会在指定的时间间隔后自动重试
- 工作方式:采用指数退避策略,每次重试的间隔会逐渐增加
- 使用场景:在网络不稳定或broker负载较高时特别有用
- 实际示例:假设设置为100ms,第一次重试等待100ms,第二次可能等待200ms,第三次可能等待400ms
long型 默认 100
retries
retries参数配置生产者发送消息时的重试次数。
- 核心功能:当消息发送出现可重试错误时(如网络问题、leader选举等),系统会自动重新发送消息
- 注意事项 :
- 如果同时需要保证消息的有序性,必须设置MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1
- 重试可能导致消息重复,消费者端需要做好幂等处理
- 推荐值:生产环境通常设置为3-5次
- 错误类型:只对可恢复的异常进行重试(如NetworkException、NotLeaderForPartitionException等)
request.timeout.ms
配置客户端等待请求响应的最长时间。
- 关键作用:控制生产者等待broker响应的时间阈值
- 配置建议 :
- 必须大于replica.lag.time.max.ms(默认10000ms)
- 在网络延迟较高的环境中需要适当增大
- 超时处理 :
- 超时后会触发重试机制(如果配置了retries>0)
- 连续超时达到重试次数上限后会抛出TimeoutException
- 影响因素:受网络状况、broker负载、消息大小等因素影响
int型 默认 30000
interceptor.classes
配置生产者拦截器链,用于在消息发送前进行预处理。
- 执行时机:在消息序列化之前,即将发送到Kafka集群时执行
- 主要用途 :
- 消息内容审计和修改
- 发送统计和监控
- 附加元数据信息
- 实现要求 :
- 必须实现org.apache.kafka.clients.producer.ProducerInterceptor接口
- 需要定义onSend()和onAcknowledgement()方法
- 配置方式:通过MapString, Object configs中的List集合配置多个拦截器
- 执行顺序:按照配置顺序依次执行
- 典型应用 :
- 日志打点
- 消息加密
- 请求追踪
默认没有拦截器
acks
同上,不介绍了。
batch.size
当多个消息发送到同一个分区时,生产者会尝试将多个记录合并为一个批处理(batch)进行发送。这种批处理机制能显著提高客户端和服务端的处理效率,减少网络请求次数。该配置项以字节为单位控制默认批处理的大小,其具体行为和影响如下:
-
批处理大小限制:
- 所有批处理的大小都小于或等于该配置值
- 例如设置为16KB(16384)时,每个批处理最大不超过16KB
-
请求发送机制:
- 发送给Broker的请求将包含多个批次
- 每个分区对应一个批次
- 请求中只包含当前可发送的数据批次
-
配置影响:
- 过小值的影响:
- 会限制系统的吞吐量
- 极端情况下(设置为0)会完全关闭批处理功能
- 示例:设置为1KB可能导致频繁的小批量请求
- 过大值的影响:
- 会占用较多内存资源
- 可能导致消息延迟发送
- 示例:设置为100MB时可能造成内存浪费
- 过小值的影响:
-
典型场景:
- 高吞吐场景建议设置较大的值(如64KB-1MB)
- 低延迟场景可适当减小该值(如16KB-32KB)
- 需根据消息平均大小和分区数量进行权衡
client.id
client.id是生产者在发送请求时传递给Broker的身份标识字符串,其主要作用和特性包括:
-
核心功能:
- 用于在Broker的请求日志中追踪消息来源
- 帮助识别是哪个应用程序发送了特定消息
- 在监控和故障排查时提供重要依据
-
命名规范:
- 通常采用与业务相关的描述性字符串
- 示例:订单服务可能使用"order-service-producer"
- 建议包含应用名称和环境标识(如dev/prod)
-
实际应用:
- 在分布式系统中识别不同生产者实例
- 结合监控系统实现细粒度的性能监控
- 用于配额管理和访问控制
-
最佳实践:
- 保持唯一性和可读性
- 避免使用敏感信息
- 在微服务架构中建议采用标准命名规范
compression.type
同上,不介绍了。
send.buffer.bytes
TCP发送数据的时候用的缓冲区的大小,若设置为0,则用操作系统默认的。
buffer.memory
生产者可以用来缓存等待发送到服务器的记录的总内存字节,如果记录的发送速度超过了将记录发送到服务器的速度,则生产者将阻塞 max.block.ms 的时间,此后将引发异常。 此设置应大致对应于生产者将使用的总内存,但并非生产者使用的所有内存都用于缓冲。
connections.max.idle.ms
当连接空闲时间达到这个值,就关闭连接。 long型 默认 540000
linger.ms
生产者发送请求传输间隔会对需要发送的消息进行累积,然后作为一个批次发送,一般情况是消息的发送速度比消息积累的速度要慢。 有时候客户端需要减少请求次数,即使在负载不大的情况下。该配置设置了一个延迟,生产者消息不会立即将消息送到Broker,而是等待这么一段时间以积累消息,然后将这段消息之类的消息作为一个批次发送,该设置是批处理的另一个上限,一旦此消息达到了batch.size指定的值,消息批会立即发送,如果积累的消息字节数达不到batch.size的值,可以设置该毫秒值,等待这么长时间之后,也会发送消息批。 默认值是0
max.block.ms
控制KafkaProducer.send()和KafkaProducer.partitionFor()阻塞时长,当缓存满了或元数据不可用的时候,这些方法阻塞。在用户提供的序列化器和分区器的阻塞时间不计入。 long型值,默认60000
max.request.size
单个请求的最大字节数,该设置会限制单个请求总消息批的个数,以免单个请求发送太多的数据,服务器有自己的限制批大小的设置,与该配置可能不一样 int 型 默认 1048576
partitioner.class
实现了接口 org.apache.kafka.clients.producer.Partitioner 的分区器实现类。默认值:org.apache.kafka.clients.producer.internals.DefaultPartitioner
receive.buffer.bytes
TCP接收缓存(SO_RECVBUF),设置为01,则使用操作系统默认的值。 int型 默认32768
security.protocol
跟 Broker 通信的协议:PLAINTEXT、SSL、SASL_PLAINTEXT、ASAL_SSL String型 默认 PLAINTEXT
max.in.flight.requests.per.connection
单个连接上未确认请求的最大数量,达到这个数量,客户端阻塞。 如果该值大于1,则存在失败的请求,在重试的时候消息顺序不能保证。 int型 默认5
reconnect.backoff.max.ms
对于每个连续的连接失败,每台主机退避将成倍增加,直到达到此最大值。
reconnect.backoff.ms
尝试重连指定主机的基础等待时间,避免该主机的密集重连。