在当今大数据时代,企业对于实时数据分析的需求呈现爆发式增长。面对动辄PB级的数据量和秒级响应的业务诉求,传统数据库系统往往力不从心。Apache Doris作为新一代MPP分析型数据库,凭借其独特的索引机制,在京东、美团等企业的实时数仓场景中展现出卓越性能。本文将深入解析Doris索引设计的精妙之处。
与传统的OLTP数据库不同,Doris作为OLAP系统面临着完全不同的挑战:海量数据(单表千亿级)、复杂查询(多表Join+聚合)、实时响应(亚秒级延迟)。在这种场景下,Doris选择了多层次互补型索引体系,通过不同粒度的索引配合,在存储空间(仅增加5%-10%)和查询效率之间找到完美平衡点。
其核心设计原则可概括为:
- 智能路由:通过元数据快速定位数据块
- 分层过滤:从分区级到列级的递进式筛选
- 计算下推:在存储层完成最大限度的过滤
Doris 索引分类
前缀稀疏索引
Apache Doris 数据库存储在类似 SSTable 的数据结构中,SSTable 是一种有序的数据结构,可以按照指定的一个或多个列进行排序存储。在查询时加上排序列,Doris 不需要扫描全表即可快速找到需要处理的数据,降低搜索复杂度。
除了排序健,Doris 还会每隔 1024 行数据创建一个稀疏前缀索引,索引中的 Key 是当前 1024 行中第一行中排序列的值。和传统数据库的单列或多列索引不同,Doris 将表数据的前序列字段组成前缀索引,最大长度不超过 36 字节。比如在以下的表结构中,前缀索引中保存的数据为:user_id(8 Bytes) + age(4 Bytes) + message(prefix 20 Bytes)。
| ColumnName | Type |
|---|---|
| user_id | BIGINT |
| age | INT |
| message | VARCHAR(100) |
| max_dwell_time | DATETIME |
| min_dwell_time | DATETIME |
这里需要注意的是,前缀索引遇到 VARCHAR 类型会自动截断,即使没有达到 36 个字节。所以在设计前缀索引时,如果不是特别需求,不建议将 VARCHAR 字段放在最前面。
在查找前缀索引表时可以通过索引确定该行数据所在的逻辑数据块的起始行号,由于前缀索引比较小,可以全量缓存在内存中,快速定位数据块,提升查询效率。
倒排索引
倒排索引将文本分成一个个词,构建词->文档编号的索引,Table 的一行对应一个文档、一列对应文档中的一个字段。对创建了倒排索引的列,建立每个值到对应行号集合的倒排表。
倒排索引的使用范围很广泛,可以加速等值、范围、全文检索等多种类型的操作。一个表可以有多个倒排索引,查询时多个倒排索引的条件可以任意组合。对于等值查询,先从倒排表中查到行号集合,然后直接读取对应行的数据,而不用逐行扫描匹配数据,从而减少 I/O 加速查询。
创建倒排索引时可以通过 PROPERTIES 参数指定分词器和分词模式,满足更加个性化的需求。
BloomFileter 索引
BloomFilter 索引是基于 BloomFilter 的一种跳数索引,原理是利用 BloomFilter 跳过等值查询指定条件不满足的数据块,达到减少 I/O、加速查询的目的。通常应用在一些需要快速判断某个元素是否属于集合,但并不严格要求 100%正确的场合。
BloomFilter 是由 Bloom 在 1970 年提出的一种多哈希函数映射的快速查找算法,由一个超长的二进制位数组和一系列的哈希函数组成。二进制位数组初始全部为 0,当给定一个待查询的元素时,这个元素会被一系列哈希函数计算映射出一系列的值,所有的值在位数组的偏移量处置为 1。
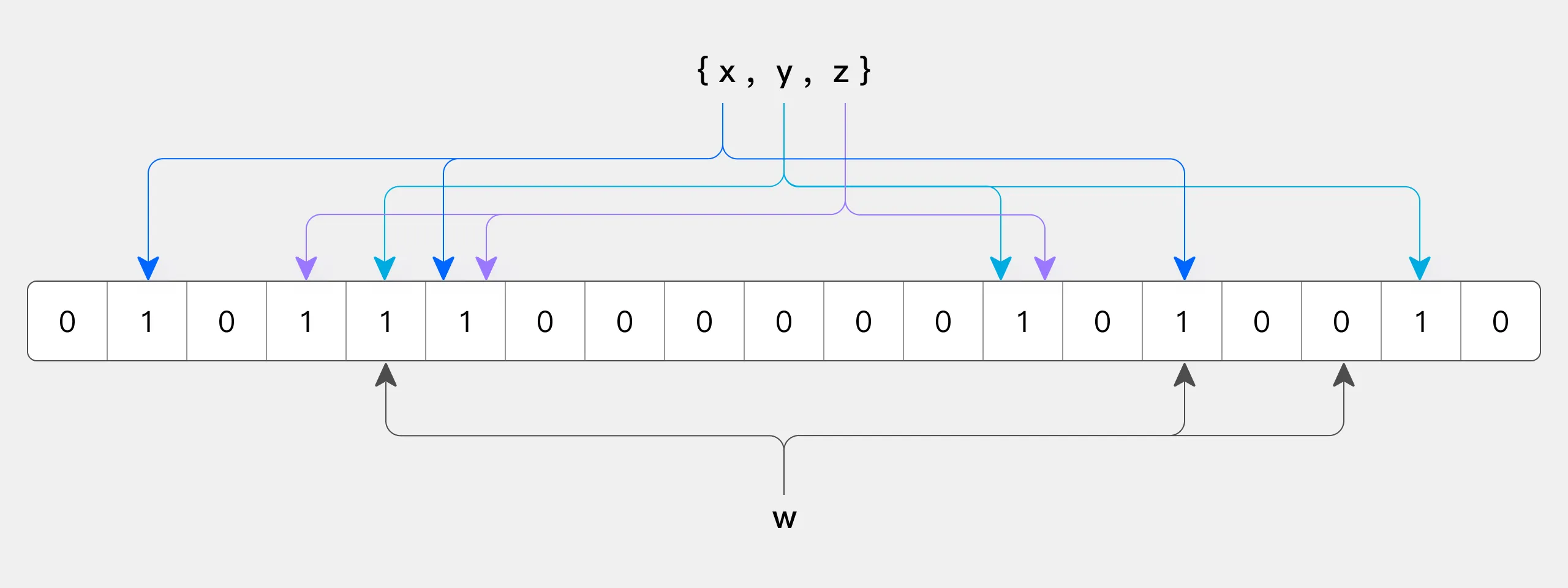
Doris BloomFilter 索引以数据块(page)为单位构建,每个数据块存储一个 BloomFilter。写入时,对于数据块中的每个值,经过 Hash 存入数据块对应的 BloomFilter。查询时,根据等值条件的值,判断每个数据块对应的 BloomFilter 是否包含这个值,不包含则跳过对应的数据块不读取,达到减少 I/O 查询加速的目的。
ZoneMap 索引
ZoneMap 索引自动维护每一列的统计信息,为每一个数据文件和数据块记录最大值、最小值以及是否包含 NULL 值。对于等值查询、范围查询、IS NULL,可以通过最大值、最小值、是否有 NULL 来判断数据文件和数据块是否可以包含满足条件的数据,如果没有则跳过不读对应的文件或数据块减少 I/O 加速查询。
前缀索引和 ZoneMap 索引是 Apache Doris 自动维护的内建智能索引,无需用户管理。
索引特性总结
最后为了大家学习的方便,将各种索引的优缺点汇总如下。
| 类型 | 索引 | 优点 | 局限 |
|---|---|---|---|
| 点查索引 | 前缀索引 | 内置索引,性能最好 | 一个表只有一组前缀索引 |
| 点查索引 | 倒排索引 | 支持分词和关键词匹配,任意列可建索引,多条件组合,持续增加函数加速 | 索引存储空间较大,与原始数据相当 |
| 跳数索引 | ZoneMap 索引 | 内置索引,索引存储空间小 | 支持的查询类型少,只支持等于、范围 |
| 跳数索引 | BloomFilter 索引 | 比 ZoneMap 更精细,索引空间中等 | 支持的查询类型少,只支持等于 |
| 跳数索引 | NGram BloomFilter 索引 | 支持 LIKE 加速,索引空间中等 | 支持的查询类型少,只支持 LIKE 加速 |