https://leetcode.cn/problems/design-linked-list/description/
一、题目分析
你可以选择使用单链表或者双链表,设计并实现自己的链表。
单链表中的节点应该具备两个属性:val 和 next 。val 是当前节点的值,next 是指向下一个节点的指针/引用。
如果是双向链表,则还需要属性 prev 以指示链表中的上一个节点。假设链表中的所有节点下标从 0 开始。
实现 MyLinkedList 类:
MyLinkedList()初始化MyLinkedList对象。int get(int index)获取链表中下标为index的节点的值。如果下标无效,则返回-1。void addAtHead(int val)将一个值为val的节点插入到链表中第一个元素之前。在插入完成后,新节点会成为链表的第一个节点。void addAtTail(int val)将一个值为val的节点追加到链表中作为链表的最后一个元素。void addAtIndex(int index, int val)将一个值为val的节点插入到链表中下标为index的节点之前。如果index等于链表的长度,那么该节点会被追加到链表的末尾。如果index比长度更大,该节点将 不会插入 到链表中。void deleteAtIndex(int index)如果下标有效,则删除链表中下标为index的节点。
示例:
输入
["MyLinkedList", "addAtHead", "addAtTail", "addAtIndex", "get", "deleteAtIndex", "get"]
[[], [1], [3], [1, 2], [1], [1], [1]]
输出
[null, null, null, null, 2, null, 3]
解释
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.addAtHead(1);
myLinkedList.addAtTail(3);
myLinkedList.addAtIndex(1, 2); // 链表变为 1->2->3
myLinkedList.get(1); // 返回 2
myLinkedList.deleteAtIndex(1); // 现在,链表变为 1->3
myLinkedList.get(1); // 返回 3今天的这道题目算得上是目前碰到的最多字数的题了,但是需求很简单,实现出四个功能即可。分别为:
- int get(int index)获取链表中下标为index的节点的值
- void addAtHead(int val)将一个val的节点插入到链表中第一个元素之前,也就是头插操作。
- void addAtTail(int val)将一个值为val的节点追加到链表中作为链表的最后一个元素,也就是尾插操作。
- void addAtIndex(int index, int val)将一个值为val的节点插入到链表中下标为index的节点之前,这里对应随机插入操作。
- void deleteAtIndex(int index) 如果下标有效,则删除链表中下标为
index的节点。
二、示例分析
输入 ["MyLinkedList", "addAtHead", "addAtTail", "addAtIndex", "get", "deleteAtIndex", "get"] [[], [1], [3], [1, 2], [1], [1], [1]] 输出 [null, null, null, null, 2, null, 3] 解释 MyLinkedList myLinkedList = new MyLinkedList(); myLinkedList.addAtHead(1); myLinkedList.addAtTail(3); myLinkedList.addAtIndex(1, 2); // 链表变为 1->2->3 myLinkedList.get(1); // 返回 2 myLinkedList.deleteAtIndex(1); // 现在,链表变为 1->3 myLinkedList.get(1); // 返回 3
三、设计思路&代码实现
首先题目说明可以使用单链表||双链表,这里我们选用单链表的解法,只要掌握了单链表的一些基本操作,再使用双链表进行实现起来就会很容易。
一、创建结构体
这里我们需要创建一个结构体,之前在和大家分享链表的中间节点那里,有提到过链表这种数据结构的存储方式,如果忘记的同学,可以点击链接重新回忆一下。
https://blog.csdn.net/m0_75144071/article/details/144828160?spm=1001.2014.3001.5502
cpp
// 定义链表节点的结构体
struct LinkNode {
int val; // 节点存储的数据值
LinkNode* next; // 指向下一个节点的指针
// 构造函数,用于初始化新节点
// 参数 val: 要存储在节点中的值
LinkNode(int val) : val(val), // 初始化 val 成员为传入的值
next(nullptr) // 初始化 next 指针为 nullptr(表示这是尾节点)
{
// 构造函数体为空,因为初始化列表已经完成了所有初始化工作
}
};LinkNode是一个表示节点的结构体,包含两个成员,分别为val用于存储节点的数据(本题用到的数据类型为int型),next用于指向一下个节点的指针(LinkNode*类型)
二、初始化链表
在昨天的题目中给大家介绍了使用虚拟头节点进行一些链表的基本操作时会很方便,今天我们同样采用虚拟带有虚拟头节点的方式来实现。忘记的同学,可以点击链接再重新回顾一下。
https://blog.csdn.net/m0_75144071/article/details/147662796?spm=1001.2014.3001.5502
cpp
// MyLinkedList 类的构造函数
MyLinkedList() {
// 创建一个虚拟头节点(dummy node),其值初始化为0
// 虚拟头节点不存储实际数据,它的存在是为了简化链表操作
// 例如在链表头部插入/删除节点时不需要特殊处理
dummyHead = new LinkNode(0);
// 初始化链表大小为0,表示当前链表为空(只有虚拟头节点)
size = 0;
}三、查找功能(按位序查找)
链表这种数据结构有一种缺点,不支持随机访问,也就是他没有办法做到像数组那样,我只要有了元素的下标就可以用常数级的时间复杂度来找到这个元素。使用链表查找元素时复杂度为O(n)(最坏)。所以我们需要从头开始遍历才可以进行查找。
cpp
/**
* 获取链表中指定位置的元素值
* index 要获取的元素位置索引(从0开始)
* return 如果索引有效则返回对应节点的值,否则返回-1
*/
int get(int index) {
// 边界检查:如果索引超出有效范围(小于0或大于等于链表长度)
// 则返回-1表示无效
if (index > (size - 1) || index < 0)
return -1;
// 初始化当前指针指向第一个实际节点(跳过虚拟头节点)
LinkNode* cur = dummyHead->next;
// 遍历链表直到目标位置
// 使用index--的方式移动指针,循环次数即为需要移动的步数
while (index--) {
cur = cur->next;
}
// 返回找到的节点的值
return cur->val;
}四、头插操作
在进行头插入/头删除操作时候,链表的效率就会比顺序表(数组)高很多, 链表的复杂度为O(1),而数组则需要O(n)。
cpp
/**
* 在链表头部插入一个新节点
* val 要插入的节点值
*/
void addAtHead(int val) {
LinkNode* newNode = new LinkNode(val);
// 新节点指向当前第一个节点
newNode->next = dummyHead->next;
// 更新dummyHead指向新节点
dummyHead->next = newNode;
// 增加链表长度
size++;
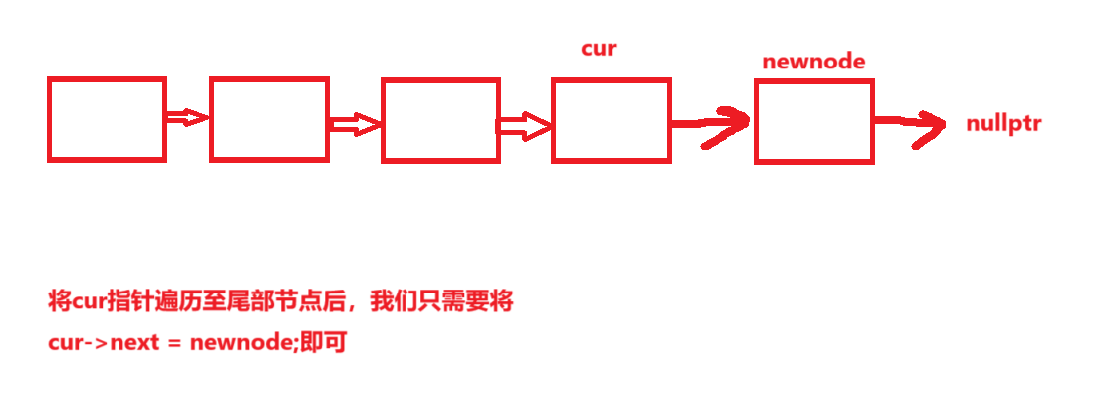
}以下为图文讲解:

五、尾插操作
链表的尾插操作由于每次需要从头节点开始遍历找到最后的尾部节点,所以整体时间复杂度为O(n)。
cpp
void addAtTail(int val) {
LinkNode* newNode = new LinkNode(val);
newNode->next = nullptr; // 由于是单链表的尾部插入,所以next的的指向应为nullptr
LinkNode* cur = dummyHead;
while (cur->next) { // 遍历直到找到最后一个节点
cur = cur->next;
}
cur->next = newNode; // 将新节点接在尾部
size++; // 增加链表大小
}图文讲解:
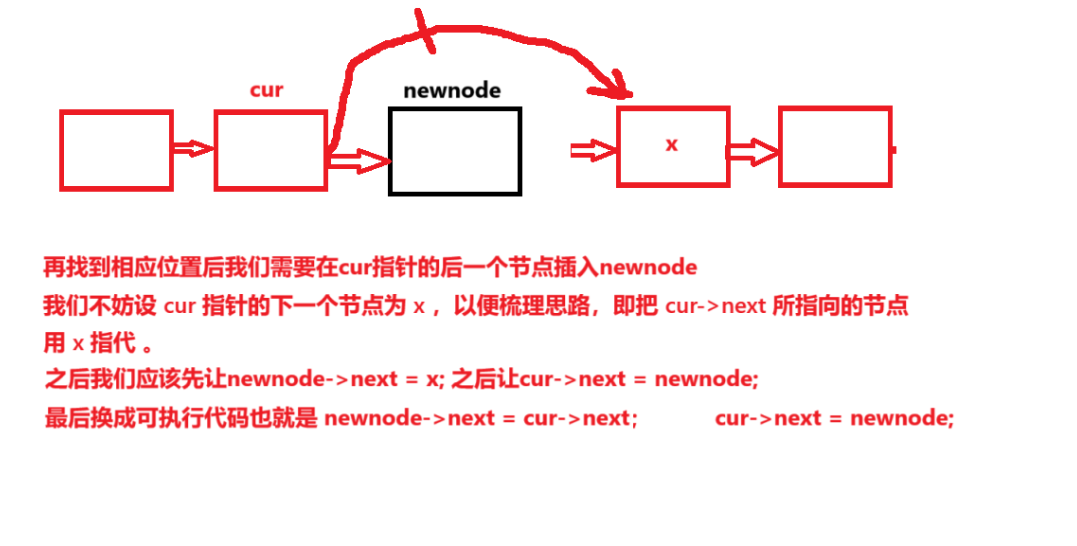
六、按位序的插入操作
在进行按位序插入操作时,链表整体的时间复杂度以查找位置为主导为O(n) (最坏情况下),相比数组来说,时间复杂度整体相同。
cpp
/**
* 在链表的指定位置插入一个新节点
* index 要插入的位置索引(从0开始)
* val 要插入的节点值
*/
void addAtIndex(int index, int val) {
// 1. 边界检查:如果索引大于当前链表长度或索引小于0,直接返回不执行插入
if (index > size || index < 0)
return;
// 2. 创建新节点,使用构造函数直接初始化节点值
LinkNode* newNode = new LinkNode(val);
// 3. 定位到要插入位置的前驱节点
LinkNode* cur = dummyHead; // 从虚拟头节点开始
while (index--) { // 循环index次,移动到插入位置的前一个节点
cur = cur->next;
}
// 4. 执行插入操作
newNode->next = cur->next; // 新节点的next指向原位置的节点
cur->next = newNode; // 前驱节点的next指向新节点
// 5. 更新链表长度
size++;
}图文解释:
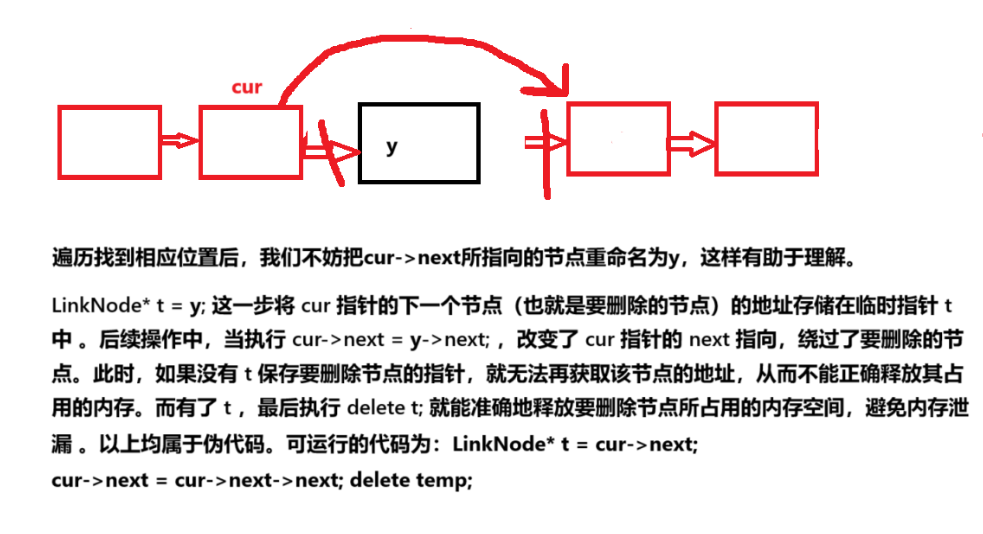
七、按位序的删除操作
在链表中的按位序删除与插入相同。链表整体的时间复杂度以查找位置为主导为O(n) (最坏情况下),相比数组来说,时间复杂度整体相同。
cpp
// 删除指定索引位置的节点
// 参数:
// index: 要删除节点的索引,索引从 0 开始
void deleteAtIndex(int index) {
// 检查索引是否越界,如果索引大于等于链表的大小或者小于 0,直接返回
if (index >= size || index < 0)
return;
// 定义一个指针 cur,初始指向虚拟头节点 dummyHead
// 虚拟头节点的作用是简化链表头节点的操作
LinkNode* cur = dummyHead;
// 通过循环让 cur 指针移动到要删除节点的前一个节点
// 循环条件 index-- 表示每次循环后 index 的值减 1,直到 index 变为 0
while (index--) {
cur = cur->next;
}
// 定义一个临时指针 temp,指向要删除的节点
// 即 cur 指针当前所指节点的下一个节点
LinkNode* temp = cur->next;
// 调整 cur 指针的 next 指针,使其跳过要删除的节点
// 直接指向要删除节点的下一个节点
cur->next = cur->next->next;
// 释放要删除节点所占用的内存,防止内存泄漏
delete temp;
// 链表的大小减 1,因为成功删除了一个节点
size--;
}图文讲解:
至此本题需实现的所有功能均已实现完毕!完结撒花!!!🌸🌸🌸
八、完整代码
C++:
cpp
class MyLinkedList {
public:
struct LinkNode {
int val;
LinkNode* next;
LinkNode(int val) : val(val), next(nullptr) {}
};
MyLinkedList() {
dummyHead = new LinkNode(0);
size = 0;
}
int get(int index) {
if (index > (size - 1) || index < 0)
return -1;
LinkNode* cur = dummyHead->next;
while (index--) {
cur = cur->next;
}
return cur->val;
}
void addAtHead(int val) {
LinkNode* newNode = new LinkNode(0);
newNode->val = val;
newNode->next = dummyHead->next;
dummyHead->next = newNode;
size++;
}
void addAtTail(int val) {
LinkNode* newNode = new LinkNode(0);
newNode->val = val;
newNode->next = NULL;
LinkNode* cur = dummyHead;
while (cur->next) {
cur = cur->next;
}
cur->next = newNode;
size++;
}
void addAtIndex(int index, int val) {
if (index > size)
return;
LinkNode* newNode = new LinkNode(val);
LinkNode* cur = dummyHead;
while (index--) {
cur = cur->next;
}
newNode->next = cur->next;
cur->next = newNode;
size++;
}
void deleteAtIndex(int index) {
if (index >= size || index < 0)
return;
LinkNode* cur = dummyHead;
while (index--) {
cur = cur->next;
}
LinkNode* temp = cur->next;
cur->next = cur->next->next;
delete temp;
size--;
}
void Print() {
LinkNode* cur = dummyHead->next;
while (cur->next) {
cout << cur->val << " ";
cur = cur->next;
}
cout << endl;
}
private:
int size;
LinkNode* dummyHead;
};
/**
* Your MyLinkedList object will be instantiated and called as such:
* MyLinkedList* obj = new MyLinkedList();
* int param_1 = obj->get(index);
* obj->addAtHead(val);
* obj->addAtTail(val);
* obj->addAtIndex(index,val);
* obj->deleteAtIndex(index);
*/四、链表与数组的对比
链表 vs 数组 操作对比总结
时间复杂度对比
操作 链表 数组 胜出方 随机访问 O(n) O(1) 数组 头部插入/删除 O(1) O(n) 链表 尾部插入/删除 O(n) O(1) 数组 中间插入/删除 O(n) O(n) 平手 核心特点
链表:动态内存、插入删除快(尤其头部)、访问慢
数组:连续内存、访问快、插入删除慢(需移动元素)
适用场景
选链表:频繁在头部/中部增删(如栈、队列)
选数组:频繁随机访问或尾部操作(如数值计算)
五、题目总结
这道题目让我们自己动手实现一个链表数据结构,主要包含获取节点值、头部插入、尾部插入、指定位置插入和删除这五个核心操作。通过这个实现过程,我们深入理解了链表的基本特性和操作原理。
链表最大的特点是插入删除高效,尤其是头部操作只需要O(1)时间,这比数组要快很多。但是链表访问元素需要从头遍历,时间复杂度是O(n),不如数组的随机访问快。在实际开发中,如果经常需要在头部插入删除数据,链表是更好的选择;如果需要频繁按位置访问数据,数组会更合适。
实现链表时要注意几个关键点:使用虚拟头节点可以简化操作;维护链表长度size变量能方便边界检查;指针操作要特别注意顺序,避免出现断链的情况。这些细节处理能力是成为一名合格程序员的基本功。
通过这道题目,我们不仅掌握了链表的实现方法,更重要的是理解了不同数据结构的适用场景。在实际工程中,要根据具体需求选择最合适的数据结构,这是写出高效代码的重要基础。链表作为基础数据结构,它的思想在很多高级数据结构中都有体现,学好链表对后续学习树、图等结构很有帮助。今天的分享到此结束!谢谢大家!!!荆轲刺秦!!!