文章目录
- String类型存储方式
- set命令
- get命令
- mset命令
- mget命令
- setnx命令
- setex和psetex命令
- incr和decr命令系列
- append命令
- getrange命令
- setrange命令
- strlen命令
- 字符串类型命令小结
- string内部的编码方式
- string类型的典型应用场景
String类型存储方式
Redis内部存储字符串完全是按照⼆进制流的形式保存的,不会做任何编码转换,存的是啥,取出来就是啥。不仅仅可以存储文本数据,还能存储整数,普通的文本字符串,JSON字符串,二进制数据(图片,视频,音频等),因为Redis单线程模型对于音视频来说,音视频的体量还是比较大的,由于希望操作比较快速,所以Redis限制了string类型最大的大小是512MB。

set命令
将string类型的value设置到key中。如果key之前存在,则覆盖,⽆论原来的数据类型是什么。之
前关于此key的TTL(生存时间)也全部失效。
用法:
SET key value expiration EX seconds\|PX milliseconds NX\|XX
以下都是set命令的选项
EX : 设置单位为秒的过期时间。
PX : 设置单位为微秒的过期时间。
NX : 如果key不存在,则设置,如果key存在,则不设置(返回nil)
XX : 如果key不存在,则不设置,如果key存在,则更新value
案例:
cpp
set key value ex 10 nx
设置一个过期时间为10秒的key-value键值对,方式是nx方式。
相当于:
set key value
expire key 10get命令
获取key对应的value,如果key不存在,则返回nil。如果key对应的value的数据类型不是string,则会报错。(因为不同的容器有不同的命令)
因为对于get来说,只是支持,字符串的类型的value,如果value是其他类型,使用get就会报错。
mset命令
一次设定多个key和value,当然也可以设定一个。
mset key value key value...
存在这个命令是因为,像redis服务器发送一次set命令和发送多次set命令区别是非常大的,经过网络层,同时也要经过路由器发送到对方服务器,所以影响性能,具体请看上一篇文章。
但是建议使用mset的使用,key和value要适量。假如一次设10w个key和value,可能会使redis服务器卡顿死机。
时间复杂度:O(N):N是我当前给的key-value的数量,不是服务器中所有的key-value的数量。所以可以理解成O(1)。
mget命令
一次获取多个key对应的value。
mget key key...
时间复杂度:O(N):N是我当前给的key的数量,不是服务器中所有的key的数量。所以可以理解成O(1)

setnx命令
这个命令其实就是上面说的set命令添加了一个nx选项后的结果。
如果key-value不存在,则设置,如果存在,则不设置。
setex和psetex命令
就是上面所说的set命令加了ex选项和pset命令加了ex选项后的结果。
setex为key设置过期时间,单位是秒。
psetex为key设置过期时间,单位是毫秒。
incr和decr命令系列
incr:针对key对应的value+1
1.key对应的value必须是整数,此时操作的返回值是+1后的值,类似(++i)
2.如果这个value是一个大于int的最大值,就会报错,说超范围了。
3.如果incr的这个key不存在,则默认把这个key设置进去,并且把value当做从0开始自增。(所以incr一个不存在的key后,返回key-1这个键值对。
incrby:针对key对应的value+n1.这个incrby的所有情况都跟上面的incr一样,除了加的数不一样之外。
2.如果自增的是一个负数,则直接相当于decrby。要存在decrby这个命令,就是因为设计这些东西要符合使用者的直觉。要让用户使用的更加简单方便。
decr:针对key对应的value-1decrby:针对key对应的value-n
这两个的注意事项跟上面的incr和incrby都几乎一样的。
incrbyfloat:针对key对应的value +/- 小数将key对应的string表示的浮点数加上对应的值。如果对应的值是负数,则视为减去对应的值。如果key不存在,则视为key对应的value是0。如果key对应的不是string,或者不是⼀个浮点数,则报错。允许采用科学计数法表示浮点数
上述操作的时间复杂度O(1),因为这些操作都是根据key获取value,然后再对value进行操作,然后更新value。
由于redis处理命令时,是单线程模型(redis单独设置一个线程专门处理命令请求的),所以多个客户端对同一个key进行incr操作时,不会引起线程安全问题。
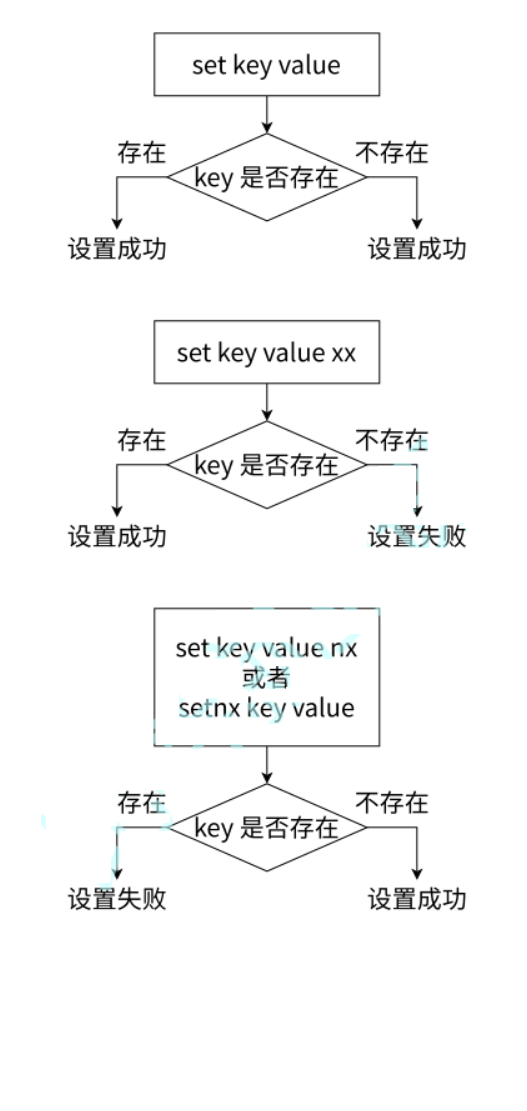
append命令
append key value
这个value是追加在key对应的value(string类型)后面的。
返回值的单位,是字节!!!
这个命令是在一个已经存在的key对应的value值(必须是string类型)后面追加一个字符串。如果key不存在,则效果等于set命令。
redis的字符串,不会对编码作任何处理(redis不认识字符,只认识字节)
在当前xhell中,默认采用的是utf8编码格式,一个汉字是3个字节。
所以返回的是6字节
时间复杂度O(1),追加的字符串较短,可视为O(1)
--raw选项让redis尝试将二进制数据翻译
在启动redis客户端时,在后面加上--raw选项后,会将key对应的value的二进制字节数据翻译。
redi-cli --raw
启动后,本来key对应的value是"你好",没翻译前是6个字节的数据,翻译后就是你好了。
还有两个小命令:
ctrl + s和ctrl + q。
在xhell的bash进程中,ctrl + s命令是"冻结当前画面"。看起来好像是卡死了一样。
其实不是,就是将当前画面冻结了,有这个功能是因为在linux中,可能会打印很多的日志,为了方便查看,就按ctrl + s冻结(在window中,ctrl+s一般是用来保存数据的)解冻也很简单:ctrl + q。
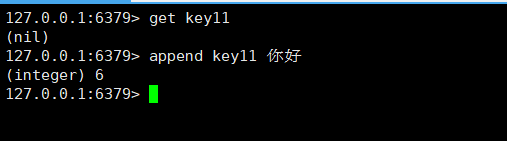
getrange命令
getrange key start end
返回值是一个字符串
在redis中,star,end这个区间是左闭右闭的。且start和end都可以使用负数表示。
-1就表示倒数第一个元素,-2表示倒数第二个。
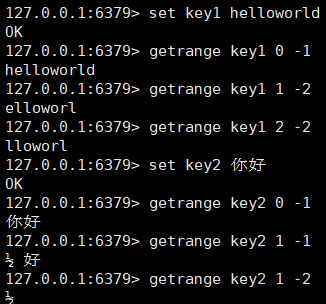
但是如果使用的是汉字,用getrange就不太合适了,就可能会出现一些问题。
上述问题,在c++同样存在,因为在C++中字符串的基本单位是字节。(redis也是)
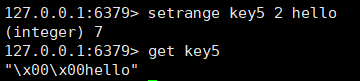
setrange命令
setrange key offset value
从offset偏移量开始,覆盖字符串。
返回值:替换后的总的string的长度。
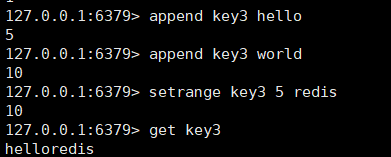
如果是一个中文字符串,覆盖后可能会出问题。
如果key不存在,会把offset之前的位置都设置为0x00。
strlen命令
返回获取到的字符串的长度,单位是字节。

字符串类型命令小结
string内部的编码方式
内部编码
字符串类型的内部编码有3种:
- int:8个字节的长整型。
- embstr:小于等于39个字节的字符串。
- raw:大于39个字节的字符串。
Redis会根据当前值的类型和长度动态决定使⽤哪种内部编码实现。
查看当前key的编码方式:
object encoding key
不建议记39字节这样的数字,这些数字在不同的业务需求下,就会出现动态变化,记了也没用。
为啥很多大厂,往往是自己造轮子,而不是直接使用业界成熟的呢?
开源的组件,往往考虑的是通用性,但是大厂往往会遇到一些极端的业务场景
往往就需要根据当前的极端业务,针对上述的开源组件进行定制化。
redis存储小数,本质上还是当做字符串来存储。这就和整数相比差别很大了
整数直接使用int来存(准确来说是一个long long(C++)/long(ava)),比较方便进行算术运算的。小数则是使用字符串来存,意味着每次进行算术运算,都需要把字符串转成小数,进行运算,结果再转回字符串保存。
总结:小数的存储是存的字符串,计算的时候先把字符串类型转成小数,再算,算完再转回字符串保存,这样转来转去,自然就有开销了。
string类型的典型应用场景
1.Redis+MySQL组成的缓存存储架构

但是这里就有一个问题了:随着时间迁移,用户读取的数据越来越多,Redis存储的热点数据越来越多,此时redis不会被存满吗,毕竟只是一个内存级的数据库。
解决方案:
1)在把数据写给redis时,给key设置一个过期时间。
2)redis在内存不足时,提供了"淘汰策略"。
伪代码演示用户业务数据访问过程:

通过增加缓存功能,在理想情况下,每个⽤⼾信息,⼀个⼩时期间只会有⼀次 MySQL 查询,极⼤地提升了查询效率,也降低了 MySQL 的访问数。
与 MySQL 等关系型数据库不同的是,Redis 没有表、字段这种命名空间,⽽且也没有对键名
有强制要求(除了不能使⽤⼀些特殊字符)。但设计合理的键名,有利于防⽌键冲突和项⽬的可维护性,⽐较推荐的⽅式是使⽤ "业务名:对象名:唯⼀标识:属性" 作为键名。
例如MySQL 的数据库名为 vs,⽤⼾表名为 user_info,那么对应的键可以使⽤
"vs:user_info:6379"、"vs:user_info:6379:name" 来表⽰。
如果当前 Redis 只会被⼀个业务使⽤,可以省略业务名 "vs:"。如果键名过程,则可以使⽤团队内部都认同的缩写替代,
例如"user:6379:friends:messages:5217" 可以被 "u:6379🇫🇷m:5217" 代替。
毕竟键名过⻓,还是会导致 Redis 的性能明显下降的。
2.计数功能
典型应用场景:统计视频播放次数。
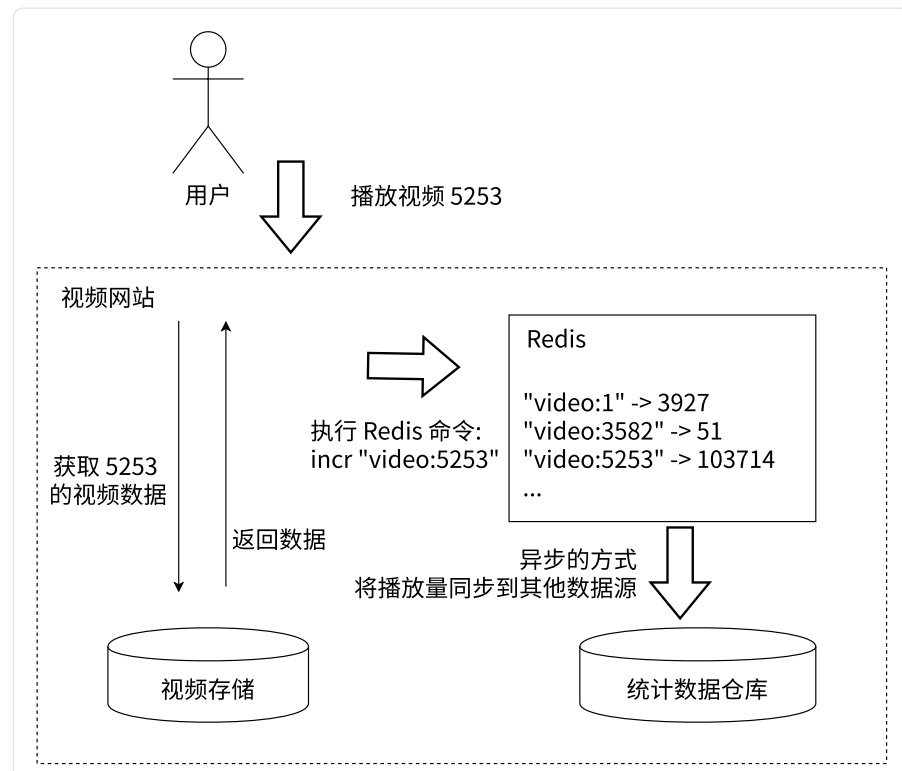
比如:想在上面的Redis中统计播放量前100的视频有那些,用Redis搞就很麻烦。
相比之下,如果是用MySQL来操作就很方便。直接select 表名 order by 视频id limit 100即可。
什么是异步?
如果一秒钟同时来了10000个客户点击视频,redis就会处理这些命令,然后把统计次数(播放量)交给其他仓库(MySQL)这些仓库不是要立刻马上把数据写入数据库,而是能写多少是多少。如果是高峰期,那可能就写得慢一点,如果是平时,那就争取把之前的数据快点写入数据库。
3.共享会话
什么是共享会话呢?
举一个简单的例子:
上周我由于感冒严重,不得已去医院看病,这个医生看我的情况比较严重,给我做了些记录:开了三天的药量,做了一个喉镜检查,我的姓名,身份证号,开药的时间,喉镜检查的时间,检查结果,药的名字,各种详细信息都记载到电脑上。然后医生吩咐我,下周来复查,。我就遵照医嘱,按时服药。然而, 下周我来复查的时候,发现了一个问题:这次给我复查的医生,不是上次那个医生了!这个新的医生没有给我看过病,这时候他打开电脑,问我姓名和身份证号(输入用户信息),登录他们医院的系统,就看到了我一周前上个医生做的各种信息记录,这时候他就了解我的情况了,然后就能给我对症下药了。
上面的案例核心在于,我相当于客户端,医生 相当于服务器,服务器采用的就是负载均衡的策略,客户端两次访问服务器,可能不是同一台服务器处理。此时如果服务器之间各自保存自己的用户的数据,用户在两次访问服务器时,可能得到的数据是错误的。
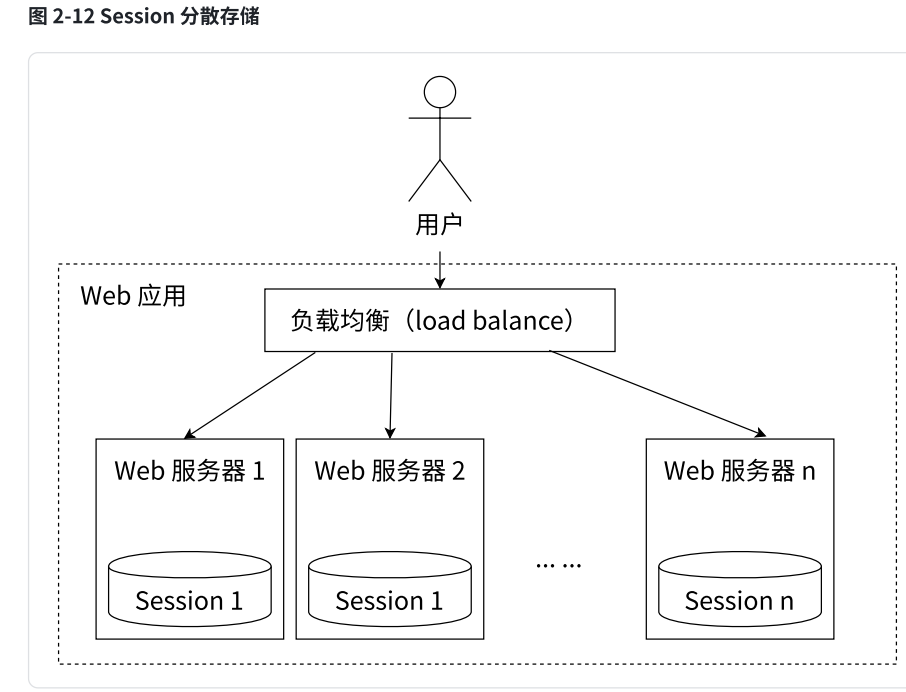
为了解决这个问题,可以使⽤ Redis 将⽤⼾的 Session 信息进⾏集中管理,在这种模式下,只要保证 Redis 是⾼可⽤和可扩展性的,⽆论⽤⼾被均衡到哪台 Web 服务器上,都集中从Redis 中查询、更新 Session 信息。
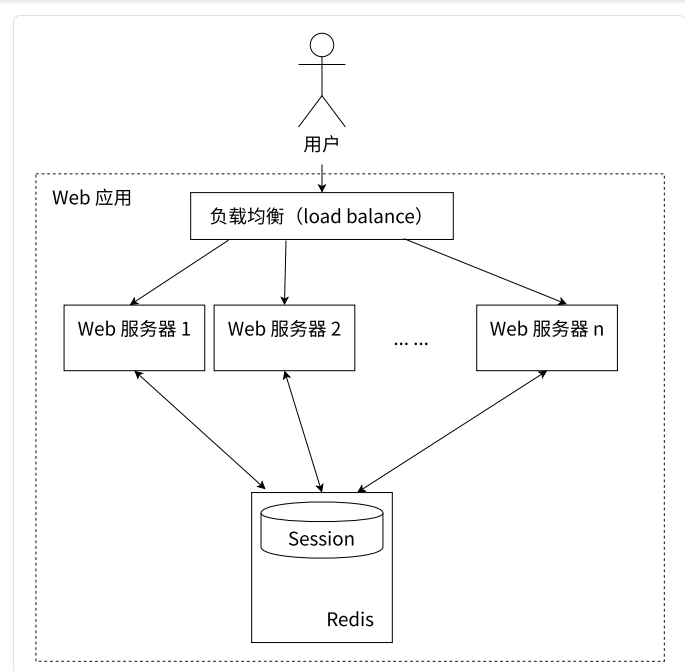
总结:这个session信息,相当于病人的相关数据,用客户端服务器的话术来说,会话信息是客户端服务器在交互过程产生的专属于客户端的中间状态信息的数据。
4.短信验证码
下面是实现验证码过期时间为1分钟或者检测当前1分钟发送验证码是否超过5次的限制策略。
(主要还是怕用户频繁请求验证码对服务器压力过大)
第二个是随机生成一个验证码,在Redis中设置该验证码5分钟内有效。
第三个是验证用户输入的验证码是否正确。
