🧑 博主简介:曾任某智慧城市类企业
算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN人工智能领域的优质创作者,提供AI相关的技术咨询、项目开发和个性化解决方案等服务,如有需要请站内私信或者联系任意文章底部的的VX名片(ID:xf982831907)
💬 博主粉丝群介绍:① 群内初中生、高中生、本科生、研究生、博士生遍布,可互相学习,交流困惑。② 热榜top10的常客也在群里,也有数不清的万粉大佬,可以交流写作技巧,上榜经验,涨粉秘籍。③ 群内也有职场精英,大厂大佬,可交流技术、面试、找工作的经验。④ 进群免费赠送写作秘籍一份,助你由写作小白晋升为创作大佬。⑤ 进群赠送CSDN评论防封脚本,送真活跃粉丝,助你提升文章热度。有兴趣的加文末联系方式,备注自己的CSDN昵称,拉你进群,互相学习共同进步。

【机器学习案列-22】基于线性回归(LR)的手机发布价格预测
-
- 一、引言
- 二、数据准备
-
- 2.1 数据集介绍
- 2.2 数据探索
- 2.3 数据清洗与处理
- 2.4 特征选择与工程
- 三、模型构建与训练
-
- 3.1 导入库并准备数据
- 3.2 训练线性回归模型
- 3.3 绘制训练结果和预测结果
- 四、结论与展望
一、引言
在当今数字化时代,智能手机已成为人们生活中不可或缺的一部分。随着技术的不断进步,智能手机市场呈现出多样化的发展趋势。本文将利用智能手机数据集,从多个维度进行分析,并使用线性回归模型预测手机的发布价格。该数据集涵盖了不同品牌、型号及硬件配置对价格的影响,揭示智能手机市场的定价规律和消费者偏好。
二、数据准备
2.1 数据集介绍
该数据集包含了不同公司的各种手机型号的详细规格和官方发布价格。它提供了对多个国家/地区的智能手机硬件、定价趋势和品牌竞争力的见解。数据集包括以下变量:
- Company Name:手机品牌或制造商。
- Model Name:智能手机的具体型号。
- Mobile Weight:手机的重量(以克为单位)。
- RAM:随机存取存储器容量(以GB为单位)。
- Front Camera:前置摄像头的分辨率(以MP为单位)。
- Back Camera:主后置摄像头的分辨率(以MP为单位)。
- Processor:设备中使用的芯片组或处理器。
- Battery Capacity:智能手机的电池容量(以mAh为单位)。
- Screen Size:智能手机的显示尺寸(以英寸为单位)。
- Launched Price (Pakistan):巴基斯坦的官方发布价格。
- Launched Price (India):印度的官方发布价格。
- Launched Price (China):中国的官方发布价格。
- Launched Price (USA):美国的官方发布价格。
- Launched Price (Dubai):迪拜的官方发布价格。
- Launched Year:手机正式推出的年份。
2.2 数据探索
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 加载数据
df = pd.read_csv('smartphone_data.csv',encoding='ISO-8859-1') # 请替换为实际文件路径
# 查看数据基本信息
df.shape
print(df.info())
df.isna().sum()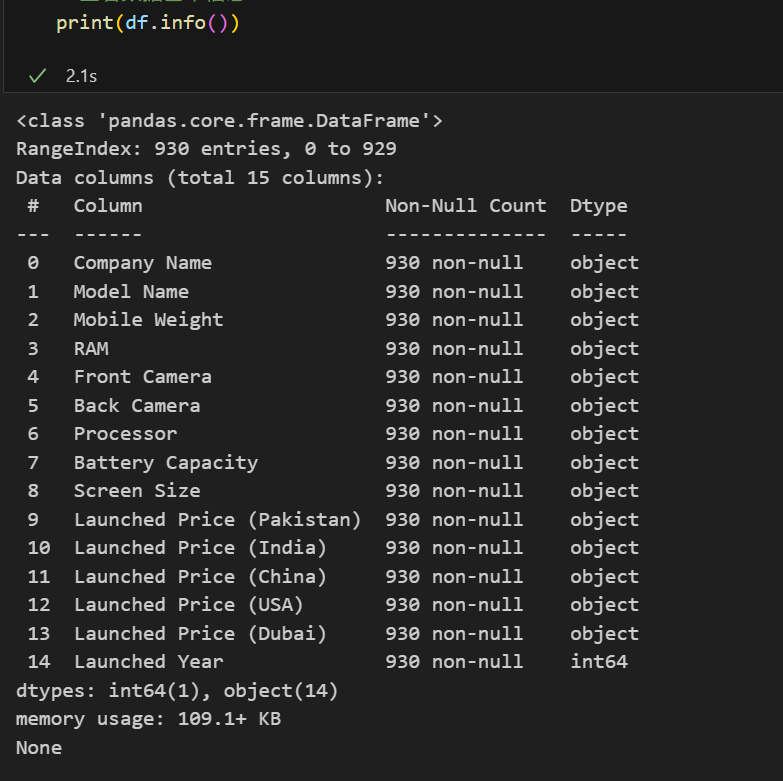
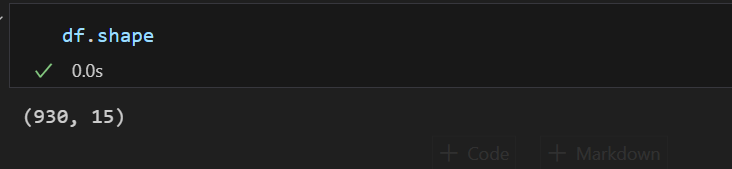
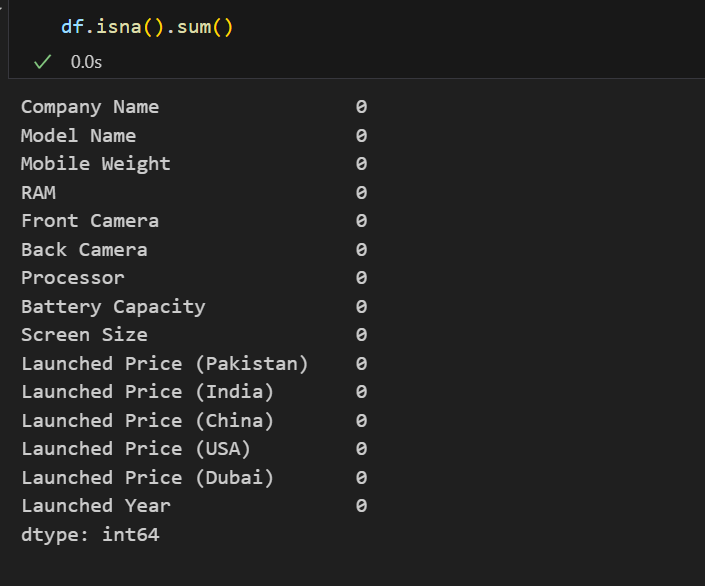
从数据基本信息可发现:
- 数据共15个维度,包含字符串和数值类型,其中只有发布年份是数值型,可视化时需要将各个国家的发布价格转成数值型。
- 数据中一个存在930条数据记录,而且数据无缺失值存在。
2.3 数据清洗与处理
在进行模型训练之前,我们需要对数据进行清洗和预处理。以下是数据清洗的代码示例:
python
# RAM处理
df['RAM'] = df['RAM'].apply(lambda x: x.split('GB')[0])
df['RAM'] = df['RAM'].map(float)
# 前置摄像头像素处理
df['Front Camera'] = df['Front Camera'].apply(lambda x: x.replace('Dual ', ''))
df['Front Camera'] = df['Front Camera'].apply(lambda x: x.split('MP')[0])
df['Front Camera'] = df['Front Camera'].map(float)
# 后置摄像头像素处理
df['Back Camera'] = df['Back Camera'].apply(lambda x: x.split('MP')[0])
df['Back Camera'] = df['Back Camera'].map(float)
# 电池容量处理
df['Battery Capacity'] = df['Battery Capacity'].apply(lambda x: x.replace('mAh', '').replace(',', ''))
df['Battery Capacity'] = df['Battery Capacity'].map(float)
# 屏幕尺寸处理
df['Screen Size'] = df['Screen Size'].apply(lambda x: x.split(' ')[0])
df['Screen Size'] = df['Screen Size'].map(float)
# 处理价格数据
price_columns = ['Launched Price (Pakistan)', 'Launched Price (India)', 'Launched Price (China)', 'Launched Price (USA)', 'Launched Price (Dubai)']
for col in price_columns:
df[col] = df[col].apply(lambda x: x.replace('PKR ', '').replace('INR ', '').replace('CNY ', '').replace('USD ', '').replace('AED ', '').replace(',', '').replace("¥", '').replace("$", ''))
df = df[df[col] != 'Not available']
df[col] = df[col].map(float)
# 将价格转换为统一货币单位(例如,转换为美元)
exchange_rates = {'Pakistan': 38.50, 'India': 11.67, 'China': 0.14, 'USA': 1.0, 'Dubai': 0.5}
for country, rate in exchange_rates.items():
df[f'Launched Price ({country})'] = df[f'Launched Price ({country})'] / rate
# 填充缺失值(如果有)
df.fillna(df.mean(), inplace=True)
# 处理Launched Price (USA)字段中的异常值
df['Launched Price (USA)'] = df['Launched Price (USA)'].apply(lambda x:x if x<df['Launched Price (China)'].max() else df['Launched Price (China)'].max())2.4 特征选择与工程
通过之前的可视化分析,我们发现以下特征对手机价格有显著影响:
具体参考文章:【数据可视化-46】截止2025年手机发布数据可视化分析
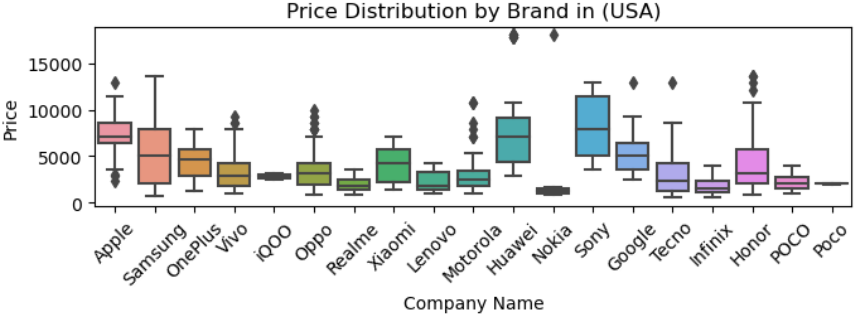
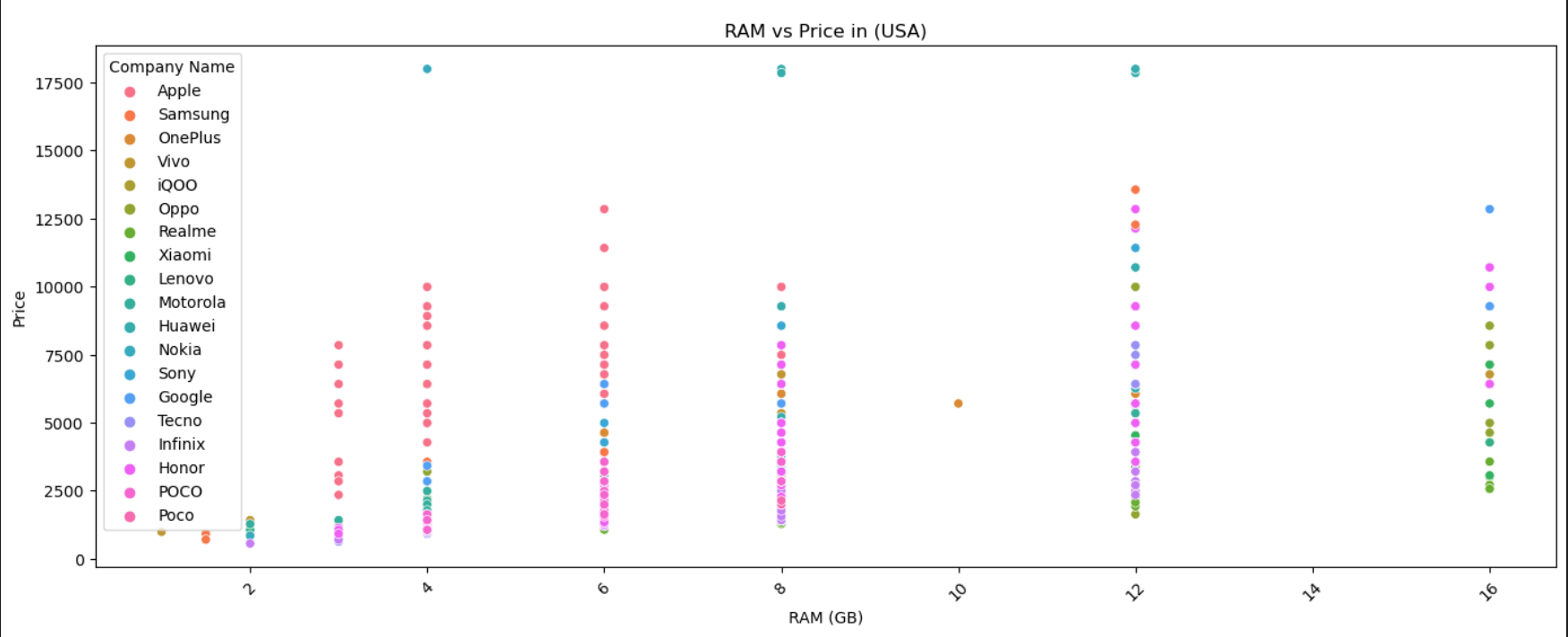
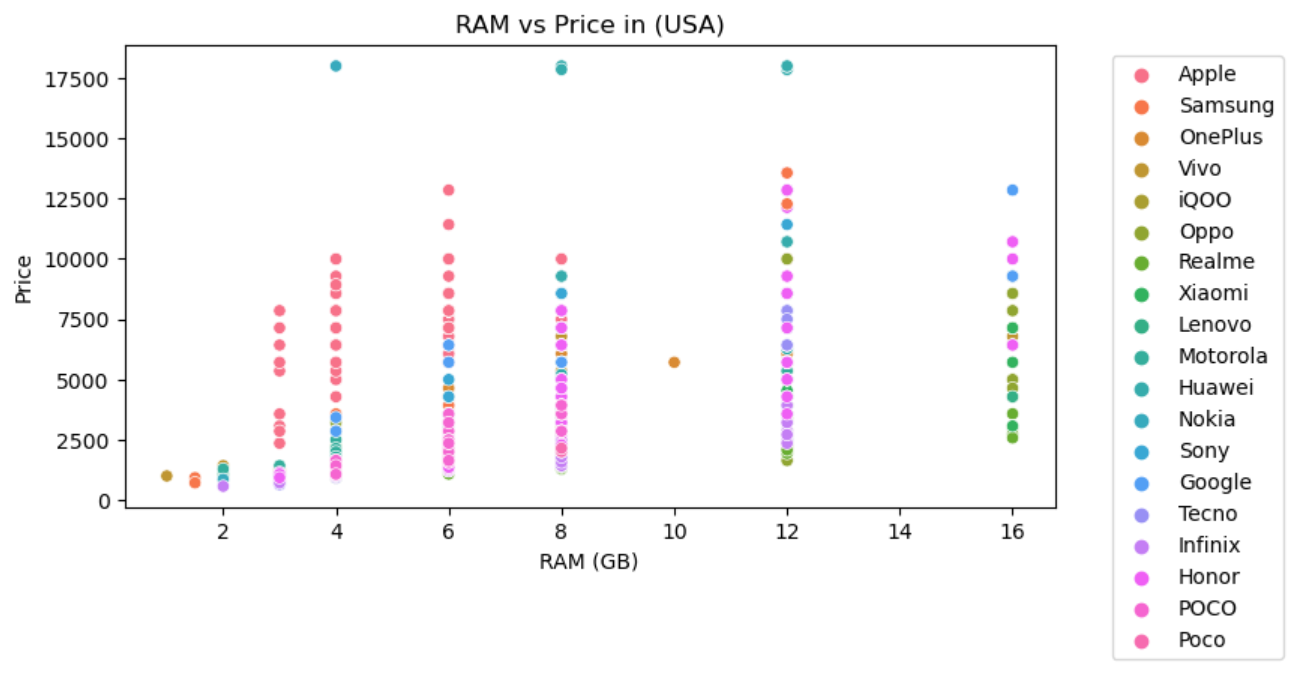
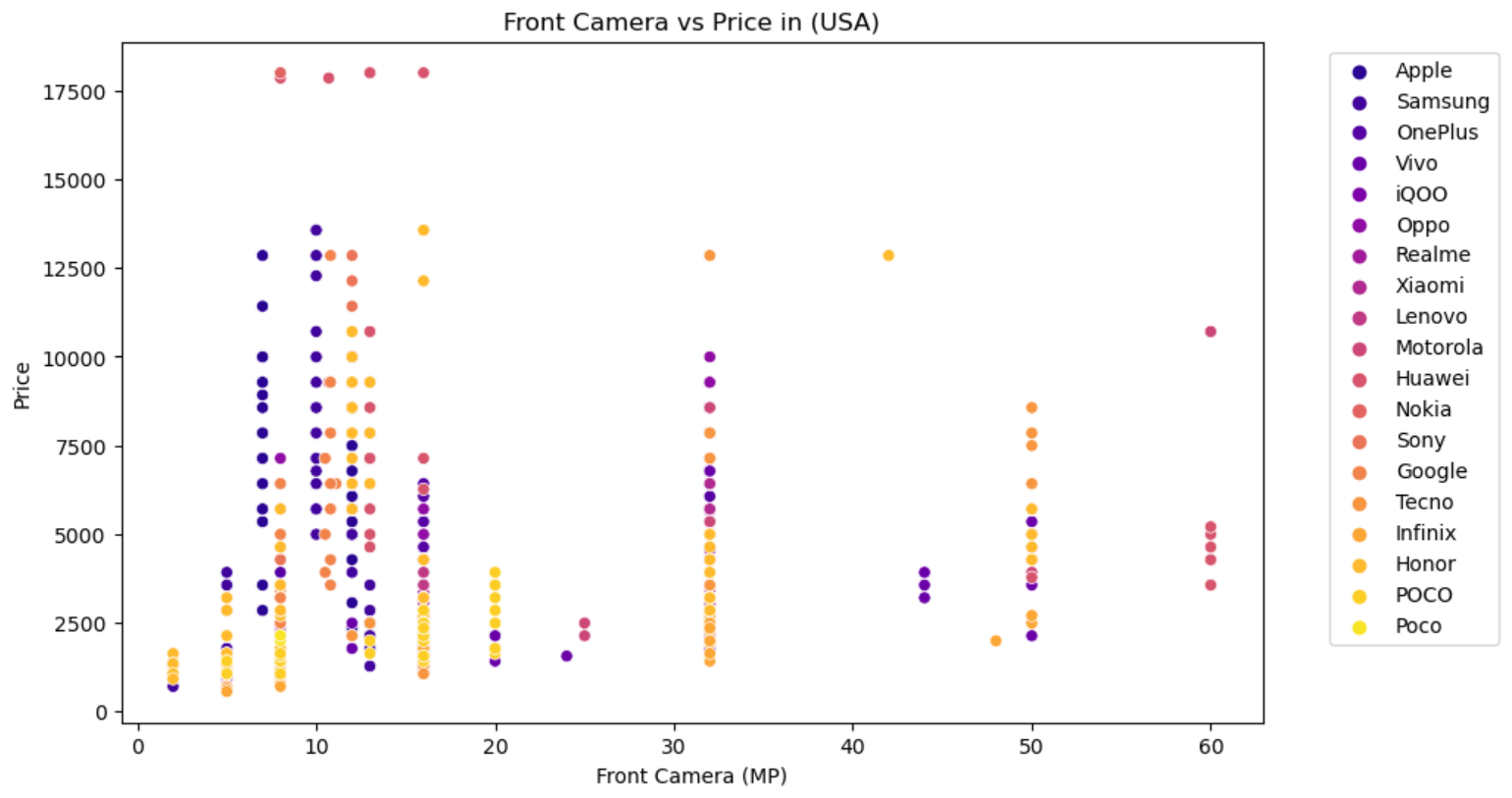
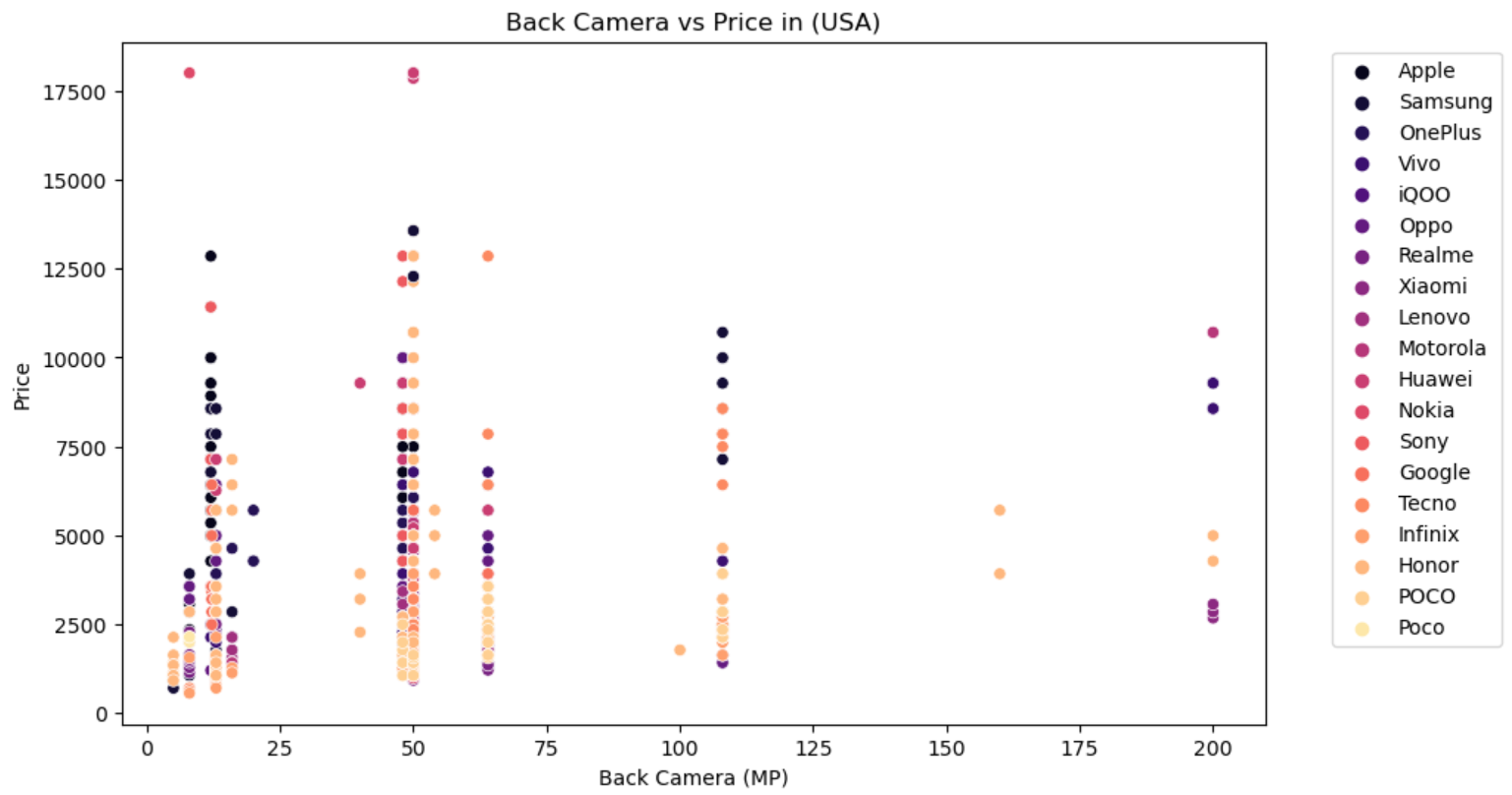
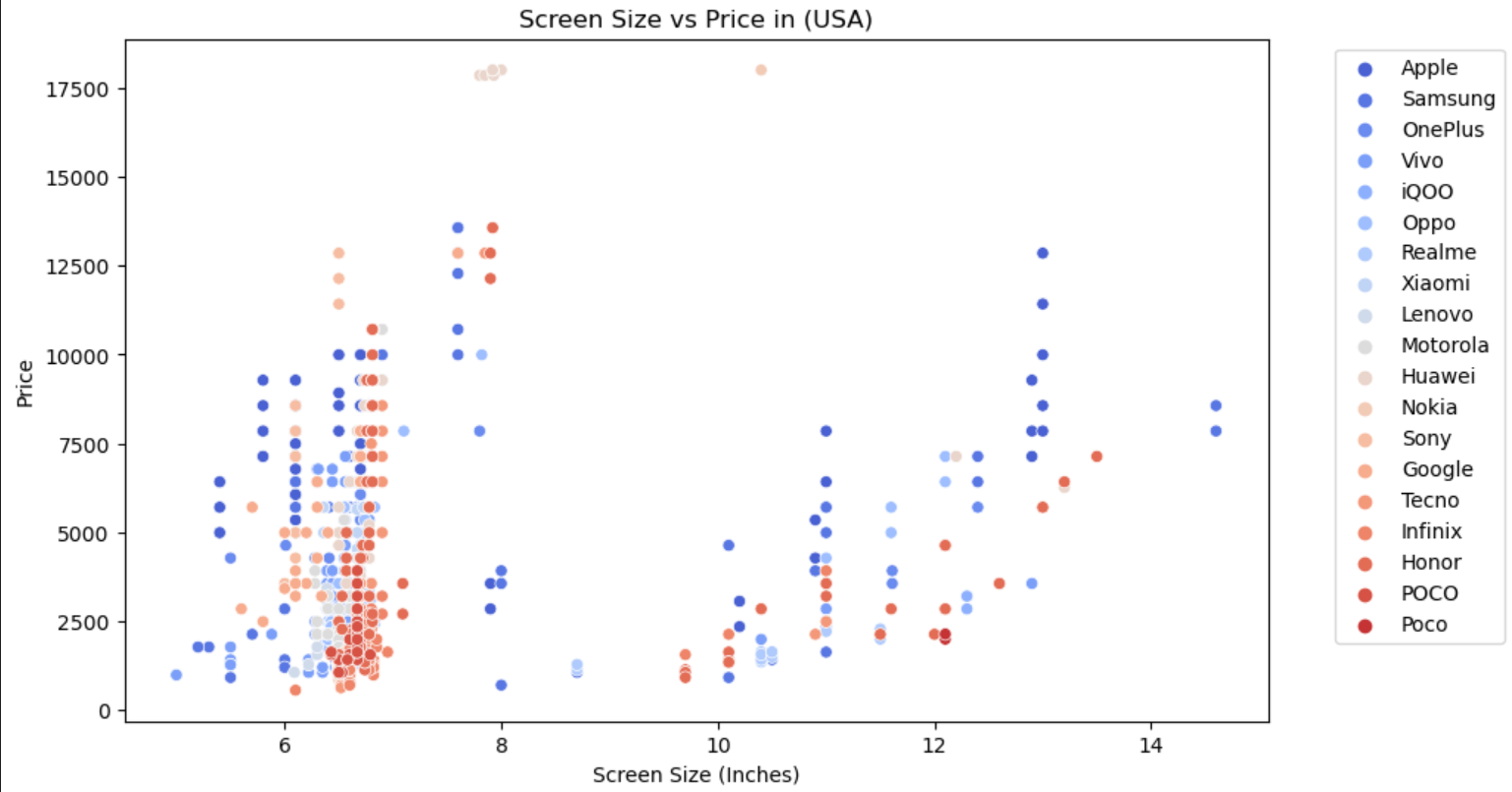
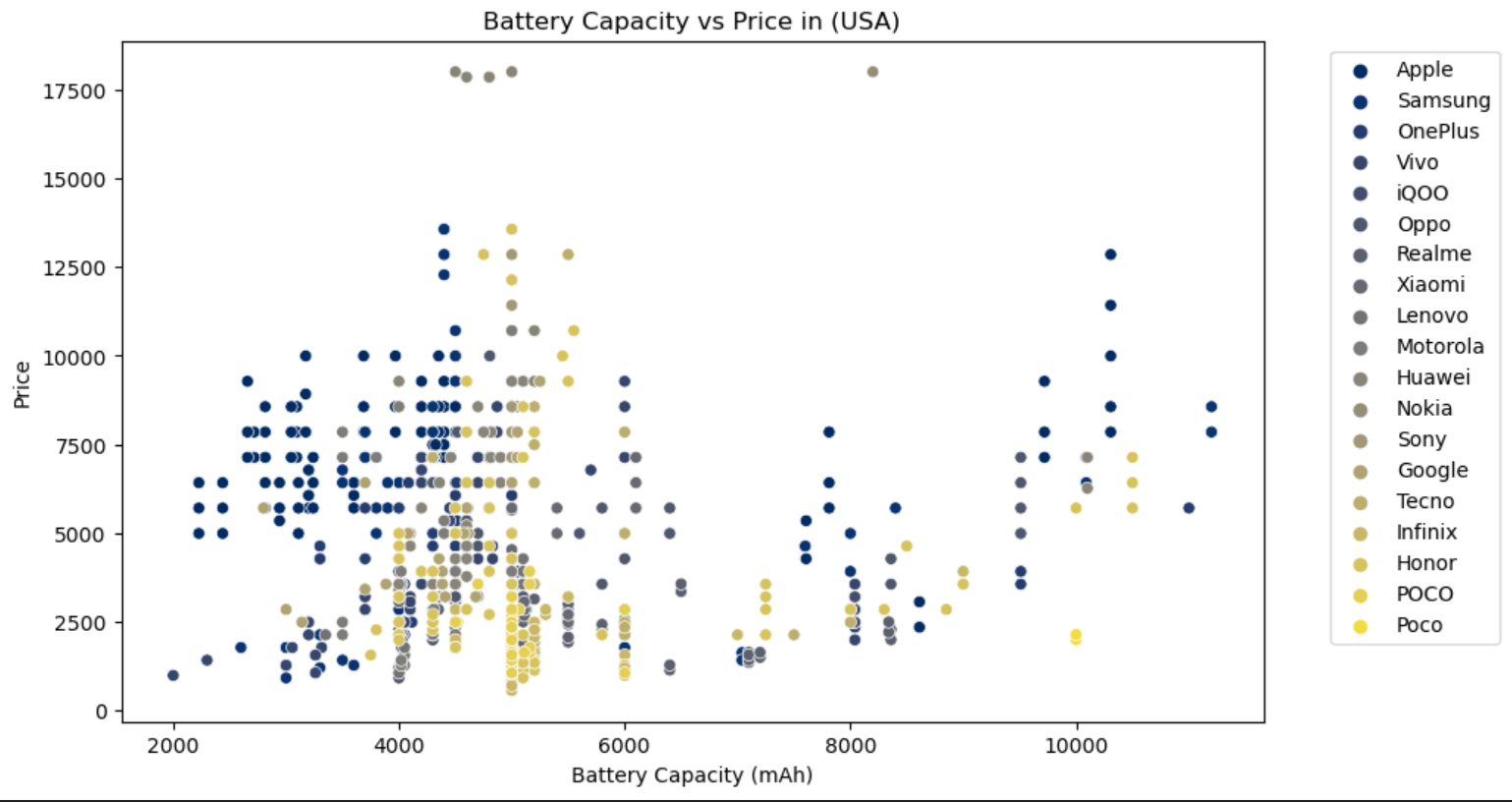
- RAM:RAM容量与价格通常呈正相关关系,高RAM配置的机型价格较高。
- 前置摄像头像素:前置摄像头像素与价格通常呈正相关关系,高像素前置摄像头的机型价格较高。
- 后置摄像头像素:后置摄像头像素与价格通常呈正相关关系,高像素后置摄像头的机型价格较高。
- 电池容量:电池容量与价格通常呈正相关关系,大容量电池的机型价格较高。
- 屏幕尺寸:屏幕尺寸与价格通常呈正相关关系,大屏幕机型价格较高。
- 推出年份:手机的推出年份也会影响价格,通常新款手机价格较高。
我们将这些特征作为自变量,选择一个国家/地区的发布价格(例如,美国的发布价格)作为因变量进行预测。
三、模型构建与训练
3.1 导入库并准备数据
python
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# 选择特征和目标变量
features = ['RAM', 'Front Camera', 'Back Camera', 'Battery Capacity', 'Screen Size', 'Launched Year']
target = 'Launched Price (USA)'
X = df[features]
y = df[target]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)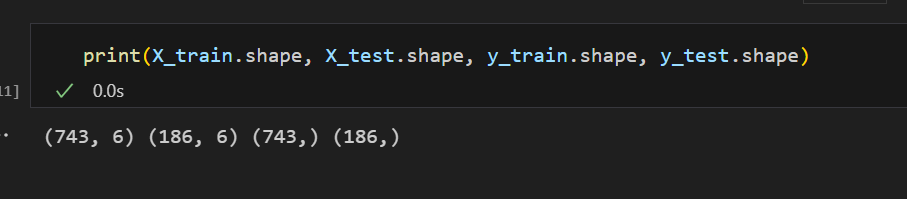
3.2 训练线性回归模型
python
# 创建线性回归模型
lr_model = LinearRegression()
# 训练模型
lr_model.fit(X_train, y_train)
# 预测测试集结果
y_pred = lr_model.predict(X_test)
# 评估模型性能
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"线性回归 - 均方误差(MSE):{mse}")
print(f"线性回归 - 决定系数(R²):{r2}")
3.3 绘制训练结果和预测结果
python
import matplotlib.pyplot as plt
# 绘制真实值和预测值
plt.figure(figsize=(12, 6))
plt.scatter(y_test, y_pred, alpha=0.5, color='blue', label='Predictions')
plt.plot([y.min(), y.max()], [y.min(), y.max()], 'k--', lw=2, label='Ideal')
plt.xlabel('Actual Price')
plt.ylabel('Predicted Price')
plt.title('Actual vs Predicted Prices')
plt.legend()
plt.show()
# 绘制残差图
plt.figure(figsize=(12, 6))
residuals = y_test - y_pred
plt.scatter(y_pred, residuals, alpha=0.5, color='red', label='Residuals')
plt.axhline(y=0, color='k', linestyle='--', lw=2)
plt.xlabel('Predicted Price')
plt.ylabel('Residuals')
plt.title('Residual Plot')
plt.legend()
plt.show()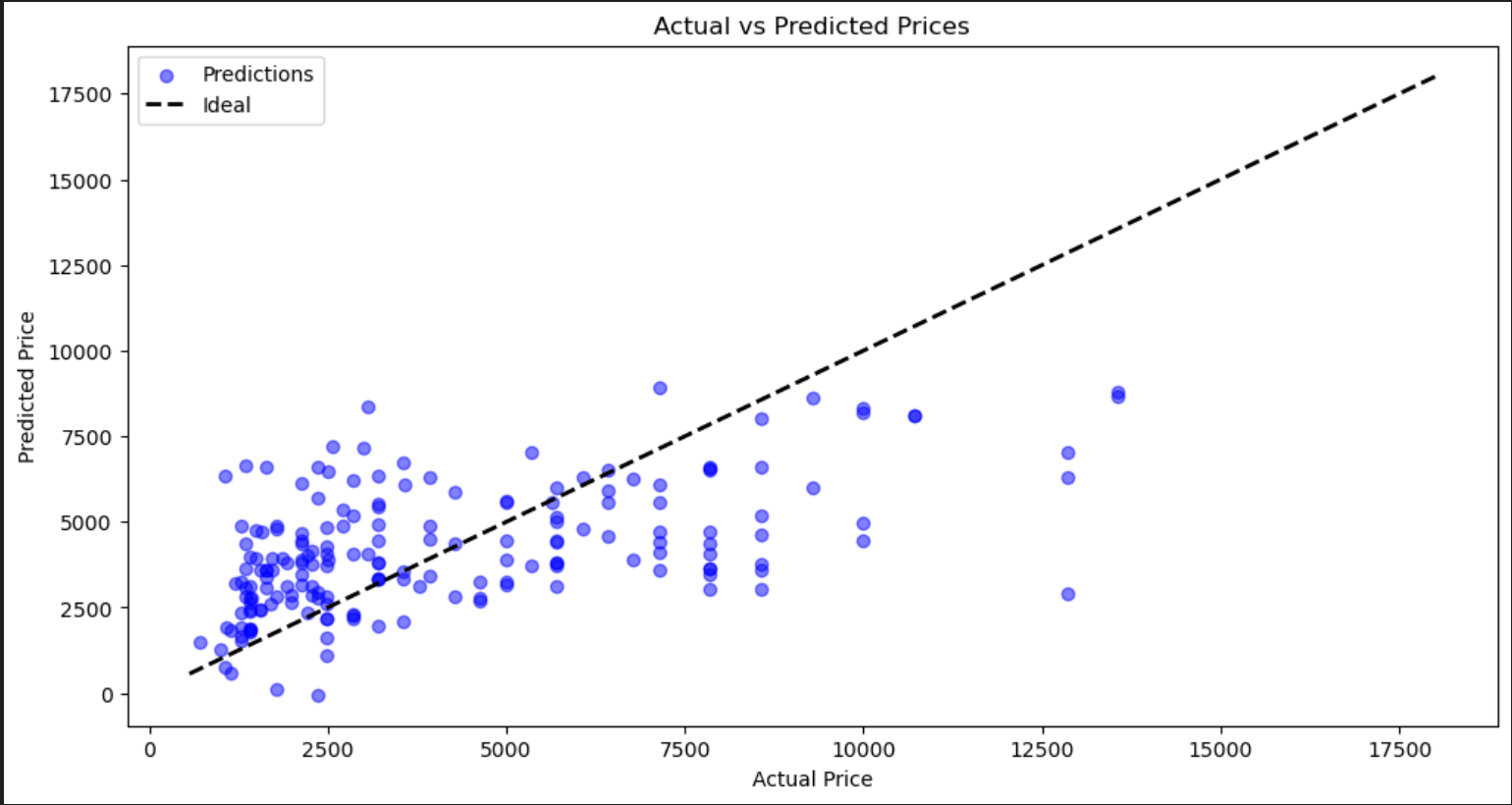
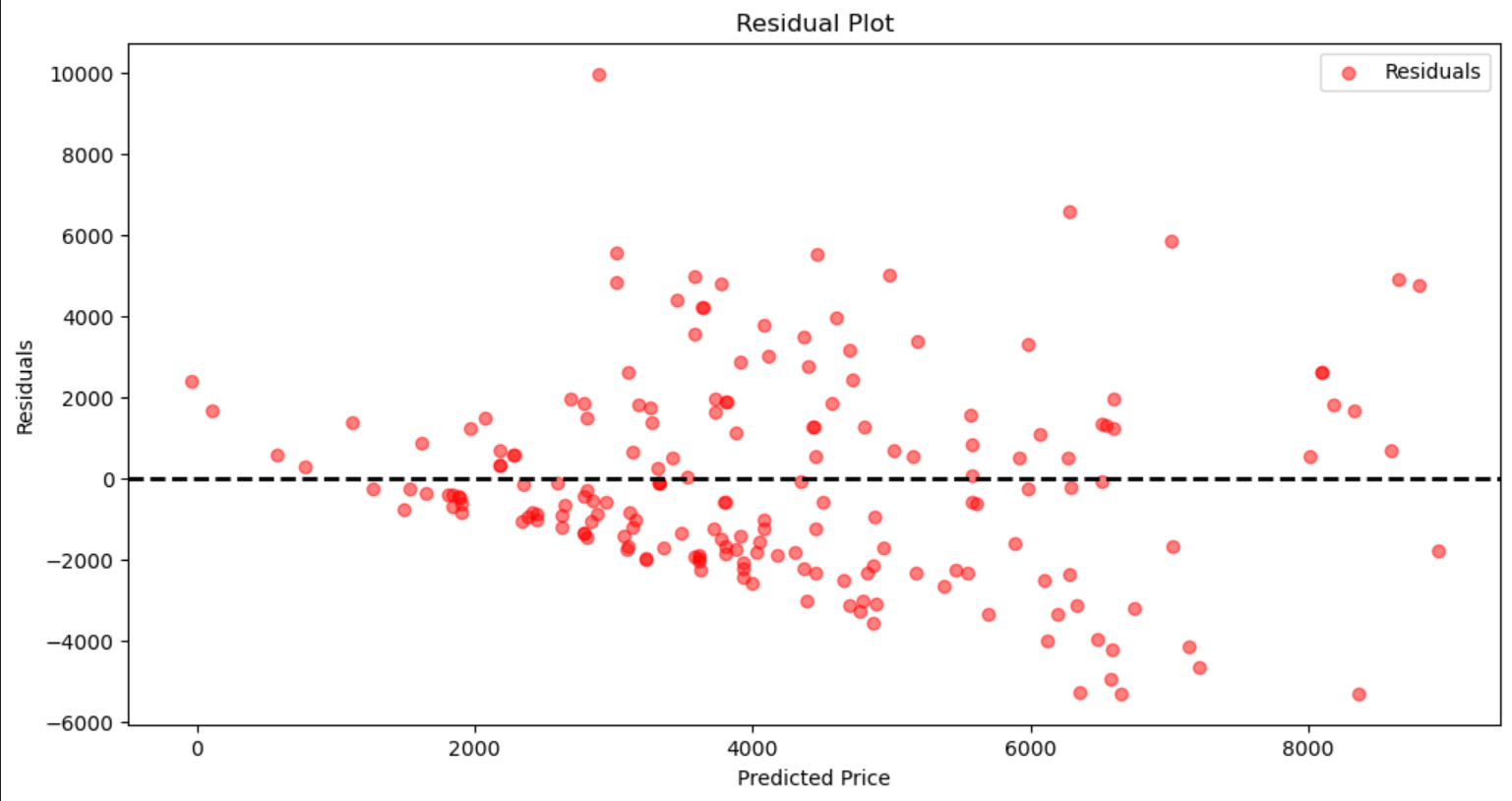
四、结论与展望
通过上述步骤,我们构建了一个基于线性回归的手机发布价格预测模型。该模型考虑了手机的硬件配置和推出年份对价格的影响,为理解和预测智能手机市场提供了有力工具。模型的均方误差(MSE)和决定系数(R²)可以帮助我们评估模型的性能。
从可视化结果可以看出,线性回归模型在预测手机价格方面表现良好,但仍有改进空间。未来的研究可以进一步优化模型,例如:
- 尝试不同的特征组合和工程方法。
- 引入更多数据集,增加模型的泛化能力。
- 考虑非线性关系,使用多项式回归或其他非线性模型。
希望这篇博客对您有所帮助!如果您有其他问题或需要进一步的解释,请随时告诉我。