目录

1.摘要
传统粒子群算法(PSO)通过粒子根据个体最佳经验和种群最佳经验更新速度和位置,虽然这种学习机制简单易行,但容易产生振荡等问题。因此设计一种有效的学习策略,以克服这些问题并提高搜索效率,成为PSO研究中的重要课题。本文提出了一种基于粒子个人最佳经验维度学习策略(DLS),其用来发现并整合种群最佳解中的有前景信息。基于BLS,本文提出了双群学习粒子群算法(TSLPSO),该算法采用不同的学习策略:一个子群通过DLS构建学习示例来引导粒子的局部搜索,另一个子群则通过综合学习策略来引导全局搜索。
2.粒子群算法PSO原理
3.改进策略
维度学习策略(DLS)
传统粒子群算法(PSO)通过个人最佳经验和种群最佳经验进行学习,但这种学习策略可能导致振荡现象的问题。当个人最佳位置和种群最佳位置位于当前粒子位置的相对方向时,粒子在接近种群最佳位置后,可能会由于个人最佳位置与当前粒子位置之间的较大差距,导致粒子在这两个位置之间徘徊,从而引发振荡现象,降低搜索效率。此外,现有PSO算法通常在更新所有维度后才评估适应度函数,即使新的解向量提高了适应度,也可能出现维度退化。为了解决这些问题,改进PSO算法采用不同的学习策略构建学习示例以引导粒子搜索,避免振荡现象。然而,这些方法存在较大的随机性,尽管提高了种群多样性和全局搜索能力,但却导致算法收敛速度变慢,且无法避免振荡现象。
为了保护粒子中潜在的有用信息,本文提出了一种受OLPSO启发的维度学习策略(DLS)。在DLS中,粒子的个人最佳位置 x i b e s t x_i^{best} xibest通过种群最佳位置 x g b e s t x_{gbest} xgbest按维度逐步构建学习示例 x i d l x_i^{dl} xidl,这种方式使得种群最佳位置 x g b e s t x_{gbest} xgbest中的优秀信息能够传递到学习示例 x i d l x_i^{dl} xidl,从而促进了优秀信息的扩展和种群最佳位置编码模式的保护。
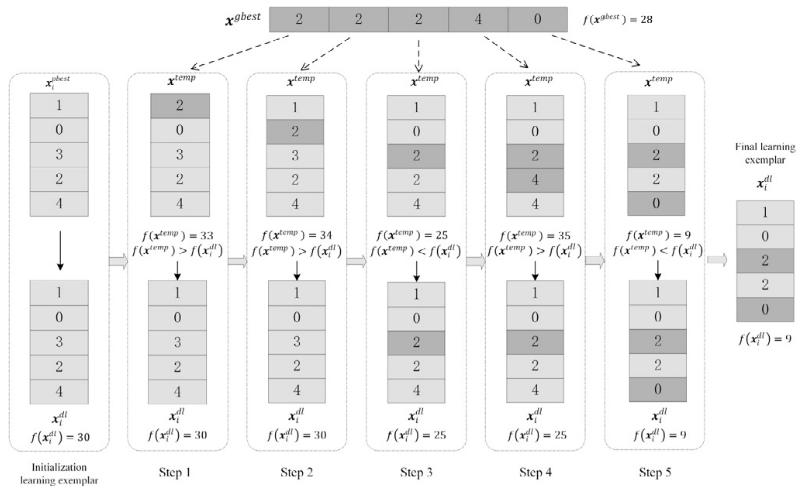
论文给出了一个示例帮助理解:假设目标是最小化一个五维球面函数: f ( x ) = x 1 2 + x 2 2 + x 3 2 + x 4 2 + x 5 2 f(x)=x_1^2+x_2^2+x_3^2+x_4^2+x_{5}^2 f(x)=x12+x22+x32+x42+x52,其全局最小值点为 ( 0 , 0 , 0 , 0 , 0 , 0 ) T (0,0,0,0,0,0)^T (0,0,0,0,0,0)T。粒子1的个人最佳位置为 x 1 b e s t = ( 1 , 0 , 3 , 2 , 4 ) T x_1^{best}=(1,0,3,2,4)^T x1best=(1,0,3,2,4)T,当前的种群最佳位置为 x g b e s t = ( 2 , 2 , 2 , 4 , 0 ) T x_{gbest}=(2,2,2,4,0)^T xgbest=(2,2,2,4,0)T,如图中的水平个体所示。显然, f ( x g b e s t ) = 30 f(x_{gbest})=30 f(xgbest)=30且 f ( x p b e s t ) = 28 f(x_{pbest})=28 f(xpbest)=28。粒子 x i b e s t x_i^{best} xibest从种群最佳位置 x g b e s t x_{gbest} xgbest的每个维度学习形成一个学习示例 x i d l x_i^{dl} xidl。我们设置一个临时向量 x t e m p x_{temp} xtemp,其初始值为 x t e m p = x g b e s t = x_{temp}=x_{gbest}= xtemp=xgbest= ( 1 , 0 , 3 , 2 , 4 ) T (1,0,3,2,4)^T (1,0,3,2,4)T。如图所示,维度学习过程如下:
- 对于维度1:令 x t e m p 1 = x p b e s t 1 = 2 x_{temp_1}=x_{pbest1}=2 xtemp1=xpbest1=2,则 x t e m p 1 = ( 2 , 0 , 3 , 2 , 4 ) T x_{temp_1}=(2,0,3,2,4)^T xtemp1=(2,0,3,2,4)T,计算 f ( x t e m p ) = 33 > f ( x p b e s t 1 ) = 30 f(x_{temp})=33>f(x_{pbest1})=30 f(xtemp)=33>f(xpbest1)=30,因此 x p b e s t 1 x_{pbest_1} xpbest1保持不变, x p b e s t 1 = x_{pbest_1}= xpbest1= ( 1 , 0 , 3 , 2 , 4 ) T (1,0,3,2,4)^{T} (1,0,3,2,4)T,且 f ( x p b e s t 1 ) = 30 f(x_{pbest_1})=30 f(xpbest1)=30。
- 对于维度2: x t e m p 2 = x p b e s t 2 = 2 x_{temp2}=x_{pbest2}=2 xtemp2=xpbest2=2,则 x t e m p 2 = ( 1 , 2 , 3 , 2 , 4 ) T x_{temp2}=(1,2,3,2,4)^T xtemp2=(1,2,3,2,4)T,计算 f ( x t e m p ) = 34 > f ( x p b e s t 2 ) = 30 f(x_{temp})=34>f(x_{pbest2})=30 f(xtemp)=34>f(xpbest2)=30,因此 x p b e s t 2 x_{pbest2} xpbest2保持不变, x p b e s t 2 = x_{pbest2}= xpbest2= ( 1 , 0 , 3 , 2 , 4 ) T (1,0,3,2,4)^T (1,0,3,2,4)T,且 f ( x p b e s t 2 ) = 30 f(x_{pbest2})=30 f(xpbest2)=30。
- 对于维度3: x t e m p 3 = x p b e s t 3 = 3 x_{temp3}=x_{pbest3}=3 xtemp3=xpbest3=3,则 x t e m p 3 = ( 1 , 0 , 2 , 2 , 4 ) T x_{temp3}=(1,0,2,2,4)^T xtemp3=(1,0,2,2,4)T,计算 f ( x t e m p ) = 25 < f ( x p b e s t 3 ) = 30 f(x_{temp})=25 < f(x_{pbest3})=30 f(xtemp)=25<f(xpbest3)=30,因此 x p b e s t 3 = x g b e s t 3 = 2 x_{pbest3}=x_{gbest3}=2 xpbest3=xgbest3=2,即 x p b e s t 3 = ( 1 , 0 , 2 , 2 , 4 ) T x_{pbest3}=(1,0,2,2,4)^{T} xpbest3=(1,0,2,2,4)T,且 f ( x p b e s t 3 ) = 25. f(x_{pbest3})=25. f(xpbest3)=25.
- 对于维度4: x t e m p 4 = x p b e s t 4 = 4 x_{temp4}=x_{pbest4}=4 xtemp4=xpbest4=4,则 x t e m p 4 = ( 1 , 0 , 2 , 4 , 4 ) T x_{temp4}=(1,0,2,4,4)^T xtemp4=(1,0,2,4,4)T,计算 f ( x t e m p ) = 35 > f ( x p b e s t 4 ) = 25 f(x_{temp})=35>f(x_{pbest4})=25 f(xtemp)=35>f(xpbest4)=25,因此 x p b e s t 4 x_{pbest4} xpbest4保持不变, x p b e s t 4 = x_{pbest4}= xpbest4= ( 1 , 0 , 2 , 2 , 4 ) T (1,0,2,2,4)^T (1,0,2,2,4)T,且 f ( x p b e s t 4 ) = 25. f(x_{pbest4})=25. f(xpbest4)=25.
- 对于维度5: x t e m p 5 = x p b e s t 5 = 5 x_{temp5}=x_{pbest5}=5 xtemp5=xpbest5=5,则 x t e m p 5 = ( 1 , 0 , 2 , 2 , 0 ) T x_{temp5}=(1,0,2,2,0)^T xtemp5=(1,0,2,2,0)T,计算
f ( x t e m p ) = 9 < f ( x p b e s t 5 ) = 25 f(x_{temp})=9 < f(x_{pbest5})=25 f(xtemp)=9<f(xpbest5)=25,因此 x p b e s t 5 = 0 x_{pbest5}=0 xpbest5=0,即 x p b e s t 5 = x_{pbest5}= xpbest5=
( 1 , 0 , 2 , 2 , 0 ) T (1,0,2,2,0)^T (1,0,2,2,0)T,且 f ( x p b e s t 5 ) = 9 f(x_{pbest5})=9 f(xpbest5)=9。
最终,学习示例为 x i d l = ( 1 , 0 , 2 , 2 , 0 ) T x_i^{dl}=(1,0,2,2,0)^T xidl=(1,0,2,2,0)T,其中第三和第五维度通过粗体显示的种群最佳位置从 x g b e s t = ( 2 , 2 , 2 , 4 , 0 ) T x_{gbest}=(2,2,2,4,0)^T xgbest=(2,2,2,4,0)T学习得到。因此,基于所提出的DLS策略,粒子 x i b e s t x_i^{best} xibest从 x g b e s t x_{gbest} xgbest构建了 x i d l x_i^{dl} xidl,并且最终得到的学习示例 x i d l x_i^{dl} xidl不会比 x g b e s t x_{gbest} xgbest差。改进后的速度更新公式:
v i , j = w v i , j + c 1 r 1 , j ( x i , j d l − x i , j ) + c 2 r 2 , j ( x j g b e s t − x i , j ) v_{i,j}=wv_{i,j}+c_1r_{1,j}\left(x_{i,j}^{dl}-x_{i,j}\right)+c_2r_{2,j}\left(x_j^{gbest}-x_{i,j}\right) vi,j=wvi,j+c1r1,j(xi,jdl−xi,j)+c2r2,j(xjgbest−xi,j)
本文提出了一种双群体学习粒子群优化算法(TSLPSO),其用来平衡探索和开发提升粒子群优化的全局搜索和局部开发能力。TSLPSO算法设计了两个子群体:DL子群体和CL子群体。两者的主要区别在于构建学习示例的策略。DL子群体通过维度学习策略(DLS)构建学习示例,具有较强的局部开发能力;而CL子群体采用综合学习策略(CLS),增强了全局搜索能力。
TSLPSO的两个子群体分别采用不同的学习策略,使得DL子群体能够从种群中获得强大的局部开发能力,而CL子群体则通过抵抗种群最佳经验的影响,保持高种群多样性和强全局搜索能力。
伪代码

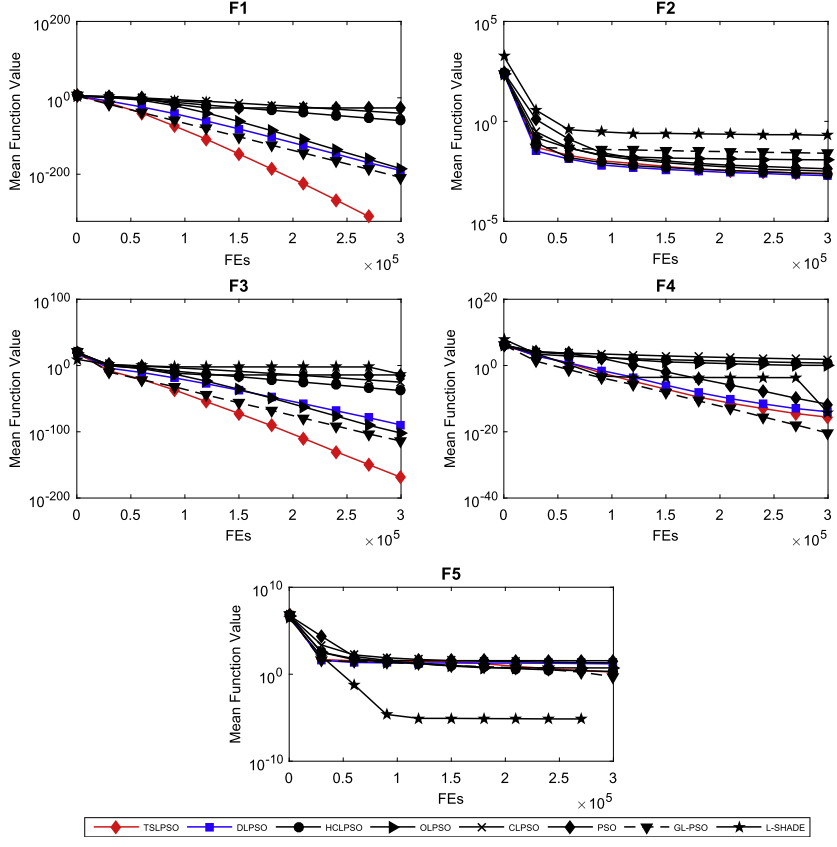
4.论文结果展示
5.参考文献
1 Xu G, Cui Q, Shi X, et al. Particle swarm optimization based on dimensional learning strategyJ. Swarm and Evolutionary Computation, 2019, 45: 33-51.